完整源码 ≧ω≦
希望各位爸爸们,给我点赞吧
kokool/GCByGo: 《垃圾回收的算法与实现》有感而发 (github.com)
书接上文
我们之前不考虑分配与合并情况下,用GO实现GCMarkSweep(标记清除算法),而这次我们继续回顾书本内容的伪代码,修改之前写的内容。
伪代码
首先根据书本的描述,我们可以编写如下的大体的框架
合并阶段
可以看到新增的合并伪代码中,中村成洋作者认为我们的堆sweeping是无所不能的结构体,它还带有存放一个个地址位置的属性
而这属性还恰好能够匹配上free_list,相应的也影响了free_list中表示存放的空闲size的属性
方便了装8,但是费脑子。
之前的做法中设置数据结构的操作如下:
- 结构体数组
[HEAP_SIZE]Object实现了堆存放所有对象 - 变量地址形象地表示成
free_list链表
妥妥地在暗示我去修改它们成结构体,可是太复杂了主要是不会改 ,所以我最终选择把free_list改成数组,里面的元素表示为存放的chunk的index
var free_list []int
而因为堆涉及到删除和增加对象元素,再使用结构体数组并不方便,因此要变成结构体切片
//go的语法糖写法
var heap []Object
觉得能搞到这么多就行了,接着分配阶段。
sweep_phase(){
sweeping = $heap_start
while (sweeping < $heap_end)
if (sweeping.mark == TRUE)
sweeping.mark = FALSE
else
//合并
if (sweeping == $free_list + $free_list.size)
$free_list.size += sweeping.size
else
sweeping.next = $free_list
$free_list = sweeping
sweeping += sweeping.size
}
分配阶段
完全照着书本来,发现也没什么特别,就是不明白分配应该在哪里启动?pickup_chunk函数具体怎么操作的?
new_obj(size){
chunk = pickup_chunk(size, $free_list)
if (chunk != NULL)
return chunk
else
allocation_fail()
}
pickup_chunk(size, $free_list){
//First - fit策略:最初发现大于等于size 的分块时就会立即返回该分块。
for i in range($free_list)
if $free_list[i].size == size
return heap[i]
else if $free_list[i].size > size
//屏蔽具体的如何划分操作
allocate()
}
allocation_fail(){
return "抛出错误,没有找到合适的分块"
}
结果全篇下来就会实现allocation_fail()函数
GCMarkSweep\Considered\PKG\allocate.go
func allocation_fail() {
//暂时不知道怎么搞,先return
panic("all not-active object have not enough size")
}
具体实现
看到它这么喜欢加属性,而且也不清楚分配操作到底要干嘛的迷惑操作,正常人的思维都被绕进去了。
但是我哪是什么常人,因为人类终究是有极限的!!

创建对象
想了想,我干嘛要死磕,于是我选择了跳过,还真不是摆烂 ,后面发现了作者写的一段话。

OK,这句话就明确说明了所谓的分配其实就是创建数据->重写之前的数据初始化操作
相应的初始化数据集进行修改即可。
但是我的朋友,有些内容还是有遗漏,堆的对象数量都是我们一开始人为设置好的,我们应该是要想办法让它们根据堆的size来自己规划好最终对象的数量,但是又要考虑实现难度,于是就有了如下的小demo。
BASE_SPACE初步规定好的堆的空间BASE_NUM初步规定好的对象数量init_space统计所有初始化后对象的size
GCMarkSweep\Considered\PKG\create_data.go
func Init_data(BASE_NUM, BASE_SPACE int) {
for i := 0; i < BASE_NUM; i++ {
...
}
//对象指向的对象(活动对象)
//对象指向的对象(非活动对象)
//判断堆的初始化的空间够不够?
if BASE_SPACE < init_space {
panic("堆不够空间分配对象")
} else if BASE_SPACE > init_space { //最终剩下的空间用来新增一个对象
heap = append(heap, *NewObject("Data", nil, BASE_SPACE-init_space))
}
//roots指向的对象.
