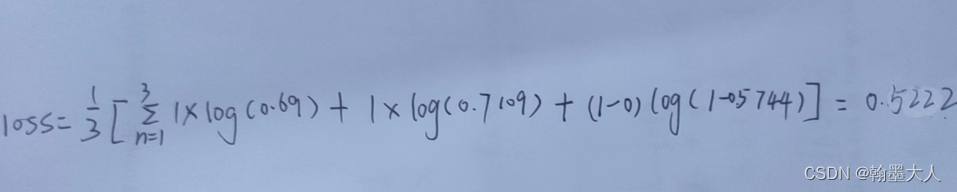文章目录
- 1. IEKF 概述
- 2. IEKF 的核心思想
- 2.1. The Motivation of Iteration
- 2.2. IEKF 迭代线性化步骤
- 3. IEKF 的推导
- 3.1. 预测公式
- 3.2. 校正公式
1. IEKF 概述
由于非线性模型中做了线性化近似,当非线性程度越强时,误差就会较大,但是由于线性化的工作点离真值越近, 线性化的误差就越小,因此解决该问题的一个方法是,通过迭代逐渐找到准确的线性化点,从而提高精度。 在EKF的推导中,其他保持不变,仅改变观测的线性化工作点,则有
g ( x k , n k ) ≈ y o p , k + G k ( x k − x o p , k ) + C k n k \boldsymbol{g}\left(\boldsymbol{x}_{k}, \boldsymbol{n}_{k}\right) \approx \boldsymbol{y}_{\mathrm{op}, k}+\boldsymbol{G}_{k}\left(\boldsymbol{x}_{k}-\boldsymbol{x}_{\mathrm{op}, k}\right)+\boldsymbol{C}_{k} \boldsymbol{n}_{k} g(xk,nk)≈yop,k+Gk(xk−xop,k)+Cknk
其中,
y
o
p
,
k
=
g
(
x
o
p
,
k
,
0
)
G
k
=
∂
g
(
x
k
,
n
k
)
∂
x
k
∣
x
o
p
,
k
,
0
C
k
=
∂
g
(
x
k
,
n
k
)
∂
n
k
∣
x
o
p
,
k
,
0
\begin{aligned} &\boldsymbol{y}_{\mathrm{op}, k}=\boldsymbol{g}\left(\boldsymbol{x}_{\mathrm{op}, k}, \mathbf{0}\right) \\ &\boldsymbol{G}_{k}=\left.\frac{\partial \boldsymbol{g}\left(\boldsymbol{x}_{k}, \boldsymbol{n}_{k}\right)}{\partial \boldsymbol{x}_{k}}\right|_{\boldsymbol{x}_{\mathrm{op}, k}, \boldsymbol{0}} \\ &\boldsymbol{C}_{k}=\left.\frac{\partial \boldsymbol{g}\left(\boldsymbol{x}_{k}, \boldsymbol{n}_{k}\right)}{\partial \boldsymbol{n}_{k}}\right|_{\boldsymbol{x}_{\mathrm{op}, \boldsymbol{k}}, \mathbf{0}} \end{aligned}
yop,k=g(xop,k,0)Gk=∂xk∂g(xk,nk)
xop,k,0Ck=∂nk∂g(xk,nk)
xop,k,0
按照与之前同样的方式进行推导,可得到滤波的校正过程为
K
k
=
P
^
k
G
k
T
(
G
k
P
^
k
G
k
T
+
C
k
R
k
C
k
T
)
−
1
x
ˇ
k
=
x
^
k
+
K
k
(
y
k
−
y
o
p
,
k
−
G
k
(
x
^
k
−
x
o
p
,
k
)
)
P
ˇ
k
=
(
1
−
K
k
G
k
)
P
^
k
\begin{aligned} \boldsymbol{K}_{k} &=\hat{\boldsymbol{P}}_{k} \boldsymbol{G}_{k}^{\mathrm{T}}\left(\boldsymbol{G}_{k} \hat{\boldsymbol{P}}_{k} \boldsymbol{G}_{k}^{\mathrm{T}}+\boldsymbol{C}_{k} \boldsymbol{R}_{k} \boldsymbol{C}_{k}^{\mathrm{T}}\right)^{-1} \\ \check{\boldsymbol{x}}_{k} &=\hat{\boldsymbol{x}}_{k}+\boldsymbol{K}_{k}\left(\boldsymbol{y}_{k}-\boldsymbol{y}_{\mathrm{op}, k}-\boldsymbol{G}_{k}\left(\hat{\boldsymbol{x}}_{k}-\boldsymbol{x}_{\mathrm{op}, k}\right)\right) \\ \check{\boldsymbol{P}}_{k} &=\left(\mathbf{1}-\boldsymbol{K}_{k} \boldsymbol{G}_{k}\right) \hat{\boldsymbol{P}}_{k} \end{aligned}
