一、kafka的架构
Kafka是一个分布式、多分区、基于发布/订阅模式的消息队列(Message Queue),具有可扩展和高吞吐率的特点。

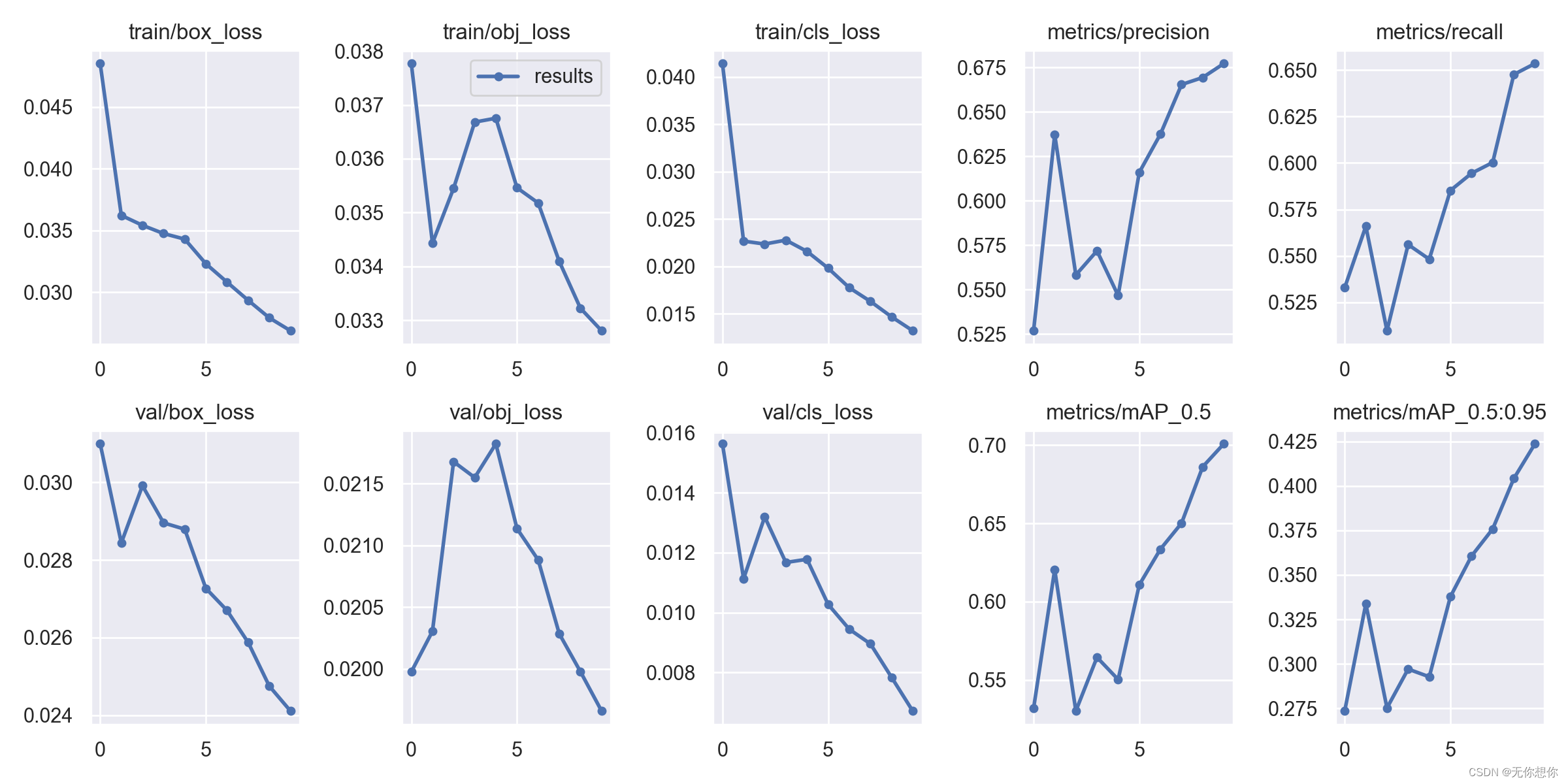
kafka中大致包含以下部分:
- Producer: 消息生产者,向 Kafka Broker 发消息的客户端。
- Consumer:消息消费者,从 Kafka Broker 取消息的客户端。
- Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 机器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic。
- Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic。
- Partition:为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker (即服务器)上,一个 Topic 可以分为多个 Partition,每个 Partition 是一个 有序的队列。
- Replica:副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
- Leader:每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。
- Follower:每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader。
- Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
- Zookeeper:Kafka 集群能够正常工作,需要依赖于 Zookeeper,Zookeeper 帮助 Kafka 存储和管理集群信息。
二、性能指标

