问题描述
环境:
- 开发调度平台:数栖平台4.18(16000+任务,7000+工作流)
- 大数据平台:CDH 5.12.0,大数据组件默认版本
- BI工具:FineBI
- 实时数仓:Dolphinscheduler + StarRocks
问题
离线跑批任务,偶尔会有个别工作流出现java.net.SocketTimeoutException: Read timed out错误。手动重跑工作流就可以了。通过分析日志,怀疑是HiveServer2端连接压力过大,做了两个操作:
-
调整了HiveServer2的超时时间。
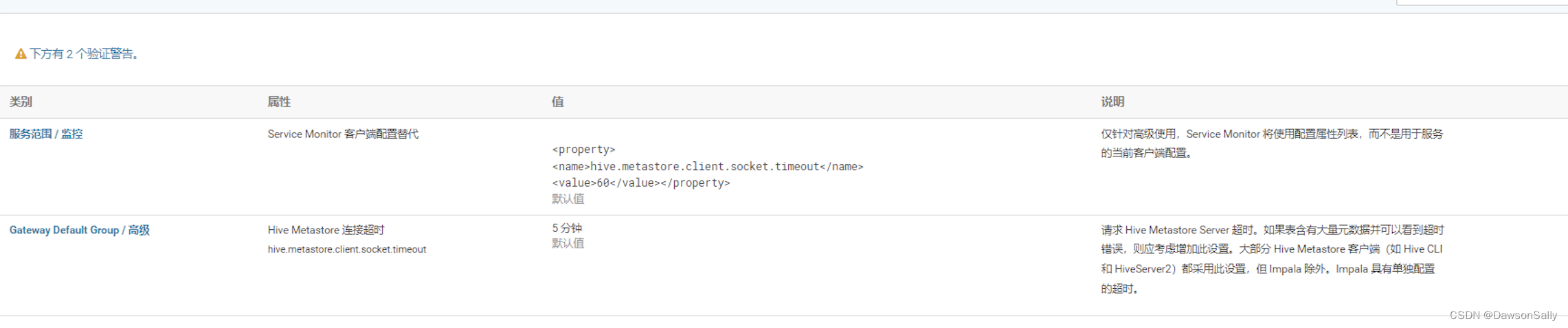
-
