简介:真实从0到1,童叟无欺~
目标:用python批量下载某站搜索视频,以“CG 服装”为例
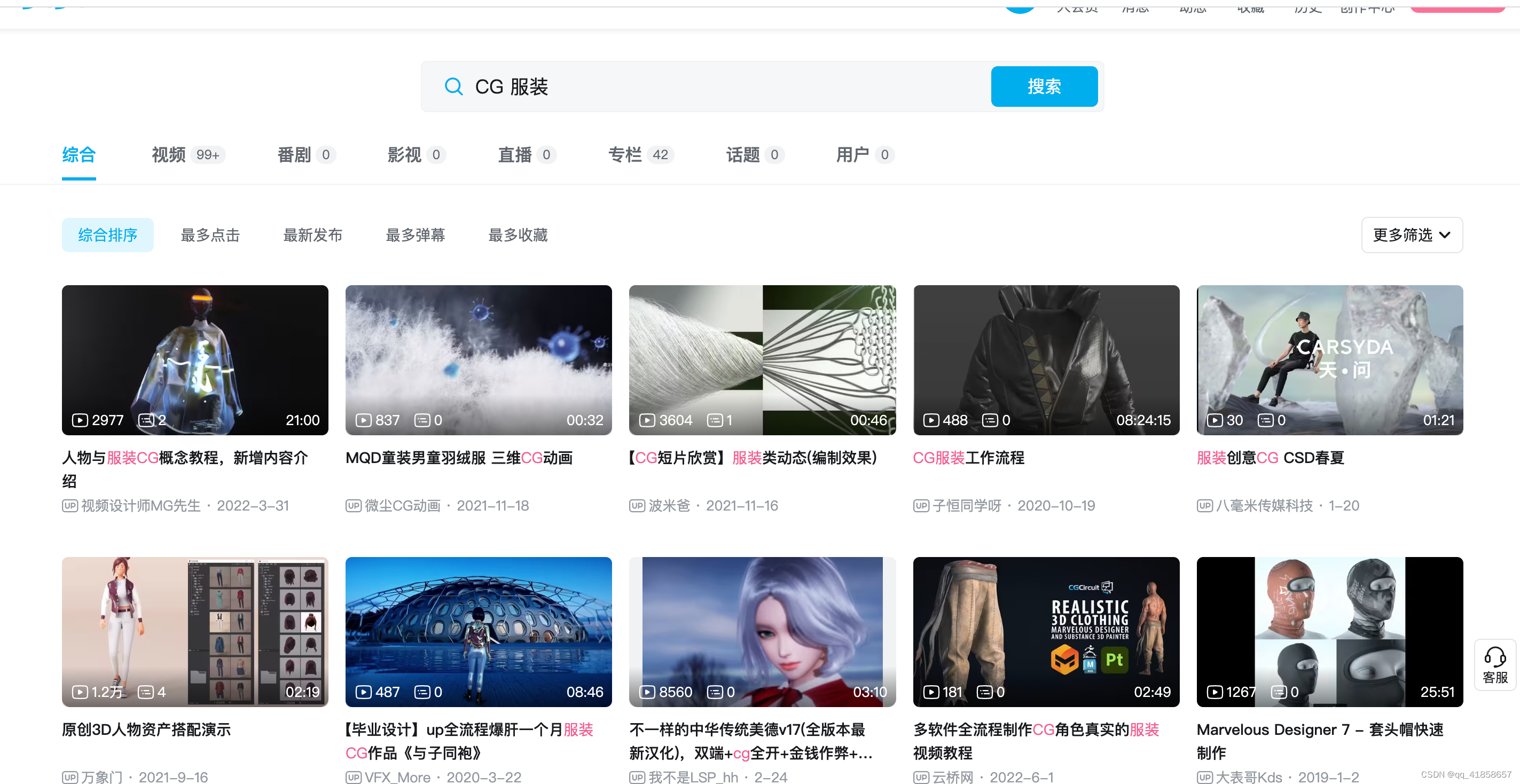
本章主要介绍如何用python把搜索到的视频直接下载到自己的本地文件夹中~
介绍一下工作流
- 1. 下载并安装python
- 2. 测试python是否安装成功
- 3. 打开jupyter notebook开始工作
- 3.1 批量获取想要下载的视频链接
- 3. 2 将这些视频批量下载到本地文件夹中
1. 下载并安装python
这里推荐并介绍下载anaconda,为什么要下载Anaconda呢,Anaconda和Python是什么关系呢~