KkxˇkPˇk=P^kGkT(GkP^kGkT+CkRkCkT)−1=x^k+Kk(yk−yop,k−Gk(x^k−xop,k))=(1−KkGk)P^k
可见唯一的区别是后验均值
x
ˇ
k
\check{\boldsymbol{x}}_{k}
xˇk 更新的公式与之前有所不同。滤波过程中,反复执行上面 3 个公式,以上次的后验均值作为本次的线性化工作点,即可达到减小非线性误差的目的。
2. IEKF 的核心思想
2.1. The Motivation of Iteration
其实原理就是上面的原理,只不过上面写的可能比较简略,所以这里再详细推导一下。
IEKF 的核心思想就是想 提高观测方程的线性化精度,因为我们之前的 EKF 都是把观测方程在IMU得到的 先验状态 x ^ k \boldsymbol {\hat {x}_k} x^k 处进行线性化,此时线性化是观测方程为:
z k = h ( x ^ k , 0 ) + H k ∣ x ^ k ( x k − x ^ k ) + V k ∣ x ^ k v k \boldsymbol z_{k} = \boldsymbol h(\boldsymbol {\hat{x}}_{k}, \boldsymbol 0) + \left. \boldsymbol H_{k} \right|_{\boldsymbol {\hat{x}_k}} (\boldsymbol x_{k} - \boldsymbol {\hat{x}}_{k}) + \left. \boldsymbol V_{k}\right|_{\boldsymbol {\hat{x}_k}} \boldsymbol v_{k} zk=h(x^k,0)+Hk∣x^k(xk−x^k)+Vk∣x^kvk
而 先验状态 x ^ k \boldsymbol {\hat {x}}_k x^k 可能离我们的真实状态 x k \boldsymbol { {x}}_k xk 比较远,这样就导致我们得到的这个线性化方程中的系数矩阵都不准确,那么自然后面我们带入校正公式进行校正的时候,我们求得的 卡尔曼增益 和 传感器观测值与预测观测值之间的差值 都不准确,也就是在先验状态上进行状态调整的那一项结果不准确,从而精度降低。
实际上 最准确的点是在真实状态 x k \boldsymbol { {x}}_k xk 处进行线性化,这样的 系数矩阵和展开点的函数值 都是最准确的,但是真实状态我们永远都不会知道,所以只能退而求其次,找一个 最接近真实状态的点 对观测方程进行线性化,这就是 IEKF 的思想。如下图所示,可以看到我们求得的后验状态由于离真实状态更近,所以在这个点对观测方程进行线性化得到的系数矩阵和展开点函数值都离真实状态更接近。

2.2. IEKF 迭代线性化步骤
(1)第一次对观测方程进行线性化的时候,我们只有先验状态值,所以只能在先验状态的地方进行线性化,得到方程:
z
k
=
h
(
x
^
k
,
0
)
+
H
k
∣
x
^
k
(
x
k
−
x
^
k
)
+
V
k
∣
x
^
k
v
k
\boldsymbol z_{k} = \boldsymbol h(\boldsymbol {\hat{x}}_{k}, \boldsymbol 0) + \left. \boldsymbol H_{k} \right|_{\boldsymbol {\hat{x}_k}} (\boldsymbol x_{k} - \boldsymbol {\hat{x}}_{k}) + \left. \boldsymbol V_{k}\right|_{\boldsymbol {\hat{x}_k}} \boldsymbol v_{k}
zk=h(x^k,0)+Hk∣x^k(xk−x^k)+Vk∣x^kvk
然后经过卡尔曼滤波的校正公式之后,我们得到了一个更接近真值状态的后验估计值
x
^
k
1
\boldsymbol {\hat {x}}^{1}_k
x^k1。
(2)把上一步得到的更接近真实状态的估计值
x
^
k
1
\boldsymbol {\hat {x}}^{1}_k
x^k1作为观测方程的新的线性化展开点,再次展开:
z
k
=
h
(
x
^
k
1
,
0
)
+
H
k
∣
x
^
k
1
(
x
k
−
x
^
k
1
)
+
V
k
∣
x
^
k
1
v
k
\boldsymbol z_{k} = \boldsymbol h(\boldsymbol {\hat{x}}^{1}_{k}, \boldsymbol 0) + \left. \boldsymbol H_{k} \right|_{\boldsymbol {\hat{x}}^{1}_k} (\boldsymbol x_{k} - \boldsymbol {\hat{x}}^{1}_k) + \left. \boldsymbol V_{k}\right|_{\boldsymbol {\hat{x}}^{1}_k} \boldsymbol v_{k}
