前言
事实证明,读过Linux内核源码确实有很大的好处,尤其在处理问题的时刻。当你看到报错的那一瞬间,就能把现象/原因/以及解决方案一股脑的在脑中闪现。甚至一些边边角角的现象都能很快的反应过来是为何。笔者读过一些Linux TCP协议栈的源码,就在解决下面这个问题的时候有一种非常流畅的感觉。
Bug现场
首先,这个问题其实并不难解决,但是这个问题引发的现象倒是挺有意思。先描述一下现象吧,
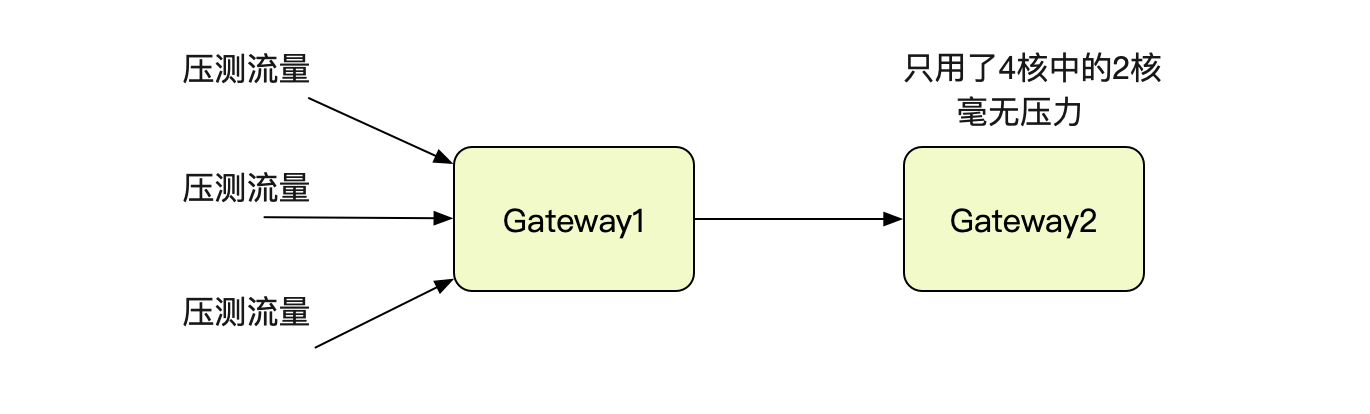
笔者要对自研的dubbo协议隧道网关进行压测(这个网关的设计也挺有意思,准备放到后面的博客里面)。先看下压测的拓扑吧:
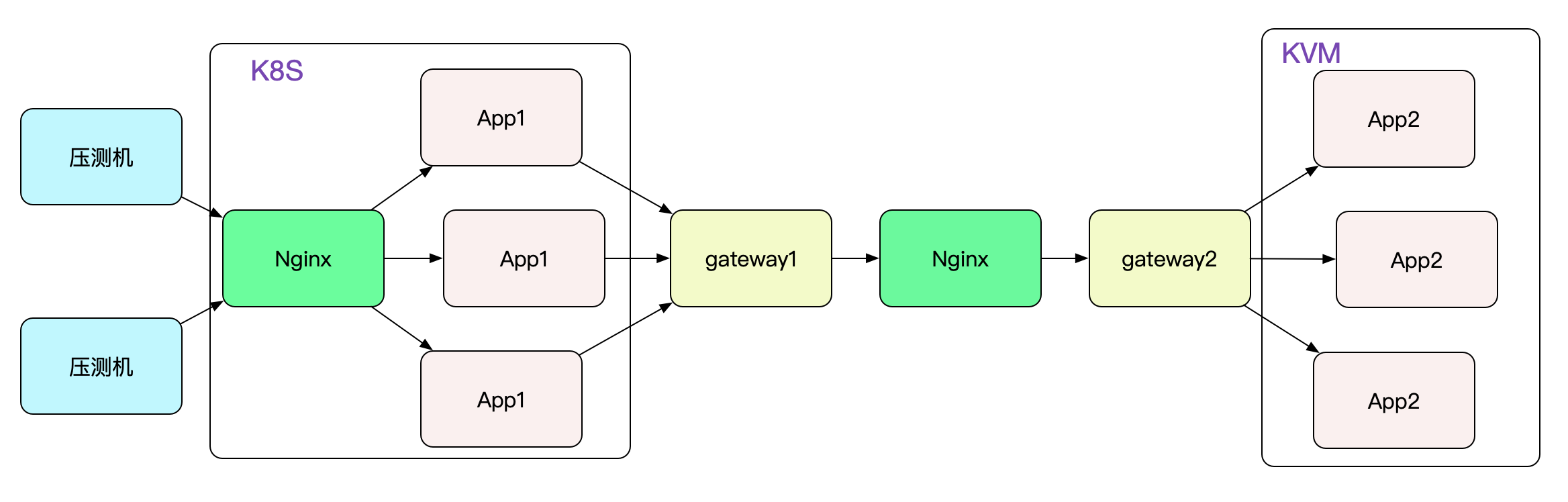
为了压测笔者gateway的单机性能,两端仅仅各保留一台网关,即gateway1和gateway2。压到一定程度就开始报错,导致压测停止。很自然的就想到,网关扛不住了。
