MySQL 主备一致
- 主备切换
- binlog 格式
- statement
- row
- mixed
- 生产格式
- 循环复制问题
主备切换
MySQL 主备切换流程 :
- 状态 1 : 客户端的读写都直接访问节点 A,而节点 B 是 A 的备库,只将 A 的更新都同步过来 , 并本地执行。来保持节点 B 和 A 的数据是相同
- 当切换成状态 2 : 客户端读写访问的都是节点 B,而节点 A 是 B的备库
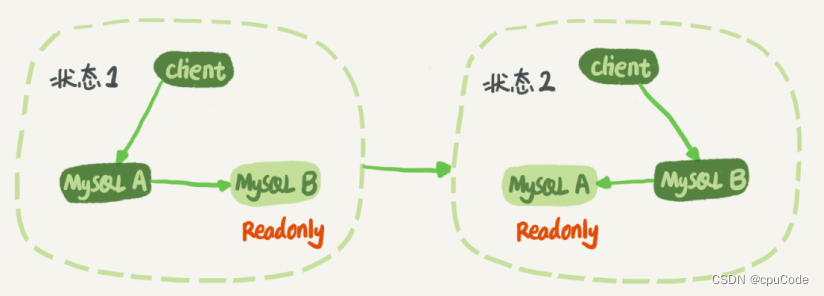
建议将备库设为只读 (readonly) 模式
- 一般查询语句会被放备库上查,设置为只读 , 能防止误操作
- 防止切换逻辑有 bug,如 : 切换过程中出现双写,造成主备不一致
- readonly 状态,能判断节点的角色
- readonly 对超级 (super) 权限用户是无效,而同步更新的线程 (有超级权限)
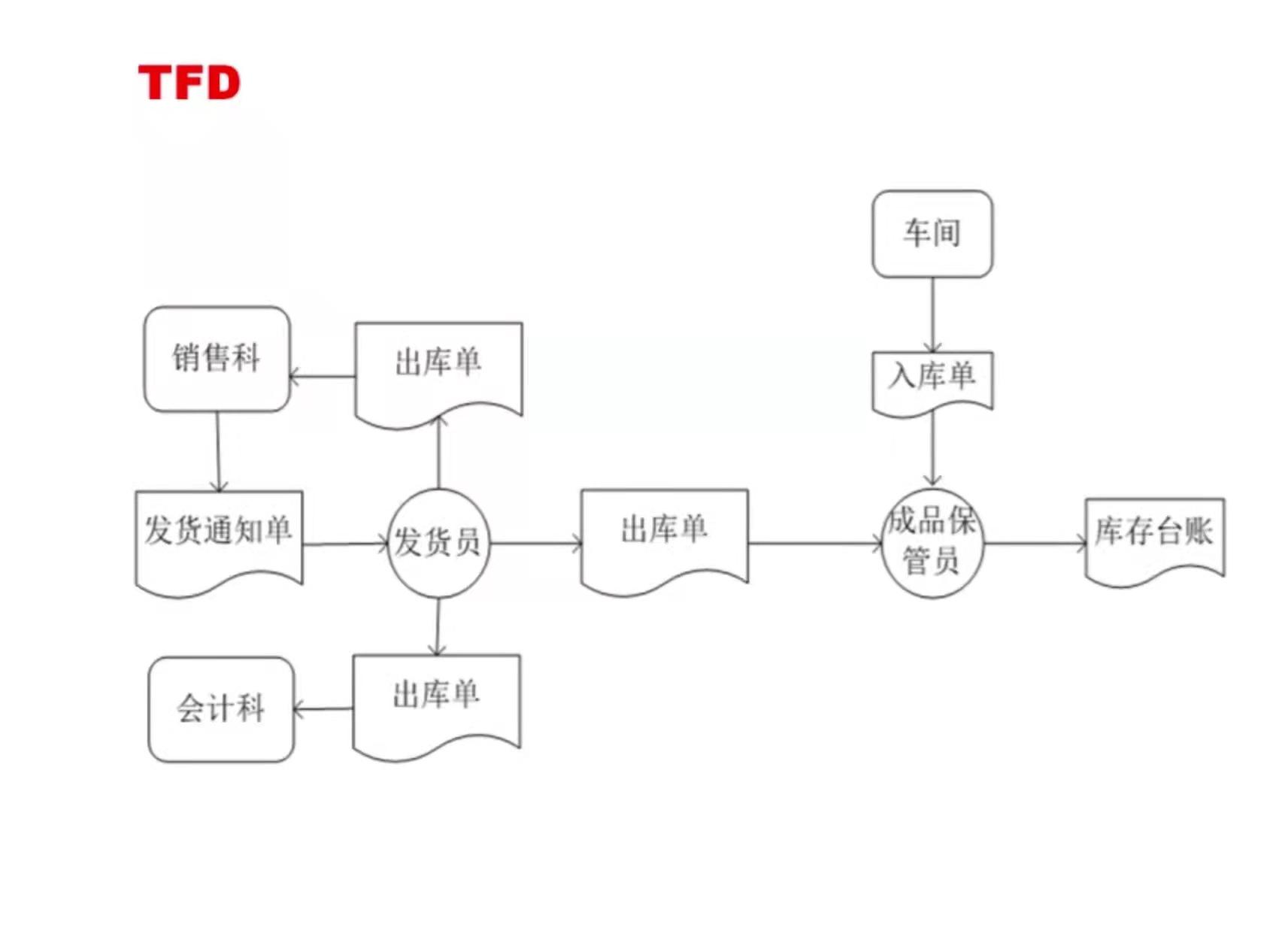
主备流程图 :
- 备库 B 通过
change master设置主库 A 的 IP、端口、用户名、密码,从哪个位置 (文件名 , 日志偏移量) 开始请求 binlog - 备库 B 执行
start slave,备库会启动两个线程 : io_thread (与主库建立连接 ) , sql_thread - 主库 A 校验完用户名、密码后,开始按备库 B 传过来的位置,从本地读取 binlog,发给 B
- 备库 B 拿到 binlog 后,写到本地文件 (中转日志 (relay log) )
- sql_thread 读取中转日志,解析出日志里的命令,并执行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-27GKlVWK-1678357937872)(../png/%E4%B8%BB%E5%A4%87%E4%B8%80%E8%87%B4/image-20230224204616476.png)]](https://img-blog.csdnimg.cn/ec4f3d9b19e145e9a4a1912121fad992.png)
