大数据-学习实践-2HDFS
(大数据系列)
文章目录
- 大数据-学习实践-2HDFS
- 1知识点
- 2具体内容
- 2.1HDFS介绍
- 2.2HDFS操作
- 2.2.1基本操作
- 2.2.2Java操作HDFS
- 2.3HDFS体系结构
- 2.3.1NameNode
- 2.3.2SecondaryNameNode
- 2.3.3DataNode
- 2.3.4总结
- 2.4HDFS回收站
- 2.4HDFS安全模式
- 2.5定时上传至HDFS
- 2.6HDFS高可用和高扩展
- 3待补充
- 4Q&A
- 5code
- 6参考
1知识点
- HDFS介绍
- HDFS基本操作
- Java操作HDFS
- HDFS体系结构
- HDFS回收站
- HDFS安全模式
- 定时上传至HDFS
- HDFS高可用和高扩展
2具体内容
2.1HDFS介绍
- Hadoop Distributed File System
- 允许文件通过网络在多台主机上分享的文件系统,可以让多台机器上的多个用户分享文件和存储空间
- HDFS只是一种实现,适合大文件
2.2HDFS操作
2.2.1基本操作
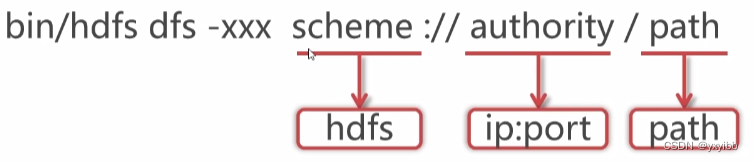
格式:bin/hdfs dfs -xxx scheme://authority/path(路径已加入环境变量,bin可不写)
- hdfs dfs -ls hdfs://bigdata01:9000/
- hdfs dfs -ls /
- hdfs dfs -put readme.txt /
- hdfs dfs -cat /readme.txt
- hdfs dfs -get /readme.txt r.txt
- hdfs dfs -mkdir /test
- hdfs dfs -mkdir -p /t/abc
- hdfs dfs -ls -R
- hdfs dfs -rm /readme.txt
- hdfs dfs -rm -r /t
- hdfs dfs -rm -r /test
 统计文件量及大小:
统计文件量及大小: - hdfs dfs -ls / | wc -l
- hdfs dfs -ls / | grep / | awk ‘{print $8,$5}’
2.2.2Java操作HDFS
- 配置maven环境变量
- IDEA创建项目,设置本地maven仓库路径
- 安装hadoop依赖,pom.xml记得引入
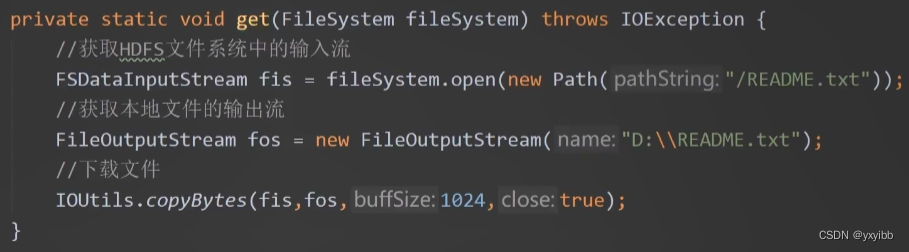
- 文件操作:上传、下载、删除
上传文件:
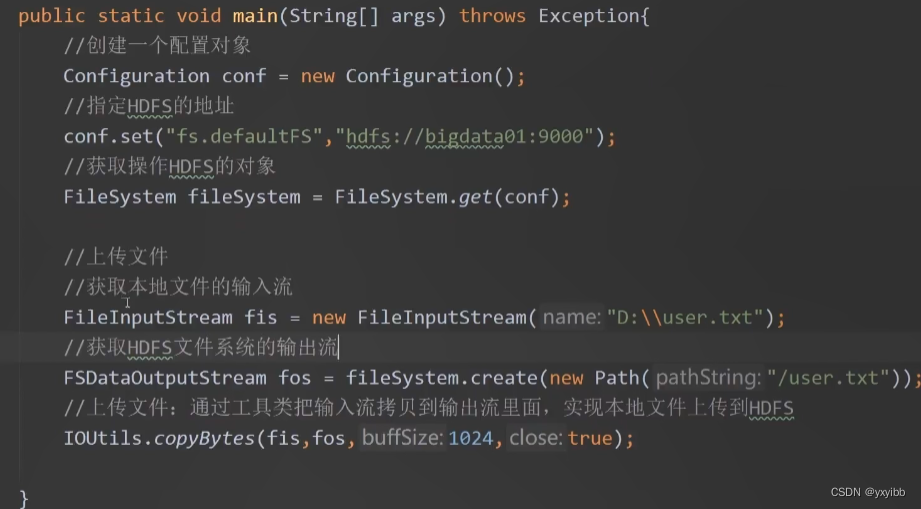 提取文件:封函数
提取文件:封函数
