关系抽取方面的基础
- 一、基本概念
- 1. 什么是关系抽取(Relation Extraction,RE)?
- 2. 都有什么奇怪的关系?
- 3. 任务评价指标
- 二、 关系抽取方法
- 2.1 按模型结构分——Pipeline 和 Joint方法
- Pipeline方法
- Joint方法
- 2.2 按解码方式分——基于序列标注的方案、基于指针网络和基于Span片段的方案
- 2.2.1 基于序列标注的方案
- 2.2.2 基于指针网络
- 2.2.3 基于Span片段的方案
- 2.3 样本获取难的解决办法——远程监督、few shot
- 半监督
- Bootstrapping
- 远程监督(Distant supervision)
一、基本概念
1. 什么是关系抽取(Relation Extraction,RE)?
若有两个存在着关系的实体,我们可将两个实体分别成为主体和客体,那么关系抽取就是在非结构或半结构化数据中找出主体与客体之间存在的关系,并将其表示为实体关系三元组,即(主体,关系,客体)。
2. 都有什么奇怪的关系?

a:正常的一个实体对应一个关系问题
b:关系重叠问题,一对多。如“张学友演唱过《吻别》《在你身边》”中,存在2种关系:「张学友-歌手-吻别」和「张学友-歌手-在你身边」
c:关系重新问题,一对实体存在多种关系。如“周杰伦作曲并演唱《七里香》”中,存在2种关系:「周杰伦-歌手-七里香」和「周杰伦-作曲-七里香」
d:复杂关系问题,由实体重叠导致。如《叶圣陶散文选集》中,叶圣陶-作品-叶圣陶散文选集,实体中包含实体;
e:复杂关系问题,关系交叉导致。如“张学友、周杰伦分别演唱过《吻别》《七里香》”,「张学友-歌手-吻别」和「周杰伦-歌手-七里香」
关系重叠问题在实体关系抽取中会影响抽取的性能,所以解决各种关系重叠类型的实体关系抽取、提高抽取性能是目前研究的重点。
Single Entity Overlap (SEO) 单一实体重叠:两个三元组之间有一个实体重叠
Entity Pair Overlap (EPO) 实体对重叠 :即一个实体对之间存在着多种关系
Subject Object Overlap (SOO) 主客体重叠 :既是主体,又是客体
3. 任务评价指标
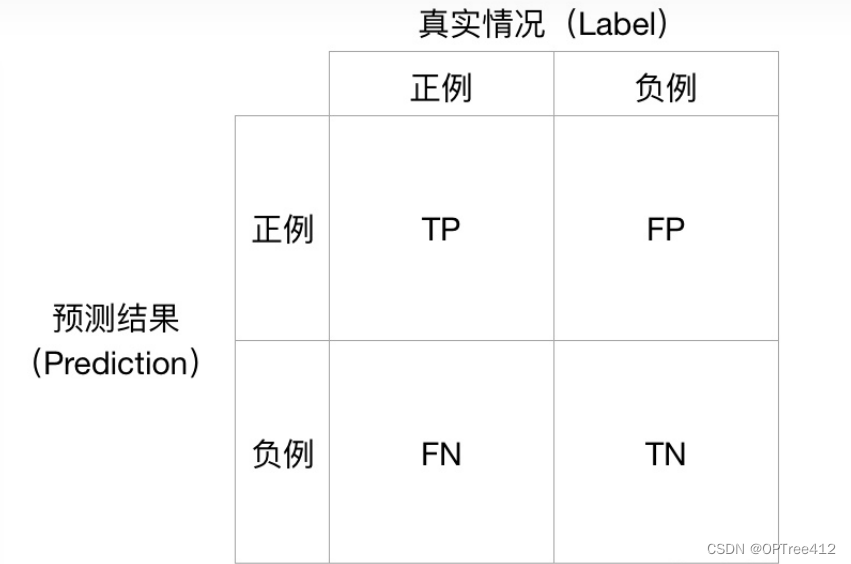
RE任务常用的评价指标为Precision、Recall和F1。
- Precision,又称精准率,
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision=\frac{TP}{TP + FP}
Precision=TP+FPTP。从预测结果角度出发,模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例,Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;
(注意:Acc准确率与Precision精确度不一样。Acc准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。) - Recall,又称召回率。 R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP,召回率指实际为正的样本中被预测为正的样本所占实际为正的样本的比例。召回率直观地说是分类器找到所有正样本的能力。
- F1, F 1 = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F1 = \frac{2*Precision*Recall}{Precision+Recall} F1=Precision+Recall2∗Precision∗Recall,是精确率和召回率的调和平均值。Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;Recall体现了模型对正样本的识别能力,Recall越高,模型对正样本的识别能力越强。F1 score是两者的综合,F1 score越高,说明模型越稳健。
二、 关系抽取方法
2.1 按模型结构分——Pipeline 和 Joint方法