评价一个服务的好坏可以通过看它能否满足高可用、高性能、高并发。
2.1 高性能
高性能(High Performance)指的是程序处理速度快、耗能少。与性能相关的一些指标如下:
- 响应时间:系统对请求做出响应的时间。例如系统处理一个 HTTP 请求需要 200ms,这个 200ms 就是系统的响应时间。
- 吞吐量:单位时间内处理的请求数量。
- TPS:每秒响应事务数。
- 并发用户数:同时承载能正常使用系统功能的用户数量。
高并发和高性能是紧密相关的,提高应用的性能,可以提高系统的并发能力。应用性能优化时,对于计算密集型和 I/O 密集型还是有很大差别,需要分开来考虑。
2.2 高可用
高可用性(High Availability)主要目的是为了保障「业务的连续性」,即在用户眼里,业务基本是正常对外提供服务的。
三、kafka的高可用设计
3.1 选举机制
kafka中的选举大致分为2类:控制器的选举、Leader的选举。
3.1.1 控制器选举
在Kafka集群中有多个broker,那么就有一个broker会被选举为控制器,这个控制器的主要责任包括监听Broker的变化、监听Topic变化、监听Partition变化、获取和管理Broker、Topic、Partition的信息、管理Partition的主从信息。同时还会负责副本的选举,当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。再比如当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
前面我们有提起过Zookeeper,控制器的选举是由Zookeeper(协调框架)的节点的唯一性来做到的。控制器的选举过程如下:
- 第一个启动的节点会在ZooKeeper里创建一个临时节点/controller,并写入该节点的注册信息,该节点成为控制器
- 其他节点在陆续启动过程中,也会尝试去ZooKeeper中创建/controller节点,如果/controller已存在则会报错,利用ZooKeeper的节点特性来保证控制器的唯一
- 其他节点启动后,会在控制器上注册相应的监听器,各个监听器负责监听各自代理节点的状态变化,当监听的节点状态发生变化时,会触发相应的监听函数
3.1.2 分区leader选举
Kafka是一个多分区,多副本的消息服务,那么每个分区的多副本由一个leader与多个follower构成。而leader负责进行数据读写,并且管理着整个follower中存储的数据状态。若某一时刻该分区leader挂掉了,Broker控制器就会对该分区进行重新选举案leader副本,其中leader的诞生只能从ISR列表中产生。
具体的选举规则:Kafka会在Zookeeper上针对每个Topic维护一个称为ISR副本的的集合,一旦Leader分区丢掉,从中随机挑选一个副本做新的Leader分区。如果ISR中的副本都宕机了,则:
- 等待ISR中的副本任何一个恢复,接着对外提供服务,需要时间等待。可以保证一致性,但可能需要很长时间
- 从OSR中选一个做Leader,需设置unclean.leader.election.enable=true,不需要等待,则很可能该副本并不一致。 当宕机的重新恢复时,会把之前commit的数据清空,重新从leader里pull数据。
3.2 多副本机制

