目录
一.vector的介绍及使用
1.vector的介绍
2.vector的使用
1.vector的定义
2.vector iterator的使用
3. vector 空间增长问题
4.vector 增删查改
3.vector 迭代器失效问题(重点)
1. 会引起其底层空间改变的操作
2.指定位置元素的删除操作--erase
3. Linux下,g++编译器对迭代器的处理情况。
二.vector深度剖析及模拟实现
1.std::vector的核心框架接口的模拟实现
2. 使用memcpy拷贝问题
3.动态二维数组理解
一.vector的介绍及使用
1.vector的介绍
2.vector的使用
1.vector的定义

2.vector iterator的使用


注意:所有的迭代器区间都是左闭右开,且不光可以传vector的迭代器,还可以传其他类型的迭代器,只要类型可以匹配。
下面是代码演示
void Print(const vector<int>& v)
{
// const对象使用const迭代器进行遍历打印
vector<int>::const_iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}3. vector 空间增长问题

// 如果已经确定vector中要存储元素大概个数,可以提前将空间设置足够
// 就可以避免边插入边扩容导致效率低下的问题了
void TestVector()
{
vector<int> v;
size_t sz = v.capacity();
v.reserve(100); // 提前将容量设置好,可以避免一遍插入一遍扩容
cout << "making bar grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
通过测试发现提前开好了空间,capacity已经变成了100。
4.vector 增删查改
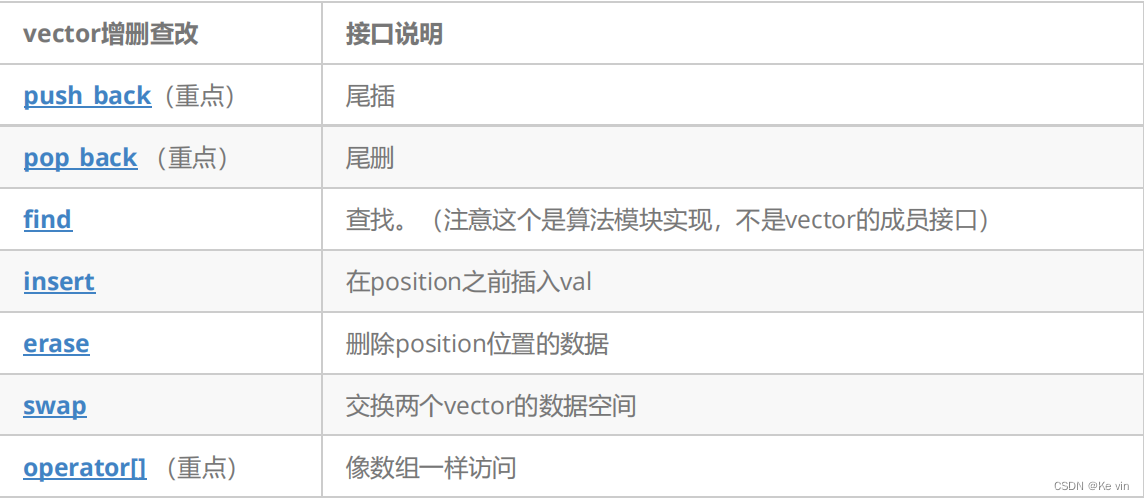
重要的函数接口参数
void push_back (const value_type& val);
void pop_back();
template <class InputIterator, class T>
InputIterator find (InputIterator first, InputIterator last, const T& val);
iterator insert (iterator position, const value_type& val);
void insert (iterator position, size_type n, const value_type& val);
iterator erase (iterator position);iterator erase (iterator first, iterator last);3.vector 迭代器失效问题(重点)
迭代器的使用特别广泛,迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)。
