一、理论
1、什么是内存对齐
现代计算机中内存空间都是按照 byte 划分的,在计算机中访问一个变量需要访问它的内存地址,从理论上看,似乎对任何类型的变量的访问都可以从任何地址开始。
但在实际情况中,通常在特定的内存地址才能访问特定类型变量,这就需要对数据在内存中存放的位置有限制。各种类型不是按照顺序排放,它们需要根据一定的规则在空间上排列,这就是对齐。
2、为什么需要内存对齐
(1)移植原因:
不是所有的硬件平台都能访问任意地址上的任意数据的,各个硬件平台对存储空间的处理上有很大的不同,部分平台对某些特定类型的数据只能从某些特定地址开始存取。
比如,市面上有些架构的 CPU 在访问一个没有进行对齐的变量时会发生错误,这时 CPU 会进入异常处理状态并且通知程序不能继续执行。
举个例子,在 ARM 硬件平台上,当操作系统被要求存取一个未对齐数据时会默认给应用程序抛出硬件异常。所以,如果不进行内存对齐,代码就不具有移植性,而且难以开展在很多平台上的开发工作。
(2)性能原因:
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的。它一般会以双字节、4 字节、8 字节、16 字节甚至 32 字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度。
如果变量的地址没有对齐,可能需要多次访问才能完整读取到变量内容,而对齐后可能就只需要一次内存访问。因此,内存对齐可以减少 CPU 访问内存的次数,提高 CPU 访问内存的吞吐量。
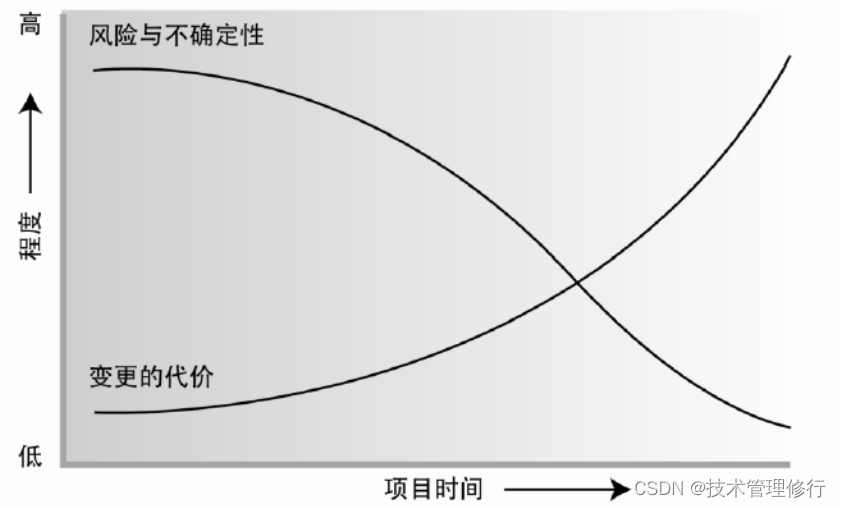
举个例子,考虑 4 字节存取粒度的处理器访问 int 类型变量,该处理器只能从地址为 4 的倍数的内存地址开始读取数据。如果未经过内存对齐,获取该 int 类型的数据需要进行两次内存访问,最后再进行数据整理得到完整数据:
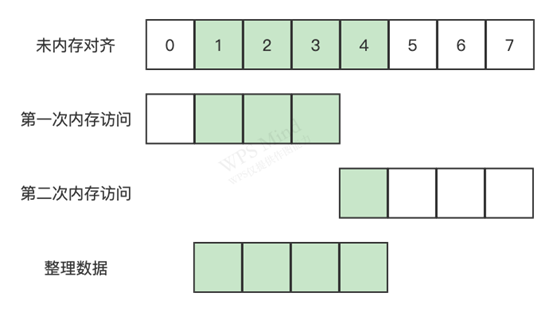
如果经过内存对齐,一次内存访问就能得到完整数据,减少了一次内存访问:

CPU 读取内存是高耗时的指令,内存对齐是在内存的使用量和 CPU 计算间的居中的优化策略。这种策略是由编译器和 CPU 共同决定,并且程序员可以设置对齐的长度。