}
尽管还是人为定义了堆的空间,但是加了一定的约束条件,应该较符合作者的期望了,就当它可以吧。
GCMarkSweep\Considered\PKG\allocate.go
func newObject(node_type string, children []int, size int) *Object {
if node_type == "Null" {
if children == nil {
children = []int{-100}
}
} else {
//统计所有初始化用的size
init_space += size
if size <= 0 {
panic("分配不正确")
}
if children == nil {
children = []int{11}
}
}
return &Object{node_type: newNodeType(node_type), children: children, size: size, next_freeIndex: -100, marked: false}
}
分配操作
但是,所列娃多卡纳,我们创建的这不是分块chunk啊!

于是仔细想想,之前不考虑分配与合并操作中的代码,我们是认为那些最终都放在链表free_list都是chunk,它们具有的统一特征:
next_freeIndex表示上一个分块chunk的indexchildren中都为[]int{-1}表示被消除所以无关链表的指针和数据
而作者这里写的chunk跟我们上面表达的意思根本不一样,它的意思是在有空闲size的情况下,把上面的chunk变成object。这就是所谓的分配。

那么实现道路其实很清晰了,具体的修改如下
GCMarkSweep\Considered\PKG\allocate.go
func NewObject(node_type string, children []int, size int) *Object {
//free_list不为空时就表示已经初始化了数据,空间分配就那么多,就只能用这些还可以用的空间
if free_list != nil {
chunk := pickup_chunk(node_type, children, size, free_list)
if chunk != nil {
return chunk
} else {
allocation_fail()
}
} else {
object := newObject(node_type, children, size)
return object
}
return nil
}
好奇的你可能会疑问了,为什么讲了那么多,pickup_chunk函数还没有实现呢?
我知道你很急,但是你先别急
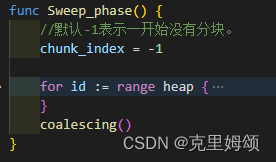
分配的前提是要有空闲分块->free_list不为空->free_list要经过sweep阶段才能诞生->sweep()新增了合并操作。
而pickup_chunk函数离不开free_list作为形参输入,所以我们接下来应该要实现合并操作才对。
合并操作
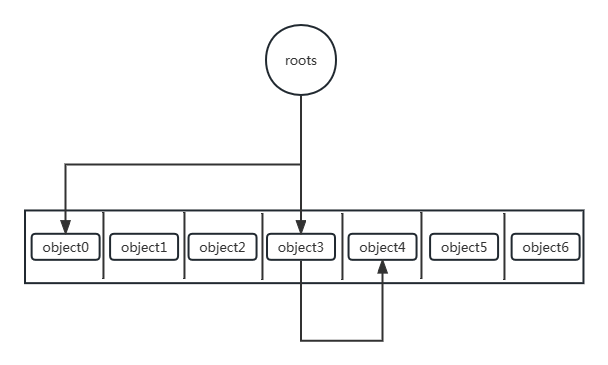
书本的伪代码认为heap应该是每次循环得到一个连续空闲的chunk时,我们都应该进行一次合并,把它们的size加在一起,把两个对象合二为一。
说白了就是删除object,但是已经选择结构体切片作为heap的数据结构,任何一次元素的修改和移动都会影响结果,所以我们应该要在生成完所有的chunk和装填chunk的free_list之后进行操作。
GCMarkSweep\Considered\PKG\mark_sweep.go
而合并分三步走
GCMarkSweep\Considered\PKG\coalese.go
func coalescing() {
//第一步:修改各对象的size,获取每次修改涉及到的两个对象的index,将它们变成区间
intervals := changeSize()
//第二步:合并区间操作
m := merge(intervals)
//第三步:利用切片和循环来合并成新的堆,更新成合并的新对象与free_list的next_freeIndex
newHeap(m)
}
第一步
利用计数器区分我们要保留的对象和最终要被删除的对象
func changeSize() [][]int {
var count int = 0
for index := range free_list {
if index != 0 {
i := free_list[index]
if free_list[index-1] == i-1 {
count++
heap[i-count].size += heap[i].size
intervals = append(intervals, []int{i - count, i})
} else {
count = 0
}
}
}
return intervals
}
第二步
复制黏贴直接拿别人的代码
//合并区间操作
//https://leetcode.cn/problems/merge-intervals/solution/shou-hua-tu-jie-56he-bing-qu-jian-by-xiao_ben_zhu/
func merge(intervals [][]int) [][]int {
sort.Slice(intervals, func(i, j int) bool {
return intervals[i][0] < intervals[j][0]
})
res := [][]int{}
prev := intervals[0]
