文章目录
- 前言
- MySQL读写分离原理
- 搭建MySQL读写分离集群
- MySQL8.0之前
- MySQL8.0之后
- 后记
前言
上一期介绍并实现了MySQL的主从复制,由于主从复制架构仅仅能解决数据冗余备份的问题,从节点不对外提供服务,依然存在单节点的高并发问题
所以在主从复制的基础上,演变出了MySQL读写分离集群!
MySQL读写分离原理
在MySQL读写分离中:master节点专门用来做数据的修改操作(如create、update、insert、delete等),在主库上写,然后主库通过主从复制把数据的更改通过binlog同步到所有从库上
再将所有的查询操作都映射到从库上,这样就可以很好的分摊读写的压力,不用全部请求都集中在主库上,这样MySQL的并发处理能力就能得到极大的提高
**在MySQL8.0之前:**这个过程需要一个中间件(如MyCat,Sharding-JDBC等),识别解析客户端的所有请求,将所有的写操作映射到master节点,而读操作都转到slave从库上
MySQL8.0之后:MySQL自身已支持读写分离(支持一主多从的读写分离,多主多从的还是需要引入中间件实现)
一主多从的读写分离:
注意:MySQL8.0之后该一主多从的读写分离可不依赖中间件

搭建MySQL读写分离集群
MySQL8.0之前
1、下载MyCat安装包
下载MyCat:http://dl.mycat.org.cn
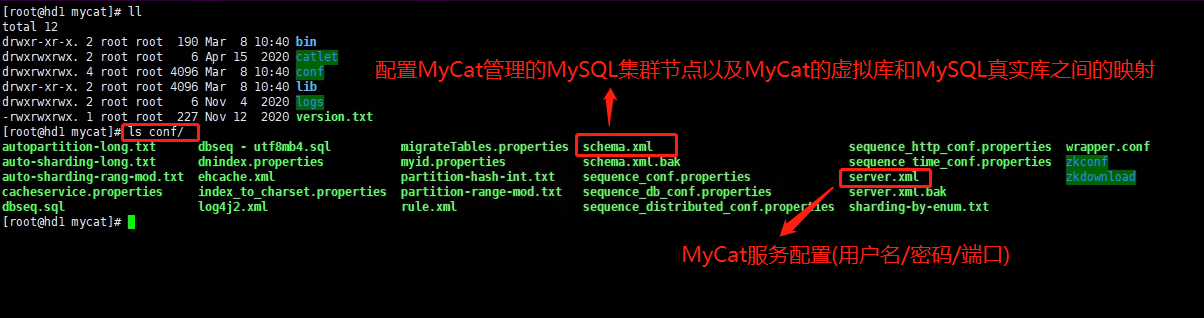
2、分别配置schema.xml和server.xml
我这里配置虚拟库meet0and1-schema映射到主从节点上的meet0and1真实库
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 定义MyCat的虚拟逻辑库,dataNode:映射真实数据节点 -->
<schema name="meet0and1-schema" checkSQLschema="false" sqlMaxLimit="800" dataNode="meet0and1Node" />
<!-- 定义MyCat的数据节点,name必须和dataNode值一致,dataHost映射真实主机,database映射真实的库 -->
<dataNode name="meet0and1Node" dataHost="meet0and1Host" database="meet0and1" />
<!-- 配置数据主机,name必须和dataHost一致 -->
<dataHost name="meet0and1Host" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<!--心跳检测-->
<heartbeat>select user()</heartbeat>
<!--主节点(写)-->
<writeHost host="hostM1" url="192.168.31.161:3306" user="root" password="123456">
<!--从节点(读)-->
<readHost host="hostS1" url="192.168.31.162:3306" user="root" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!-- 这里配置的都是一些系统属性-->
<system>
<!-- 默认的sql解析方式 -->
<property name="defaultSqlParser">druidparser</property>
<property name="charset">utf8mb4</property>
</system>
<!-- 配置登录mycat的用户信息 -->
<user name="root">
<property name="password">123456</property>
<!-- 该用户可以操作哪个逻辑库 -->
<property name="schemas">meet0and1-schema</property>
</user>
</mycat:server>
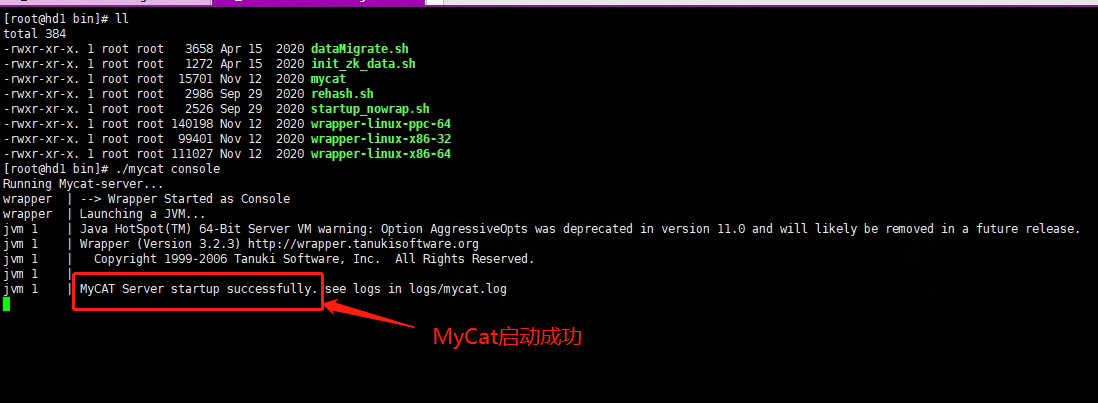
3、启动MyCat
在mycat的bin目录下,启动MyCat
# 以前台窗口启动
./mycat console
# 以后台守护进程启动
./mycat start
./mycat status
./mycat stop
./mycat restart
4、MyCat实现MySQL读写分离
修改properties连接MySQL配置
# MyCat的server.xml中配置的用户和密码
spring.datasource.username=root
spring.datasource.password=123456