 删除文件:
删除文件:
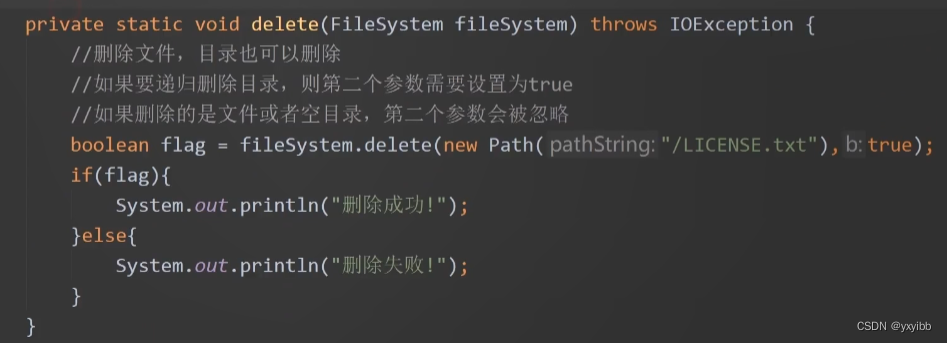
- 权限:打包至linux执行;或者关闭集群权限校验机制,hdfs-site.xml文件

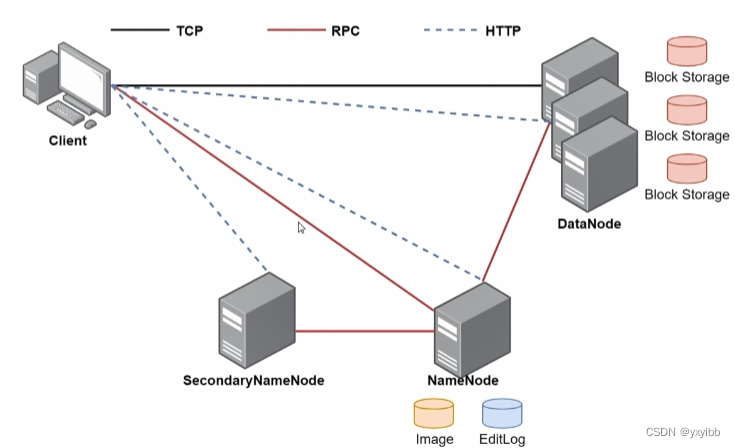
2.3HDFS体系结构
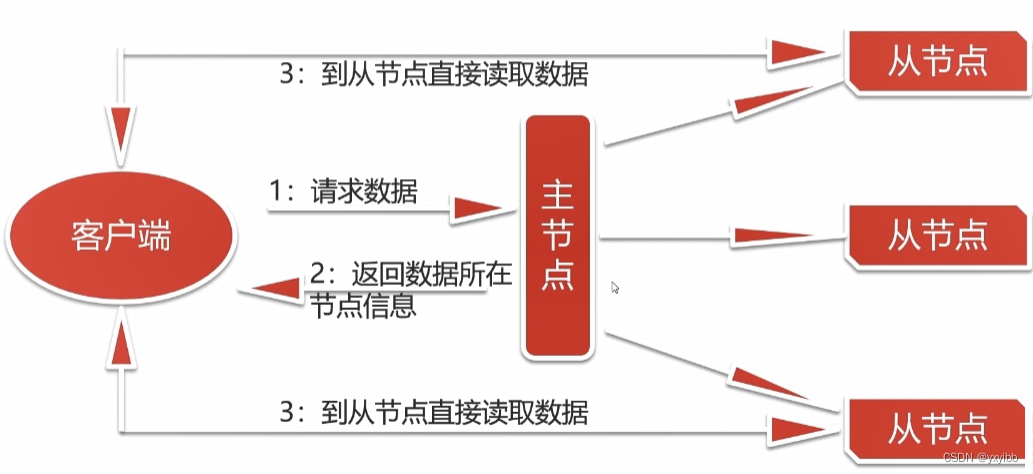
- 支持主从结构,主节点为NameNode,支持多个从节点DataNode
- 含一个SecondaryNameNode进程
2.3.1NameNode
- 整个文件系统的管理节点
- 维护整个文件系统的文件目录树,文件/目录信息每个文件对应的数据块列表,并负责接收用户操作请求
- fsimage
- edits
- seed_txid
- VERSION
#文件目录树及文件数据列表等核心信息,源数据信息
hdfs oiv -p XML -i fsimage_000000056 -o fsimage56.xml
#事务文件
hdfs oev -i edits_000000057-00000000072 -o edits.xml
#保存文件编号信息
cat seen_txid
#保存版本信息
cat VERSION
2.3.2SecondaryNameNode
- 定期把edits文件内容合并到fsimage
- 合并称checkpoint,合并时对edits内容进行转换,生成新的内容保存到fsimage中
- 注:NameNode的HA架构中没有SecondaryNameNode进程,文件合并由standby NameNode负责实现
2.3.3DataNode
- 提供真实文件数据的存储服务
- HDFS按固定大小,顺序对文件进行划分并编号,划分好的每一个块称为一个Block,默认128M
- 从节点,dfs/data、current下存储
- 如果一个文件小于一个数据块大小,并不会占据整个数据块空间
- Replication:多副本机制,默认3
- 通过dfs.replication属性控制
2.3.4总结
NameNode维护2份关系:
- File与Block list关系,对应关系信息存在fsimage和edits文件中(NameNode启动时把文件中的元数据信息加载到内存中)
- DataNode与Block关系(DataNode启动时把当前节点的Block信息和节点信息上报给NameNode)
2.4HDFS回收站
- 回收站目录:/user/用户名/.Trash/
- 有默认保存周期,过期未恢复被HDFS自动彻底删除
- 默认不开启
- 修改:core-site.xml ,fs.trash.interval 属性,并集群同步

hdfs dfs -rm /readme.txt