通过上述介绍的内存对齐的必要性,我们可以知道,如果不理解内存对齐,在编程时就可能产生下面的问题:
(1) 程序运行速度变慢;
(2) 应用程序产生死锁;
(3) 操作系统崩溃;
(4) 程序会毫无征兆的出错,产生错误的结果。
但是,我们在写程序时一般无需考虑对齐,通常是依赖编译器来为我们选择适合的对齐策略。
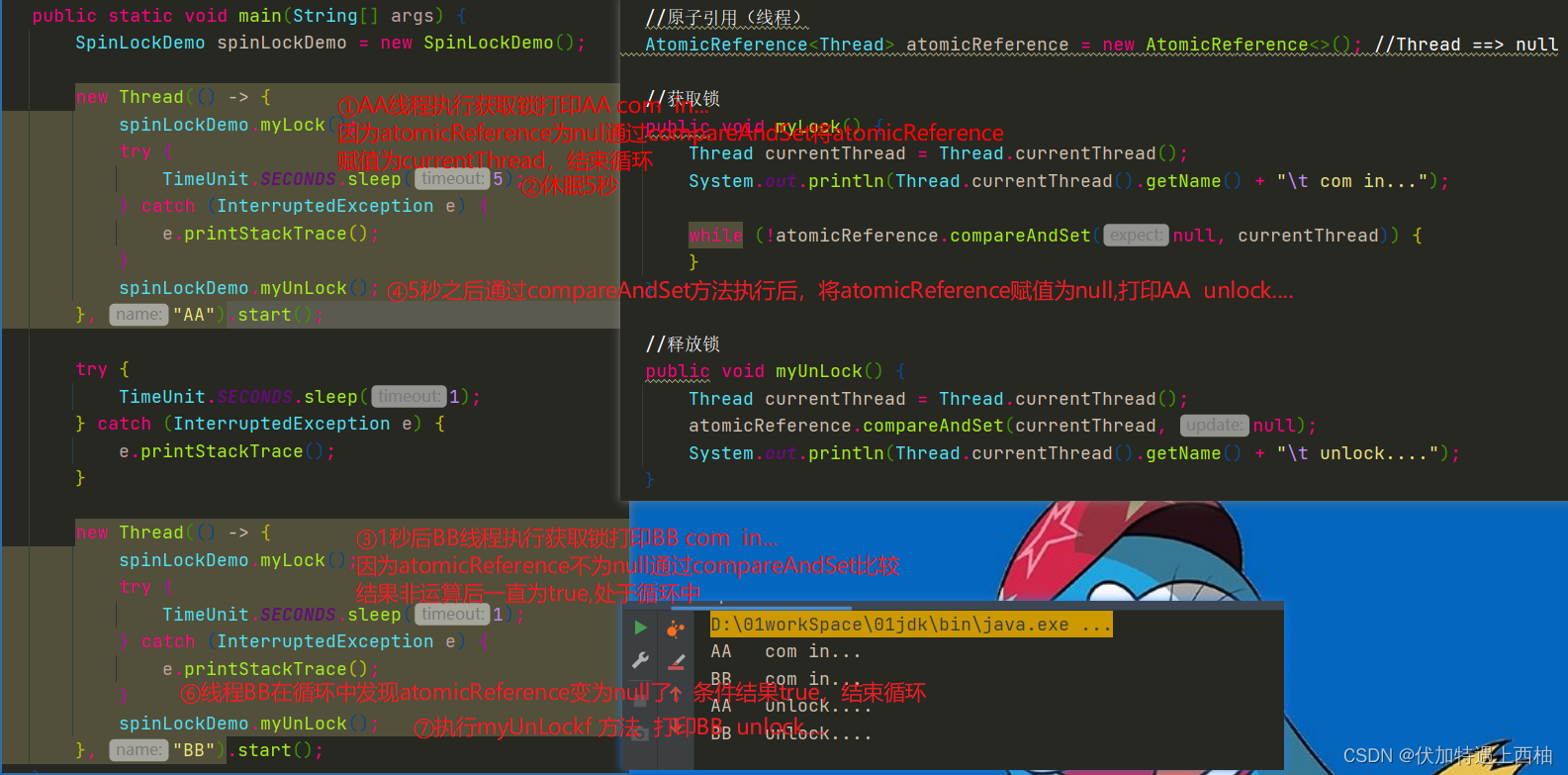
1、内存对齐规则
在学习内存对齐规则前,我们先一起了解下四个重要的基本概念:
指定对齐值:
#pragma pack (n) 时指定的对齐值 n;
基本数据类型的自身对齐值:
基本数据类型自身占用的存储空间大小,如 char 类型为 1,short 类型为 2,int 类型为 4,double 类型为 8 等;
结构体或类类型的自身对齐值:
结构体或类的成员中自身对齐值最大的值,如 struct a 中有 char、int 和 double 共 3 个类型的数据成员,那么 struct a 的自身对齐值是 8 字节;
数据成员、结构体和类的有效对齐值:
自身对齐值或指定对齐值中的较小值。
了解上述概念后,我们一起来了解具体的内存对齐规则。
内存地址对齐包含了两种相互独立又相互关联的部分:基本数据对齐和结构体数据对齐。
基本数据对齐比较简单,其自身对齐值就等于自身占用的存储空间大小,可以通过 alignof 获取一个类型的对齐值。
结构体数据对齐需要保证结构体的数据成员对齐以及结构体的整体对齐:
(1)数据成员对齐规则:
第一个数据成员放在 offset 为 0 的地方,也就是结构体变量本身的起始地址,以后每个数据成员的偏移为其有效对齐值的整数倍;
(2)结构体整体对齐规则:
在数据成员完成各自对齐后,结构体本身也要进行对齐,对齐会将结构体的大小增加为该结构体有效对齐值的整数倍,如有需要编译器会在最末成员后加上填充字节。
二、应用
1、前提介绍
在 KaiwuDB 时序引擎中,一条时序数据由不同的列数据组成,其中每列都对应一种数据类型。在存储的代码实现中,每条时序数据都存放在一块连续的内存空间里,不同列的数据按照列的顺序连续紧邻的排放,如下图所示:

值得一提的是,上图示例中的 char 类型,并非是一个字符,而是代表一个不定长的字符数组,也就是说这条数据的第二列,存放的是一个长度为 3 的 char 数组。另外,TIMESTAMP 的类型是 uint64_t,长度为 8 字节;Bitmap 的类型也是 char 数组,长度不定。
显然,这种存放方式并不满足内存对齐的要求,会对我们的程序产生两种可能的影响:
(1)在不同硬件平台上的程序 crash;
(2)降低存取效率。
由于我们的程序需要在 ARM 平台上运行,而且会有高密集地进行内存访问,所以时序数据存放满足内存对齐要求是十分必要的。
2、使用内存对齐生成存储格式
存储记录的数据类型可以分类为两种:
(1)定长:
TIMESTAMP、SMALLINT、INT、BIGINT、FLOAT、DOUBLE、BOOL、BINARY,长度包括 8、4、2、1 字节,都属于基本数据类型。前文介绍过,基本数据类型的对齐系数等于自身的类型长度。
(2)不定长:
char、Bitmap,这两种类型都是不定长的 char 数组,基本组成元素都是 char 类型,因此它们的对齐系数都为 1。
由上可知,目前存储中存放的都是一些基本数据类型记录,不存在结构体或类类型。在这个条件下,一条时序数据的格式满足内存对齐的要求就相对而言比较简单了,存储格式生成方案如下:
对于定长的数据类型对应的列,按类型长度降序排列,先存放 8 字节的列、再存放 4 字节的列、再存放 2 字节和 1 字节的列,这样就可以满足内存对齐的要求。
存放完定长的列后,char 和 Bitmap 都是 char 数组,对齐系数都为 1,所以可以直接存放在定长的列之后,先存放 char 类型,最后存放 Bitmap。
通过上述内存对齐的存储格式生成方案生成的一条时序数据的格式如下:

3、测试
通过编写一个简单的测试,验证一下内存对齐对存取效率的影响。
测试场景:
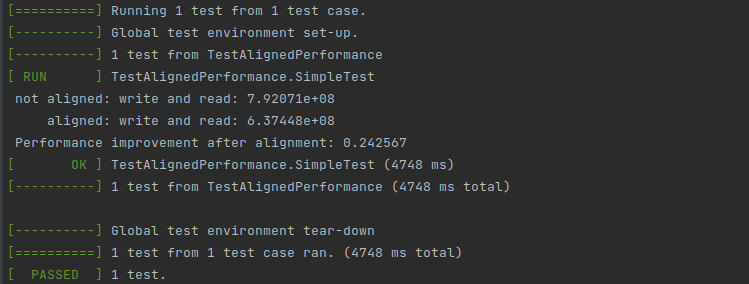
内存对齐系数为 8 字节,申请 10K 内存空间,在内存对齐和非内存对齐的情况下,分别写入数据 1G 次并且读取数据 1G 次。写入的数据类型均为 uint64_t,长度 8 字节,内存写满后循环使用。分别统计其耗时并进行对比,测试代码和测试结果如下:

测试结果显示,在只进行读写操作的情况下,进行 1G 次读写操作,非内存对齐要比内存对齐的耗时多 24.3% 左右。
END