1. 会引起其底层空间改变的操作
比如:resize、reserve、insert、assign、push_back等,都有可能造成迭代器失效
#include <iostream>
using namespace std;
#include <vector>
int main()
{
vector<int> v{1,2,3,4,5,6};
auto it = v.begin();
// 将有效元素个数增加到100个,多出的位置使用8填充,操作期间底层会扩容
// v.resize(100, 8);
// reserve的作用就是改变扩容大小但不改变有效元素个数,操作期间可能会引起底层容量改变
// v.reserve(100);
// 插入元素期间,可能会引起扩容,而导致原空间被释放
// v.insert(v.begin(), 0);
// v.push_back(8);
// 给vector重新赋值,可能会引起底层容量改变
v.assign(100, 8);
while(it != v.end())
{
cout<< *it << " " ;
++it;
}
cout<<endl;
return 0;
}2.指定位置元素的删除操作--erase
#include <iostream>
using namespace std;
#include <vector>
int main()
{
int a[] = { 1, 2, 3, 4 };
vector<int> v(a, a + sizeof(a) / sizeof(int));
// 使用find查找3所在位置的iterator
vector<int>::iterator pos = find(v.begin(), v.end(), 3);
// 删除pos位置的数据,导致pos迭代器失效。
v.erase(pos);
cout << *pos << endl; // 此处会导致非法访问
return 0;
}#include <iostream>
using namespace std;
#include <vector>
int main()
{
vector<int> v{ 1, 2, 3, 4 };
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
return 0;
}
int main()
{
vector<int> v{ 1, 2, 3, 4 };
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
it = v.erase(it); //返回一个迭代器,指向删除数据的下一个位置
else
++it;
}
return 0;
}第一个代码是错误的,会造成迭代器失效,且其删除逻辑是不对的。以上面的代码为例,当程序删除“2”以后,pos位置会变成“3”,然后it++,迭代器就指向了4,就错过了对3的判断,且最后一个是偶数4,删除以后,迭代器会超过_finish,导致it永远不会==v.end()。
3. Linux下,g++编译器对迭代器的处理情况。