在数栖平台调整了任务的调度时间,让分布更加均衡。
之后基本上就较少出现类似问题了。
某天下午16点左右,同事反馈所有任务提交,马上报java.net.SocketTimeoutException: Read timed out错误。Yarn上一个Hive任务都拉不起来。所有任务都提交不到Yarn上。

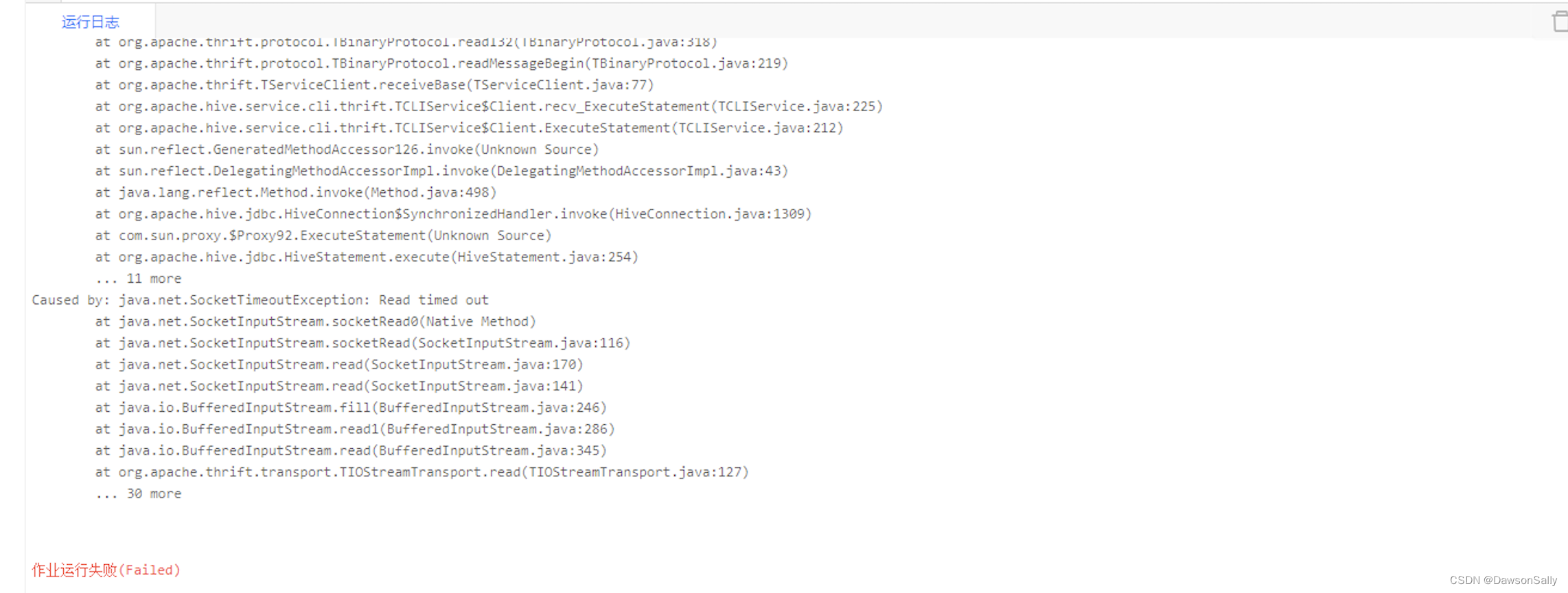
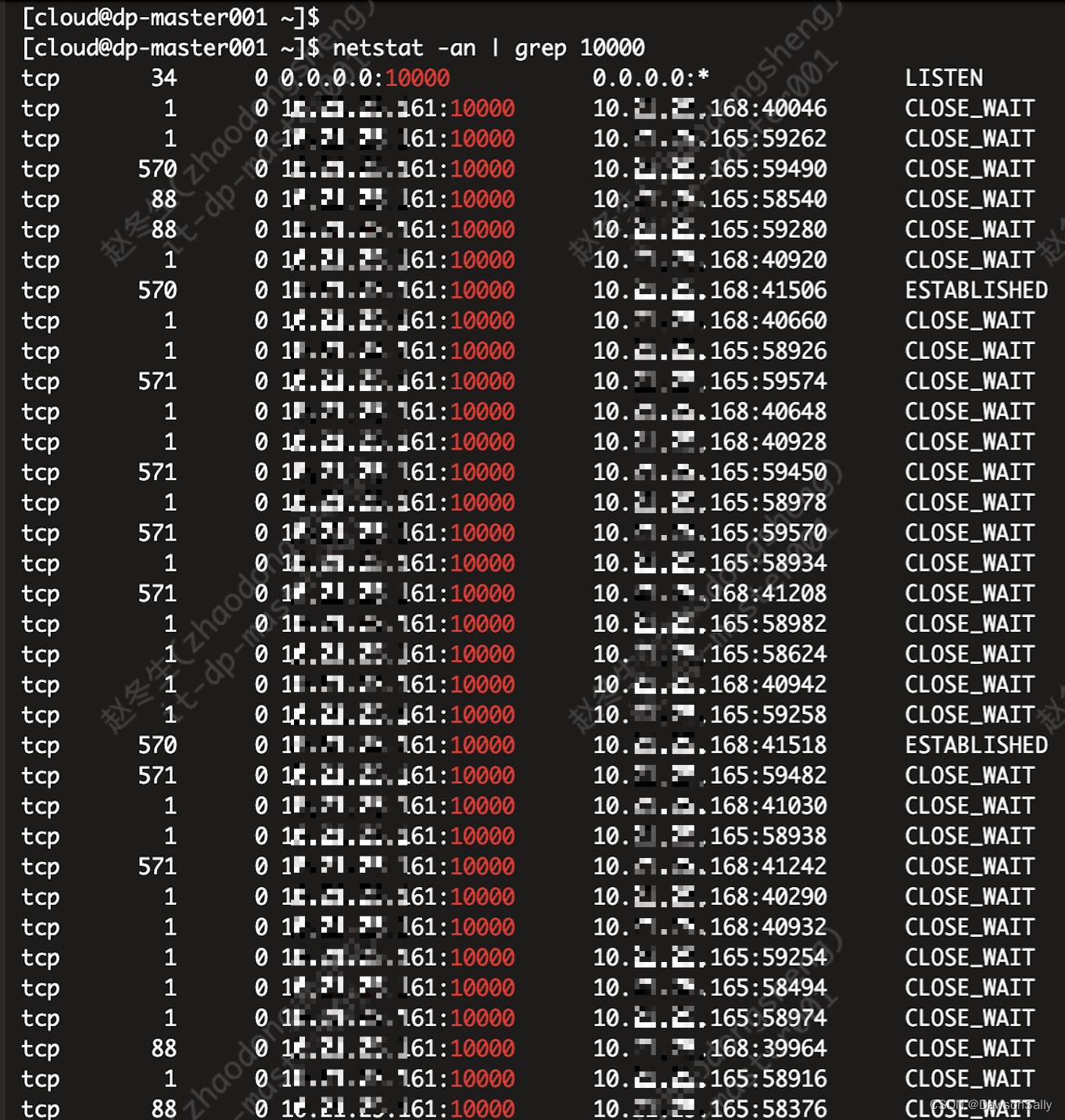
查看HiveServer的连接情况:
排查
- 询问是否有同事调整过CDH集群参数,回答无。
- 是否有同事调整过数栖平台的参数及服务运行环境,回答无。