binlog 格式
binlog 有两种格式 :
- statement
- row
- mixed : 前两种格式的混合
测试表/数据 :
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `t_modified`(`t_modified`)
) ENGINE=InnoDB;
insert into t values(1,1,'2018-11-13');
insert into t values(2,2,'2018-11-12');
insert into t values(3,3,'2018-11-11');
# 注意这俩条数据
insert into t values(4,4,'2018-11-10');
insert into t values(5,5,'2018-11-09');
查看 binlog 记录 delete 语句
delete from t /*comment*/ where a>=4 and t_modified<='2018-11-10' limit 1;
statement
statement : binlog 记录的 SQL 原语句
show binlog events in 'master.000001';

警告信息 :
- statement 格式,delete 中带 limit,会认为该命令是 unsafe
show warnings;

statement : delete 带 limit,可能出现主备数据不一致 :
- delete 用索引 a,就会删除 a=4 该行
- 用索引 t_modified,那就删除 t_modified='2018-11-09’ ( a=5 该行 )
- 当主库用索引 a;而备库用索引 t_modified 。就会出现主备不一致
row
row 格式 binlog :
- row 的 binlog 没有 SQL 原语句,只能换成 :Table_map (操作表) , Delete_rows (删除的行为)
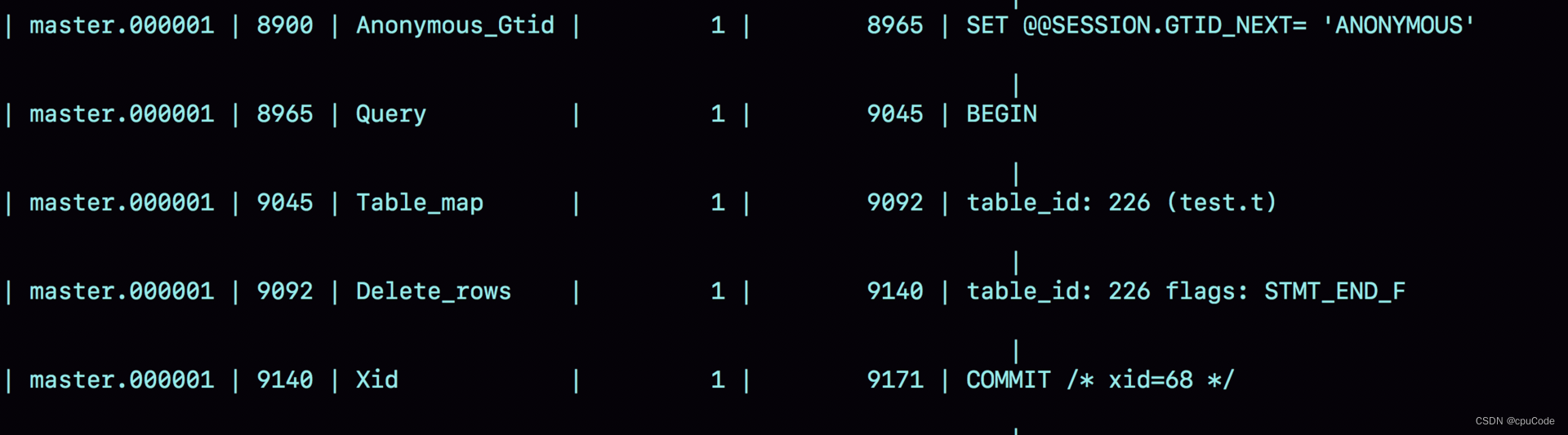
解析 binlog 内容 : 从 8900 位置开始
- server id 1 : 该事务在
server_id=1该库 - Table_map : 显示打开的表,map 226 : 用于区分不同表
- binlog_row_image 默认配置是 FULL,Delete_rows 会有删掉的行的所有字段的值 ; binlog_row_image = MINIMAL : 记录必要的信息,只记录 id=4 信息
- 最后 Xid : 事务被正确提交
mysqlbinlog -vv data/master.000001 --start-position=8900;
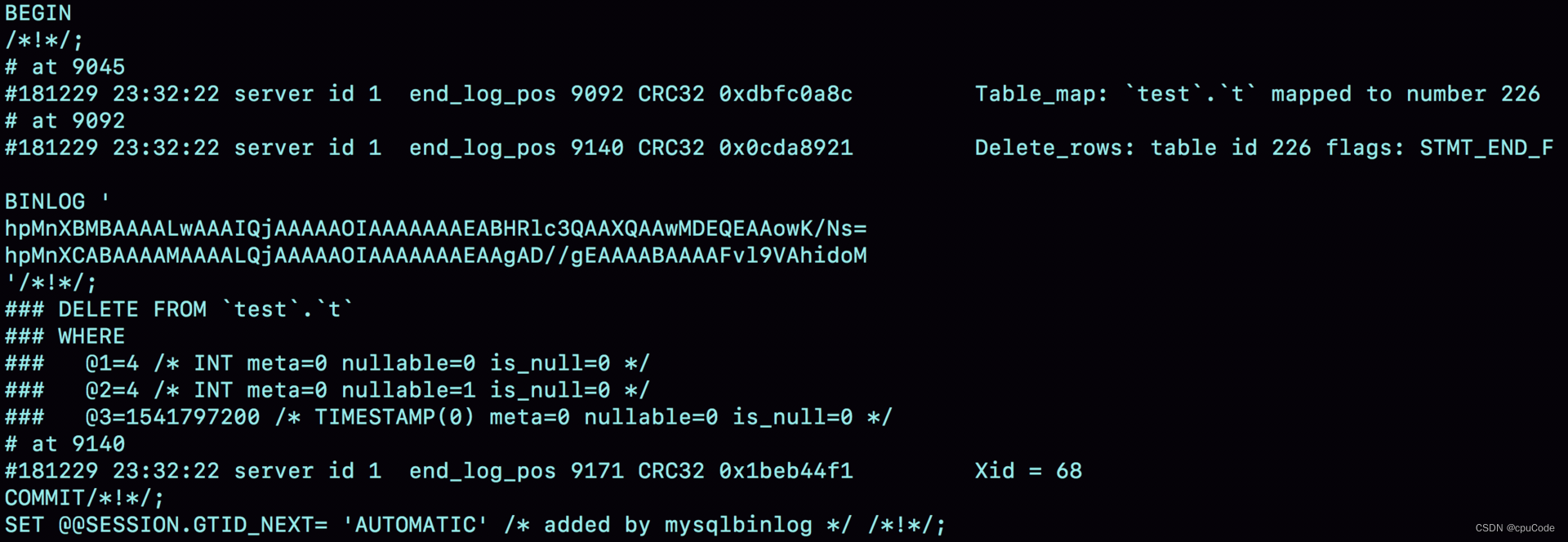
binlog_format=row : binlog 记录真实删除行的主键 id,binlog 传到备库去,就肯定会删除 id=4 行,不会造成主备不一致问题
mixed
mixed : 即利用 statment 优点,又避免了数据不一致问题
-
MySQL 会判断该 SQL 是否可能引发主备不一致,可能就用 row 格式,否则就用 statement 格式
-
row 的缺点 : 很占存储。如 : delete 删掉 10 万行数据 , 0 万条记录都写到 binlog
-
statement : SQL 记录到 binlog ,仅占用几十个字节
mixed 格式的特别点 :
insert into t values(10, 10, now());
该 SQL 用 statement 格式 : 炸一看会引发主备不一致

用 mysqlbinlog 查看 :
- 其中 :
SETTIMESTAMP=1546103491: 约定now()的返回时间 - 依然能保障主备数据的一致性

生产格式
生产环境依然用 row 格式 , 其原因 : 利于恢复数据
各CUD 的恢复角度 :
- delete : 会把删掉的整行信息保存起来。所以当执行完一条 delete 后,发现删错数据了,就在 binlog 中记录的 delete 转成 insert,把错删的数据插入就可以恢复
