WordCount(流处理)
通过socket数据源,去请求一个socket服务(9999),得到数据流然后统计数据流中出现的单词及其个数
1.创建一个编程入口,生成环境
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 批处理入口环境
StreamExecutionEnvironment env = StreamExecutionEnvironment. getExecutionEnvironment(); //流批一体的入口环境
2.设置该环境的默认并行度
streamEnv.setParallelism(1);本地运行模式时,程序的默认并行度为CPU的逻辑核数
3.通过source算子,把socket数据源加载为一个dataStream(数据流)
DataStreamSource<String> source = env.socketTextStream("localhost", 9999);4.通过算子对数据流进行各种转换(计算逻辑)
SingleOutputStreamOperator<Tuple2<String, Integer>> words = source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
//切单词
String[] split = s.split("//s+");
for (String word : split) {
//返回每一对(单词,1)
collector.collect(Tuple2.of(word, 1));
}
}
});输入数据流由文本行组成,flatMap 函数将每行拆分为单独的单词,并将它们作为单独的输出元素发出。生成的数据流包含所有输入行中的所有单词。
KeyedStream<Tuple2<String, Integer>, String> Keyed = words.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> tuple2) throws Exception {
return tuple2.f0;
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> resultStream = Keyed.sum("f1");将输入数据流 words 转换成一个键控流 (KeyedStream),使用 .keyBy() 方法指定按照元组中的第一个元素 f0 进行键控,也就是相同的 f0 值将被分到同一个分区中。这里用了匿名类实现了 KeySelector 接口,用于从元组中提取出键值。然后,调用 .sum() 方法对键控流进行求和操作。由于之前已经根据元组中的第一个元素进行了分区,所以对每个分区内所有元组的第二个元素 f1 求和得到的结果是每个不同键的数量总和。最后,将结果流 resultStream 作为输出。
5.通过sink算子,将结果输出
resultStream.print();6.触发程序运行
env.execute();7.程序测试
通过netcat来创建一个socket连接

监听端口9999,当有实体连接时,就可以相互发送socket信息
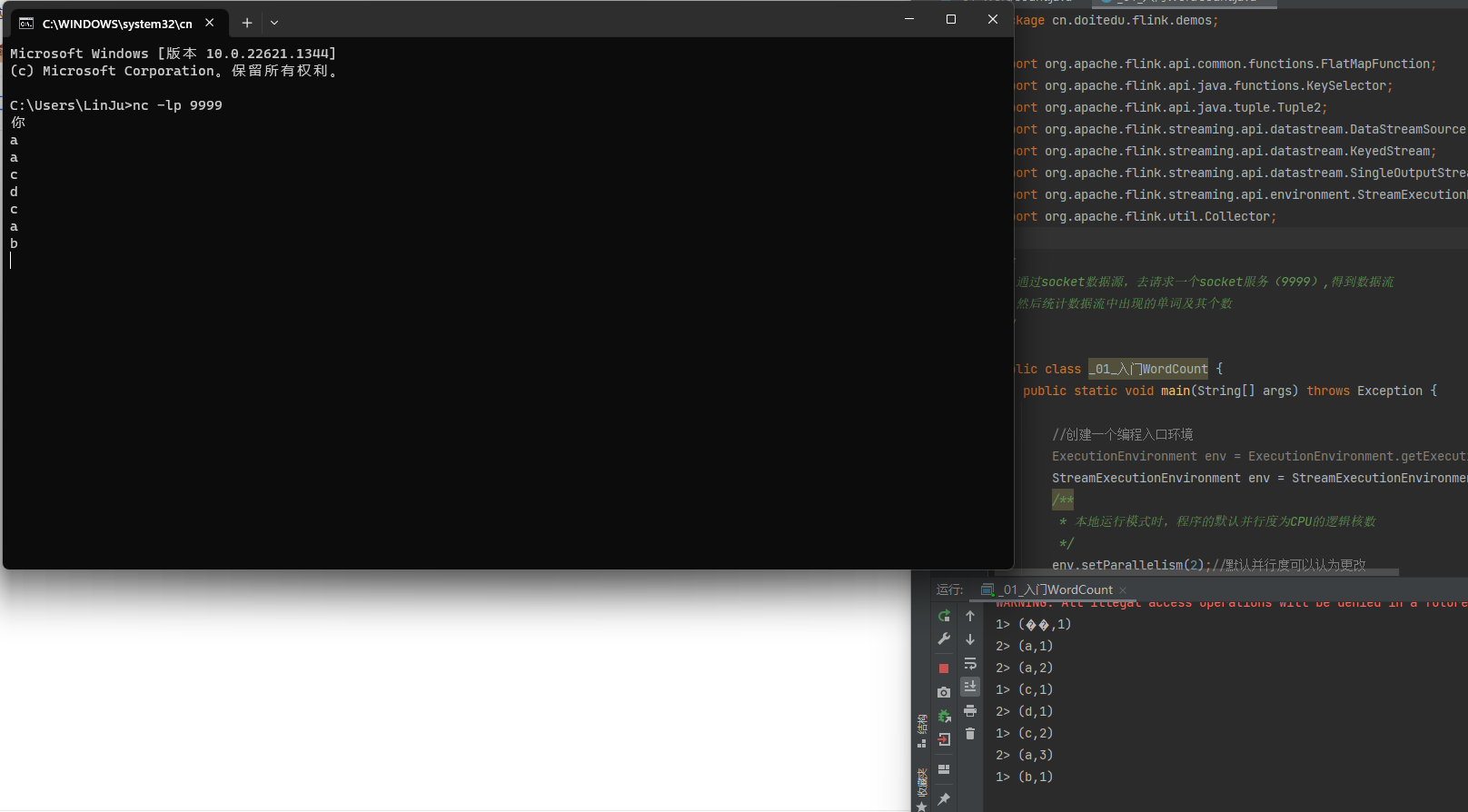
当连接后,我们输入词以后,程序会对这些词进行分区统计