网关的情况
去Gateway2的机器上看了一下,没有任何报错。而Gateway1则有大量的502报错。502是Bad Gateway,Nginx的经典报错,首先想到的就是Gateway2不堪重负被Nginx在Upstream中踢掉。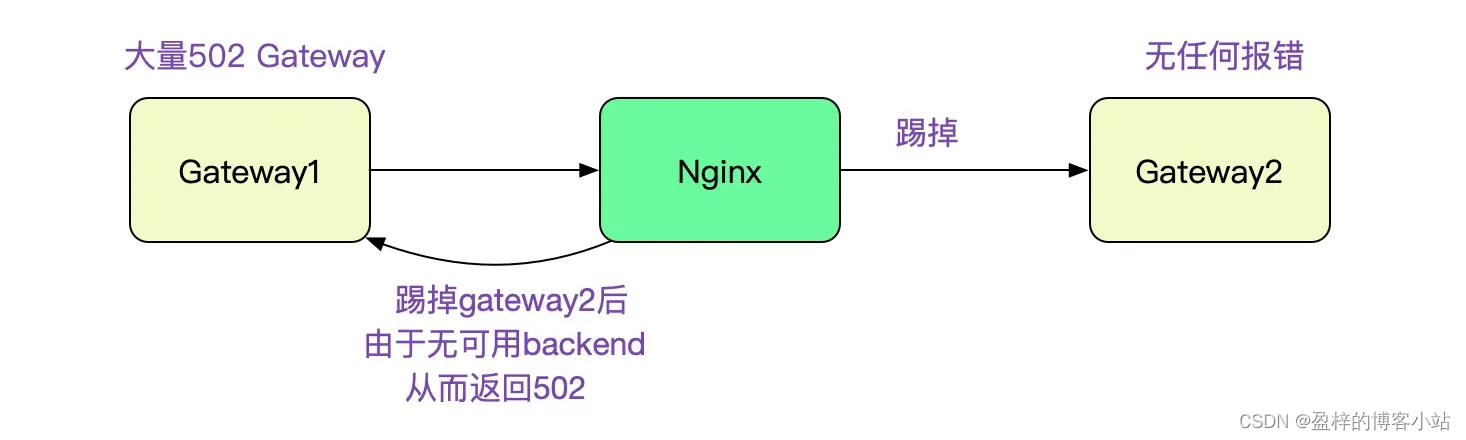
那么,就先看看Gateway2的负载情况把,查了下监控,发现Gateway2在4核8G的机器上只用了一个核,完全看不出来有瓶颈的样子,难道是IO有问题?看了下小的可怜的网卡流量打消了这个猜想。
Nginx所在机器CPU利用率接近100%
这时候,发现一个有意思的现象,Nginx确用满了CPU!
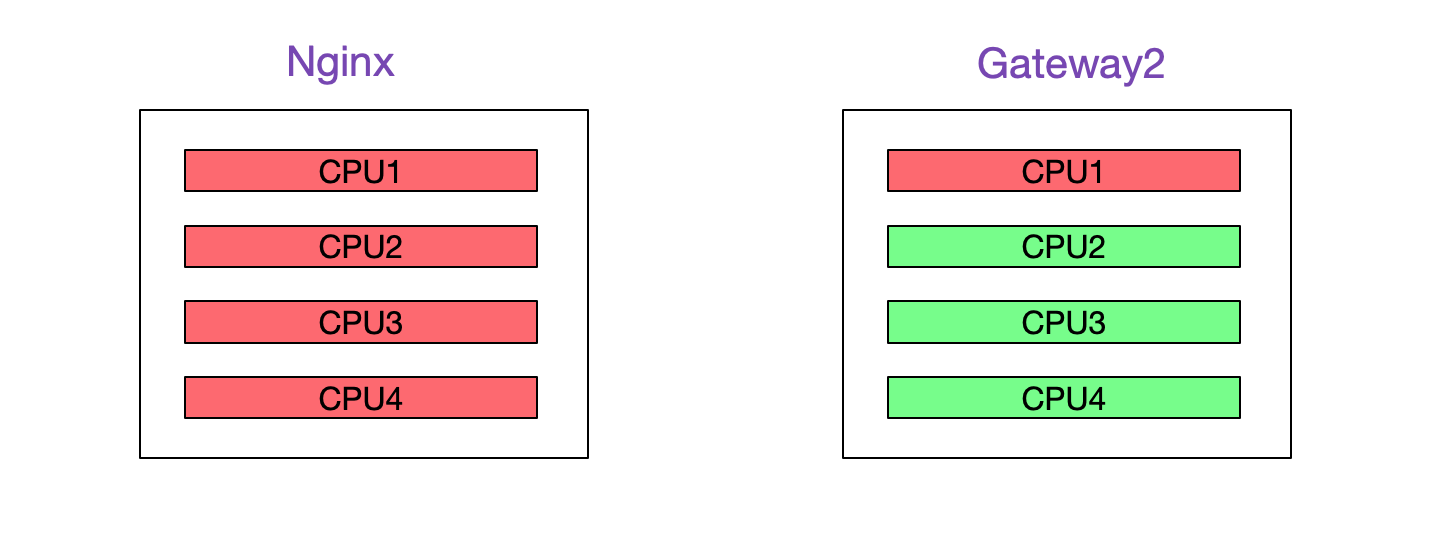
再次压测,去Nginx所在机器上top了一下,发现Nginx的4个Worker分别占了一个核把CPU吃满-_-!