基础环境没有人调整过,按理说就不应该有问题。
- 询问是谁发现的?
- 执行什么操作发现的?
回答,执行了一个脚本,该脚本还卡住没有出来。
怀疑是脚本问题,强制Kill掉脚本。
问题依旧,存在。
于是重启,hive、hdfs服务。
集群短暂可以提交任务到Yarn,一会儿又出问题了。所有Hive任务无法提交Yarn,报同样的java.net.SocketTimeoutException: Read timed out。
参考文章:https://blog.csdn.net/xin_jmail/article/details/85004967自检,发现和我们的症状不完全相同。
监控CDH Hive的指标,发现开发平台无法提交Hive任务到Yarn时,连接数暴涨。
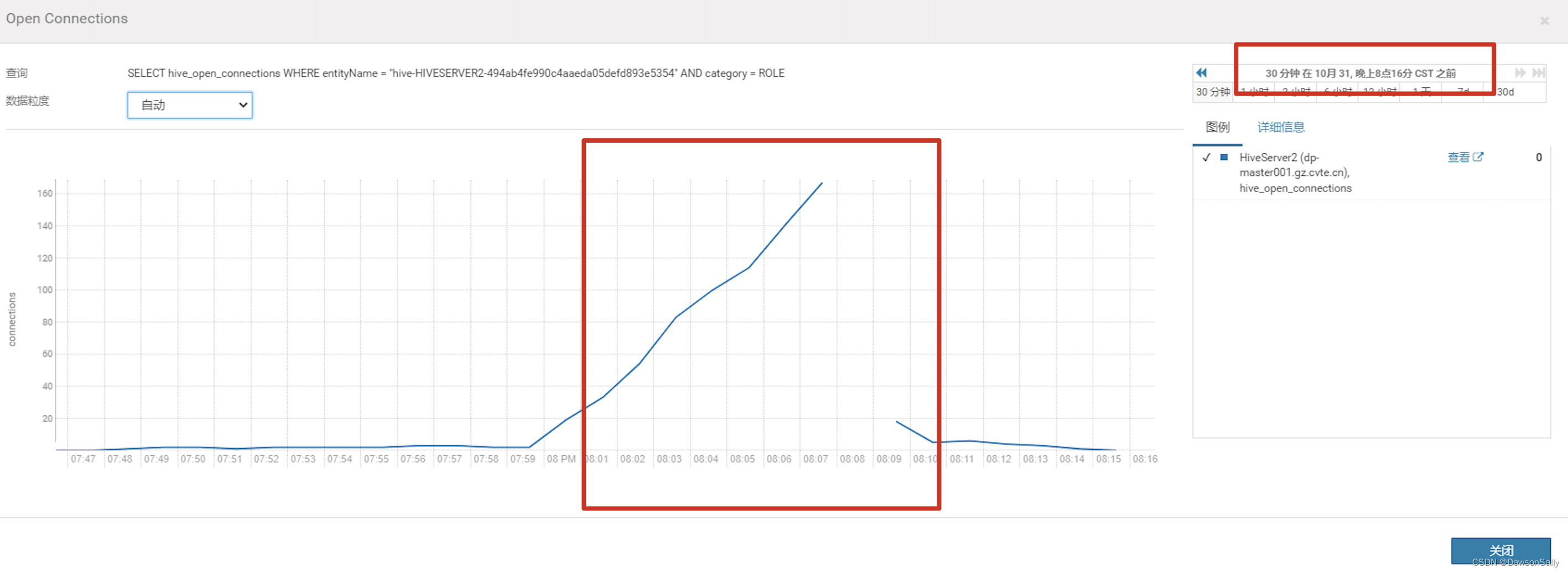
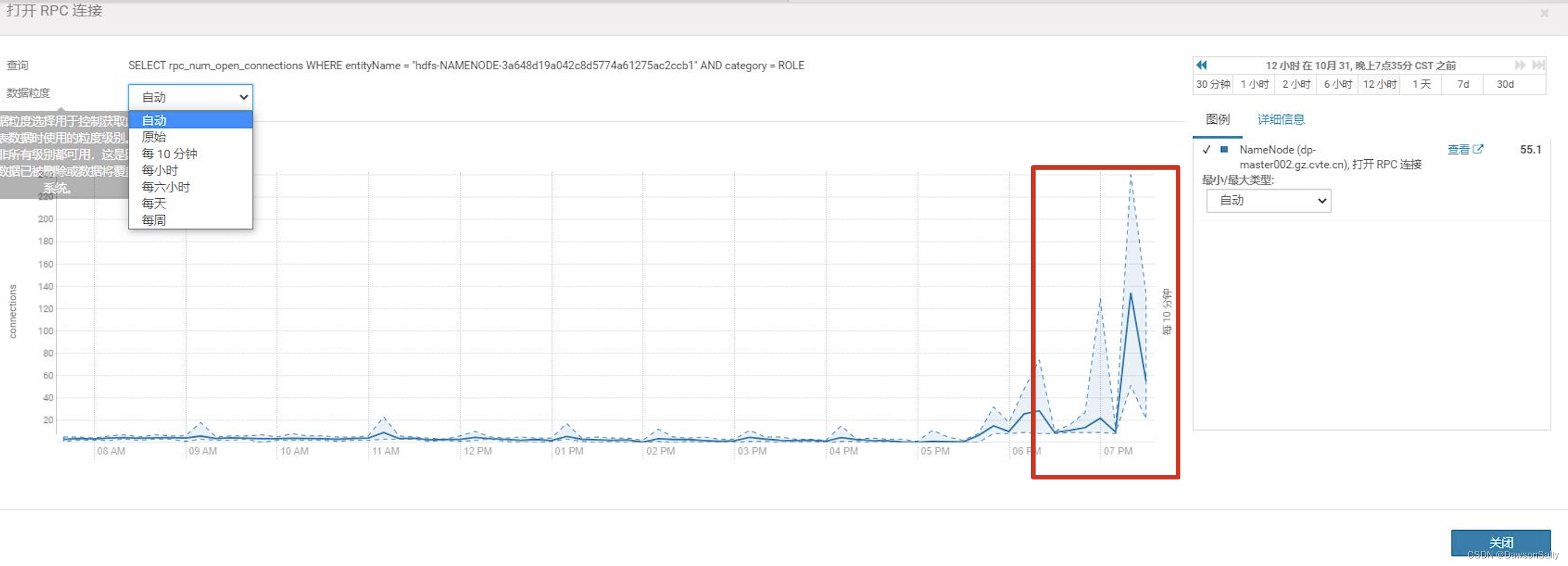
查看HiveServer的连接数配置,是100.于是修改为200.发现能提交任务,一段时间,又不能使用了。
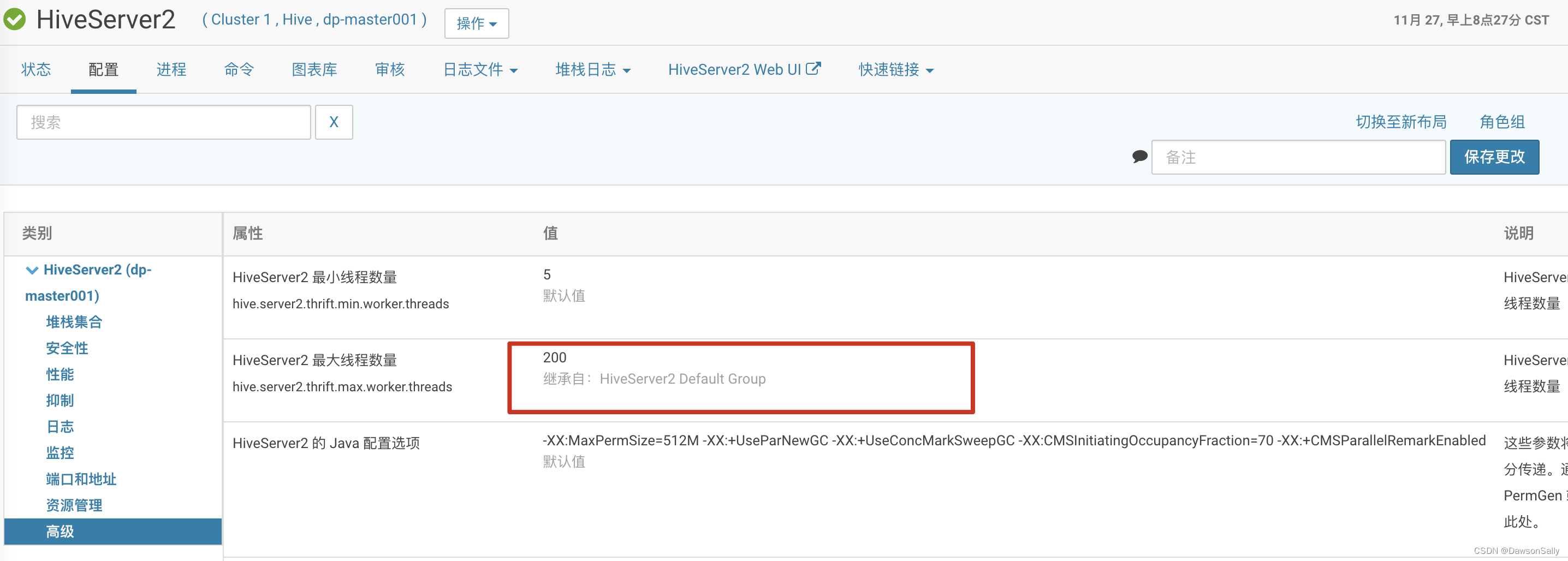
初步断定是提交Hive任务的客户端与Hive server之间的连接数不够了。但是为啥不够呢?
回顾下图:
怀疑是Hive Client端异常了。我们的环境只有数栖平台的Hive Client端提交Hive任务。
于是想到,前面几天数栖平台的Hive Client端修改配置参数。扩大了Java内存和并发量。怀疑是重试机制及并发数太大导致。
于是,暴力重启数栖平台的Hive Client端的提交Hive任务的代理服务。
观察:正常。
结论
HiveServer2-java.net.SocketTimeoutException: Read timed out问题,主要还是和连接数密切相关,有的可能是BUG导致的连接数不释放,例如https://blog.csdn.net/xin_jmail/article/details/85004967提高。有的可能是客户端和服务端,通信异常,导致大量的异常连接占用连接数,而不释放。还有的可能就是性能不足。