// 1. 扩容之后,迭代器已经失效了,程序虽然可以运行,但是运行结果已经不对了
int main()
{
vector<int> v{1,2,3,4,5};
auto it = v.begin();
cout << "扩容之前,vector的容量为: " << v.capacity() << endl;
// 通过reserve将底层空间设置为100,目的是为了让vector的迭代器失效
v.reserve(100);
cout << "扩容之后,vector的容量为: " << v.capacity() << endl;
// 经过上述reserve之后,it迭代器肯定会失效,在vs下程序就直接崩溃了,但是linux下不会
// 虽然可能运行,但是输出的结果是不对的
while(it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
输出:
扩容之前,vector的容量为: 5
扩容之后,vector的容量为: 100
0 2 3 4 5 409 1 2 3 4 5
// 2. erase删除任意位置代码后,linux下迭代器并没有失效
// 因为空间还是原来的空间,后序元素往前搬移了,it的位置还是有效的
#include <vector>
#include <algorithm>
int main()
{
vector<int> v{1,2,3,4,5};
vector<int>::iterator it = find(v.begin(), v.end(), 3);
v.erase(it);
cout << *it << endl;
while(it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
程序可以正常运行,并打印:
4
4 5
// 3: erase删除的迭代器如果是最后一个元素,删除之后it已经超过end
// 此时迭代器是无效的,++it导致程序崩溃
int main()
{
vector<int> v{1,2,3,4,5};
// vector<int> v{1,2,3,4,5,6};
auto it = v.begin();
while(it != v.end())
{
if(*it % 2 == 0)
v.erase(it);
++it;
}
for(auto e : v)
cout << e << " ";
cout << endl;
return 0;
}从上述三个例子中可以看到:Linux下,g++编译器对迭代器失效的检测并不是非常严格,处理也没有vs下极端,SGI STL中,迭代器失效后,代码并不一定会崩溃,但是运行结果肯定不对,如果it不在begin和end范围内,肯定会崩溃的。
二.vector深度剖析及模拟实现

1.std::vector的核心框架接口的模拟实现
#pragma once
#include <iostream>
using namespace std;
#include <assert.h>
namespace Kevin
{
template<class T>
class vector
{
public:
// Vector的迭代器是一个原生指针