什么,号称性能强悍的Nginx竟然这么弱,说好的事件驱动\epoll边沿触发\纯C打造的呢?一定是用的姿势不对!
去掉Nginx直接通信毫无压力
既然猜测是Nginx的瓶颈,就把Nginx去掉吧。Gateway1和Gateway2直连,压测TPS里面就飙升了,而且Gateway2的CPU最多也就吃了2个核,毫无压力。
去Nginx上看下日志
由于Nginx机器权限并不在笔者手上,所以一开始没有关注其日志,现在就联系一下对应的运维去看一下吧。在accesslog里面发现了大量的502报错,确实是Nginx的。又看了下错误日志,发现有大量的
Cannot assign requested address
由于笔者读过TCP源码,一瞬间就反应过来,是端口号耗尽了!由于Nginx upstream和后端Backend默认是短连接,所以在大量请求流量进来的时候回产生大量TIME_WAIT的连接。
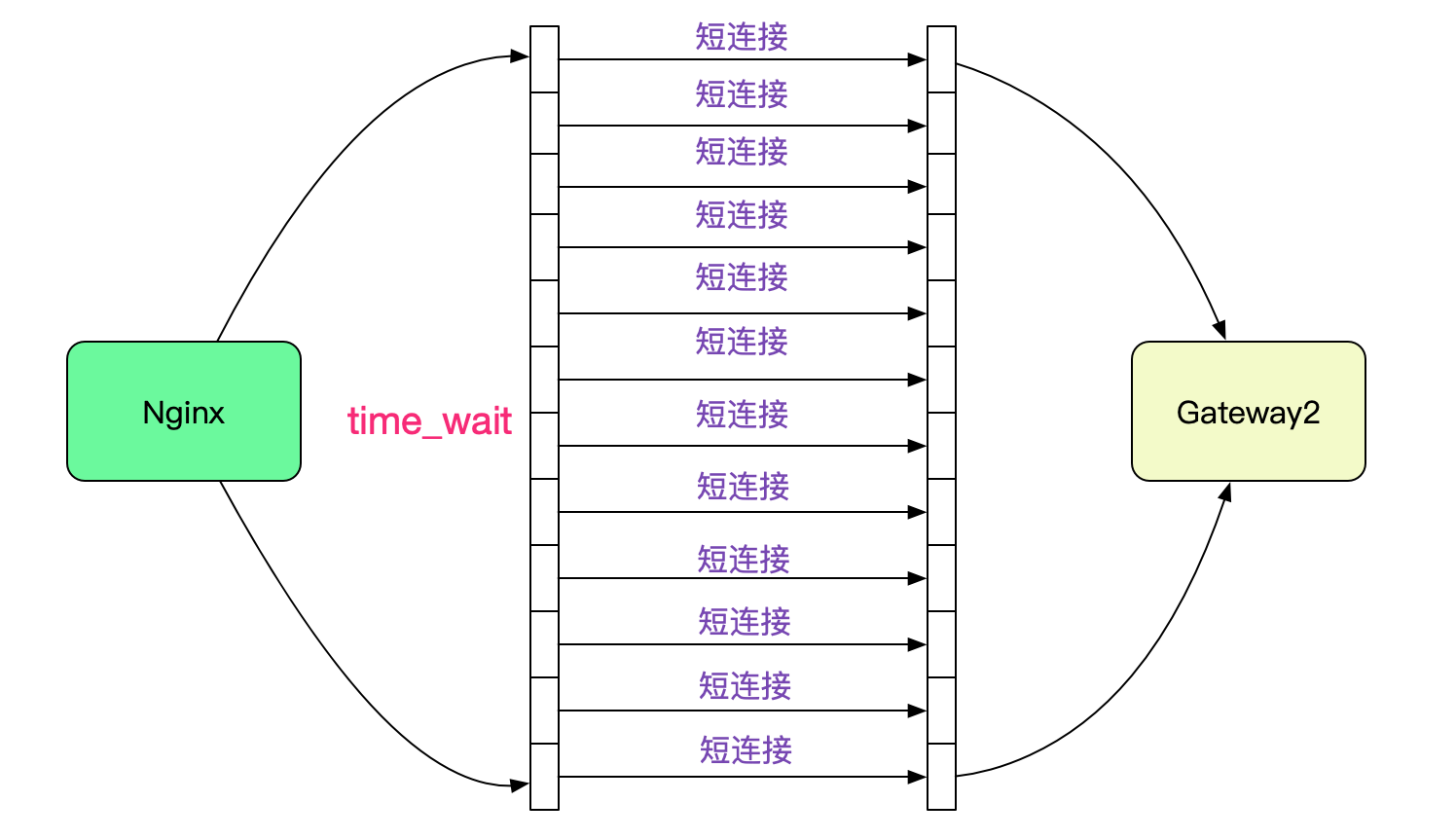
而这些TIME_WAIT是占据端口号的,而且基本要1分钟左右才能被Kernel回收。
cat /proc/sys/net/ipv4/ip_local_port_range
32768 61000
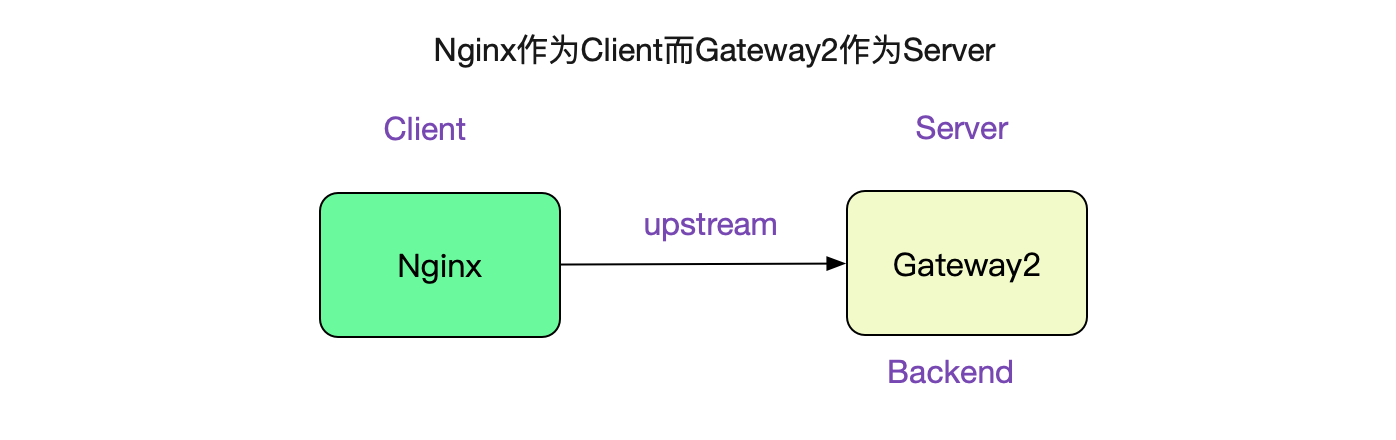
也就是说,只要一分钟之内产生28232(61000-32768)个TIME_WAIT的socket就会造成端口号耗尽,也即470.5TPS(28232/60),只是一个很容易达到的压测值。事实上这个限制是Client端的,Server端没有这样的限制,因为Server端口号只有一个8080这样的有名端口号。而在
upstream中Nginx扮演的就是Client,而Gateway2就扮演的是Nginx
为什么Nginx的CPU是100%
