Hive窗口函数
其他函数: Hive—Hive函数
文章目录
- Hive窗口函数
- 开窗
- 数据准备
- 建表
- 导入数据
- 聚合函数
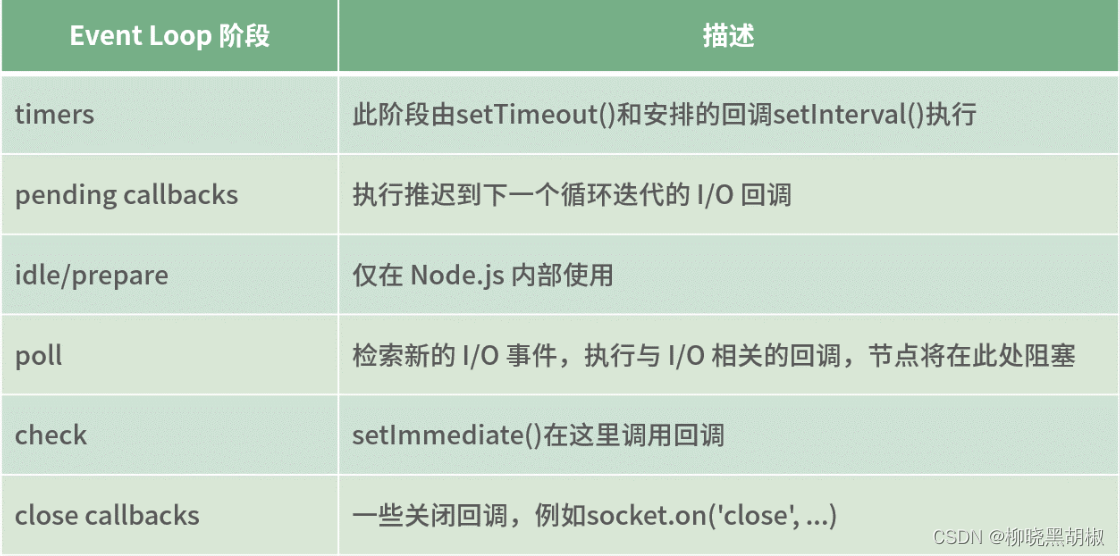
- window子句
- LAG(col,n,default_val) 往前第 n 行数据
- LEAD(col,n, default_val) 往后第 n 行数据
- ROW_NUMBER() 会根据顺序计算
- RANK() 排序相同时会重复,总数不会变
- DENSE_RANK() 排序相同时会重复,总数会减少
- first_value取分组内排序后,截止到当前行,第一个值
- last_value取分组内排序后,截止到当前行,最后一个值
- NTILE(n) 数据切片函数
开窗
又称开窗函数
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
数据准备
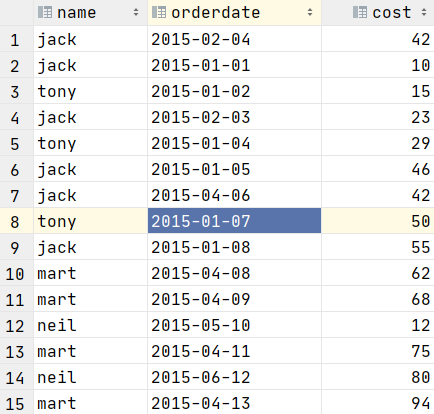
字段为 name,orderdata,cost
jack,2015-01-01,10
tony,2015-01-02,15
jack,2015-02-03,23
tony,2015-01-04,29
jack,2015-01-05,46
jack,2015-04-06,42
tony,2015-01-07,50
jack,2015-01-08,55
mart,2015-04-08,62
mart,2015-04-09,68
neil,2015-05-10,12
mart,2015-04-11,75
neil,2015-06-12,80
mart,2015-04-13,94
建表
----建表------
create table if not exists t_window(
name string,
orderdate date,
cost int
)
导入数据
原始数据的已经上传到hdfs上
load data inpath '/order.csv' into table t_window;
# 查看数据
select * from t_window;
聚合函数
常见聚合函数(count(),sum(),max(),min(),avg()……)