(1)流水线(Pipeline)方法:先从文本中抽取全部实体(
e
1
,
.
.
.
,
e
n
e_1,...,e_n
e1,...,en),然后针对全部可能的实体对
(
e
i
,
e
j
(e_i,e_j
(ei,ej),
i
≠
j
i \neq j
i=j判定其之间的关系类别。
(2)联合抽取(Joint extraction)方法:通过修改标注方法和模型结构直接输出文本中包含的三元组。

Pipeline方法
Joint方法
对于 联合抽取(Joint extraction),又可以分为 “参数共享的联合模型” 和 “联合解码的联合模型”:
现有联合抽取模型总体上有两大类:
- 共享参数的联合抽取模型
通过共享参数(共享输入特征或者内部隐层状态)实现联合,此种方法对子模型没有限制,但是由于使用独立的解码算法,导致实体模型和关系模型之间交互不强。 - 联合解码的联合抽取模型
为了加强实体模型和关系模型的交互,复杂的联合解码算法被提出来,比如整数线性规划等。这种情况下需要对子模型特征的丰富性以及联合解码的精确性之间做权衡:
一方面如果设计精确的联合解码算法,往往需要对特征进行限制,例如用条件随机场建模,使用维特比解码算法可以得到全局最优解,但是往往需要限制特征的阶数。
另一方面如果使用近似解码算法,比如集束搜索,在特征方面可以抽取任意阶的特征,但是解码得到的结果是不精确的。
因此,需要一个算法可以在不影响子模型特征丰富性的条件下加强子模型之间的交互。
此外,很多方法再进行实体抽取时并没有直接用到关系的信息,然而这种信息是很重要的。需要一个方法可以同时考虑一个句子中所有实体、实体与关系、关系与关系之间的交互。
- 参数共享的联合模型的loss是各个子过程的loss之和;
- 联合解码的联合模型中主体,客体和关系类型是在同一个步骤中进行识别然后得出


2.2 按解码方式分——基于序列标注的方案、基于指针网络和基于Span片段的方案
标注方案,指以什么样的方案描述实体和关系

2.2.1 基于序列标注的方案
序列标注简单的来说就是给定一个序列,对序列中的每一个元素做一个标记,或者说给每一个元素打一个标签,这是一个比较宽泛的概念。中文命名实体识别、中文分词和词性标注等这些基本的NLP任务都属于序列标注的范畴。
序列标注的方法中有多种标注方式:BIO、BIOSE、IOB、BILOU、BMEWO,其中前三种最为常见。各种标注方法大同小异。
- BIO 三位序列标注法(B-begin,I-inside,O-outside)
B-X代表实体X的开头
I-X代表实体X的中间或结尾
O代表不属于任何类型的
我 O
是 O
李 B-PER
果 I-PER
冻 I-PER
, O
我 O
爱 O
中 B-ORG
国 I-ORG
, O
我 O
来 O
自 O
四 B-LOC
川 I-LOC
。 O
- BIOES 四位序列标注法(B-begin,I-inside,O-outside,E-end,S-single)
B表示开始
I表示内部
O表示非实体
E表示实体尾部
S表示该词本身就是一个实体
我 O
是 O
李 B-PER
果 I-PER
冻 E-PER
, O
我 O
爱 O
中 B-LOC
国 E-LOC
, O
我 O
来 O
自 O
四 B-LOC
川 E-LOC
。 O
- BMES 四位序列标注法(B-begin,M-middle,E-end,S-single)
B表示一个词的词首位值
M表示一个词的中间位置
E表示一个词的末尾位置
S表示一个单独的字词
我 S
是 S
四 B
川 M
人 E
基于序列标注的解码方式通常会使用CRF作为解码器,使用结合BIO或者BIOES标签的联合标签,每个token标记一个tag标签。解码层的任务就是确定每个token的tag,CRF能够进行标签约束,解码效果比直接使用Softmax更好。
序列标注方法在命名实体识别任务中非常常用,但是在实体关系抽取任务中,序列标注有非常多的不足,很重要的一点是一个token只能有一个标签,而关系抽取任务情况复杂,存在实体重叠、关系重叠等诸多特殊情况,经常需要设计比较复杂的联合标签才能完成对实体关系三元组的抽取,然而标签越复杂,抽取效果就越差。因此最新的论文基本都不再采用这种方法。
下图中的句子使用了序列标注方法,采用BIO和实体类型联合标签,该方法只能确定“北京”这一个实体,而无法将另一个实体“北京德易东方转化医学研究中心”也一起表示出来。