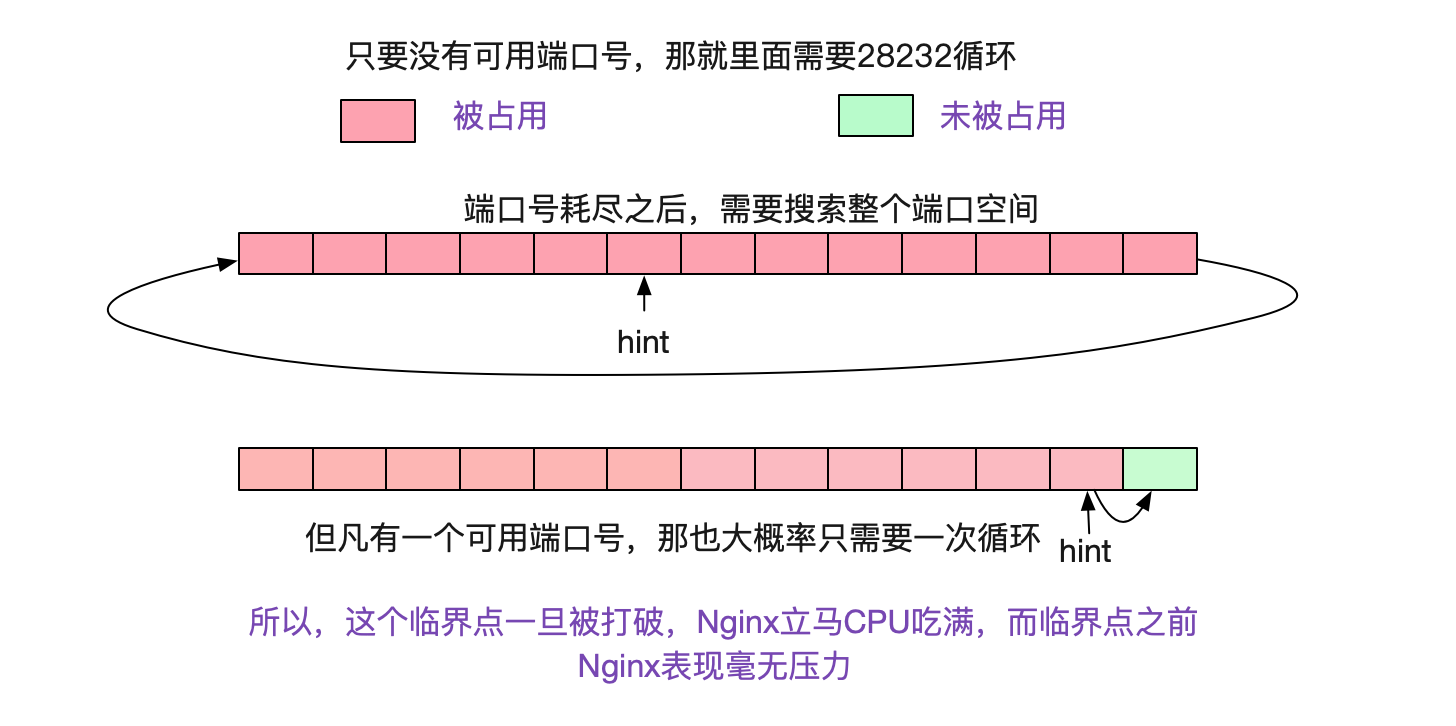
而笔者也很快想明白了Nginx为什么吃满了机器的CPU,问题就出来端口号的搜索过程。

让我们看下最耗性能的一段函数:
int __inet_hash_connect(...)
{
// 注意,这边是static变量
static u32 hint;
// hint有助于不从0开始搜索,而是从下一个待分配的端口号搜索
u32 offset = hint + port_offset;
.....
inet_get_local_port_range(&low, &high);
// 这边remaining就是61000 - 32768
remaining = (high - low) + 1
......
for (i = 1; i <= remaining; i++) {
port = low + (i + offset) % remaining;
/* port是否占用check */
....
goto ok;
}
.......
ok:
hint += i;
......
}
看上面那段代码,如果一直没有端口号可用的话,则需要循环remaining次才能宣告端口号耗尽,也就是28232次。而如果按照正常的情况,因为有hint的存在,所以每次搜索从下一个待分配的端口号开始计算,以个位数的搜索就能找到端口号。如下图所示:
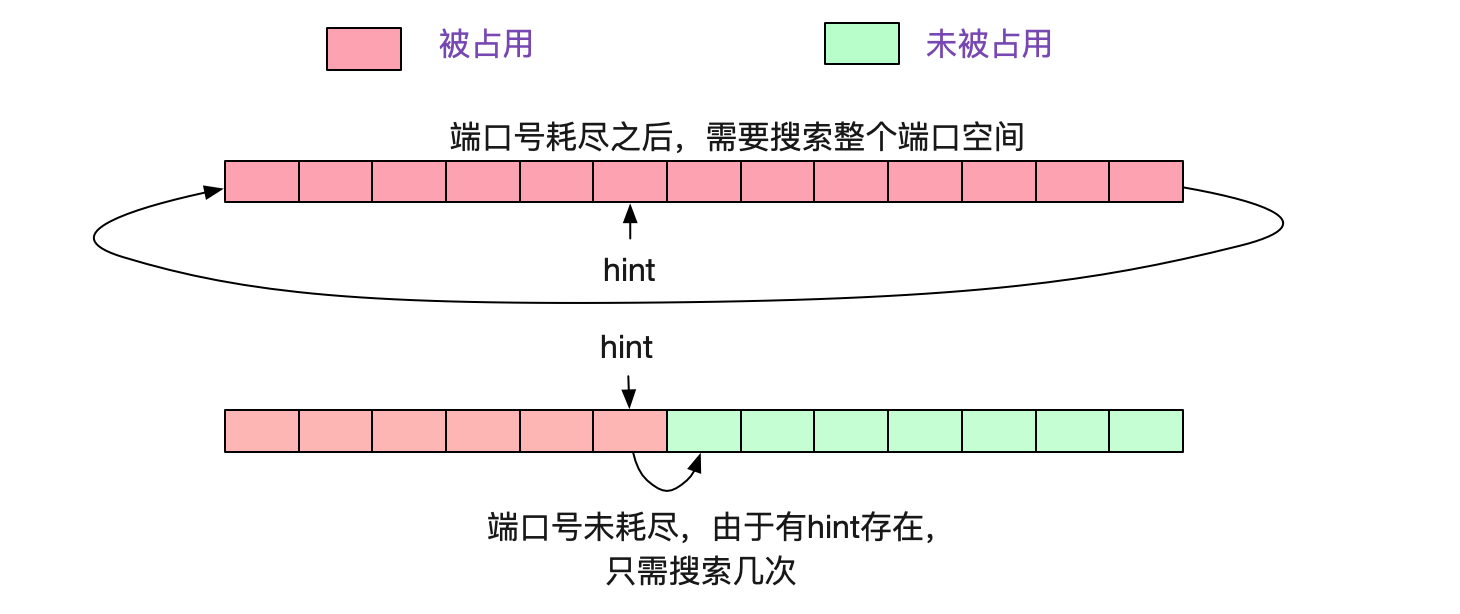
所以当端口号耗尽后,Nginx的Worker进程就沉浸在上述for循环中不可自拔,把CPU吃满。
为什么Gateway1调用Nginx没有问题
很简单,因为笔者在Gateway1调用Nginx的时候设置了Keepalived,所以采用的是长连接,就没有这个端口号耗尽的限制。