---全表数据cost的总和
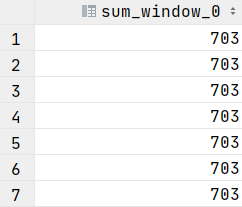
select name,orderdate,cost,sum(cost) over () from t_window;
window子句
UNBOUNDED 起点
CURRENT ROW 当前行
n PRECEDING 往前 n 行数据
n FOLLOWING 往后 n 行数据
UNBOUNDED PRECEDING 表示从前面的起点
UNBOUNDED FOLLOWING 表示到后面的终点
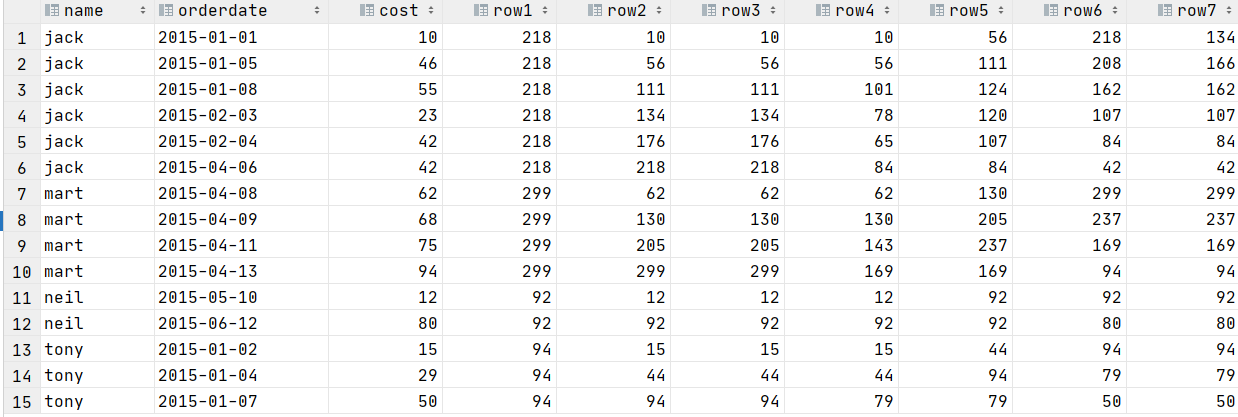
select name,orderdate,cost,
sum(cost) over (partition by name order by orderdate rows between unbounded preceding and unbounded following) as row1,---个人累计消费总和
sum(cost) over(partition by name order by orderdate) as row2,--个人截止到当前时间的消费总和
sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row ) as row3,--个人截止到当前时间的消费总和
sum(cost) over(partition by name order by orderdate rows between 1 preceding and current row ) as row4,---当前消费额与上一次消费额的总和
sum(cost) over(partition by name order by orderdate rows between 1 preceding and 1 following ) as row5, --前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as row6,--当前行及后面所有行
sum(cost) over(partition by name order by orderdate rows between current row and 3 following) as row7 --当前消费与后三次的消费总额