Anaconda和Python相当于是汽车和发动机的关系,你安装Anaconda后,就像买了一台车,无需你自己安装发动机和其他零配件,而Python作为发动机提供Anaconda工作所需的内核。

简单来说,你可以把Anaconda看做成Python在数据科学领域的瑞士军刀,什么都给你安排好了,就等你下载安装。
指路下载链接与下载安装教程:
复制网址,进入anaconda官网:https://www.anaconda.com/
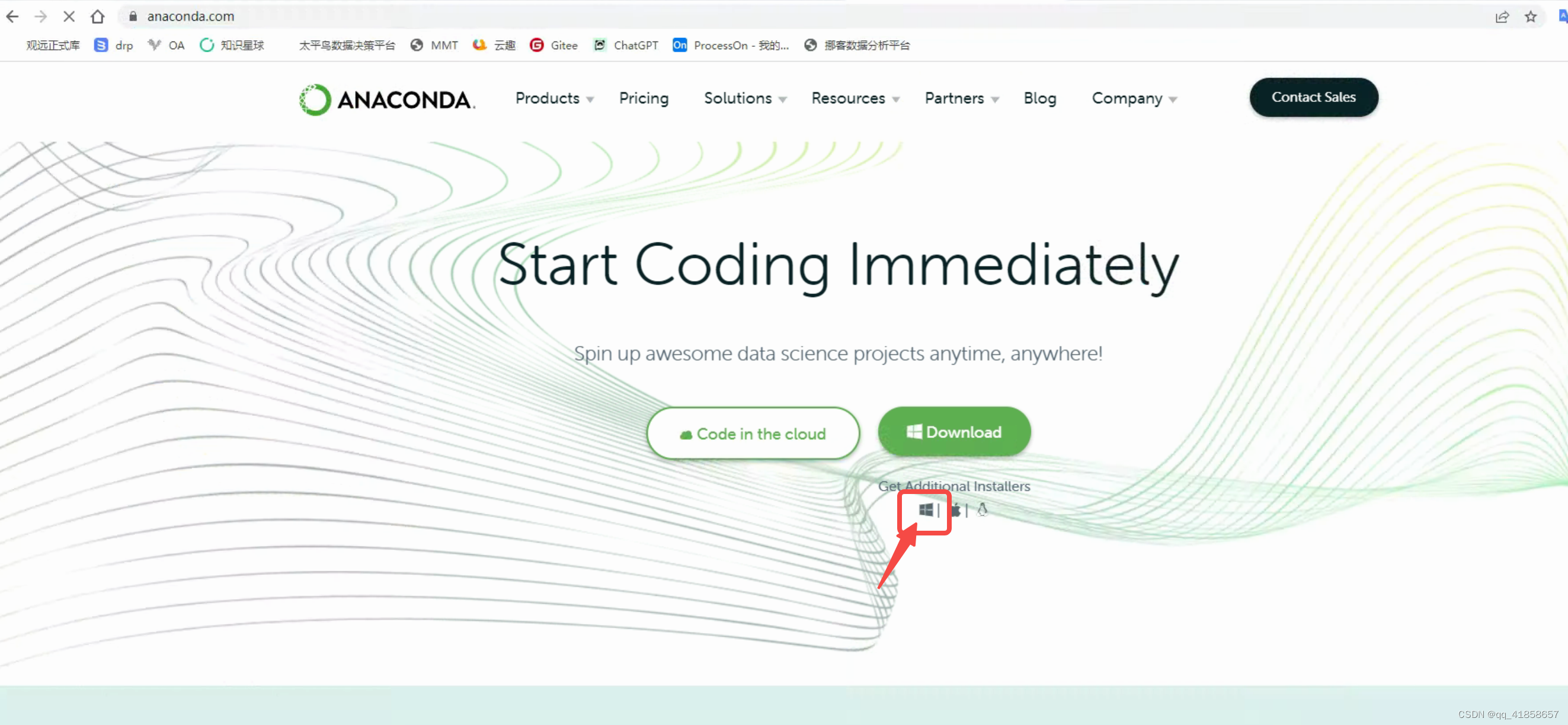
点击箭头指向位置,进入以下页面
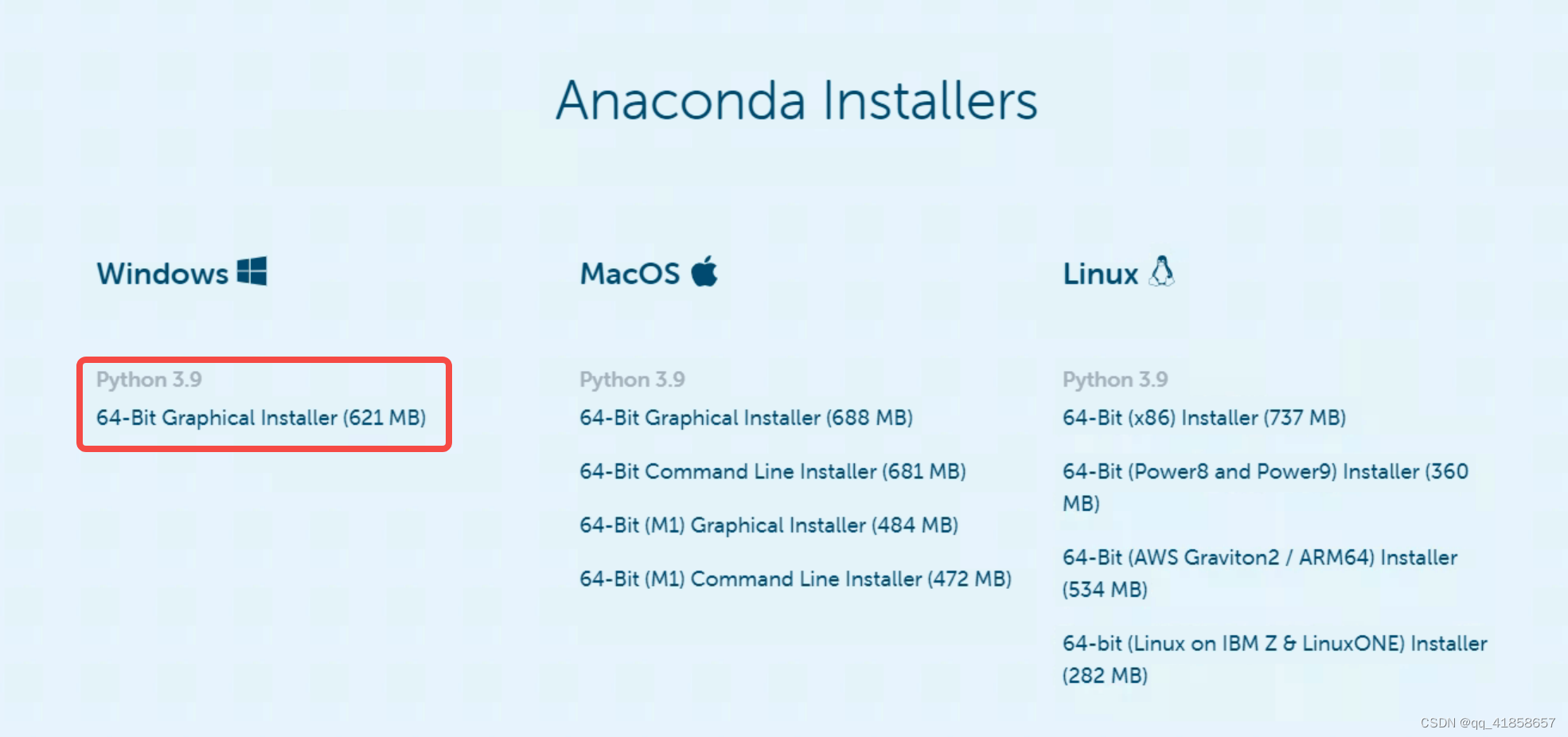
点击此处开始下载(也有朋友推荐不下载最新版本的,个人习惯使用最新版本的~)
下载好后按照以下教程一步一步操作,直到finish:
https://blog.csdn.net/baidu_22225919/article/details/82957508
2. 测试python是否安装成功
回到主页,按键win+R或者直接搜索cmd,打开命令提示符
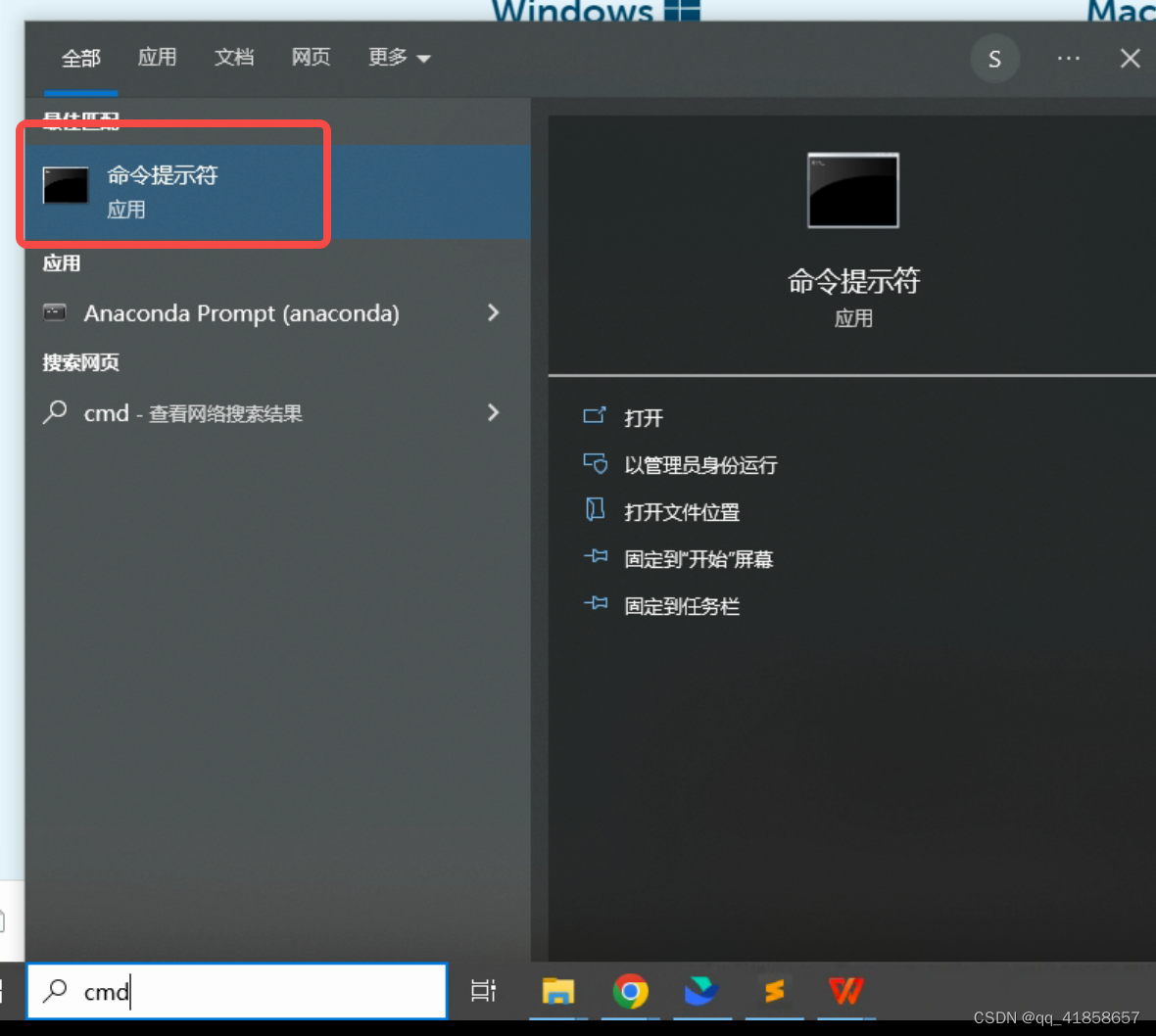
输出python并按回车,如下显示表示下载成功
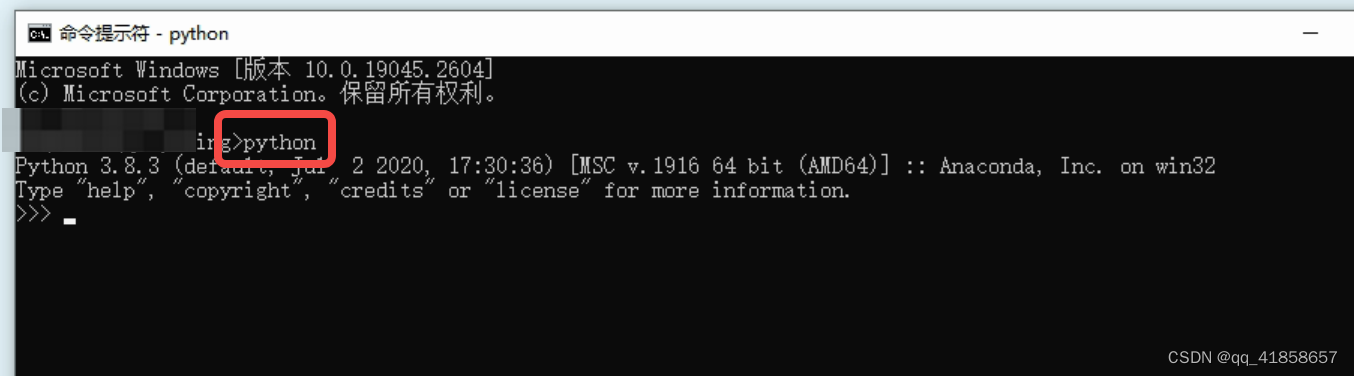
然后输入quit()退出
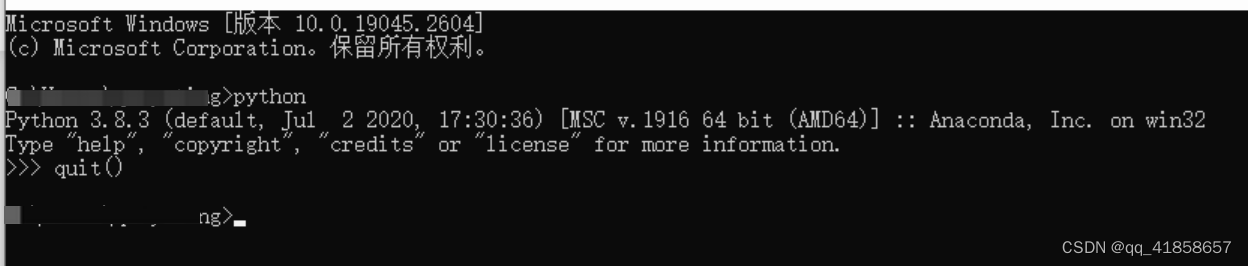 停留在这个页面不要关掉,稍后还会用到~
停留在这个页面不要关掉,稍后还会用到~
3. 打开jupyter notebook开始工作
科普:那jupyter notebook又是什么呢?
