目录
- 一、SENet
- 1. 设计原理
- 2. SE Block
- 2.1 Squeeze:Global Information Embedding
- 2.2 Excitation:Adaptive Recalibration
- 3. SE-Inception and SE-ResNet
- 二、YOLOv5中添加SENet
- 1.修改common.py
- 2.修改yolo.py
- 3.修改yolov5s.yaml
- 参考文章
一、SENet
论文地址:Squeeze-and-Excitation Networks [CVPR2017]
Caffe代码地址:SENet-Caffe
Pytorch代码地址:SENet-Pytorch
1. 设计原理
论文中提到,在SENet提出之前,大部分工作专注于研究特征图的空间编码质量(可以理解为每个通道的特征图的特征提取质量),即只关注每个通道中特征图的表达能力,而没有关注不同通道的特征图的融合(如果一个特征图的维度为 C × H × W C×H×W C×H×W的话,SENet之前的工作只关注了 H H H和 W W W维度,而没有关注 C C C维度,不同通道的特征图融合还是通过卷积相加的方式完成)。
SENet关注了通道关系,提出了Squeeze-and-Excitation模块,通过显式地模拟通道之间的相互依赖关系,自适应地重新校准通道的特征响应(普通卷积过程的通道关系本质上是隐式的和局部的(除了最顶层的通道关系,因为最顶层的通道与任务相关,比如分割网络的最顶层通道数为分割类别数,而中间层的通道数通常是经验所得))。
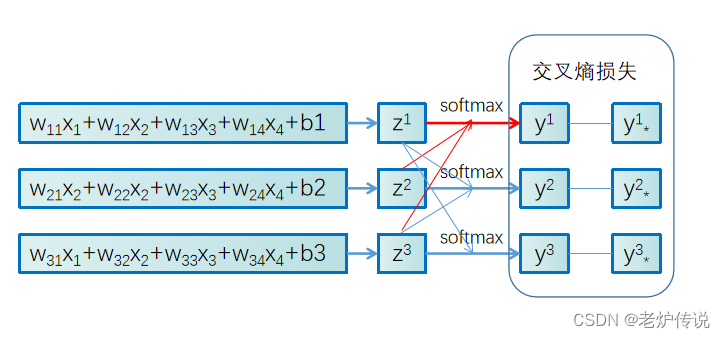
2. SE Block

SE Block的结构如图1所示,首先通过卷积操作
F
t
r
F_{tr}
Ftr将输入特征图
X
∈
R
H
′
×
W
′
×
C
′
X\in R^{H'\times W'\times C'}
X∈RH′×W′×C′映射到特征图
U
∈
R
H
×
W
×
C
U\in R^{H\times W\times C}
U∈RH×W×C,在这个过程中,用
V
=
[
v
1
,
v
2
,
.
.
.
,
v
C
]
V=[v_{1},v_{2},...,v_{C}]
V=[v1,v2,...,vC]表示卷积核的集合,输出可表示为
U
=
[
u
1
,
u
2
,
.
.
.
,
u
C
]
U=[u_{1},u_{2},...,u_{C}]
U=[u1,u2,...,uC],则:
u
c
=
v
c
∗
X
=
∑
s
=
1
C
′
v
c
s
∗
x
s
u_c=v_{c}*X=\sum_{s=1}^{C'}v_{c}^s*x^s
uc=vc∗X=s=1∑C′vcs∗xs
这里 ∗ * ∗ 表示卷积操作, u c ∈ R H × W u_{c}\in R^{H\times W} uc∈RH×W, v c = [ v c 1 , v c 2 , . . . , v c C ′ ] v_{c}=[v_{c}^1,v_{c}^2,...,v_{c}^{C'}] vc=[vc1,vc2,...,vcC′], X = [ x 1 , x 2 , . . . , x C ′ ] X=[x^{1},x^{2},...,x^{C'}] X=[x1,x2,...,xC′], v c s v_{c}^s vcs是一个二维卷积核,表示 v c v_{c} vc的单个通道作用于 X X X的相应通道上。
2.1 Squeeze:Global Information Embedding
为了考虑输出特征图中每个通道的信息,论文通过全局平均池化的方式,将全局空间信息压缩到一个通道描述符 z c z_{c} zc中:
z c = F s q ( u c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W u c ( i , j ) z_{c}=F_{sq}(u_{c})=\frac{1}{H\times W}\sum_{i=1}^{H}\sum_{j=1}^{W}u_{c}(i,j) zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
2.2 Excitation:Adaptive Recalibration
为了完全捕获通道依赖关系,论文选择使用一种简单的带有Sigmoid激活的门控机制:
s = F e x ( z , W ) = σ ( g ( z , W ) ) = σ ( W 2 δ ( W 1 z ) ) s=F_{ex}(z,W)=\sigma (g(z,W))=\sigma (W_{2}\delta (W_{1}z)) s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
其中, δ \delta δ为ReLU函数, W 1 ∈ R C r × C W_{1}\in R^{\frac{C}{r}\times C} W1∈RrC×C, W 2 ∈ R C × C r W_{2}\in R^{C\times\frac{C}{r}} W2∈RC×rC。
通过s重新缩放U,得到SE Block最后的输出:
x ˉ c = F s c a l e ( u c , s c ) = s c u c \bar{x}_{c}=F_{scale}(u_{c},s_{c})=s_{c}u_{c} xˉc=Fscale(uc,sc)=scuc
3. SE-Inception and SE-ResNet
图2为原文设计的SE-Inception模块和SE-ResNet模块,这是一个即插即用模块。为了解决通道之间的依赖关系,作者使用全局平均池化操作来压缩全局空间信息,这就是Sequeeze操作。为了利用在Sequeeze操作中聚合的信息,作者通过FC-ReLU-FC-Sigmoid操作来完全捕获通道依赖性,这就是Excitation操作。

class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) #全局平均池化,输入BCHW -> 输出 B*C*1*1
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False), #可以看到channel得被reduction整除,否则可能出问题
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c) #得到B*C*1*1,然后转成B*C,才能送入到FC层中。
y = self.fc(y).view(b, c, 1, 1) #得到B*C的向量,C个值就表示C个通道的权重。把B*C变为B*C*1*1是为了与四维的x运算。
return x * y.expand_as(x) #先把B*C*1*1变成B*C*H*W大小,其中每个通道上的H*W个值都相等。*表示对应位置相乘。
二、YOLOv5中添加SENet
1.修改common.py
在models/common.py中添加下列代码
class SElayer(nn.Module):
def __init__(self, c1, c2, ratio=16):
super(SElayer, self).__init__()
#c*1*1
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // ratio, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // ratio, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
2.修改yolo.py
在models/yolo.py中的parse_model函数中添加SElayer模块
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR, ASPP, SElayer]:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
3.修改yolov5s.yaml
在Backbone的倒数第二层添加SElayer,修改后的yolov5s.yaml如下所示:
# parameters
nc: 20 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SElayer, [1024]],
[-1, 1, SPPF, [512, 512]], # 10
]
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
参考文章
SE-ResNet的实现
YOLOv5-6.1添加注意力机制(SE、CBAM、ECA、CA)