from t_window;
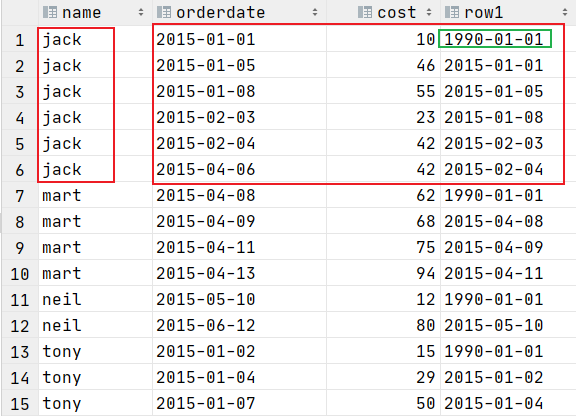
LAG(col,n,default_val) 往前第 n 行数据
分区内滞后当前行的参数值
select name,orderdate,cost,
-----前一个日期
lag(orderdate,1,'1990-01-01') over (partition by name order by orderdate) as row1
from t_window;
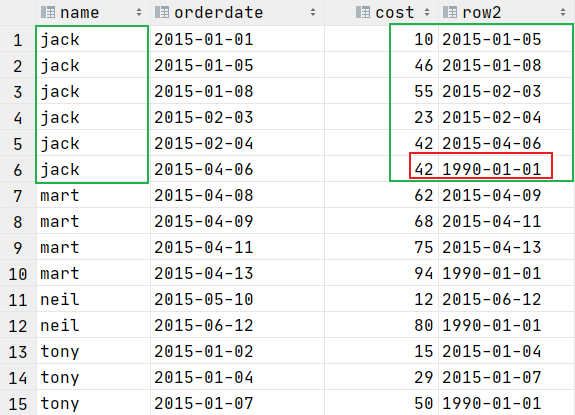
LEAD(col,n, default_val) 往后第 n 行数据
分区内当前行前导行的参数值
select name,orderdate,cost,
----后一个日期
lead(orderdate,1,'1990-01-01') over (partition by name order by orderdate) as row2
from t_window;
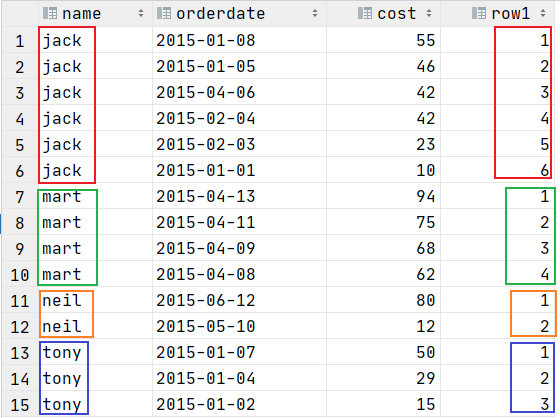
ROW_NUMBER() 会根据顺序计算
row_number()从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列
---根据名字分区,消费金额降序排序
select name,orderdate,cost,
row_number() over (partition by name order by cost desc ) as row1
from t_window;
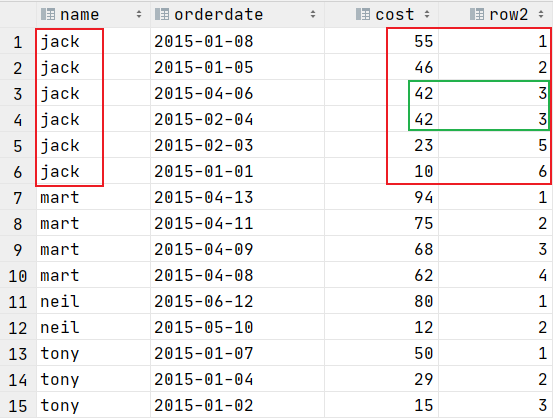
RANK() 排序相同时会重复,总数不会变
rank() 生成数据项在分组中的排名,排名相等会在名次中留下空位
select name,orderdate,cost,
rank() over (partition by name order by cost desc )as row2
from t_window;
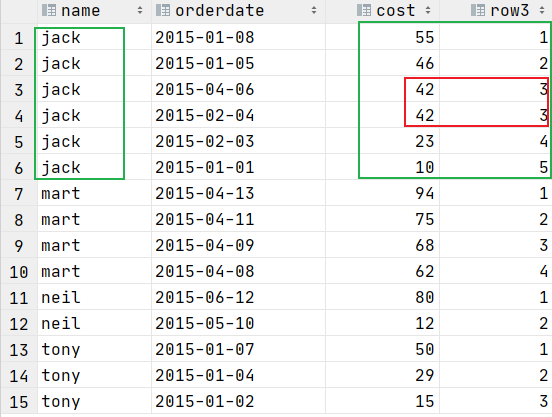
DENSE_RANK() 排序相同时会重复,总数会减少
