在线测试
Project #4 - Concurrency Control
以下是Project #4的网址,2022FALL的Project #4是实现并发控制,可以分为以下三个任务:
- 我们首先需要实现一个锁管理器,能够支持 READ_UNCOMMITED、READ_COMMITTED、REPEATABLE_READ 三个隔离级别,以及相应的上锁解锁;
- 其次我们需要实现死锁检测,并能够中止最年轻的事务;
- 最后我们需要对 Project 3 中实现的 SeqScanExecutor 、InsertExecutor 、DeleteExecutor 三个算子进行改进,使其能够支持相应的上锁解锁以实现不同的隔离级别。
我们首先需要明确, Bustub 中的锁管理器通过 2PL 实现并发控制,其中的三种隔离级别分别为:
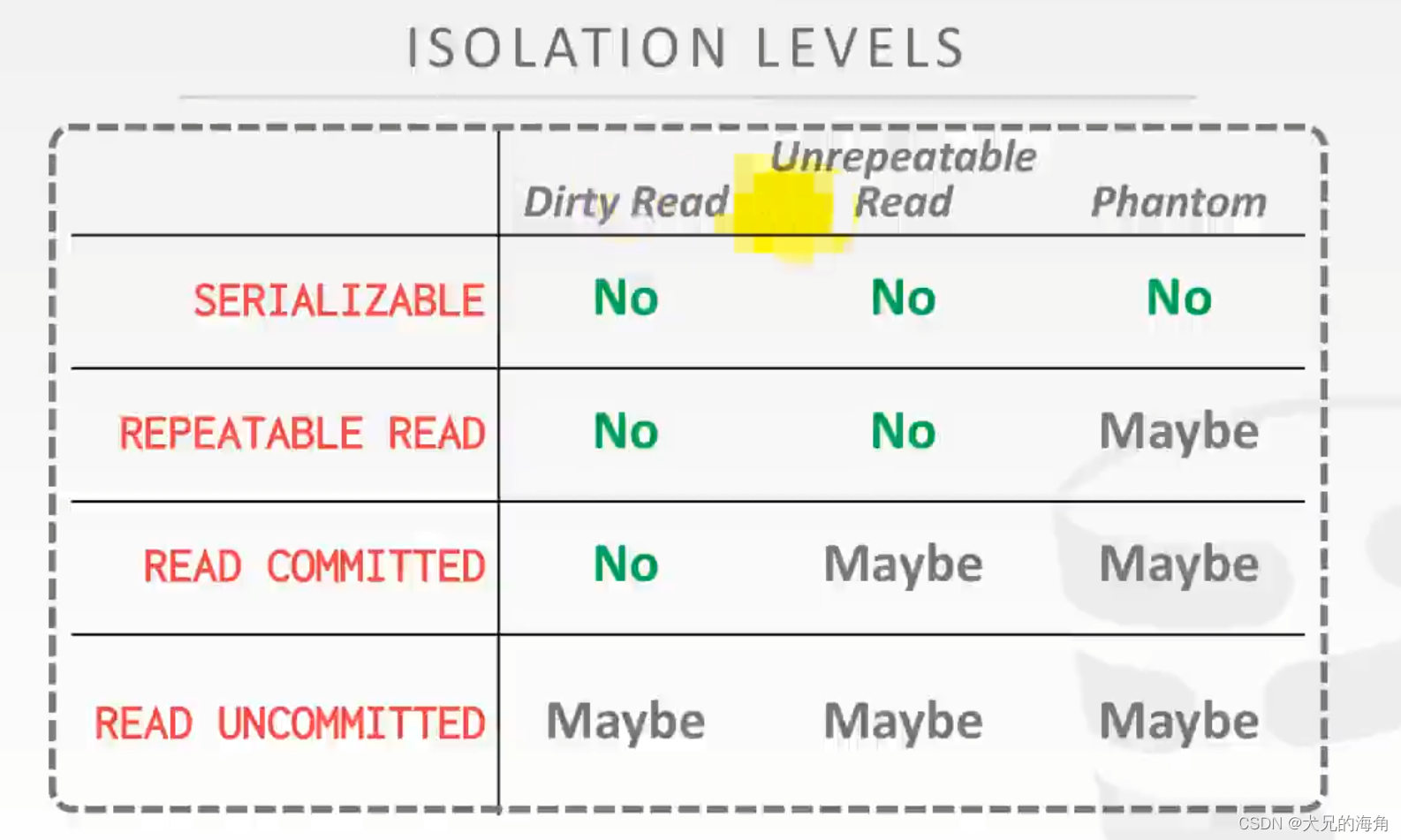
- REPEATABLE_READ(可重复读):这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。
- READ_COMMITTED (读已提交):这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。
- READ_UNCOMMITTED(读未提交):在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。
他们的性能依次更好但是一致性依次更差,分别可能会出现以下三个问题:
- 脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
- 不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
- 幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
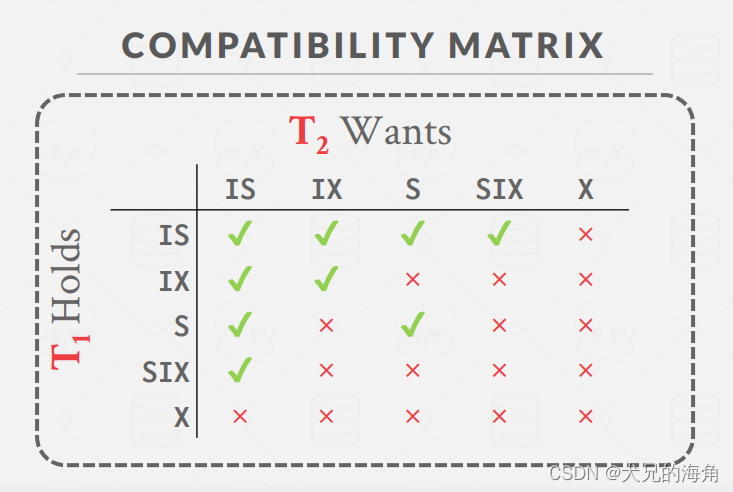
此外,Bustub 中的锁管理器支持 table 和 row 两种粒度,S、X、IS、IX、SIX 五种锁类型:
- S锁(共享锁):加了S锁的记录,允许其他事务再加S锁,不允许其他事务再加X锁;
- X锁(排他锁):加了X锁的记录,不允许其他事务再加S锁或者X锁;
- IS 锁(读意向锁):当事务要在记录上加上读锁时,要首先在表上加上读意向锁;
- IX 锁(写意向锁):当事务要在记录上加上写锁时,要首先在表上加上写意向锁;
- SIX 锁(共享写意向锁):在已经获得表或者页级别的S锁之后又分配IX给它。
任务 #1 - 锁管理器
在锁管理器中包含了如下结构:
- table_lock_map_:记录 table 和与锁请求队列;
- row_lock_map_:记录 row 和与锁请求队列;