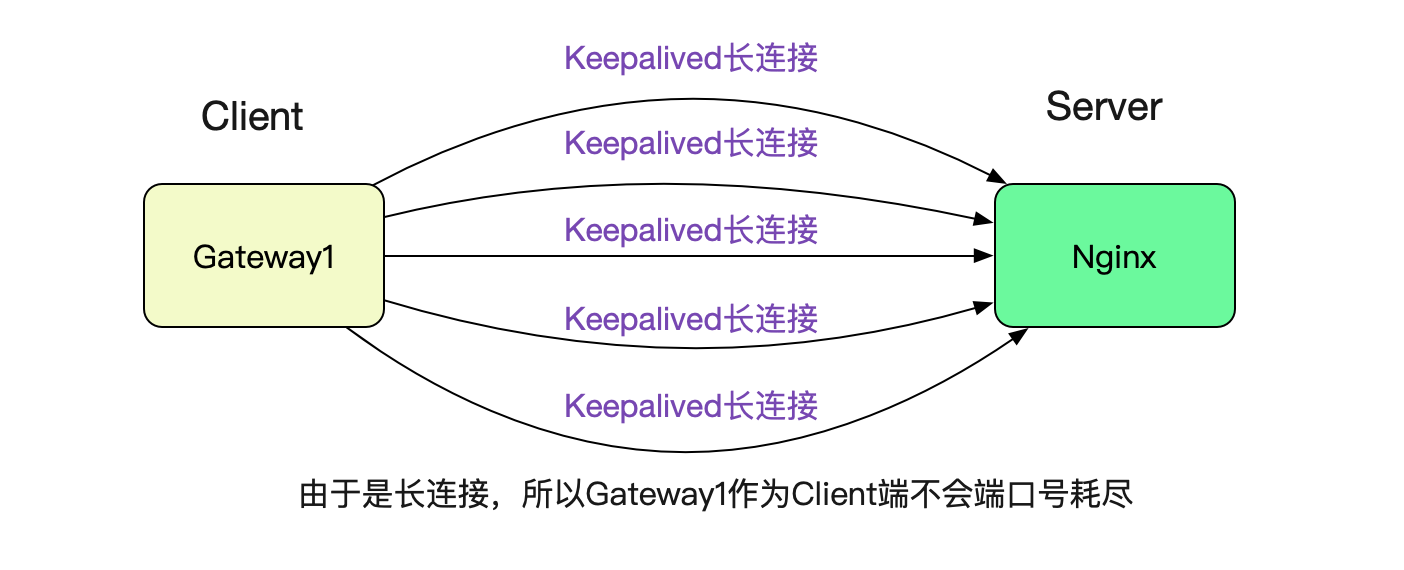
Nginx 后面有多台机器的话
由于是因为端口号搜索导致CPU 100%,而且但凡有可用端口号,因为hint的原因,搜索次数可能就是1和28232的区别。
因为端口号限制是针对某个特定的远端server:port的。
所以,只要Nginx的Backend有多台机器,甚至同一个机器上的多个不同端口号,只要不超过临界点,Nginx就不会有任何压力。
把端口号范围调大
比较无脑的方案当然是把端口号范围调大,这样就能抗更多的TIME_WAIT。同时将tcp_max_tw_bucket调小,tcp_max_tw_bucket是kernel中最多存在的TIME_WAIT数量,只要port范围 - tcp_max_tw_bucket大于一定的值,那么就始终有port端口可用,这样就可以避免再次到调大临界值得时候继续击穿临界点。
cat /proc/sys/net/ipv4/ip_local_port_range
22768 61000
cat /proc/sys/net/ipv4/tcp_max_tw_buckets
20000
开启tcp_tw_reuse
这个问题Linux其实早就有了解决方案,那就是tcp_tw_reuse这个参数。
echo '1' > /proc/sys/net/ipv4/tcp_tw_reuse
事实上TIME_WAIT过多的原因是其回收时间竟然需要1min,这个1min其实是TCP协议中规定的2MSL时间,而Linux中就固定为1min。
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
