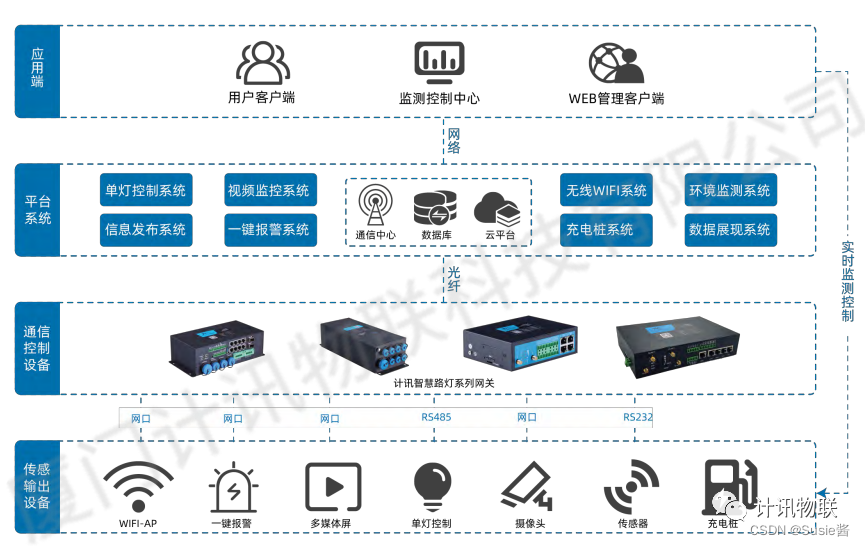
NLP现有的四个阶段:
- 完全有监督机器学习
- 完全有监督深度学习
- 预训练:预训练 -> 微调 -> 预测
- 提示学习:预训练 -> 提示 -> 预测
阶段1,word的本质是特征,即特征的选取、衍生、侧重上的针对性工程。
阶段2,对数据集与结构的抽象化构建,如卷积或 Attention。
阶段3,无监督方法,如BERT构建 MLM/NSP,及变体(PLM,DAE)都是更好的训练预训练模型。
阶段4,提示学习是让下游任务来适应语言模型,而不是让语言模型适应下游任务。
- 语言模型越大 = 微调难度越大
- 相信语言模型具有独立解决NLP问题的能力
使用prompt的原因
Prompt 本意在于下游任务使用模型的时候,尽可能与预训练模型pretrain阶段的任务保持一致。重定义下游任务,将下游任务均统一为预训练语言模型任务,避免预训练模型和下游任务之间存在的gap。之前使用BERT + finetune,有以下弊端:
-
finetune存在上下游任务不一致问题,破坏了BERT结构。下游任务通过标注数据驱动, finetune语义没有告知给模型。
对这两点弊端做出改进主要就是pretrain阶段和下游任务阶段能尽可能一致,以发挥MLM能力,即prompt 思想:上下游任务一致。衍生出auto prompt,soft prompt,连续 prompt等
finetune上下游阶段任务不一致的问题
finetune对BERT原来的结构破坏严重,pretrain阶段学习最主要的任务是MLM,prompt最开始的思路就是利用这个MLM,使下游任务变成MLM任务。
如任务情感分类,x = 我很累 y=负面。
第一步构造prompt,加入prompt,prompt = 我感觉很[MASK],得到给BERT的token为[CLS]我很累,感觉很[MASK][SEP]
第二步,构造MAKS token映射,即MASK预测的token映射到标签,比如负面可能的token有:难受,坏,烦,这样使上下游任务一致。
finetune语义没有告知模型
BERT是个语言模型,但finetune却让数据驱动参数变化,而不是先表明这个任务目的。而prompt就是在使用语言的通顺,pretrain阶段的语料也是通顺的语料,因此构建prompt,将句子X和prompt接起来是一个通顺的句子,使上下游一致。为让拼接语句通顺,结合场景设计prompt,如上面那个案例使用的prompt=感觉很[MASK],也可以promp=心情很[MASK]。
预训练模型越大,所需要的预训练预料就越大,参数越多。如果微调时没有足够的数据,就无法达到好的Fine-tuning效果。语言模型中的MLM预测结果能够较好地预测出指定的结果,其必定包含了很重要的上下文知识,即上下文特征。
预训练语言模型的知识相当丰富,没有必要为利用它而进行重构。
构建Prompt Engineering
Cloze Prompt和Prefix Pompt对应Prompt在句中还是句末。
通常根据预训练模型来选择:
- 需要用自回归语言模型解决的生成任务,Prefix Pompt更好,其符合模型从左到右的特点。
- 需要用自编码语言模型解决的掩码任务,Cloze Prompt更好,其和预训练任务形式匹配。
硬提示/离散提示(Hard Prompt/Discrete Prompt)
硬提示即搜索空间是离散的,需要算法工程师在下游任务上具备丰富的经验以及了解原预训练模型的底层概念,一般硬提示的准确率会不及Fine-tuning的SOTA,不同的Prompt对模型的影响非常大,如提示的长度、词汇位置等,一点Prompt的微小差别,可能会造成效果的巨大差异。
因此需要如下要求:
- 设计一个合适的提示模板,创造一个完形填空的题目
- 设计一个合适的填空答案,创造一个完型填空的选项
第一步构造prompt;第二步,构造MAKS token映射。都涉及人为因素,prompt的几个字都能导致模型效果的较大变化。为减少人工设计“构造prompt”,“MAKS token映射”,提出auto-prompt。
具体有以下这么几种方式:
- Prompt Mining:从大的语料库中进行挖掘(如挖掘输入与输出间高频词作为模板构建元素)
- Prompt Paraphrasing:参考文本数据增强方法,可以做seed Prompt的同义词替换,跨语种翻译等
- Gradient-based Search:从候选词中选择一些作为Prompt并参与训练,根据梯度下降对选择词重新排列组合
- Prompt Generation:通过文本生成模型直接生成一个Prompt
- Prompt Scoring:根据语言模型对所有候选Prompt打分,选择一个对高分的Prompt使用
上述Hard Prompt方法会输出可被人类理解的句子。
AUTOPROMPT
使用提示学习的方式做文本分类、文本蕴涵判断任务。不对预训练语言模型做任何改动(结构或参数),使用基于梯度搜索得到的优质提示模板,就可以让预训练语言模型具有良好的文本分类能力。使用语言模型做关系抽取任务,并与关系数据库、有监督的关系抽取模型进行比较,发现BERT这样的预训练语言模型可以较好地完成实体关系抽取任务,证明预训练语言模型中存储了大量与实体关系有关的知识。
为了去除人工设计带来的变数,auto-prompt针对自动“构造prompt”,自动选择“MASK token映射”。
第一步,构造prompt,选择loss下降最大的prompt token,先给定mask映射词,也就是:[CLS] {sentence} [T] [T] [T] [MASK]. [SEP],先用假设的[T],获取[MASK],再用得到的[MASK]映射用数据驱动选择[T]
第二步,构造MAKS token映射,使用上下文的MASK token的output embedding作为x,与label训练一个logistic,logistic得分高的向量更能表示label.使用上下文MASK token的output token的embedding给打分函数,取得分top-k。
注意large模型的mlm能力更强,而在做分类任务finetune中,large和base的能力差距则不明显。大多数情况,模型参数量越大MLM能力越强, prompt论文都是large起步。
基础提示模板:
改造后的关系抽取任务目标是预测“Dante was born in [T] [T] [T] [T] [Mask]”中[MASK]为遮蔽的部分,[T]是用来引导模型的触发词(trigger word)。触发词就是“提示”信息,这些触发词可以提升语言模型的分类能力。
AUTOPROMPT的模板由2个部分构成:
掩码:直接追加到文本后面、让语言模型去预测。预测多个词语比较困难,因此将所有的类别表示为单个token;只预测客体(Dante was born in [Mask]),不预测主体(In [Mask] Dante was born)和关系。
触发词(trigger word):“提示”信息,触发词可提升语言模型在下游任务中的能力。
类标签词:
使用ERNIE的词汇表,有18018个type。
优质类标签词集合的搜索:在情感极性二分类任务中,为两个类别各配置若干标签词(降低方预测方差)。对于一些任务,词汇表中存在很多相关性特别强的type,可设定为某些类的标签词,比如“乐”字之于“积极”类。可使用自动方法来为各个类别搜索类标签词:用情感二分类语料,为每一个类别训练一个逻辑回归模型,
![]()
![]()
hi是语言模型接收文本后 [MASK] 位置输的logits向量,逻辑回归模型的权重和偏置带有情感二分类任务的信息。注意,这里需要预训练语言模型进行的前向计算次数,与训练样本个数相等,不是很大。“估计”类别与词语的联合概率分布。比如说(积极类,乐)的概率估计方式为:
![]()
embedding(乐)为词向量,可从预训练模型处直接查到;
为每个类别选择联合概率最高的k个标签词,构成各类的标签词集合。保证各类标签词数量相等的目的,是配合类标签词概率到类别概率分布的换算。
类标签词到标签的映射:
当语言模型输出对[MASK]处token属于词汇表各个type的概率分布,就可以快速计算情感极性类别了。预训练语言模型中蕴含的知识或模式是既定的,不一定会按照预想的方式预测——需要给一些“提示”,引导模型去做下游任务(或是用提示信息“激活”某种模式)。