- request_queue_:实际存放锁请求的队列;
- cv_ 和 latch_:条件变量和锁,用于实现多线程的协同等待;
- upgrading_:正在此资源上尝试锁升级的事务 id;
- txn_id_:发起此请求的事务 id ;
- lock_mode_:请求锁的类型;
- oid_:在 table 粒度锁请求中,代表 table id。在 row 粒度锁请求中,表示 row 属于的 table 的 id;
- rid_:仅在 row 粒度锁请求中有效。指 row 对应的 rid;
- granted_:是否已经对此请求授予锁。
在锁管理器中,我们需要对事务发送的锁请求进行处理,主要包括了上锁和解锁请求。
Lock
LockTable()和LockRow()都是阻塞方法;它们应该等待,直到锁被授予,然后返回。如果事务在此期间被中止,则不授予锁,并返回false。- LockManager 应该为每个资源维护一个队列;应该以先进先出的方式向事务授予锁。只要FIFO被遵守,如果有多个兼容的锁请求,所有的锁应该同时被授予。
- 表锁应该支持所有的锁模式;行锁不应该支持意图锁。试图这样做应该把交易状态设置 ABORTED并抛出一个 TransactionAbortException (ATTEMPTED_INTENTION_LOCK_ON_ROW)。
- 根据隔离级别,当事务在不允许的情况下发出锁请求时,应抛出相应的异常 TransactionAbortException(LOCK_SHARED_ON_READ_UNCOMMITTED)和TransactionAbortException(LOCK_ON_SHRINKING)。其中:
- repeatable_read:事务需要占用所有的锁;在GROWING状态下允许有所有的锁;在SHRINKING状态下不允许有锁。
- read_committed:该事务需要取得所有的锁;在GROWING状态下允许有所有的锁; 在SHRINKING状态下只允许使用IS, S锁。
- read_uncommitted:事务被要求只采取IX, X锁;在GROWING状态下允许使用X, IX锁; S, IS, SIX锁是绝对不允许的。
- 在锁定行的时候,
Lock()应该确保事务在该行所属的表上有一个适当的锁。属于哪个表。例如,如果试图对某行进行独占锁,事务必须持有X, IX, 或者SIX。如果表上不存在这样的锁,Lock()应该把TransactionState 为 ABORTED,并抛出一个TransactionAbortException(TABLE_LOCK_NOT_PRESENT)。 - 在一个已经被锁定的资源上调用Lock()应该有以下行为:如果请求的锁模式与目前持有的锁的模式相同,Lock()应该返回true,因为它已经有了锁; 如果请求的锁模式不同,Lock()应该升级事务所持有的锁。被升级的锁请求应该优先于同一资源上的其他等待的锁请求。