2MSL的原因就是排除网络上还残留的包对新的同样的五元组的Socket产生影响,也就是说在2MSL(1min)之内重用这个五元组会有风险。为了解决这个问题,Linux就采取了一些列措施防止这样的情况,使得在大部分情况下1s之内的TIME_WAIT就可以重用。下面这段代码,就是检测此TIME_WAIT是否重用。
__inet_hash_connect
|->__inet_check_established
static int __inet_check_established(......)
{
......
/* Check TIME-WAIT sockets first. */
sk_nulls_for_each(sk2, node, &head->twchain) {
tw = inet_twsk(sk2);
// 如果在time_wait中找到一个match的port,就判断是否可重用
if (INET_TW_MATCH(sk2, net, hash, acookie,
saddr, daddr, ports, dif)) {
if (twsk_unique(sk, sk2, twp))
goto unique;
else
goto not_unique;
}
}
......
}
而其中的核心函数就是twsk_unique,它的判断逻辑如下:
int tcp_twsk_unique(......)
{
......
if (tcptw->tw_ts_recent_stamp &&
(twp == NULL || (sysctl_tcp_tw_reuse &&
get_seconds() - tcptw->tw_ts_recent_stamp > 1))) {
// 对write_seq设置为snd_nxt+65536+2
// 这样能够确保在数据传输速率<=80Mbit/s的情况下不会被回绕
tp->write_seq = tcptw->tw_snd_nxt + 65535 + 2