LAMA把若干触发词添加到文本和[MASK]中间,作为提示信息(简单粗暴的做法)。开始的时候,触发词集合是J个[T]。实际处理文本时,会添加[MASK]标签。将分类数据分为若干batch,每处理一个batch,就会更新一次触发词集合。更新搜索触发词集合的操作,是一个beam search的过程:逐个地遍历当前样本的各个[T],从词汇表中找出k个候选触发词,从k个候选触发词中找出对模型提升作用最大的,用它替换当前位置的原有触发词。
寻找k个候选触发词所用的指标计算方法:计算一个batch样本的平均loss,然后计算第k个触发词对应词向量的梯度(词向量每一个维度上的参数,对应一个梯度); 遍历词汇表,计算每一个type的词向量,与(a)所得梯度向量的点积,就是指标取值。该指标的含义是,将原有触发词替换成当前type,可以给预测效果(似然概率)带来的提升幅度。
从k个候选触发词中选择最终词语的过程:遍历k个词语,将第j个触发词替换为当前词语,并执行前项过程,获得概率值;选择概率值最大时,对应的那个词语,作为最终的词语。文中没有提及这k个词不如原有第j个触发词时的处理方式。把原有的第j个触发词,替换为最终找到的词语。
软提示/连续提示(Soft Prompt/Continuous Prompt)
由于硬提示的相对不稳定性(过多融入语言符号),软提示概念即将Prompt的生成作为模型的一个任务来学习,将定性的语言转化为机器进行自搜索的过程。Prompt 开始变了,将离散的prompt token换成可训练的prompt token向量。离散prompt的是以token喂给bert的,连续prompt就是把这些token替换成向量,直接把通过了bert emebdding层的prompt token的向量替换成可训练参数,冻结BERT,只训练3*768这个矩阵
- Prefix-tuning:在输出前加上一串连续的向量(前缀prefix),保持PLM参数不变,仅训练该向量。在给定可训练前缀矩阵M和θ参数化的固定PLM对下面的对数似然函数优化:
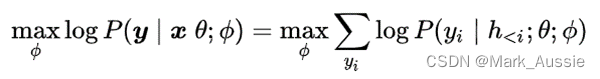


提示学习的关键方法
基于提示学习已有的工作,其主要模块或方法:
(1)输入改造模板。目标是给语言模型“最合适”的提示。
(2)标签词。目标是让语言模型“最容易”预测到。
(3)标签词与类别概率分布的转换方式。让语言模型输出与下游任务对应。
小结
算法工程师的主要任务,就是基于业务场景、结合实际资源情况选择尽可能匹配的方法来完成任务——这个选择的重要依据是方法在一些常见维度上的特性,或者说相对其他方法的优劣。
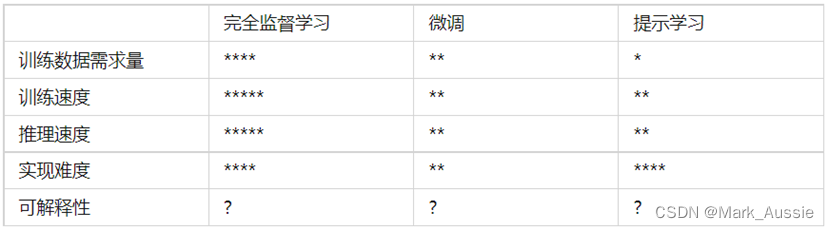
星号越多表示该指标取值越大
提示学习充分利用了语言模型在学习大规模语料后得到的知识、和模式,以及文本生成能力,在训练数据很少甚至没有的情况下,完成分类、阅读理解等任务。相比端到端的方法,提示学习框架结构复杂多变、实现难度较大,对广大工程师不是很亲和。
提示模板的设计,类似特征工程工作,对领域知识和数据挖掘能力要求比较高。需要注意的是,提示学习的一些策略需要基于“开发集”来优化提示模板,模型过拟合的概率比较大。一些提示学习工作,使用规模较大的开发集或测试集来优化提示模板,实际上脱离了“小样本”这个场景——实际的小样本场景中,训练集和测试集都很小。一些人把“对抗学习”的目标换改为“帮助”,应用到提示学习中。比如,AutoPrompt就借鉴了对抗学习的方法来搜索优质模板。
垂直领域应用越来越多,需要 预训练语言模型在低资源的情况下快速形成工作能力。提示学习是微调之后又一种非常好的策略,可以帮助预训练语言模型快速形成战斗力。提示学习是一种人工主导的。

参考:
Prompt Learning(提示学习) - 简书
prompt到底行不行 - 知乎
提示学习(Prompt Learning)——低资源场景的福音 - 知乎
Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章