简单来说,是一个编程工具,用来做python等语言的编程工作。代码可以写一行运行一行,出现错误修改非常方便,无需从头再来一次,很适合初学者或者教学使用。
当你下载好了anaconda就自带了这个编程工具,直接搜索它就好啦~
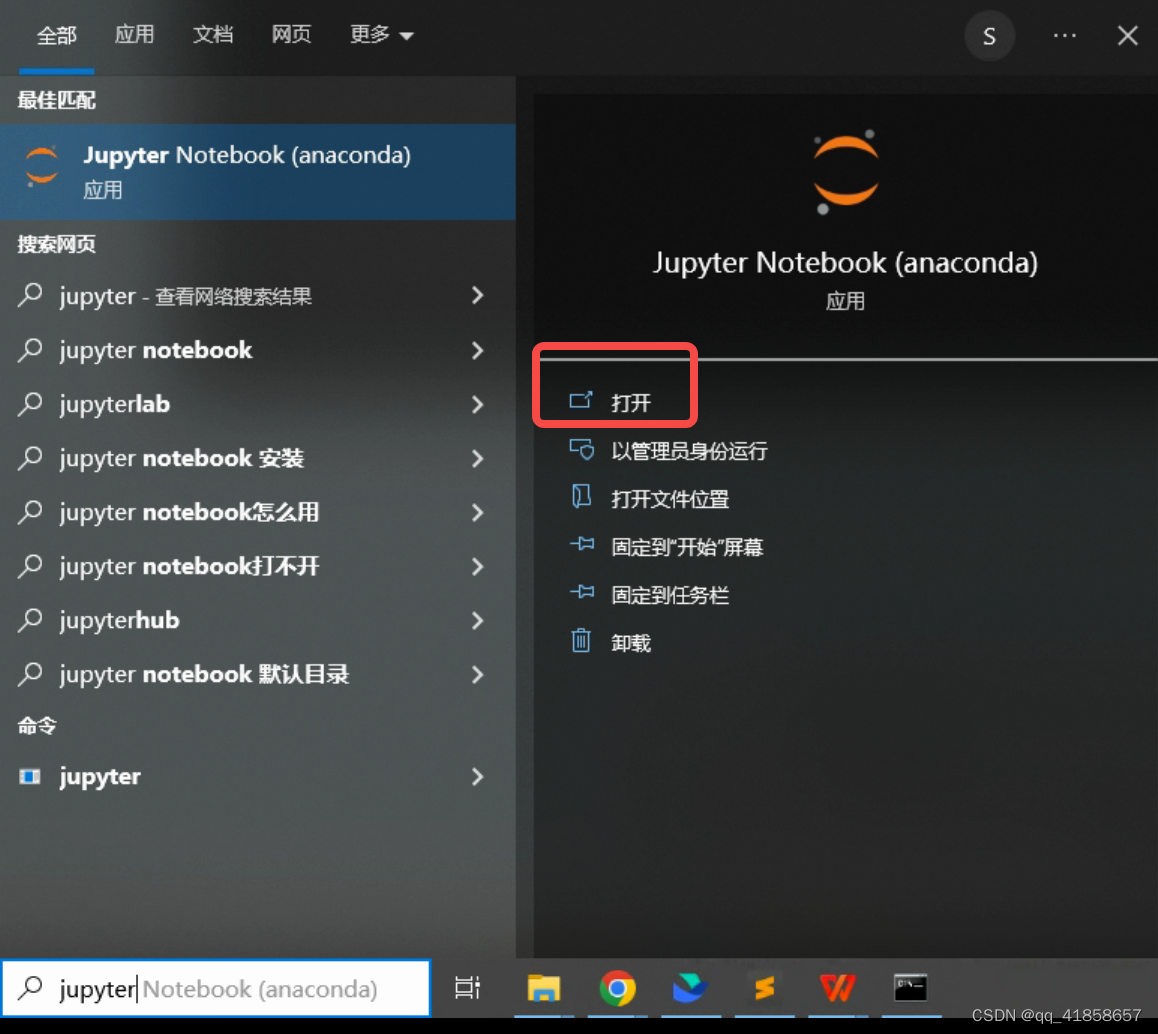
打开网页以后,可以新建自己的文件夹或者直接新建写代码的页面,这里我们就痛快直接开始~
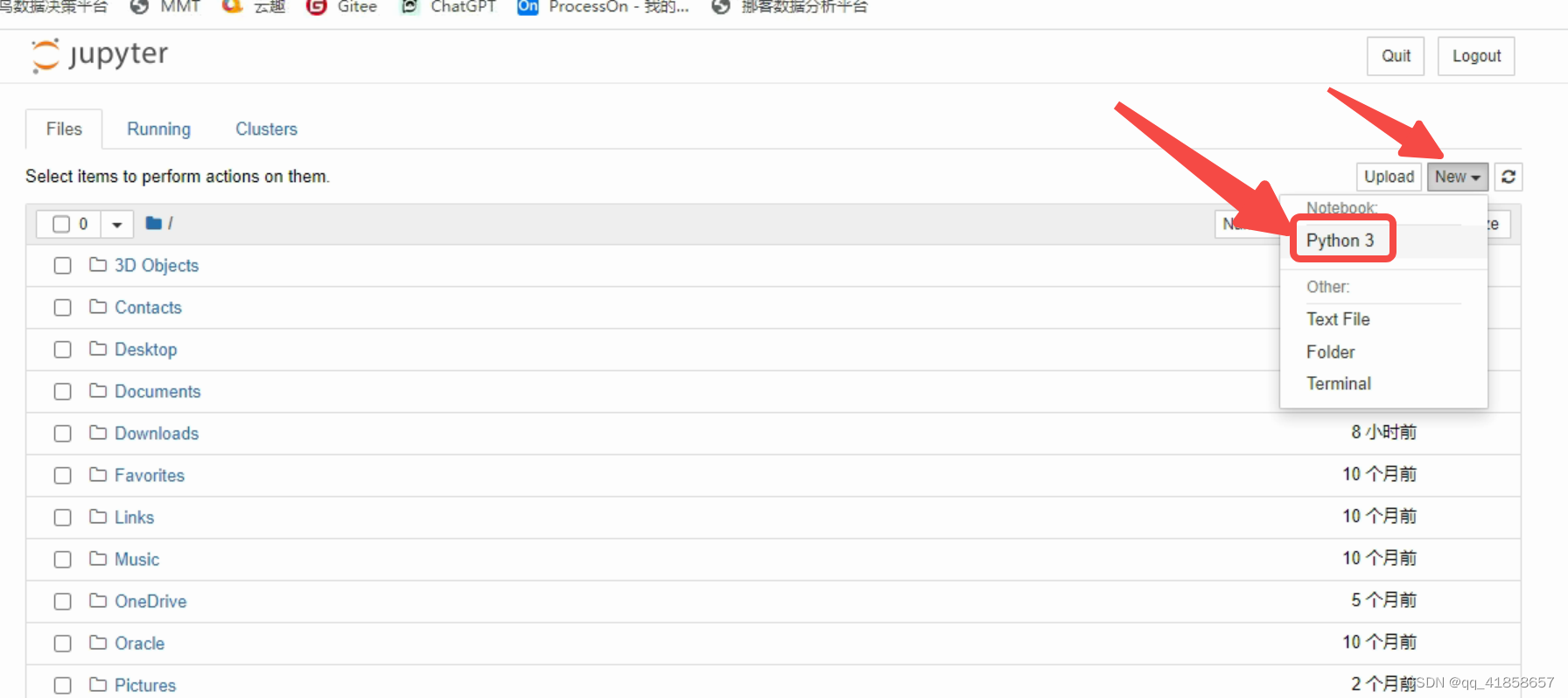
进入后的页面如下所示:
3.1 批量获取想要下载的视频链接
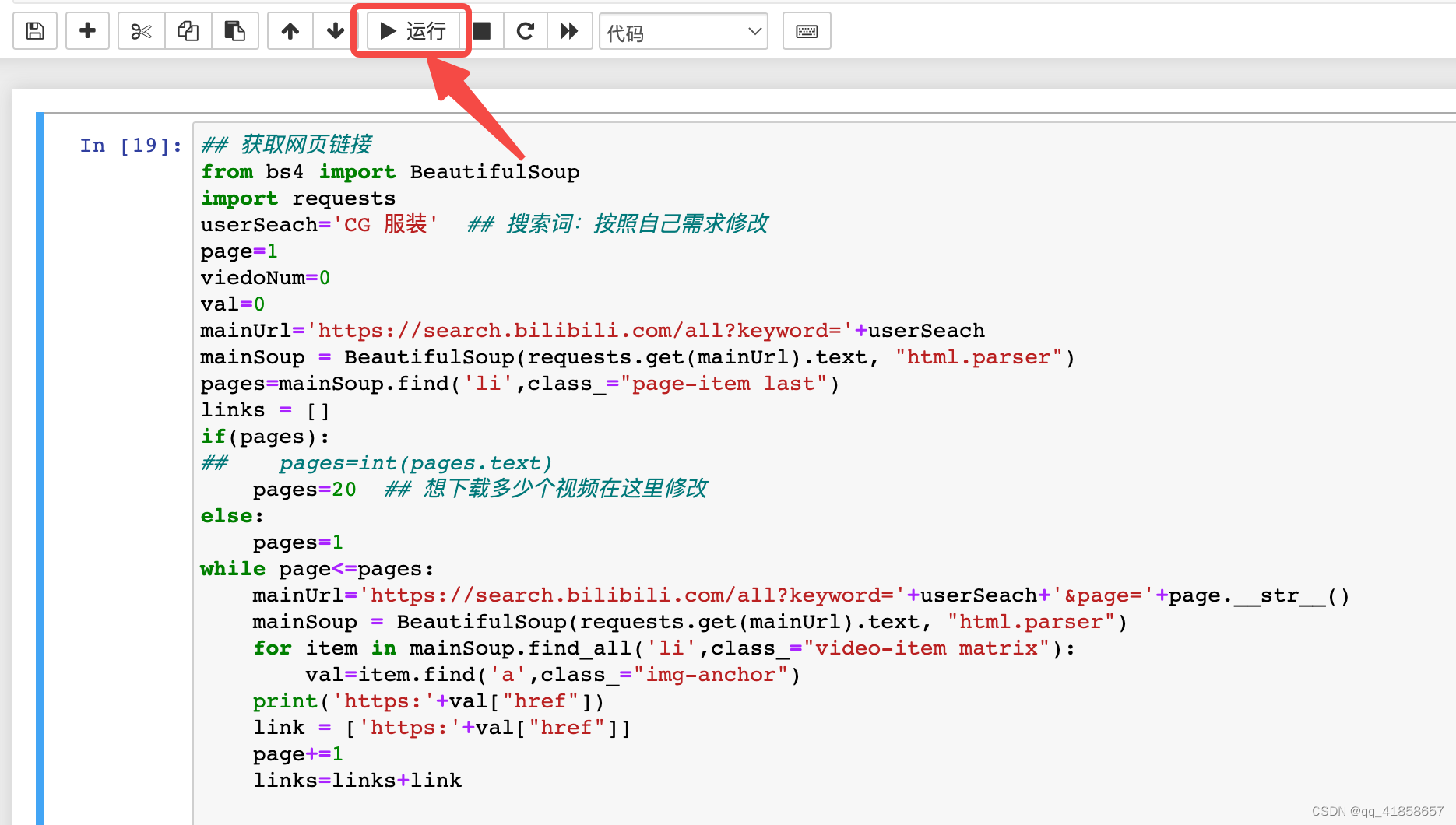
然后开动!将以下代码复制进去
## 获取网页链接
from bs4 import BeautifulSoup
import requests
userSeach='CG 服装'。## 搜索内容,按自己需求来
page=1
viedoNum=0
val=0
mainUrl='https://search.bilibili.com/all?keyword='+userSeach