- 在升级时,只允许有以下的转换。任何其他的升级被认为是不兼容的,这样的尝试应该把交易状态设置为 ABORTED 并抛出一个TransactionAbortException(INCOMPATIBLE_UPGRADE)。
- IS -> [S, X, IX, SIX].
- S-> [X, SIX]
- IX-> [X, SIX]
- SIX-> [X]
- 此外,在一个给定的资源上,只允许一个事务升级其锁。在同一资源上的多个并发的锁升级应该把交易状态设置为 ABORTED并抛出一个TransactionAbortException (UPGRADE_CONFLICT)。
- 如果一个锁被授予一个事务,锁管理器应该更新它的适当的锁集.
基于以上需求,我们按照如下的流程进行上锁:
- 检查事务的隔离等级与当前上锁类型之间的对应关系,若不满足需要抛出相应异常;
- 给储存 table 和锁请求队列的哈希表进行上锁,获得当前表对应的锁请求队列,而后对队列上锁并对哈希表解锁。若队列不存在则需要创建默认队列。
- 遍历锁请求队列判断是否为锁升级请求:
- 判断此前授予锁类型是否与当前请求锁类型相同。
- 判断当前资源上是否有另一个事务正在尝试升级。
- 判断升级锁的类型和之前锁是否兼容。
- 在确认当前锁请求合法之后,我们释放当前已经持有的锁,并把新的锁请求作为一个新的请求加入队列中尚未执行的事务最前方,在 upgrading_中标记当前事务的 id 。
- 利用条件变量和互斥锁实现线程同步。我们首先持有锁判断能否获得资源:若无法获得则调用条件变量的
wait函数,自动释放 latch 并挂起线程;当其他线程完成使用资源之后会发出notify_all函数唤醒所有因此资源而阻塞的线程,被唤醒的线程在wait函数尝试获取 latch ,成功获取之后退出当前wait函数并尝试获取资源:若不能则继续重复wait过程;若能则退出循环。 - 基于以上机制,我们在
GrantLock中判断能否满足当前锁请求,我们需要首先判断有的已经 granted 的请求与当前的锁请求是否兼容,若可以则返回 true 跳出循环。 - 最终我们将 granted_ 置为 true,并根据情况将 upgrading_ 重置为 INVALID_TXN_ID,并更新 Transaction 中持有的锁集合。
- 值得注意的是,当我们在对行进行上锁时,我们还需要判断所在表是否具有相应的意向锁。
Unlock
- UnlockTable()和UnlockRow()都应该释放资源上的锁并返回。两者都应该确保事务当前对它试图解锁的资源持有锁。如果不是,LockManager应该将TransactionState设置为 ABORTED 并抛出TransactionAbortException (ATTEMPTED_UNLOCK_BUT_NO_LOCK_HELD).