......
return 1;
}
return 0;
}
上面这段代码逻辑如下所示:
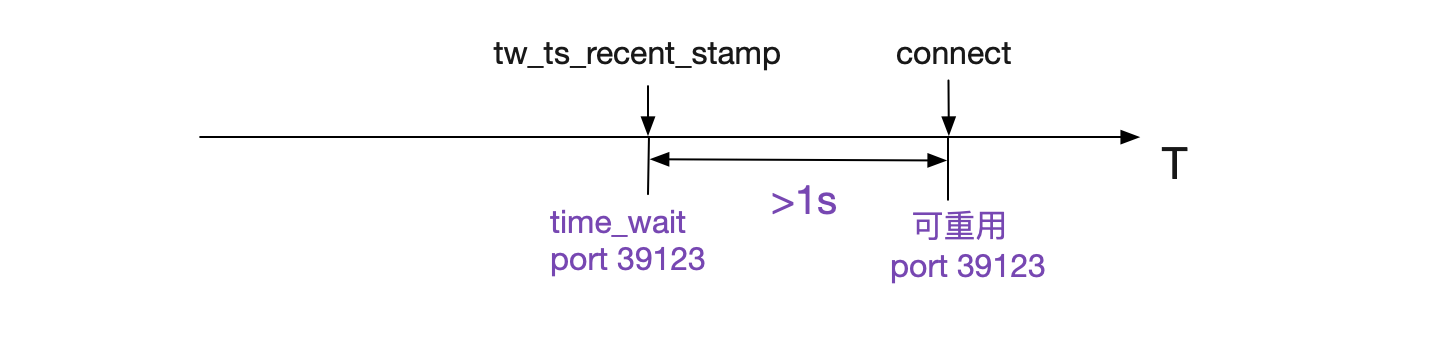
在开启了tcp_timestamp以及tcp_tw_reuse的情况下,在Connect搜索port时只要比之前用这个port的TIME_WAIT状态的Socket记录的最近时间戳>1s,就可以重用此port,即将之前的1分钟缩短到1s。同时为了防止潜在的序列号冲突,直接将write_seq加上在65537,这样,在单Socket传输速率小于80Mbit/s的情况下,不会造成序列号重叠(冲突)。
同时这个tw_ts_recent_stamp设置的时机如下图所示:
所以如果Socket进入TIME_WAIT状态后,如果一直有对应的包发过来,那么会影响此TIME_WAIT对应的port是否可用的时间。
开启了这个参数之后,由于从1min缩短到1s,那么Nginx单台对单Upstream可承受的TPS就从原来的470.5TPS(28232/60)一跃提升为28232TPS,增长了60倍。
如果还嫌性能不够,可以配上上面的端口号范围调大以及tcp_max_tw_bucket调小继续提升tps,不过tcp_max_tw_bucket调小可能会有序列号重叠的风险,毕竟Socket不经过2MSL阶段就被重用了。
不要开启tcp_tw_recycle
开启tcp_tw_recyle这个参数会在NAT环境下造成很大的影响,建议不开启。
Nginx upstream改成长连接
事实上,上面的一系列问题都是由于Nginx对Backend是短连接导致。
Nginx从 1.1.4 开始,实现了对后端机器的长连接支持功能。在Upstream中这样配置可以开启长连接的功能:
upstream backend {