typedef T* iterator;
typedef const T* const_iterator;
///
// 构造和销毁
vector()
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{}
vector(size_t n, const T& value = T())
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
reserve(n);
while (n--)
{
push_back(value);
}
}
/*
* 理论上将,提供了vector(size_t n, const T& value = T())之后
* vector(int n, const T& value = T())就不需要提供了,但是对于:
* vector<int> v(10, 5);
* 编译器在编译时,认为T已经被实例化为int,而10和5编译器会默认其为int类型
* 就不会走vector(size_t n, const T& value = T())这个构造方法,
* 最终选择的是:vector(InputIterator first, InputIterator last)
* 因为编译器觉得区间构造两个参数类型一致,因此编译器就会将InputIterator实例化为int
* 但是10和5根本不是一个区间,编译时就报错了
* 故需要增加该构造方法
*/
vector(int n, const T& value = T())
: _start(new T[n])
, _finish(_start+n)
, _endOfStorage(_finish)
{
for (int i = 0; i < n; ++i)
{
_start[i] = value;
}
}
// 若使用iterator做迭代器,会导致初始化的迭代器区间[first,last)只能是vector的迭代器
// 重新声明迭代器,迭代器区间[first,last)可以是任意容器的迭代器
template<class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
reserve(v.capacity());
iterator it = begin();
const_iterator vit = v.cbegin();
while (vit != v.cend())
{
*it++ = *vit++;
}
_finish = it;
}
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
~vector()
{
if (_start)
{
delete[] _start;
_start = _finish = _endOfStorage = nullptr;
}
}
/
// 迭代器相关
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator cbegin() const
{
return _start;
