大家好,我是微学AI,今天给大家带来OCR的分栏识别。
一、文本分栏的问题
在OCR识别过程中,遇到文字是两个分栏的情况确实是一个比较常见的问题。通常情况下,OCR引擎会将文本按照从左到右,从上到下的顺序一行一行地识别。这种方式对于单栏或者少量分栏的文本来说是有效的,但是对于两个或者更多分栏的文本来说就有些棘手了。
在这种情况下,OCR引擎往往会将整个文本当作一行来处理,这就导致了分栏信息的丢失。如果直接将整个文本传递给OCR引擎,那么它会试图将所有的文字一起识别,而没有办法分辨哪些文字属于哪个栏目。

二、解决方案
为了解决这个问题,我们需要首先将文本分成两个栏目,然后再分别进行OCR识别。这个过程可以手动完成,也可以借助一些自动化工具。例如,可以使用图像处理算法来检测出文本中的分栏线,然后将文本按照这些线进行分割。
一旦将文本分成了两个栏目,就可以对每个栏目进行独立的OCR识别。这样可以保留分栏信息,同时提高识别精度。
对于三栏或者更多分栏的文本,也可以采用类似的方法进行处理。首先将文本分成多个栏目,然后再对每个栏目进行独立的OCR识别。
需要注意的是,将文本按照分栏进行切分会增加处理复杂度和运算量,可能会降低处理速度和识别准确率。因此,在实际应用中需要根据具体情况进行权衡和选择。
三、代码实现
import cv2
from paddleocr import PaddleOCR
# 加载OCR引擎
engine = PaddleOCR(enable_mkldnn=True, use_angle_cls=False)
#分两栏识别
def recognize_multicolumn_text2(image_path,left_ratio=0.5):
# 读取图片
img = cv2.imread(image_path)
# 将图片转为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 获取图片的高度和宽度
height, width = gray.shape
# 将图片分成左右两栏,分别识别
left_width = int(width * left_ratio)
left_img = gray[:, :left_width]
right_img = gray[:, left_width:]
titles = []
left_text=image2text(left_img)
right_text=image2text(right_img)
titles.extend(left_text)
titles.extend(right_text)
# 将识别出的两栏文字拼接起来
#result_text = left_text + ' ' + right_text
for i in titles:
print(i)
return titles
#分三栏识别
def recognize_multicolumn_text3(image_path, left_ratio=0.3333, middle_ratio=0.6667):
# 读取图片
img = cv2.imread(image_path)
# 将图片转为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 获取图片的高度和宽度
height, width = gray.shape
# 将图片分成三栏,分别识别
left_width = int(width * left_ratio)
middle_width = int(width * middle_ratio)
left_img = gray[:, :left_width]
middle_img = gray[:, left_width:middle_width]
right_img = gray[:, middle_width:]
titles = []
left_text = image2text(left_img)
middle_text = image2text(middle_img)
right_text = image2text(right_img)
titles.extend(left_text)
titles.extend(middle_text)
titles.extend(right_text)
for i in titles:
print(i)
return titles
# 图片OCR转文本信息
def image2text(path):
result = engine.ocr(path)
print('识别结果:')
title= []
title_append= title.append
for key in result[0]:
key[-1] = list(key[-1])
key[-1][0] = key[-1][0].replace('\n', '')
title_append(key[-1][0])
return title
image ='200.jpg'
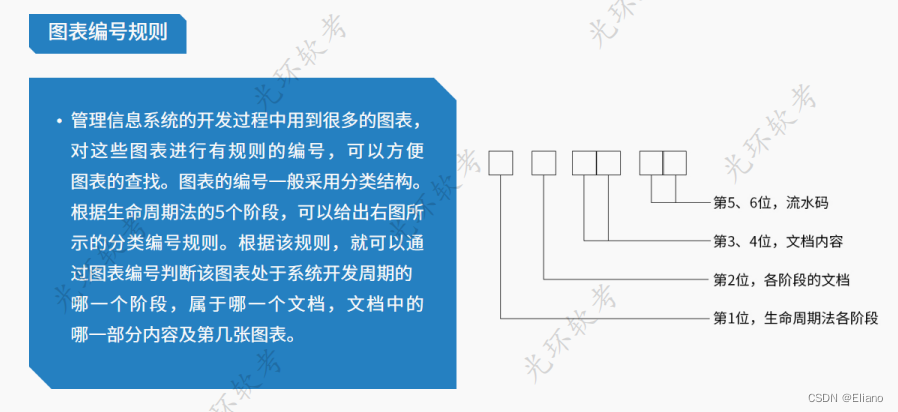
recognize_multicolumn_text3(image)代码提供了分栏识别与分三栏识别的函数,可以扩展N栏,根据需求设定。
对于分三栏的问题也一样可以识别:

识别效果还可以,调用函数之后可以进行批量识别,可以识别PDF,和图库的文件,实现批量识别。
OCR分栏识别是OCR技术的一个应用领域,它可以在处理多列或多块的文本时,将文本分割成段落、行和字符,并对它们进行识别。
OCR分栏识别的主要优势:
1. 能够自动识别并分割多栏文本,从而加快文本提取和理解速度。
2. 可以处理各种类型的文档,如书籍、报纸、表格等。
3. 提高了文本提取和处理的准确性和效率,降低了人工处理的成本。
4. 可以使数字化文件搜索和浏览更加方便。
总之,OCR分栏识别可以将传统的文本处理转换为数字化的自动处理,为企业和个人节省时间和成本,提升效率和准确性。