mainSoup = BeautifulSoup(requests.get(mainUrl).text, "html.parser")
pages=mainSoup.find('li',class_="page-item last")
links = []
if(pages):
## pages=int(pages.text)
pages=1 ## 想要下载的页数,按自己需求来
else:
pages=1
while page<=pages:
mainUrl='https://search.bilibili.com/all?keyword='+userSeach+'&page='+page.__str__()
mainSoup = BeautifulSoup(requests.get(mainUrl).text, "html.parser")
for item in mainSoup.find_all('li',class_="video-item matrix"):
viedoNum += 1
print('第'+ viedoNum.__str__() + '个视频:')
val=item.find('a',class_="img-anchor")
print('视频标题:'+ val["title"])
print('https:'+val["href"])
link = ['https:'+val["href"]]
print('视频链接:'+'https:'+val["href"])
print('视频简介:'+item.find('div',class_="des hide").text.strip())
print('up主:'+ item.find('a',class_="up-name").text.strip())
print('视频观看量:'+ item.find('span',title='观看').text.strip())
print('弹幕量:'+ item.find('span',title='弹幕').text.strip())
print('上传时间:'+ item.find('span',title='上传时间').text.strip())
subUrl=val["href"];
subSoup = BeautifulSoup(requests.get('https:'+subUrl).text.strip(), "html.parser")