for i := 1; i < len(intervals); i++ {
cur := intervals[i]
if prev[1] < cur[0] { // 没有一点重合
res = append(res, prev)
prev = cur
} else { // 有重合
prev[1] = max(prev[1], cur[1])
}
}
res = append(res, prev)
return res
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
第三步
利用切片删除对象的操作
func newHeap(m [][]int) {
//合并
var heap_copy []Object
for i := 0; i < len(m)-1; i++ {
hj := heap[:m[i][0]+1]
hk := heap[m[i][1]+1 : m[i+1][0]+1]
for j := range hj {
heap_copy = append(heap_copy, hj[j])
}
for k := range hk {
heap_copy = append(heap_copy, hk[k])
}
}
change_Index_list(heap_copy)
}
//更改next_freeIndex和更改free_list
func change_Index_list(heap_copy []Object) {
var list []int
var next_index int = -1
for i := range heap_copy {
if heap_copy[i].children[0] == -1 {
list = append(list, i)
heap_copy[i].next_freeIndex = next_index
next_index = i
}
}
heap = heap_copy
fmt.Println(heap)
free_list = list
fmt.Println(free_list)
}
你学废了嘛?

pickup_chunk函数
那么在清楚了free_list怎么来之后,就可以根据伪代码实现了
GCMarkSweep\Considered\PKG\allocate.go
func pickup_chunk(node_type string, children []int, needSize int, freeList []int) *Object {
// fmt.Println(needSize, freeList)
var heap_copy []Object
for i := range freeList {
index := freeList[i]
//刚刚好就直接返回这个对象
if heap[index].size == needSize {
return &heap[index]
//如果空间较大就要分块
} else if heap[index].size > needSize {
heap[index].size -= needSize
obj := *newObject(node_type, children, needSize)
//注意:不能利用切片append插入,否则引用传递,我指的是append(heap_copy,heap[:index],obj)这样的写法
for j := 0; j < index; j++ {
heap_copy = append(heap_copy, heap[j])
}
heap_copy = append(heap_copy, obj)
for k := index; k < len(heap); k++ {
heap_copy = append(heap_copy, heap[k])
}
change_Index_list(heap_copy)
return &heap[index]
}
}
return nil
}
图解演示
初始化
恭喜你读完了以上的废话,让我们到了最激动人心的演示过程,先创建数据集
func Init_data(BASE_NUM, BASE_SPACE int) {
for i := 0; i < BASE_NUM; i++ {
no := NewObject("Null", nil, 0)
heap = append(heap, *no)
}
//对象指向的对象(活动对象)
heap[0] = *NewObject("Data", []int{11}, 2)
// heap[3] = *newObject("Key", []int{5, 4}, 2)
heap[3] = *NewObject("Key", []int{4}, 2)
heap[4] = *NewObject("Data", []int{11}, 2)
//对象指向的对象(非活动对象)
heap[5] = *NewObject("Data", []int{11}, 2)
heap[1] = *NewObject("Data", []int{11}, 2)
heap[2] = *NewObject("Data", []int{11}, 2)
heap[6] = *NewObject("Data", []int{11}, 2)
//判断堆的初始化的空间够不够?
if BASE_SPACE < init_space {
panic("堆不够空间分配对象")
} else if BASE_SPACE > init_space { //最终剩下的空间用来新增一个对象
heap = append(heap, *NewObject("Data", nil, BASE_SPACE-init_space))
}
//roots指向的对象.