在Kafka中,一个主题被划分为若干个分区,一个分区包含一个或多个副本,副本对应着消息存储的日志文件。副本机制就是通过对分区数据的冗余处理,即在不同的broker节点中存储多个副本,来实现Kafka的故障转移,从而提升可靠性。kafka的每个分区都有一个ISR列表,用于维护所有同步的、可用的副本。其中,Leader副本必是同步副本,而对于Follower副本来说,需要满足以下条件才能被认为是同步副本:
- 必须定时向ZooKeeper发送心跳
- 在规定的时间内从Leader副本“低延迟”的获取的消息
如果副本不满足上面条件的话,就会从ISR列表中移除,直到满足条件才会被再次加入。replica.lag.time.max.ms 这个参数值表示Follower副本能够落后Leader副本的最长时间间隔,当前默认值为10s,即只要一个Follower副本落后Leader副本的时间不连续超过10s, kafka就认为两者是同步的。
3.3 ACK确认机制
Kafka的Producer有三种ack机制,参数值有0、1 和 -1
- acks = 0: 相当于异步操作,Producer 不需要Leader给予回复,发送完就认为成功,继续发送下一条消息。这个机制下延迟最低,但是持久性可靠性也最差,当服务器发生故障时,很可能发生数据丢失。
- acks = 1: Kafka 默认的设置。表示 Producer 要 Leader 确认已成功接收数据才发送下一条消息。不过如果Leader宕机且Follower 尚未复制这部分数据的情况下,数据就会丢失。这个机制提供了比较好的持久性和较低的延迟性。
- acks = -1: Leader 接收到消息之后,还必须要求ISR列表里的那些Follower都确认消息已同步,Producer 才发送下一条消息。此机制持久性可靠性最好,但延时性最差。
四、kafka的高性能设计
Reactor多路复用
Kafka SocketServer 是基于Java NIO 开发的,采用了 Reactor 的模式,包含三种角色:Acceptor;Processor;Handler。Kafka Reactor包含一个Acceptor负责接收客户端请求,N个Processor线程负责读写数据(即即为每个 Connection 创建出一个 Processor 去单独处理,每个Processor中均引用独立的Selector),M个Handler来处理业务逻辑。在Acceptor和Processor,Processor和Handler之间都有队列来缓冲请求。
页缓存技术
操作系统本身有一层缓存叫做页缓存(Page Cache),是操作系统自己管理的内存缓存。页缓存是位于内存和文件之间的缓冲区,它实际上也是一块内存区域,所有的文件IO(包括网络文件)都是直接和页缓存交互,操作系统通过一系列的数据结构,比如inode, address_space, struct page,实现将一个文件映射到页的级别,这些具体数据结构及之间的关系我们暂且不讨论,只需知道页缓存的存在以及它在文件IO中扮演着重要角色,很大一部分程度上,文件读写的优化就是对页缓存使用的优化。
Kafka 在写入磁盘文件的时候,可以直接写入到页缓存里,由操作系统负责将页缓存里的数据刷入到磁盘文件中,这样消息写入就变成了写内存而不是写磁盘,大大提高了kafka写的性能。
零拷贝技术
在消费的时候kafka从磁盘文件上读取数据然后发送给下游的消费者,其数据流转为:
磁盘 -> os cache -> 应用进程缓存 -> socket缓存 -> 网卡 -> 消费者
可以看出来,从os cache 拷贝数据到应用进程缓存, 接着从应用进程缓存拷贝到操作系统的socket缓存这两步是没必要的,期间发生了好几次上下文切换,比较消耗性能。kafka为了解决这个问题,在读取数据的时候引入了零拷贝技术,即让操作系统的 os cache 中的数据直接发送到网卡后传出给下游的消费者,中间跳过了两次拷贝数据的步骤,减少了上下文的切换。其中,Socket缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到Socket缓存。
kafka主要使用到了mmap和sendfile的方式实现了零拷贝。

压缩传输
压缩有助于提高吞吐量,降低延迟并提高磁盘利用率。在 Kafka 中, 压缩可能会发生在两个地方: 生产者端和Broker端, 一句话总结下压缩和解压缩, 即 Producer 端压缩, Broker 端保持, Consumer 端解压缩。
Producer、Broker、Consumer 要使用相同的压缩算法, 在 Producer 向 Broker 写入数据, Consumer 向 Broker 读取数据的时候可以不用解压缩, 只需要在最终 Consumer 到消息的时候才进行解压缩, 这样可以节省大量的网络和磁盘开销。
数据顺序写入
kafka写入数据的时候,会将数据追加到文件的末尾,而不是在文件的随机位置。追加到文件末尾的写法可以大大提升数据写入磁盘的速度。
批处理设计
kafka在0.8版本之后, 进行了简单的改进, 性能得到了指数级上升,即来了一条消息后不会立马发送出去, 而是先写入到一个缓存(RecordAccumulator)队列中,封装成一个个批次(RecordBatch)。这个时候会有一个sender线程会将多个批次封装成一个请求(Request), 然后进行发送, 这样会减少很多请求,提高吞吐量。
内存池设计
Kafka是一个分布式的消息队列系统,它通过内存池(Memory Pool)来管理内存,提高内存的利用率和系统的性能。Kafka的内存池设计如下:
- 内存池的基本单位是chunk,chunk是一个连续的内存块。
- 内存池中维护了一个chunk列表,每个chunk都有一个状态(free、allocated、deallocated),表示该chunk当前的使用状态。
- 当Kafka需要分配内存时,会先在chunk列表中查找一个状态为free的chunk,如果找到了就将其分配出去。
- 如果没有找到状态为free的chunk,Kafka会尝试从操作系统申请一定数量的内存,并将其分成多个chunk,加入chunk列表中,并将其中一个chunk分配出去。
- 当chunk被释放时,它的状态会变成deallocated,但是并不会立即释放内存,而是等到内存池中的chunk数量超过一定阈值时才会进行一次批量内存释放。
- 这种设计可以避免频繁的内存分配和释放操作,提高内存利用率和系统性能。同时,由于chunk是固定大小的,可以减少内存碎片的产生,提高内存分配的效率。


![IO多路复用--[select | poll | epoll | Reactor]](https://img-blog.csdnimg.cn/0eb85dc013b048beb35a9c3dec6e9618.png)