- 此外,只有在事务没有在表上持有锁的情况下,才允许解锁该表。该表的任何行。如果事务在该表的行上持有锁,那么解锁应该将事务状态设置为 为ABORTED,并抛出一个TransactionAbortException(TABLE_UNLOCKED_BEFORE_UNLOCKING_ROWS)。
- 解锁一个资源也应该授予该资源的任何新锁请求。
- repeatable_read: 解锁S/X锁应该将事务状态设置为SHRINKING。
- read_committed:解锁X锁应该将事务状态设置为SHRINKING。解除S锁不会影响事务状态。
- read_uncommitted:解除X锁应该将事务状态设置为SHRINKING。S锁在READ_UNCOMMITTED下是不允许的。在这个隔离级别下,解锁S锁时的行为是未定义的。
- 在一个资源被解锁后,锁管理器应该适当地更新事务的锁集。
基于以上需求,我们按照如下的流程进行上锁:
- 给储存 table 和锁请求队列的哈希表进行上锁,获得当前表对应的锁请求队列,而后对队列上锁并对哈希表解锁。若队列不存在则需要创建默认队列。
- 遍历请求队列,找到 unlock 对应的 granted 请求,根据当前的隔离级别和锁类型修改状态并删除锁请求。
- 更新 Transaction 中持有的锁集合,并调用
notify_all唤醒其他被阻塞的线程。
任务 #2 - 死锁检测
为了避免多个线程之间的循环等待造成死锁,我们需要利用 wait for 图来判断当前的所有进程之间是否存在死锁的情况。值得注意的是,我们并不需要移植维护 wait for 图,只需要在死锁检测线程被唤醒时,根据当前请求队列构建 wait for 图,而后便可以丢弃当前构建的 wait for 图。
在 wait for 图中,我们利用 t 1 − > t 2 t1->t2 t1−>t2 表示 t1 事务正在等待 t2 事务释放资源。若 wait for 图中存在环则说明存在死锁情况。我们可以利用 DFS 来进行环检测,其中利用哈希表来储存节点和该节点的邻居节点。我们利用 txn_set_ 表示所有已获得运行许可的线程节点集合,利用 safe_set_ 表示已经遍历完所有邻居节点的节点,利用 active_set_ 表示尚有邻居节点未遍历完的节点。若我们在遍历邻居节点时遍历到了 active_set_ 中的节点说明图中存在环,若为遍历到则递归调用函数并判断其邻居节点出发是否会出现环。若仍没有则可以将当前节点加入 safe_set_ 中。我们按照 tid 从大到小的顺序来遍历每一个节点,这样就就能够确保当我们需要删除造成死锁的节点时,我们优先删除的是 tid 最大的事务,也就是最年轻的事务。
在找到需要删除的事务之后,我们将其状态设为 Aborted。并且在请求队列中移除此事务,释放其持有的锁,终止其正在阻塞的请求,并调用 notify_all通知正在阻塞的相关事务。此外,还需移除 wait for 图中与此事务有关的边。因此当事务被唤醒时,需要确认其是否处于 Aborted 状态,若处于则释放所持资源并返回。
任务 #3 - 并发查询执行
SeqScan
如果隔离级别是 READ_UNCOMMITTED 则无需加锁。加锁失败则抛出 ExecutionException 异常。在 READ_COMMITTED 下,在 Next() 函数中,若无数据则提前释放之前持有的锁。在 REPEATABLE_READ 下,在 Commit 或 Abort 时统一释放。
Insert & Delete
在 Init() 函数中,为表加上 IX 锁,再为行加 X 锁。同样,若获取失败则抛 ExecutionException 异常。另外,这里的获取失败不仅是结果返回 false,还有可能是抛出了 TransactionAbort 异常,例如 UPGRADE_CONFLICT,需要用 try catch 捕获。锁在 Commit 或 Abort 时统一释放。