// roots = []int{1, 3}
roots = append(roots, 0)
roots = append(roots, 3)
// fmt.Println(heap)
// fmt.Printf("类型是%T\n", heap)
}
启动
func main() {
MSC.Init_data(7, 20)
fmt.Println("### init ###")
MSC.Print_data()
MSC.Mark_phase()
fmt.Println("### mark phase ###")
MSC.Print_data()
MSC.Sweep_phase()
fmt.Println("### sweep phase ###")
MSC.Print_data()
//测试分配
_ = MSC.NewObject("Data", []int{22}, 6)
}
约束
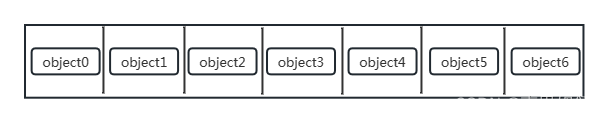
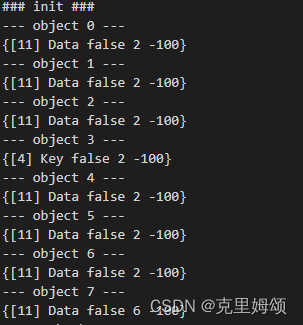
设定初始对象数量为7个,空间size有20大小
图像表示如下
可以看到了object7是新生成的,它的size大小为6,即BASE_SPACE-init_size,具体数值是20-14=6
mark
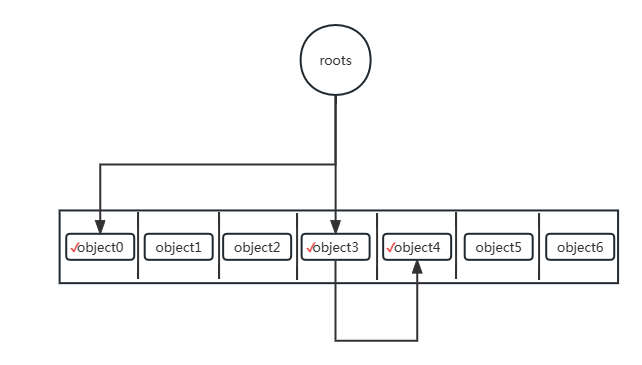
该打勾的地方都打勾了
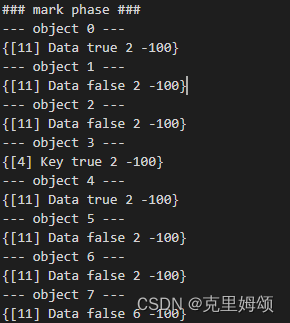
sweep
可以看到我们的对象最终减少到它应有的最少数量,size的大小也是相邻合并,而且next_freeIndex并没有出错,这也同时体现在存放chunk_index的free_list上
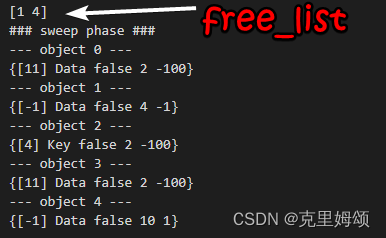
allocate
策略是:
heap的size刚刚好等于自己新增的对象就直接返回- 大于就新增一个分块
白框的对象就表示成chunk变成了active object了

致谢
感谢您的耐心观看,如果有什么不懂可以在评论区评论(当然我不一定会回答,纯粹就是因为我菜而已)
考虑
没测试过大量的数据集,所以有可能会存在问题,希望细心的读者可以帮忙发现吧。
参考
[1] 《垃圾回收的算法与实现》
[2] https://leetcode.cn/problems/merge-intervals/solution/shou-hua-tu-jie-56he-bing-qu-jian-by-xiao_ben_zhu/
[3] https://www.perfcode.com/p/golang-struct-slice-pointer.html