server 127.0.0.1:8080;
# It should be particularly noted that the keepalive directive does not limit the total number of connections to upstream servers that an nginx worker process can open. The connections parameter should be set to a number small enough to let upstream servers process new incoming connections as well.
keepalive 32;
keepalive_timeout 30s; # 设置后端连接的最大idle时间为30s
}
这样前端和后端都是长连接,大家又可以愉快的玩耍了。
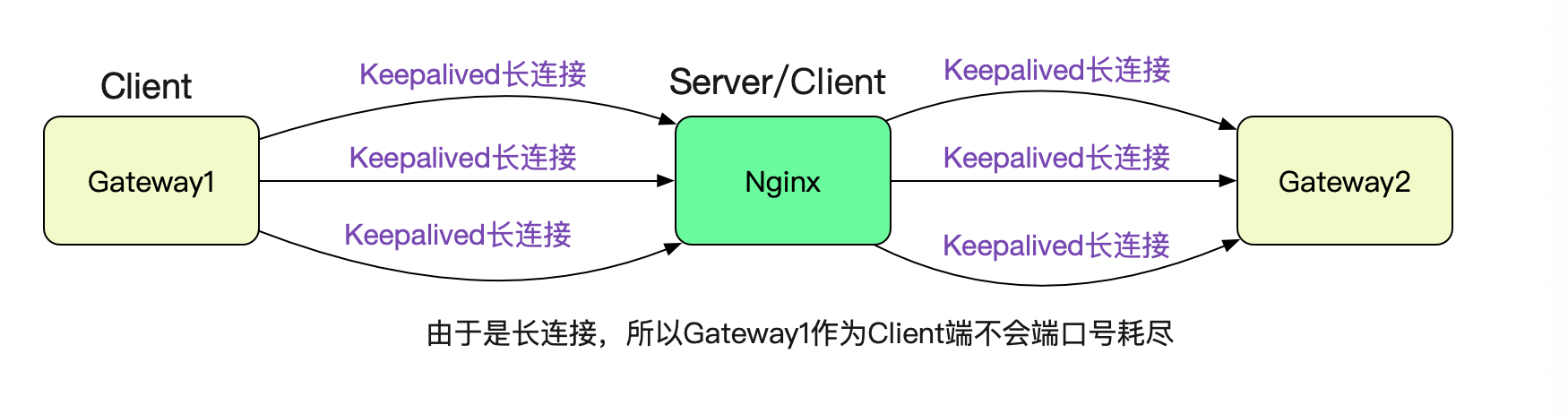
由此产生的风险点
由于对单个远端ip:port耗尽会导致CPU吃满这种现象。所以在Nginx在配置Upstream时候需要格外小心。假设一种情况,PE扩容了一台Nginx,为防止有问题,就先配一台Backend看看情况,这时候如果量比较大的话击穿临界点就会造成大量报错(而应用本身确毫无压力,毕竟临界值是470.5TPS(28232/60)),甚至在同Nginx上的非此域名的请求也会因为CPU被耗尽而得不到响应。多配几台Backend/开启tcp_tw_reuse或许是不错的选择。
总结
应用再强大也还是承载在内核之上,始终逃不出Linux内核的樊笼。所以对于Linux内核本身参数的调优还是非常有意义的。如果读过一些内核源码,无疑对我们排查线上问题有着很大的助力,同时也能指导我们避过一些坑!