- insert : 会记录所有的字段信息,能精准确定刚插入的那行数据。只要将 insert 转成 delete ,删除掉被误插入数据就行
- update : 会记录修改前整行的数据和修改后的整行数据。只要将 event 前后的信息对调下,再去进行更新恢复
循环复制问题
生产环境使用比较多的是双 M 结构 : 节点 A 和 B 之间总是互为主备关系
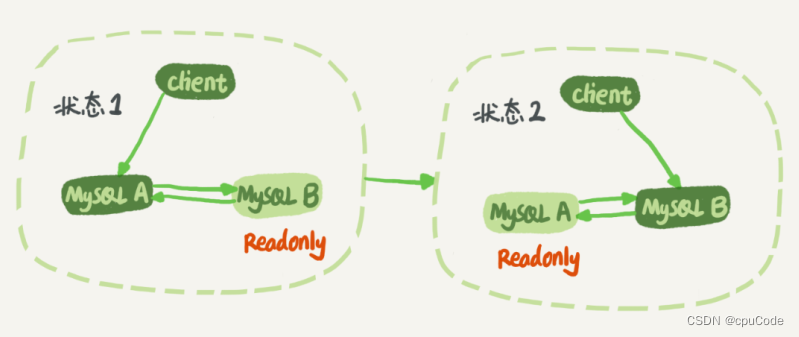
双 M 结构有个循环复制问题 :
- 建议参数 :
log_slave_updates = on: 备库执行 relay log 后生成 binlog - 节点 A 更新一条语句,再生成 binlog 发给节点 B,节点 B 执行完更新语句 , 也会生成 binlog
- 而节点 A 同时又是节点 B 的备库 : 会把节点 B 新生成的 binlog 拿过来执行一次
解决循环复制问题 :
- 两个节点的 server id 必须不同 (或者不能成为主备关系)
- binlog 中记录该命令第一次执行时 , 所在实例的 server id
- 备库接到 binlog 并重放时,生成原 binlog 的 server id 相同的新 binlog
- 备库 binlog 后,会先判断 server id,当与自己相同,表示该 binlog 是自己生成,就直接丢弃该 binlog
具体流程 :
- 节点 A 更新数据,binlog 记录 A 的 server id
- 传到节点 B 执行后,节点 B 生成的 binlog 的 server id 就是 A 的 server id
- 再传给节点 A,A 判断该 server id 是否与自己的相同,当相同就不执行该日志
- 死循环在这里就断掉
![Python蓝桥杯训练:基本数据结构 [二叉树] 中](https://img-blog.csdnimg.cn/dec5845a62084f10afa700ee7366802d.jpeg#pic_center)