# MyCat服务的端口8066,meet0and1-schema:MyCat中配置映射到meet0and1的虚拟库
spring.datasource.url=jdbc:mysql://192.168.31.161:8066/meet0and1-schema?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
**注意:**Spring中事务是支持传播的,MyCat为避免在一个查询中又执行了更新操作,而将连接请求转到slave从库导致主从数据不一致的情况,所以MyCat会开启了事务的连接请求都转到master主库
如下面的findAll方法,查询操作应该走从库,但由于在类上开启了事务,若方法上的事务传播属性不设置为SUPPORTS,执行这个方法就会走master主库
@Service
@Transactional(rollbackFor = Exception.class)
public class SysUserService {
@Autowired
private SysUserDao sysUserDao;
/**
* Propagation.SUPPORTS:支持事务的传播
* 有事务则融入:如其他含有事务的方法调用这个方法时,融入调用方的事务
* 没有则不开启事务:它自身的方法不开启事务,且这里覆盖了类上配置的事务
* (方法上的事务优先级大于类上开启的事务)
*/
@Transactional(propagation = Propagation.SUPPORTS)
public List<SysUser> findAll() {
return sysUserDao.findAll();
}
/**
* 执行写操作,会走master主库
*/
public void save(SysUser sysUser) {
sysUserDao.save(sysUser);
}
}
MySQL8.0之后
MySQL8.0之后一主多从的读写分离,可不再依赖任何中间件
1、连接MySQL时只有url配置有变化
# 语法:默认配置的第一个节点为主(写)库,后面的都为从(读)库
jdbc:mysql:replication://主(写)库,从(读)库1,从(读)库2,从(读)库N/库名
示例:
spring.datasource.url=jdbc:mysql:replication://192.168.31.161:3306,192.168.31.162:3306/meet0and1?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
2、只有显示设置方法的事务为只读(readOnly = true),并且单独执行它时才会走从(读)库
只有事务为只读的查询操作才走从(读)库!
为保证主从节点数据的一致性:当有其它service方法调用时,无论他们是否包含事务,即使不包含更新操作(insert/update/delete),走的都是主(写)库,如下面几种
@Service
public class SysUserService {
@Autowired
private SysUserMapper sysUserMapper;
/**
* 这里只有设置事务为只读,且单独执行该方法时才走从(读)库
*/
@Transactional(readOnly = true)
public List<SysUser> findAll(){
return sysUserMapper.findAll();
}
@Transactional
public void hasTranFind(){
// 走主(写)库
findAll().forEach(System.out::println);
}
public void notTranFind(){
// 走主(写)库
findAll().forEach(System.out::println);
}
public void notTranSave(SysUser sysUser){
// 走主(写)库
findAll().forEach(System.out::println);
sysUserMapper.save(sysUser);
}
/**
* 该方法执行会报错:Connection is read-only. Queries leading to data modification are not allowed
* (设置只读的事务方法中,不能有非查询操作)
*/
@Transactional(readOnly = true)
public List<SysUser> findAll2(SysUser sysUser){
sysUserMapper.save(sysUser);
return sysUserMapper.findAll();
}
}
后记
现在MyCat的社区和项目维护不是很友好,MySQL8.0之后自身虽支持一主多从的读写分离
但在并发极高的大型项目中要实现分库分表,读写分离和分布式主键等功能还是推荐Sharding-JDBC