什么是redis?
Redis是Remote Dictionary Server的简称,是一个由意大利人Salvatore Sanfilippo开发的key-value存储系统,具有极高的读写性能,读的速度可达110000次/s,写的速度可达81000次/s 。今天主要是分享redis的缓存功能。
为什么要使用缓存?
当互联网发展之初时,我们对于数据总量、需求都很小,我们的项目本身也很小,可以直接访问数据库;随着网络需求的不断增大,项目的不断扩大,数据库的压力剧增,增删改查需要频繁地在内存与外存之间交换数据,很费时间。
为了保证“有效、有限的请求”访问到数据库,我们放大前置环节的逻辑和成本,所以缓存应运而生。它是一种小巧而功能强大的存储结构,用于在内存中管理数据量不太大但是访问量特别大的热点数据。
缓存的优点:
1、提高接口的响应时间和并发量
2、减轻数据库的压力
Redis支持数据的持久化,周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,重启的时候可以再次加载进行使用。Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
当我们正式使用redis时,需要考虑几个经典的场景:
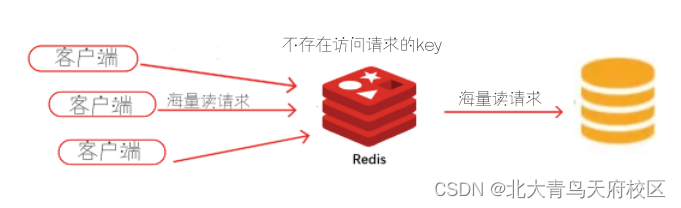
1、缓存穿透:用户访问的key在数据库中一定不存在的数据,如果有人利用这个漏洞恶意系统,每次请求的压力都给到数据库,会压垮数据库,造成系统崩溃。
正常情况下,一个请求过来,首先判断key是否存在,如果key存在,直接返回;如果key不存在或者已过期,查询数据库,如果数据库中存在数据,则更新缓存并返回数据;如果不存在,则直接返回空。
参考解决方案:
1、缓存默认值:在数据库查询不存在时,可以将其缓存为默认值。不过设置的时间不宜过长(一般设置为60s),如果过了一会儿数据库新增了该数据,时间太长的话,就会出现数据不一致的情况。
2、业务逻辑前置判断:为避免有人为的恶意打击,用不合理的参数去请求系统。我们在接口处进行数据合法性校验,进行提前拒绝。比如:a接口只允许查询18+的成年人的数据,请求带有未成年人就明显不合适。
避免了因为新增了大量的不存在的key到内存中,极端情况下,缓存被撑爆。
3、使用布隆过滤器:如果通过前面两种方案也无法避免问题,可以使用布隆过滤器。当把数据写入数据库的时候,使用布隆过滤器进行标记;当有请求时,如果发现缓存消失,在去查询数据库前,先查询布隆过滤器该key是否存在;如果不存在,直接返回,不过布隆过滤器有一定的误判率,这个可以忽略。
4、加互斥锁或队列:基于高并发的场景,我们要加一个锁,只保证一个线程去创建缓存,其余的等待。避免高并发带来的大量的请求同一时刻都来请求同一个key,发现没有这个key,全都去访问数据库,以至于系统崩溃。
2、缓存击穿:指的是一个热点key,在不停的被大量的请求访问,当这个热点key缓存失效的瞬间,大量的请求访问到数据库,以至于系统崩溃。
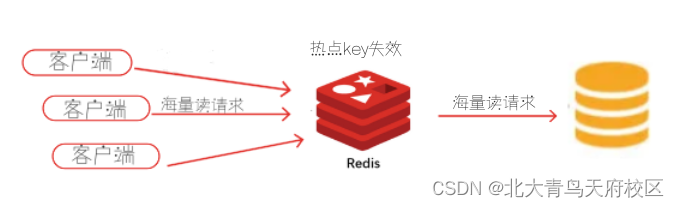
参考解决方案:
1、设置永不过期:提前把热点数据不设置过期时间,后台异步更新缓存。不过面对真实场景时,也需要根据实际情况及时的调整,毕竟没有永不过时的热点,用户们的关注点每时每刻都在变化中。
2、加互斥锁或队列:加一个互斥锁,让一个线程正常请求数据库,其他线程等待即可(这里可以使用线程池来处理),都创建完缓存,让其他线程请求缓存即可。
3、缓存雪崩:当某一个时刻出现大规模的缓存失效,然后大量的请求直接访问到数据库,以至于压垮数据库,造成系统崩溃等情况。出现的原因主要包括:缓存采用相同的过期时间,或者缓存服务出现故障。
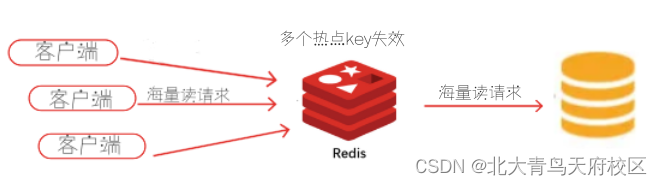
参考解决方案:
1、相对随机数过期时间:key的过期时间加上一个随机值,保证不是同一时间失效
2、分布式集群部署:单节点缓存服务容易宕机,那我们就部署个集群,然后把缓存均匀的分不到不同的服务器上。
3、服务限流、熔断、降级:当流量到一定的阈值或者服务出现异常、故障时,直接返回“请稍后再试”的友好性处理,让一部分用户正常使用,其他用户多重试几次,不过这样难免会降低用户体验,不过几个人有问题也总比整个系统崩溃好。
Redis作为我们北大青鸟Java课程必学内容之一,结合实际的商业项目,掌握技术的各种应用场景和解决方案,让学员能积累到真实有效的工作项目经验,提升竞争力!
了解更多开发技能、学习内容及就业情况等,可以持续关注我们成都基地!