2.2.2 基于指针网络
序列标注方法只有一个标签序列,表达能力较弱,不能解决实体重叠问题,因此有人提出使用MRC机器阅读理解中大量使用的指针网络来对关系抽取中的输入句子进行标注,使用多个标签序列(多层label网络)来表示一个句子。对每个span的start和end进行标记,对于多片段抽取问题转化为N个2分类(N为序列长度),如果涉及多类别可以转化为层叠式指针标注(C个指针网络,C为类别总数)。事实上,指针标注已经成为统一实体、关系、事件抽取的一个“大杀器”。
如下图所示,该指针网络采用了两个标签序列,一个表示实体的起始位置,另一个表示实体的结束位置。在解码时使用Sigmoid代替Softmax,预测每个token对应的标签是0还是1。由于指针网络的表达能力较强,可以很好地解决实体-关系重叠等问题,所以在目前的实体关系抽取方法中被大量使用。虽然指针网络是一个比较好的方案,但是在指针网络的使用过程中很可能会遇到标签不平衡问题,需要进行一些调参工作。

多层label指针网络。由于只使用单层指针网络时,无法抽取多类型的实体,我们可以构建多层指针网络,每一层都对应一个实体类型
2.2.3 基于Span片段的方案
源于Span-level NER的思想,枚举所有可能的span进行分类,同序列长度进行解耦,可以更加灵活地处理复杂抽取和低资源问题。事实上,片段排列的思想已经被Google推崇并统一了信息抽取各个子任务。
片段分类方法和上述两方法有较大的差异,片段分类方法找出所有可能的片段组合,然后针对每一个片段组合求其是否是实体的概率。如下图所示,针对一个句子,片段排序方法从开始位置起依次选取一个token,两个token……,组成实体可能的片段,然后求该片段是否是实体的概率。
在确定所有的实体之后,对所有实体两两配对,然后求每一对实体对之间存在关系的概率。例如,如果有N个实体,M种关系,那么存在N × N个实体对(实体对是有序的),需要求N × N × M个概率,来判断每个实体对之间的关系。
如果文本过长,片段分类会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。