zk=h(x^k1,0)+Hk∣x^k1(xk−x^k1)+Vk∣x^k1vk
然后经过卡尔曼滤波的校正公式之后,我们得到了一个更接近真值状态的后验估计值
x
^
k
2
\boldsymbol {\hat {x}}^{2}_k
x^k2。
(3) 依此类推,每次对观测方程进行线性化展开的点都更加接近真实状态,这代表每次对观测方程的线性化展开结果都更加精确,得到的系数矩阵和展开点函数值更加精确。
3. IEKF 的推导
3.1. 预测公式
由于我们只是对观测方程的线性化点进行迭代,和状态方程没有关系,也就是和预测没有关系,所以这里预测公式不变。
带入上一时刻的后验状态到自变量中,即 x k − 1 ← x ˇ k − 1 : x ^ k = f ( x ^ k − 1 , 0 ) + F k − 1 ( x ˇ k − 1 − x ˇ k − 1 ) = f ( x ^ k − 1 , 0 ) P ^ k = F k − 1 P ˇ k − 1 F k − 1 T + Q 带入上一时刻的后验状态到自变量中,即\boldsymbol x_{k-1} \leftarrow \boldsymbol {\check{x}}_{k-1} : \\ \boldsymbol {\hat{x}}_{k} = \boldsymbol f(\boldsymbol {\hat{x}}_{k-1} , \boldsymbol 0) + \boldsymbol F_{k-1} (\boldsymbol {\check{x}}_{k-1} - \boldsymbol {\check{x}}_{k-1}) = \boldsymbol f(\boldsymbol {\hat{x}}_{k-1} , \boldsymbol 0) \\ \boldsymbol {\hat P}_{k} = \boldsymbol F_{k-1} \boldsymbol {\check P}_{k-1} \boldsymbol F_{k-1} ^{T}+ \boldsymbol Q 带入上一时刻的后验状态到自变量中,即xk−1←xˇk−1:x^k=f(x^k−1,0)+Fk−1(xˇk−1−xˇk−1)=f(x^k−1,0)P^k=Fk−1Pˇk−1Fk−1T+Q
3.2. 校正公式
首先时刻保持清醒的一个问题是:我们对观测方程进行迭代的时候,改变 只是对它进行线性化的工作点,而线性化之后我们带入这个线性化公式里面的 自变量 仍然是IMU得到的 先验估计状态,因为典型的线性卡尔曼滤波就是这么做的,是把 状态方程得到的先验值 和 传感器测量值与先验状态预测观测值之间的差值 进行加权平均,作为在先验状态上的调整项。
(1)第一次迭代
这个时候线性化点和普通的 EKF 的线性化点是一样的,都是在IMU状态方程得到的先验状态处进行线性化,所以校正公式也是一样的(注意计算预测观测值
z
k
\boldsymbol {z}_k
zk 时不知道噪声,所以简化为0):
观测方程在
I
M
U
的先验状态
x
^
k
处展开。带入
I
M
U
的先验状态到自变量中,即
x
k
←
x
^
k
:
z
k
=
h
(
x
^
k
,
0
)
+
H
k
∣
x
^
k
(
x
^
k
−
x
^
k
)
=
h
(
x
^
k
,
0
)
K
k
=
P
^
k
H
T
H
P
^
k
H
T
+
R
x
ˇ
k
1
=
x
^
k
+
K
k
(
z
m
−
z
k
)
=
x
^
k
+
K
k
(
z
m
−
h
(
x
^
k
,
0
)
)
P
ˇ
k
=
(
I
−
K
k
H
)
P
^
k
观测方程在IMU的先验状态\boldsymbol {\hat{x}}_{k}处展开。带入IMU的先验状态到自变量中,即\boldsymbol x_{k} \leftarrow \boldsymbol {\hat{x}}_{k} : \\ \boldsymbol z_{k} = \boldsymbol h(\boldsymbol {\hat{x}}_{k}, \boldsymbol 0) + \left. \boldsymbol H_{k} \right|_{\boldsymbol {\hat{x}_k}} (\boldsymbol {\hat{x}}_{k} - \boldsymbol {\hat{x}}_{k}) = \boldsymbol h(\boldsymbol {\hat{x}}_{k}, \boldsymbol 0) \\ \begin{gathered} \boldsymbol K_{k}=\frac{ \boldsymbol {\hat P}_{k} \boldsymbol H^{T}}{ \boldsymbol H \boldsymbol {\hat P}_{k} \boldsymbol H^{T} + \boldsymbol R} \\ \boldsymbol {\check {x}}^{1}_{k} = \boldsymbol {\hat{x}}_{k} + \boldsymbol {K}_{k}\left( \boldsymbol {z}_m - \boldsymbol {z}_k \right) = \boldsymbol {\hat{x}}_{k} + \boldsymbol {K}_{k}\left( \boldsymbol {z}_m - \boldsymbol h(\boldsymbol {\hat{x}}_{k}, \boldsymbol 0) \right) \\ \boldsymbol {\check P}_{k}=\left( \boldsymbol I- \boldsymbol K_{k} \boldsymbol H\right) \boldsymbol {\hat P}_{k} \end{gathered}
观测方程在IMU的先验状态x^k处展开。带入IMU的先验状态到自变量中,即xk←x^k:zk=h(x^k,0)+Hk∣x^k(x^k−x^k)=h(x^k,0)Kk=HP^kHT+RP^kHTxˇk1=x^k+Kk(zm−zk)=x^k+Kk(zm−h(x^k,0))Pˇk=(I−KkH)P^k
(2)第二次迭代
此时上一次迭代得到了一个更加接近真实状态的后验估计值
x
ˇ
k
1
\boldsymbol{\check x}^{1}_k
xˇk1,然后把它带入观测方程中进行线性化,得到更加准确的线性化观测方程(注意计算预测观测值
z
k
\boldsymbol {z}_k
zk 时不知道噪声,所以简化为0):
观测方程在上一次迭代得到的后验状态
x
ˇ
k
1
处展开。带入
I
M
U
的先验状态到自变量中,即
x
k
←
x
^
k
:
z
k
=
h
(
x
ˇ
k
1
,
0
)
+
H
k
∣
x
ˇ
k
1
(
x
^
k
−
x
ˇ
k
1
)
K
k
=
P
^
k
H
T
H
P
^
k
H
T
+
R
x
ˇ
k
2
=
x
^
k
+
K
k
(
z
m
−
z
k
)
=
x
^
k
+
K
k
(
z
m
−
h
(
x
ˇ
k
1
,
0
)
−
H
k
∣
x
ˇ
k
1
(
x
^
k
−
x
ˇ
k
1
)
)
P
ˇ
k
=
(
I
−
K
k
H
)
P
^
k
观测方程在上一次迭代得到的后验状态\boldsymbol {\check{x}}^{1}_{k}处展开。带入IMU的先验状态到自变量中,即\boldsymbol x_{k} \leftarrow \boldsymbol {\hat{x}}_{k} : \\ \boldsymbol z_{k} = \boldsymbol h(\boldsymbol {\check{x}}^{1}_{k}, \boldsymbol 0) + \left. \boldsymbol H_{k} \right|_{\boldsymbol {\check{x}}^{1}_{k}} (\boldsymbol {\hat{x}}_{k} - \boldsymbol {\check{x}}^{1}_{k}) \\ \begin{gathered} \boldsymbol K_{k}=\frac{ \boldsymbol {\hat P}_{k} \boldsymbol H^{T}}{ \boldsymbol H \boldsymbol {\hat P}_{k} \boldsymbol H^{T} + \boldsymbol R} \\ \boldsymbol {\check {x}}^{2}_{k} = \boldsymbol {\hat{x}}_{k} + \boldsymbol {K}_{k}\left( \boldsymbol {z}_m - \boldsymbol {z}_k \right) = \boldsymbol {\hat{x}}_{k} + \boldsymbol {K}_{k}\left( \boldsymbol {z}_m - \boldsymbol h(\boldsymbol {\check{x}}^{1}_{k}, \boldsymbol 0) - \left. \boldsymbol H_{k} \right|_{\boldsymbol {\check{x}}^{1}_{k}} (\boldsymbol {\hat{x}}_{k} - \boldsymbol {\check{x}}^{1}_{k}) \right) \\ \boldsymbol {\check P}_{k}=\left( \boldsymbol I- \boldsymbol K_{k} \boldsymbol H\right) \boldsymbol {\hat P}_{k} \end{gathered}