}
const_iterator cend() const
{
return _finish;
}
//
// 容量相关
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _endOfStorage - _start;
}
bool empty() const
{
return _start == _finish;
}
void reserve(size_t n)
{
if (n > capacity())
{
size_t oldSize = size();
// 1. 开辟新空间
T* tmp = new T[n];
// 2. 拷贝元素
// 这里直接使用memcpy会有问题吗?同学们思考下
//if (_start)
// memcpy(tmp, _start, sizeof(T)*size);
if (_start)
{
for (size_t i = 0; i < oldSize; ++i)
tmp[i] = _start[i];
// 3. 释放旧空间
delete[] _start;
}
_start = tmp;
_finish = _start + oldSize;
_endOfStorage = _start + n;
}
}
void resize(size_t n, const T& value = T())
{
// 1.如果n小于当前的size,则数据个数缩小到n
if (n <= size())
{
_finish = _start + n;
return;
}
// 2.空间不够则增容
if (n > capacity())
reserve(n);
// 3.将size扩大到n
iterator it = _finish;
_finish = _start + n;
while (it != _finish)
{
*it = value;
++it;
}
}
///
// 元素访问
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return _start[pos];
}
T& front()
{
return *_start;
}
const T& front()const
{
return *_start;
}
T& back()
{
return *(_finish - 1);
}
const T& back()const
{
return *(_finish - 1);
}
/
// vector的修改操作
void push_back(const T& x)
{
insert(end(), x);
}
void pop_back()
{
erase(end() - 1);
}
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endOfStorage, v._endOfStorage);
}
iterator insert(iterator pos, const T& x)
{
assert(pos <= _finish);
// 空间不够先进行增容