print('视频图片:'+subSoup.find(itemprop="image")["content"])
links=links+link
page+=1
然后在这个框格处按运行即可
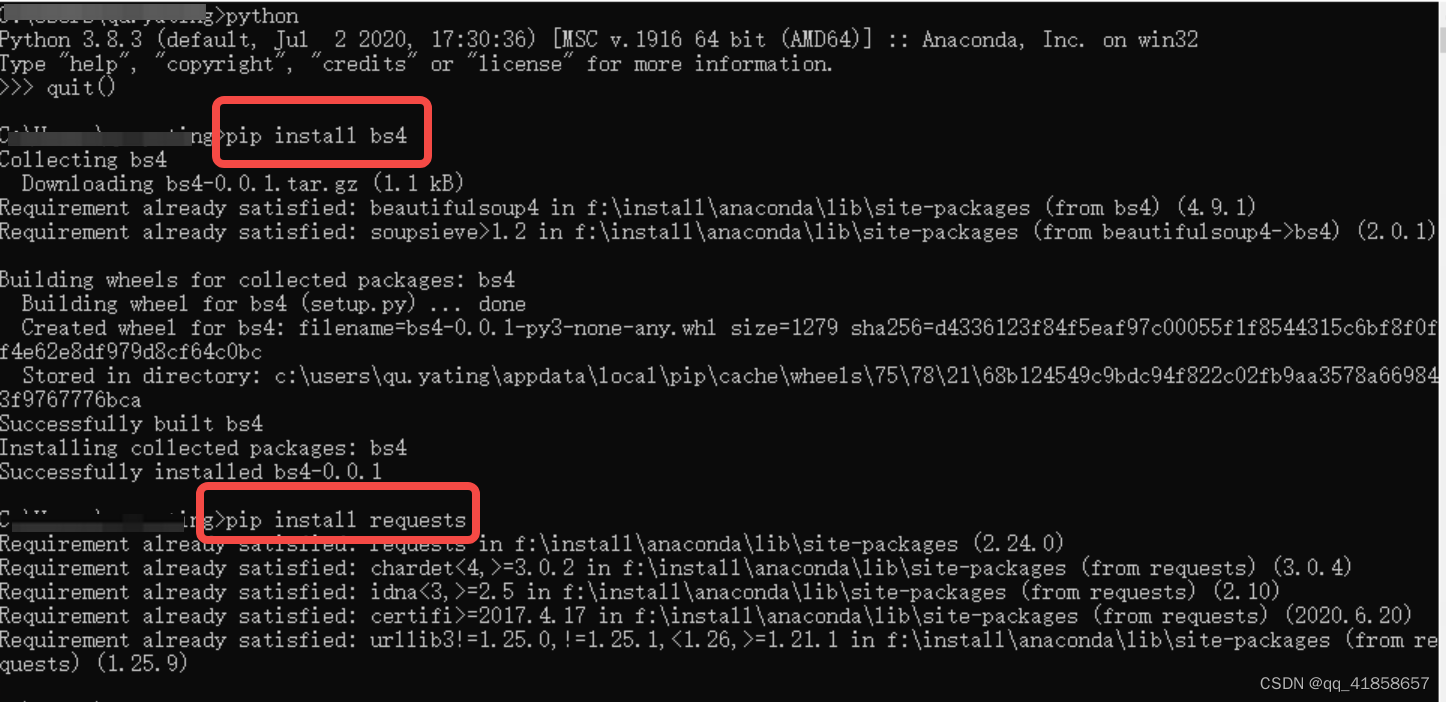
⚠️注意,这里第一次运行会报错,python中常常会调用写好的包方便我们用简单的代码就可以变成,这里是因为第一行用到的bs4包和第二行用到的requests包没有加载进来,再返回刚刚的命令提示符页面中,将这两个包加载进来
依次输出这两个红框中的内容,等待他们运行完成,再回来按一次运行,即可得到以下结果
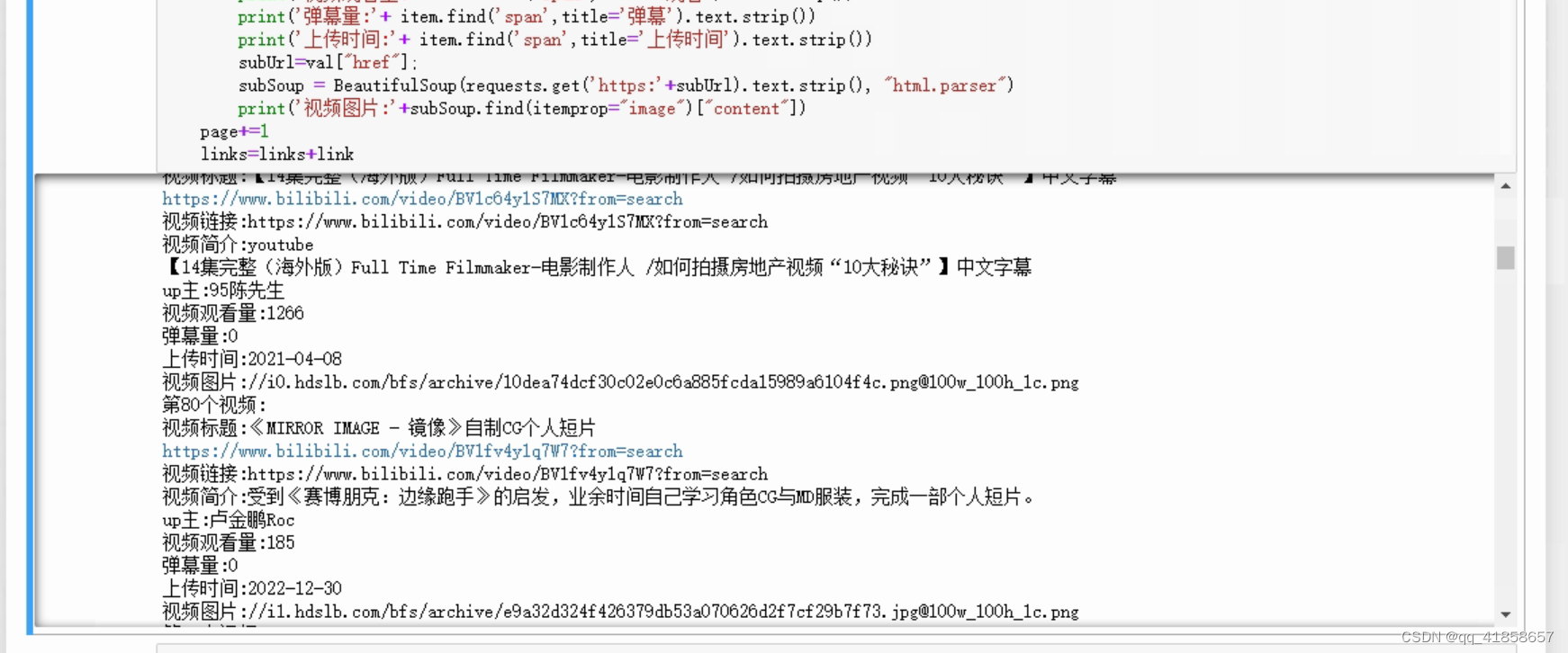
可以根据内容判断是不是自己想要的,然后再进行下一步操作
3. 2 将这些视频批量下载到本地文件夹中
跟上面一样,先把这个厉害的包下载进来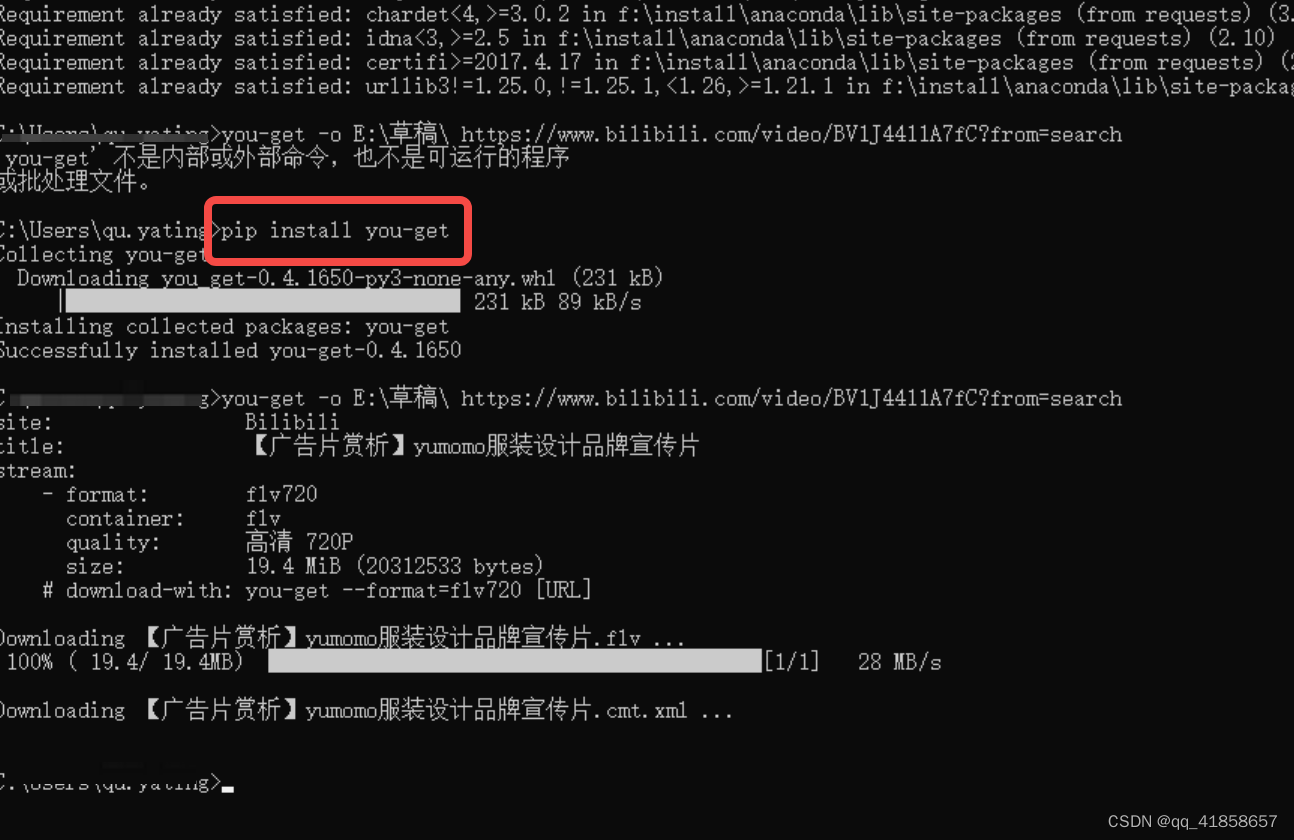
然后将以下的代码复制到第二个框框里,先在D盘新建一个video文件夹(不建也可以,它是个成熟的程序,会自己建的),然后运行:
import os
for link in links:
print('you-get -o d:/vedio/ '+link)
os.system('you-get -o d:/vedio/ '+link)
找到下面那个图标位置,点开当前页面,你就会发现视频已经在下载啦~
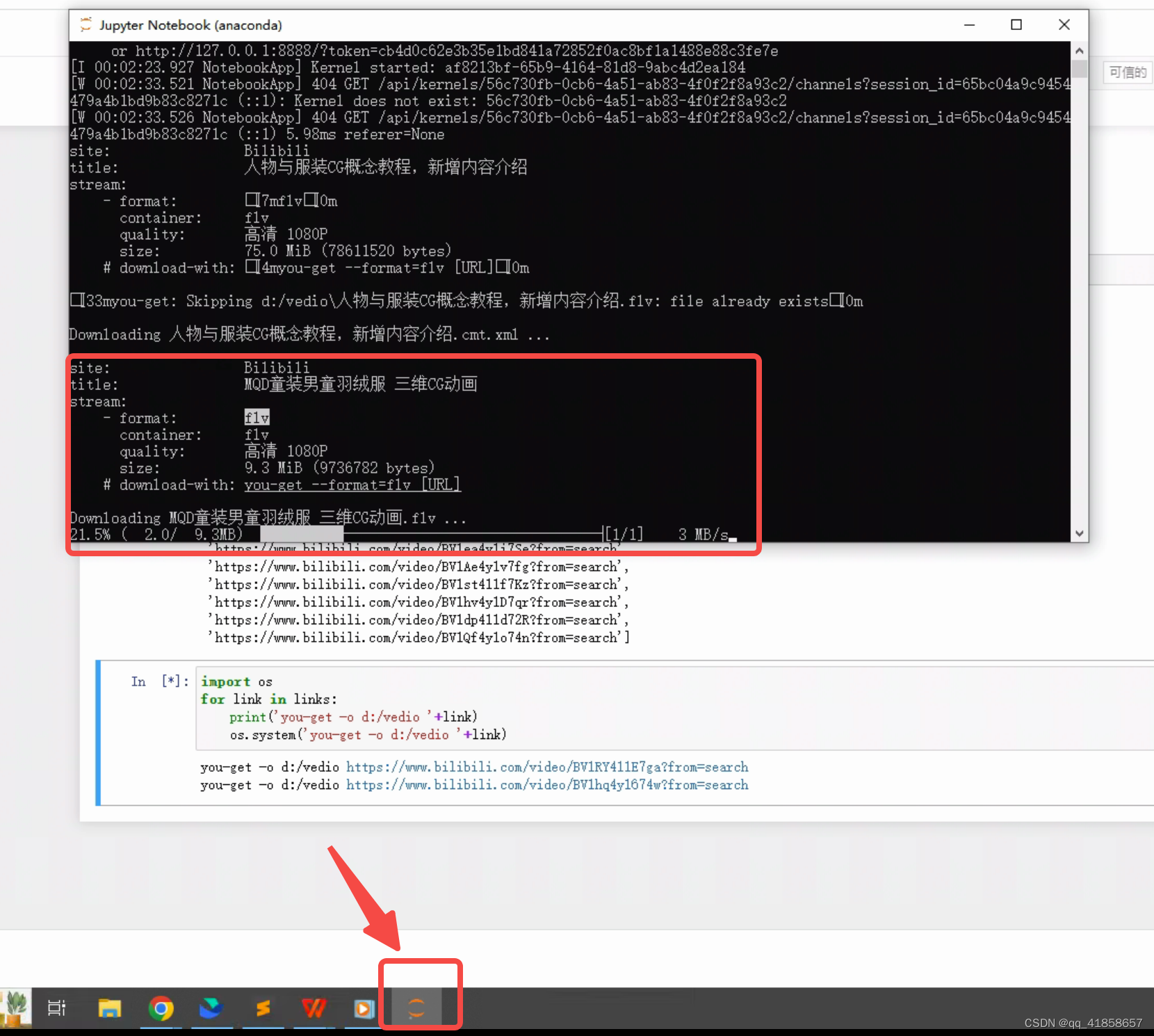
然后,我们去文件夹video里面看看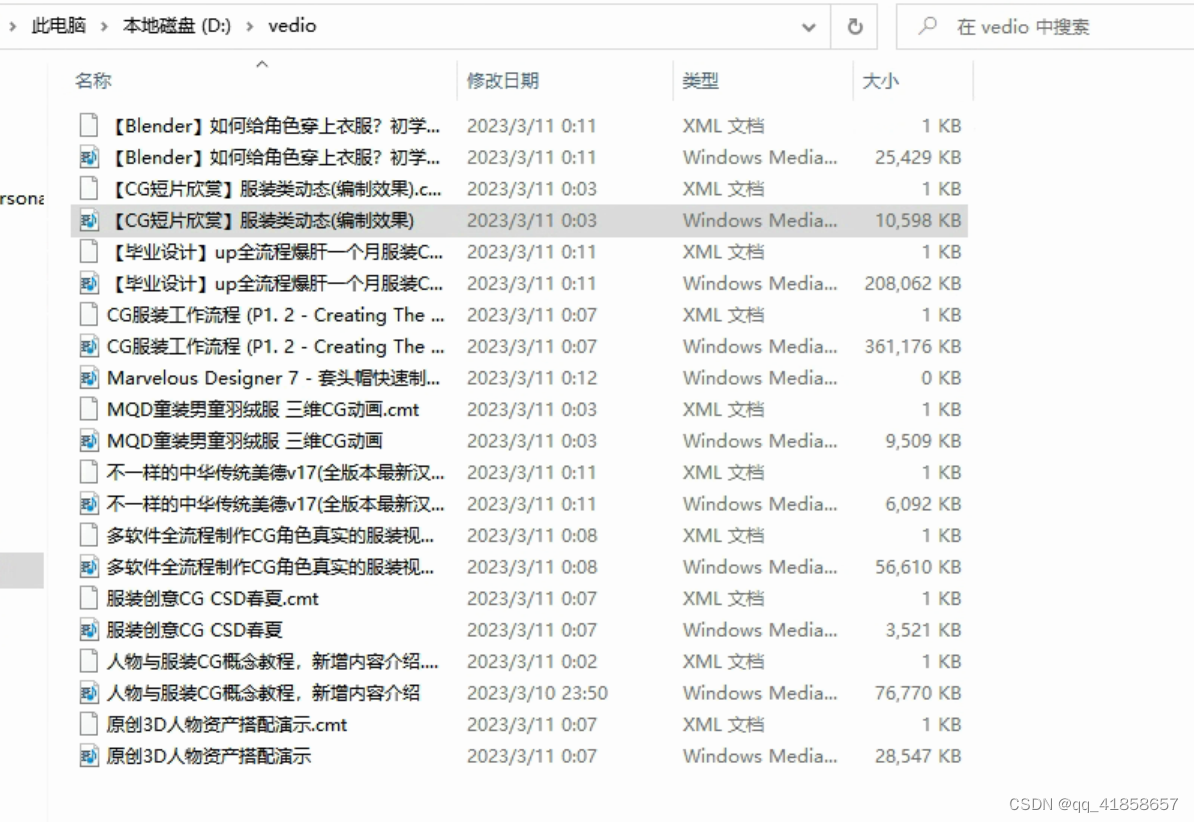
当当当~ 下载成功啦~
欢迎大家测试使用,有问题及时留言嗷~





![[论文笔记]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://img-blog.csdnimg.cn/142f9dd71bd24d75b57e95c0c9ce15aa.png#pic_center)
![【LeetCode每日一题:[面试题 17.05] 字母与数字-前缀和+Hash表】](https://img-blog.csdnimg.cn/c08f8a4d170444d0aa318a40e27f40c3.png)