2.3 样本获取难的解决办法——远程监督、few shot
有监督和无监督,懂得都懂。一个很平常,一个效果很差。

半监督
半监督学习的算法主要有两种:Bootstrapping和Distant Supervision。
Bootstrapping不需要标注好实体和关系的句子作为训练集,不用训练分类器;
Distant Supervision可以看做是Bootstrapping和Supervise Learning的结合,需要训练分类器。
Bootstrapping
Bootstrapping算法的输入是拥有某种关系的少量实体对,作为种子,输出是更多拥有这种关系的实体对。敲黑板!不是找到更多的关系,而是发现拥有某种关系的更多新实体对。
怎么做的呢?举个栗子,“创始人”是一种关系,如果我们已经有了一个小型知识图谱,里面有3个表达这种关系的实体对:(严定贵,你我贷),(马云,阿里巴巴),(雷军,小米)。
需要以下四步:
- 在一个大型的语料集中去找包含某一实体对(3个中的任意1个)的句子,全部挑出来。比如:严定贵于2011年创立了你我贷;严定贵是你我贷的创始人;在严定贵董事长的带领下,嘉银金科赴美上市成功。
- 归纳实体对的前后或中间的词语,构造特征模板。比如:A 创立了 B;A 是 B 的创始人;A 的带领下,B。
- 用特征模板去语料集中寻找更多的实体对,然后给所有找到的实体对打分排序,高于阈值的实体对就加入到知识图谱中,扩展现有的实体对。
- 回到第一步,进行迭代,得到更多模板,发现更多拥有该关系的实体对。
细心的小伙伴会发现,不是所有包含“严定贵”和“你我贷”的句子都表达了“创始人”这种关系啊,比如:“在严定贵董事长的带领下,嘉银金科赴美上市成功”——这句话就不是表达“创始人”这个关系的。某个实体对之间可能有很多种关系,哪能一口咬定就是知识图谱中已有的这种关系呢?这不是会得到错误的模板,然后在不断的迭代中放大错误吗?
没错,这个问题叫做语义漂移(Semantic Draft),一般有两种解决办法:
一是人工校验,在每一轮迭代中观察挑出来的句子,把不包含这种关系的句子剔除掉。
二是Bootstrapping算法本身有给新发现的模板和实体对打分,然后设定阈值,筛选出高质量的模板和实体对。具体的公式可以看《Speech and Language Processing》(第3版)第17章。
优缺点
Bootstrapping的缺点一是上面提到的语义漂移问题,二是查准率会不断降低而且查全率太低,因为这是一种迭代算法,每次迭代准确率都不可避免会降低,80%---->60%---->40%---->20%…。所以最后发现的新实体对,还需要人工校验。
远程监督(Distant supervision)
远程监督方法缺少人工标注数据集, 因此, 远程监督方法比有监督多一步远程对齐知识库给无标签数据打标的过程,而构建关系抽取模型的部分, 与有监督领域的流水线方法差别不大。
要介绍的论文是《Distant supervision for relation extraction without labeled data》,斯坦福大学出品,把远程监督的方法用于关系抽取。研究关系抽取的远程监督算法,不得不提这篇论文。
(一)远程监督的思想
远程监督算法有一个非常重要的假设:对于一个已有的知识图谱(论文用的Freebase)中的一个三元组(由一对实体和一个关系构成),假设外部文档库(论文用的Wikipedia)中任何包含这对实体的句子,在一定程度上都反映了这种关系。基于这个假设,远程监督算法可以基于一个标注好的小型知识图谱,给外部文档库中的句子标注关系标签,相当于做了样本的自动标注,因此是一种半监督的算法。
具体来说,在训练阶段,用命名实体识别工具,把训练语料库中句子的实体识别出来。如果多个句子包含了两个特定实体,而且这两个实体是Freebase中的实体对(对应有一种关系),那么基于远程监督的假设,认为这些句子都表达了这种关系。于是从这几个句子中提取文本特征,拼接成一个向量,作为这种关系的一个样本的特征向量,用于训练分类器。
论文中把Freebase的数据进行了处理,筛选出了94万个实体、102种关系和180万实体对。下面是实体对数量最多的23种关系。

关系种类相当于分类的类别,那么有102类;每种关系对应的所有实体对就是样本;从Wikipedia中所有包含某实体对的句子中抽取特征,拼接成这个样本的特征向量。最后训练LR多分类器,用One-vs-Rest,而不是softmax,也就是训练102个LR二分类器——把某种关系视为正类,把其他所有的关系视为负类。
因为远程监督算法可以使用大量无标签的数据,Freebase中的每一对实体在文档库中可能出现在多个句子中。从多个句子中抽出特征进行拼接,作为某个样本(实体对)的特征向量,有两个好处:
- 单独的某个句子可能仅仅包含了这个实体对,并没有表达Freebase中的关系,那么综合多个句子的信息,就可以消除噪音数据的影响。
- 可以从海量无标签的数据中获取更丰富的信息,提高分类器的准确率。
但是问题也来了,这个假设一听就不靠谱!哪能说一个实体对在Freebase中,然后只要句子中出现了这个实体对,就假定关系为Freebase中的这种关系呢?一个实体对之间的关系可能有很多啊,比如马云和阿里巴巴的关系,就有“董事长”、“工作”等关系,哪能断定就是“创始人”的关系呢?