Kafka 分区机制
- 分区策略
- 轮询策略
- 随机策略
- 按消息键保序策略
- 基于地理位置的分区策略
主题 (Topic) :承载真实数据的逻辑容器,主题下还分 n 个分区
Kafka 消息的三级结构:
- 主题 - 分区 - 消息
- 主题下的每条消息只会保存在某个分区中,而不会在多个分区中被保存多份
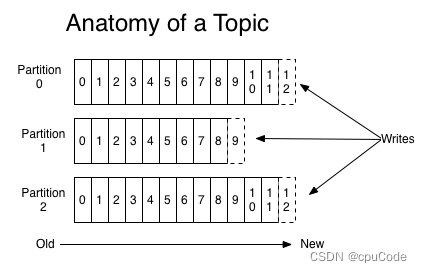
分区的作用 : 提供负载均衡的能力 , 为了实现系统的高伸缩性(Scalability)
- 不同的分区能放在不同节点上
- 每个节点能独立处理各自分区的读写请求处理
- 添加新节点能增加整体系统的吞吐量
分区策略
分区策略 :生产者将消息发送到哪个分区的算法
自定义分区策略 : 实现 org.apache.kafka.clients.producer.Partitioner接口 , 定义方法:partition() , close()
实现 partition 方法
int partition(String topic, Object key,
byte[] keyBytes, Object value,
byte[] valueBytes, Cluster cluster);
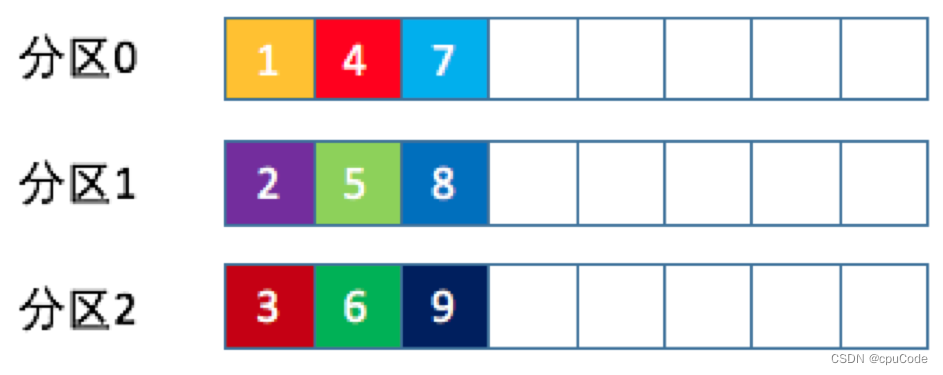
轮询策略
轮询策略 (Round-robin 策略) : 顺序分配
- 生产者 API 默认的分区策略
- 有很好的负载均衡,能保证消息最大限度的平均分配到所有分区上
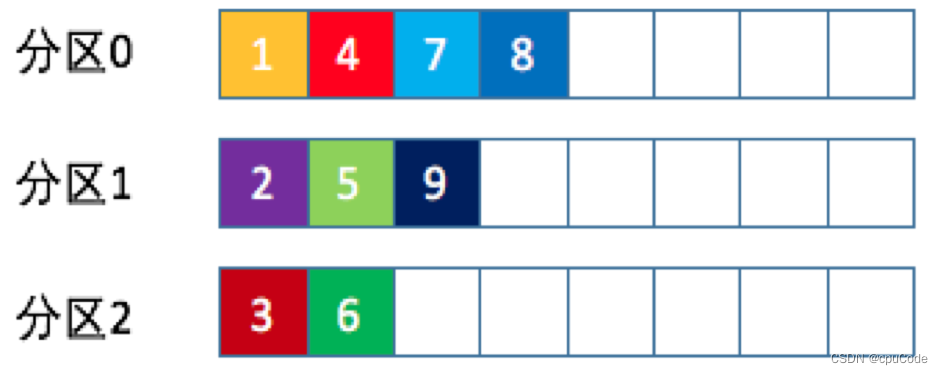
随机策略
随机策略 (Randomness 策略) : 随机将消息放到任意一个分区上
- 随机策略是老版本生产者使用的分区策略
- 数据的均匀分布,还是轮询策略更好
随机策略的 partition 方法 :
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
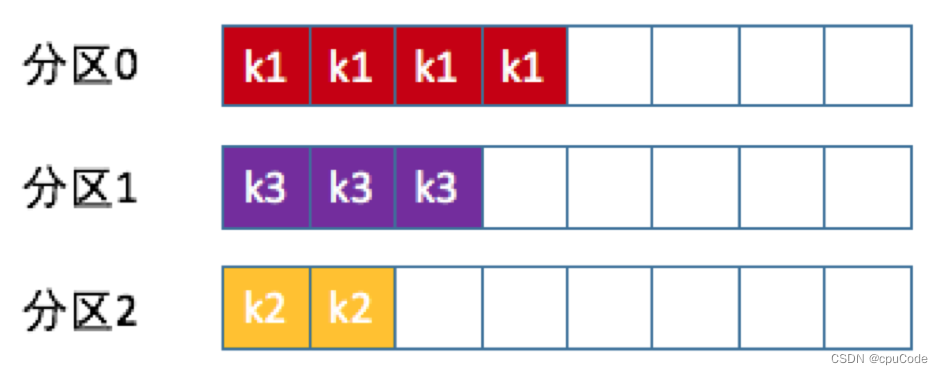
按消息键保序策略
按消息键保序策略 (Key-ordering 策略) : 为每条消息定义消息键 (Key) , 同个 Key 的消息都会进入到同个分区,每个分区数据都是顺序处理
partition 方法
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();
基于地理位置的分区策略
基于地理位置的分区策略 : 适合那些大规模的 Kafka 集群,跨城市、跨国家、跨大洲的集群
例子 : 从北京,广州机房,选取一部分机器组成一个 Kafka 集群
- 当南方的用户注册,送别墅,而北方的用户注册,送跑车
- 把南北注册用户的消息发送到南北的不同机房
根据 Broker 的 IP 地址实现定制化的分区策略
List<PartitionInfo> partitions =
cluster.partitionsForTopic(topic);
return partitions.stream()
.filter(p -> isSouth(p.leader().host()))
.map(PartitionInfo::partition).findAny().get();