观测方程在上一次迭代得到的后验状态xˇk1处展开。带入IMU的先验状态到自变量中,即xk←x^k:zk=h(xˇk1,0)+Hk∣xˇk1(x^k−xˇk1)Kk=HP^kHT+RP^kHTxˇk2=x^k+Kk(zm−zk)=x^k+Kk(zm−h(xˇk1,0)−Hk∣xˇk1(x^k−xˇk1))Pˇk=(I−KkH)P^k
(3)第三次迭代
此时上一次迭代得到了一个更加接近真实状态的后验估计值 x ˇ k 2 \boldsymbol {\check {x}}^{2}_{k} xˇk2,然后把它带入观测方程中进行线性化,得到更加准确的线性化观测方程:
观测方程在上一次迭代得到的后验状态 x ˇ k 2 处展开。带入 I M U 的先验状态到自变量中,即 x k ← x ^ k : z k = h ( x ˇ k 2 , 0 ) + H k ∣ x ˇ k 2 ( x ^ k − x ˇ k 2 ) K k = P ^ k H T H P ^ k H T + R x ˇ k 3 = x ^ k + K k ( z m − h ( x ˇ k 2 , 0 ) − H k ∣ x ˇ k 2 ( x ^ k − x ˇ k 2 ) ) P ˇ k = ( I − K k H ) P ^ k 观测方程在上一次迭代得到的后验状态\boldsymbol {\check{x}}^{2}_{k}处展开。带入IMU的先验状态到自变量中,即\boldsymbol x_{k} \leftarrow \boldsymbol {\hat{x}}_{k} : \\ \boldsymbol z_{k} = \boldsymbol h(\boldsymbol {\check{x}}^{2}_{k}, \boldsymbol 0) + \left. \boldsymbol H_{k} \right|_{\boldsymbol {\check{x}}^{2}_{k}} (\boldsymbol {\hat{x}}_{k} - \boldsymbol {\check{x}}^{2}_{k}) \\ \begin{gathered} \boldsymbol K_{k}=\frac{ \boldsymbol {\hat P}_{k} \boldsymbol H^{T}}{ \boldsymbol H \boldsymbol {\hat P}_{k} \boldsymbol H^{T} + \boldsymbol R} \\ \boldsymbol {\check {x}}^{3}_{k} = \boldsymbol {\hat{x}}_{k} + \boldsymbol {K}_{k}\left( \boldsymbol {z}_m - \boldsymbol h(\boldsymbol {\check{x}}^{2}_{k}, \boldsymbol 0) - \left. \boldsymbol H_{k} \right|_{\boldsymbol {\check{x}}^{2}_{k}} (\boldsymbol {\hat{x}}_{k} - \boldsymbol {\check{x}}^{2}_{k}) \right) \\ \boldsymbol {\check P}_{k}=\left( \boldsymbol I- \boldsymbol K_{k} \boldsymbol H\right) \boldsymbol {\hat P}_{k} \end{gathered} 观测方程在上一次迭代得到的后验状态xˇk2处展开。带入IMU的先验状态到自变量中,即xk←x^k:zk=h(xˇk2,0)+Hk∣xˇk2(x^k−xˇk2)Kk=HP^kHT+RP^kHTxˇk3=x^k+Kk(zm−h(xˇk2,0)−Hk∣xˇk2(x^k−xˇk2))Pˇk=(I−KkH)P^k
注意:从上面的公式中可以发现,每次迭代过程中, K k \boldsymbol {K}_k Kk 矩阵都会变化,因为他会在校正公式中被使用。虽然 P ˇ k \boldsymbol {\check P}_k Pˇk 也会变化,但是他却对校正公式没有影响,因为它只是表征经过这次迭代后得到的后验估计值的置信度有多高。所以实际上我们只要 在最后一次迭代中计算一次 P ˇ k \boldsymbol {\check P}_k Pˇk即可,也就是最后迭代滤波完成,输出最终的滤波结果和对应的后验协方差矩阵。




![[思考进阶]06 养成“记笔记”的习惯,能够改变你的思考方式](https://img-blog.csdnimg.cn/9a7258047a67487c8ca75cf5d7e2c0d5.png)