if (_finish == _endOfStorage)
{
//size_t size = size();
size_t newCapacity = (0 == capacity()) ? 1 : capacity() * 2;
reserve(newCapacity);
// 如果发生了增容,需要重置pos
pos = _start + size();
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
return pos;
}
// 返回删除数据的下一个数据
// 方便解决:一边遍历一边删除的迭代器失效问题
iterator erase(iterator pos)
{
// 挪动数据进行删除
iterator begin = pos + 1;
while (begin != _finish) {
*(begin - 1) = *begin;
++begin;
}
--_finish;
return pos;
}
private:
iterator _start; // 指向数据块的开始
iterator _finish; // 指向有效数据的尾
iterator _endOfStorage; // 指向存储容量的尾
};
}2. 使用memcpy拷贝问题
int main()
{
bite::vector<bite::string> v;
v.push_back("1111");
v.push_back("2222");
v.push_back("3333");
return 0;
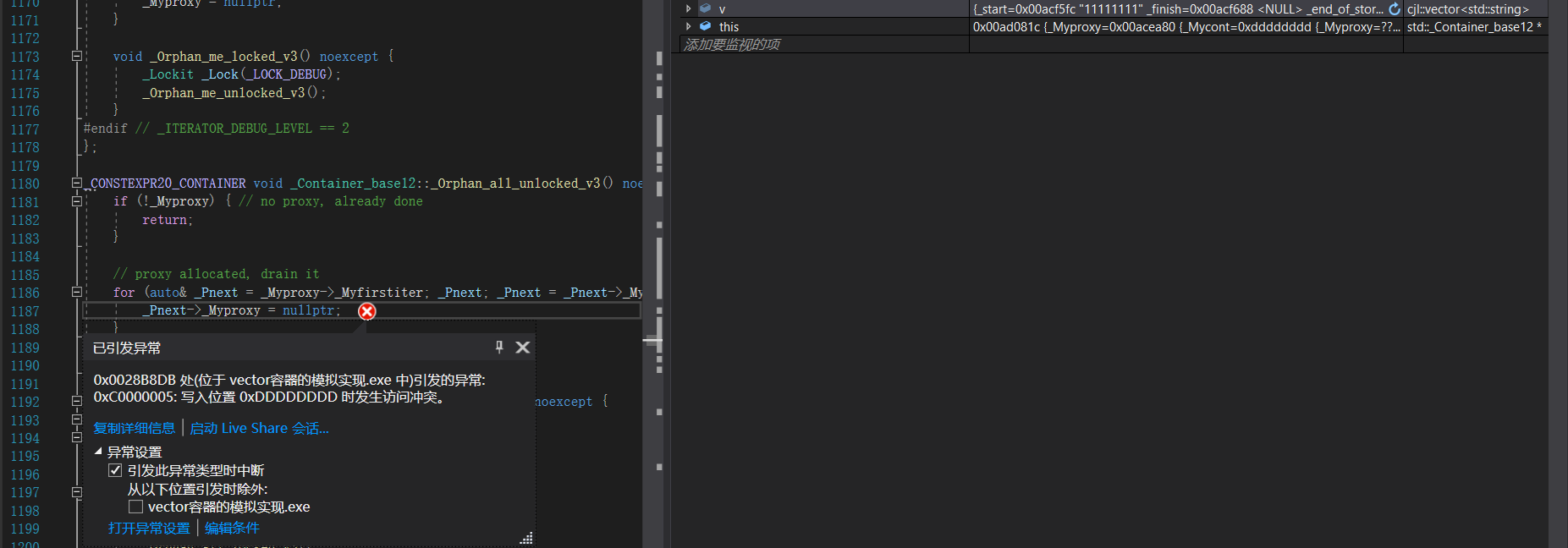
}假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,上面的代码会有什么问题吗?
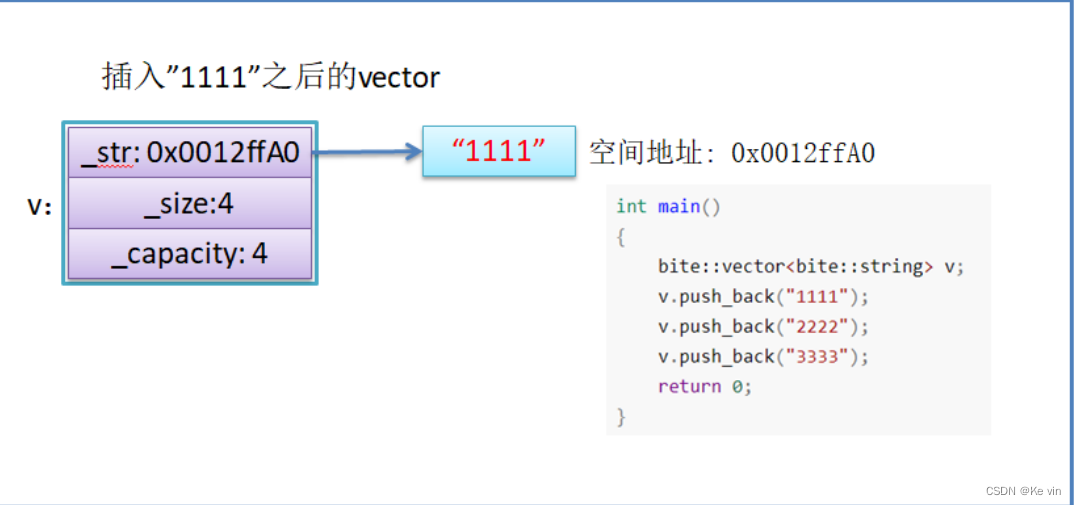
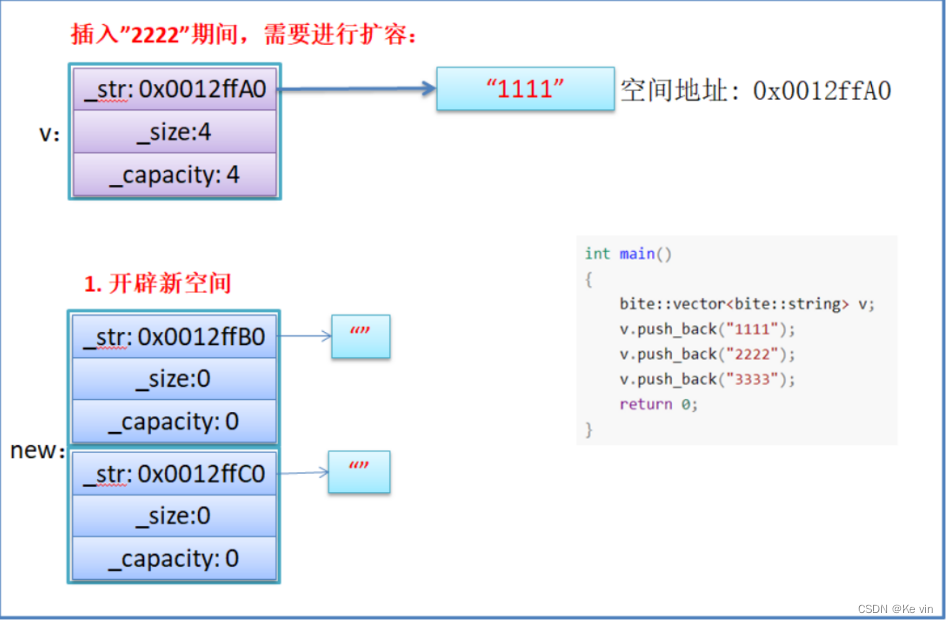
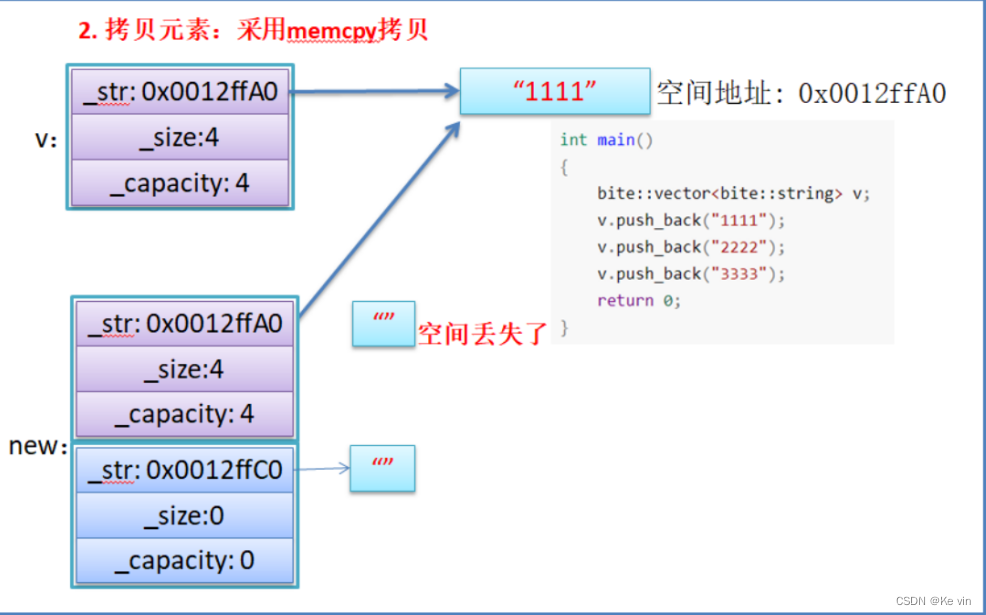
如果拷贝的是自定义类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
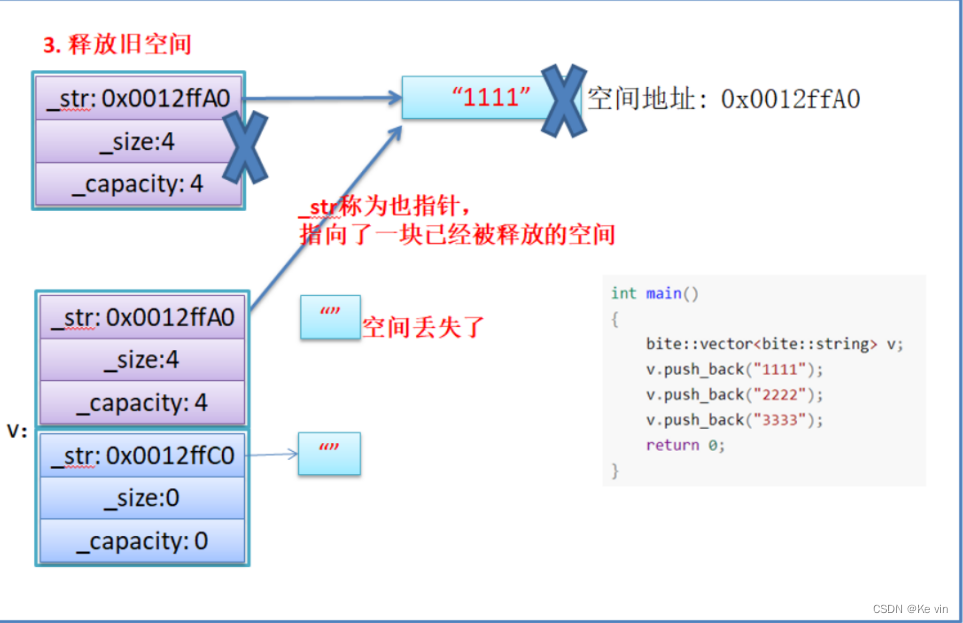
结论:如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是 浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。
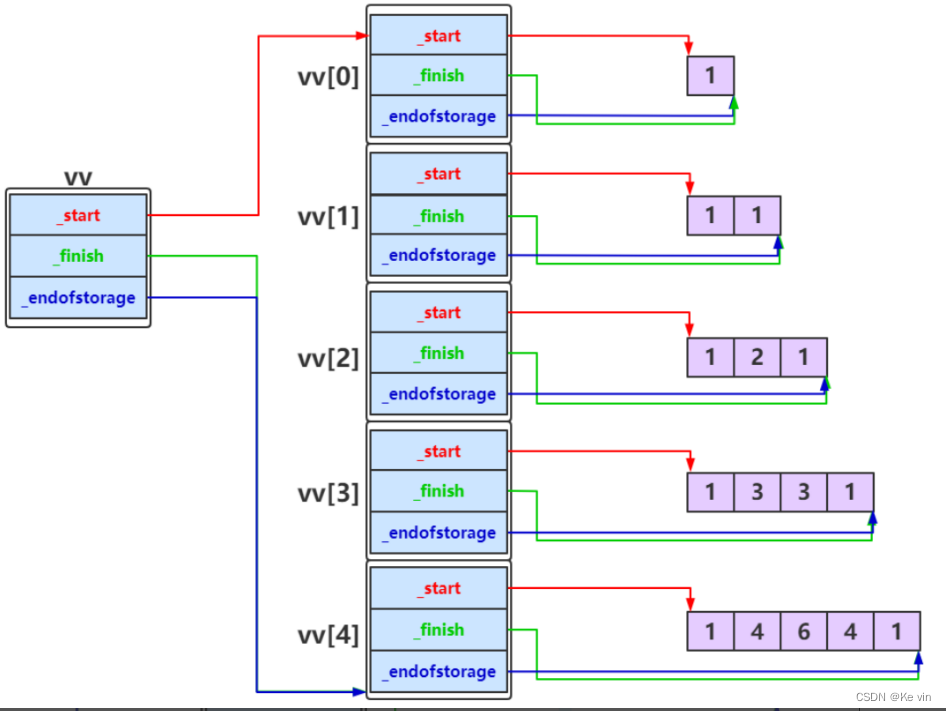
3.动态二维数组理解
vector<vector<int>> vv(n);
完成元素填充后,如下图:





![[论文笔记]Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://img-blog.csdnimg.cn/142f9dd71bd24d75b57e95c0c9ce15aa.png#pic_center)