dense_rank() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
select name,orderdate,cost,
dense_rank() over (partition by name order by cost desc )as row3
from t_window;
first_value取分组内排序后,截止到当前行,第一个值
select name,orderdate,cost
--------按名字分区,查询第一笔消费的时间与所有时间对比(有需求查询员工的入职时间,与此类似)
,first_value(orderdate)over (partition by name order by orderdate)as time1
from t_window;
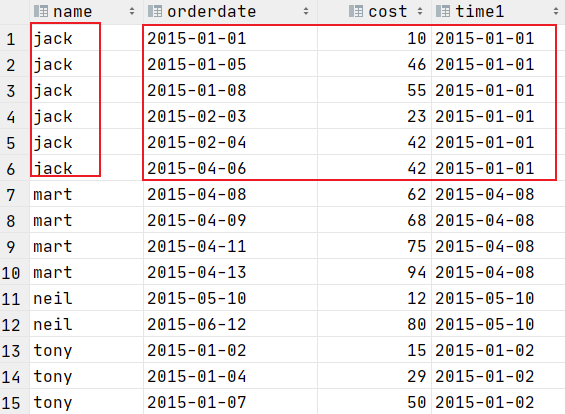
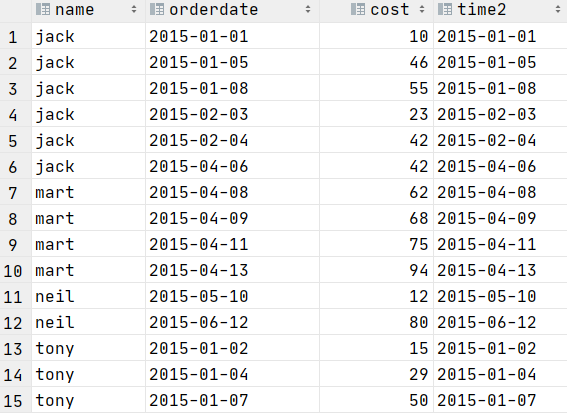
last_value取分组内排序后,截止到当前行,最后一个值
select name,orderdate,cost
--------按名字分区,查询当前行的最后一个时间
,last_value(orderdate)over (partition by name order by orderdate)as time2
from t_window;
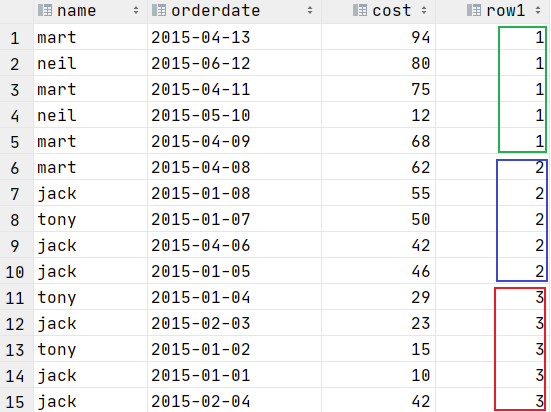
NTILE(n) 数据切片函数
把有序窗口的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对于每一行,NTILE 返回此行所属的组的编号
注意:n 必须为 int 类型
select name,orderdate,cost,
ntile(3) over() as row1---把数据分成三份
from t_window;
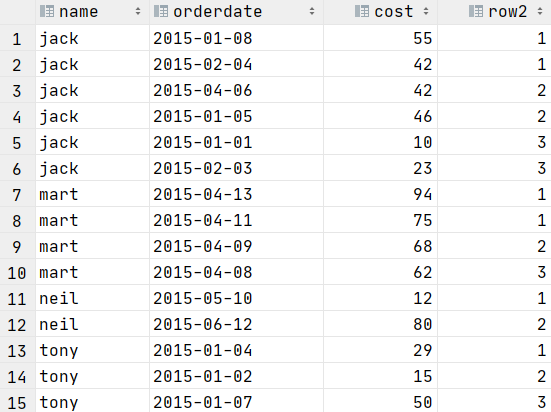
select name,orderdate,cost,
ntile(3) over(partition by name)as row2---按名字分组 切片成三份
from t_window;