hdfs dfs -rm -skipTrash /user.txt #忽略回收站,永久删除
2.4HDFS安全模式
- 刚启动进入安全模式,无法执行写操作
- 查看:hdfs dfsadmin -safamode get
- 离开:hdfs dfsadmin -safamode leave
2.5定时上传至HDFS
- 获取昨天日志名称
- 在HDFS上使用昨天的日期创建目录
- 将昨天的日志文件上传到刚创建的HDFS目录
- 考虑脚本重跑,补数据情况
- 配置crontab任务
#!/bin/bash
yesterday = $1
if [ "yesterday" = "" ]
then
yesterday = 'date +%Y_%m_%d --date= "1 days ago"'
fi
logPath = /data/log/access_${yesterday}.log
hdfsPath = /log/${yesterday//_/} #下划线去电,拼接成hdfs路径
hdfs dfs -mkdir -p ${hdfsPath}
hdfs dfs -put ${logPath} ${hdfsPath}
sh -x uploadLogData.sh
sh -x uploadLogData.sh 2020_04_10
#手动上传2020_04_10文件;注意写脚本的时候,留好接口
#配置crontab
#新增:
0 1 * * * root sh /data/shell/uploadLogData.sh >> /data/shell/uploadLogData.log
2.6HDFS高可用和高扩展
NameNode节点宕机
NameNode节点宕机内存不够用?
-
HA (High Available)

- HA表示一个集群存在多个NameNode,只有一个NameNode是Active状态,其他是Standby
- ActiveNameNode(ANN)负责所有客户端操作,StandbyNameNode(SNN)同步ANN状态信息,以提供快速故障恢复能力
- 使用HA时,不能启动SecondaryNameNode,会出错
-
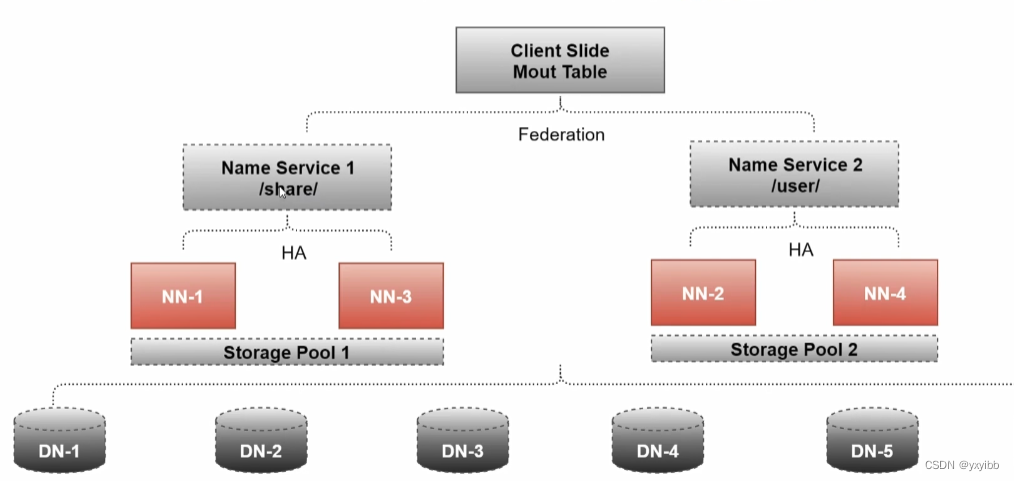
HDFS高扩展Federation
- 解决单一命名空间的问题, 提供HDFS集群扩展性、性能更高效、良好的隔离性
-
Federation+HA
3待补充
无
4Q&A
无
5code
无
6参考
- 大数据课程资料





![[思考进阶]06 养成“记笔记”的习惯,能够改变你的思考方式](https://img-blog.csdnimg.cn/9a7258047a67487c8ca75cf5d7e2c0d5.png)