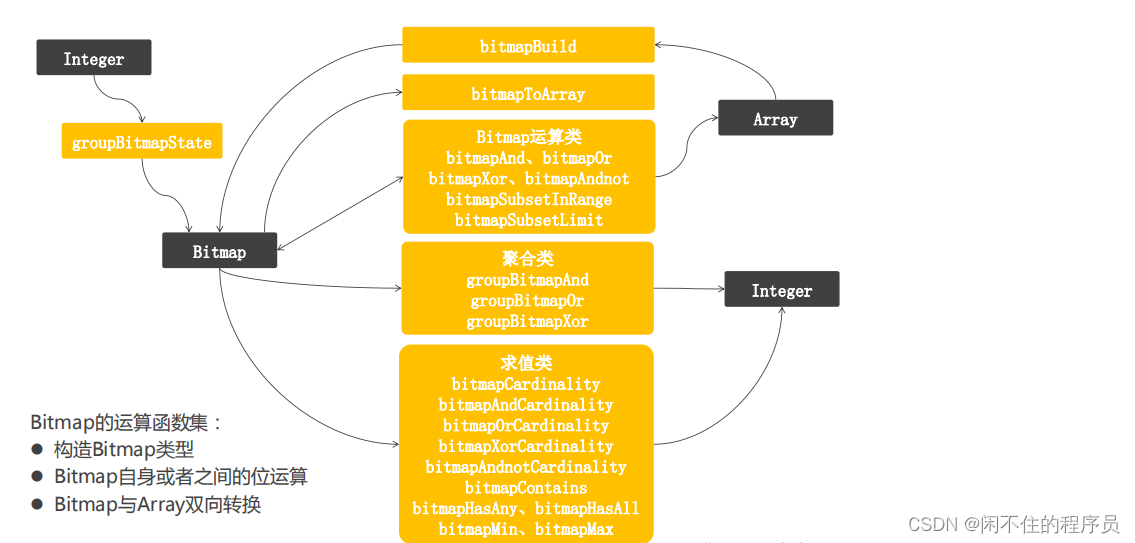
前言
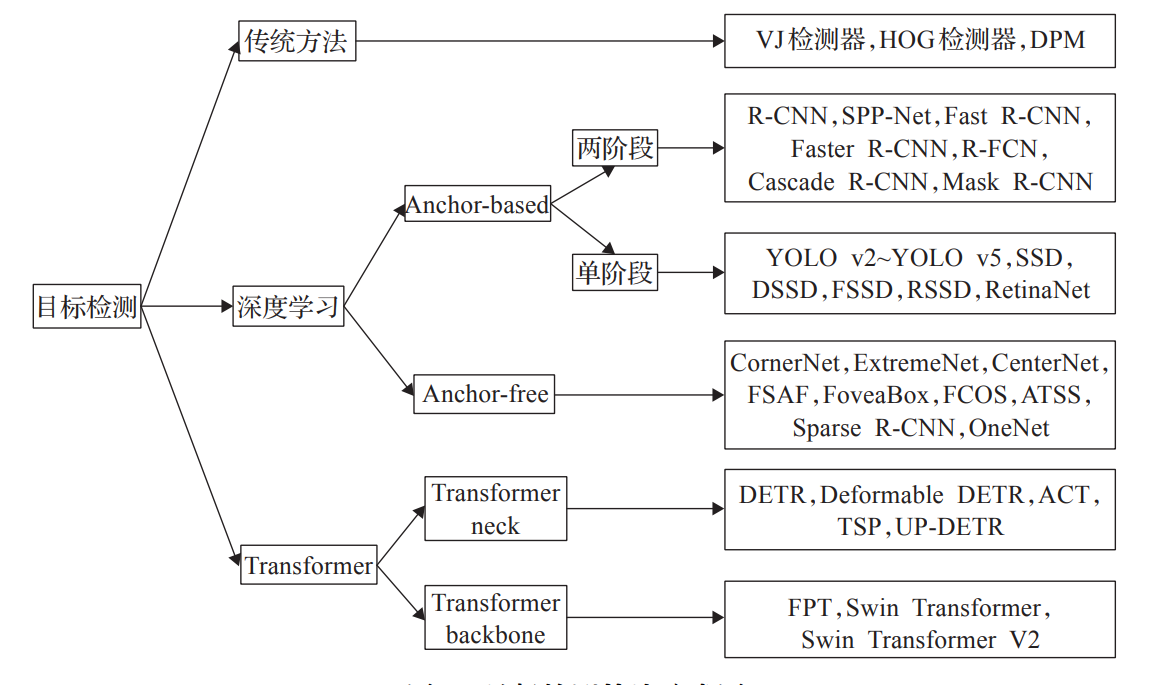
本文主要通过阅读相关论文了解当前Transformer在目标检测领域的应用与发展。
谷歌在 ICLR2020 上提出的 ViT(Vision Transformer)是将 Transformer 应用在视觉领域的先驱。从此,打开了Transformer进入CV领域的桥梁,NLP与CV几有大一统之趋势。
俗语云:万事开头难,尽管Transformer在CV领域的研究仍处于开始阶段,但伴随着研究者们夜以继日,前仆后继的不断深入,Transformer在CV领域的研究已经颇有成效,尤其是目标检测领域,随着2020 年 Carion 等人提出了一种新型的 Transformer 目 标检测框架DETR(Detection Transformer),为 Transformer 在目标检测任务中的应用奠定了重要的基础,后续出现了大量基于 DETR 的改进算法。
今天我们便围绕着Transformer在目标检测领域的研究工作展开学习。
Transformer 与 CNN 相结合
CNN 是基于临近像素具有较大相似性这一假设而形成的归纳偏置,局部性是它的典型特征,而Transformer 则对特征进行全局交互,因此,二者特征学习的方式和特征编码的内容有较大的差异。换言之,CNN侧重于局部特征的获取,而Transformer则在全局特征表达桑颇具心得。
因此,将 Transformer 和 CNN 相结合是提高模型特征提取能力的有效手段,下面从结构融合、特征融合和机理融合三个层面介绍 Transformer 和 CNN 结合的方法。
结构融合
旨在通过对多个模块进行有效的组合形成新的网络结构。
MobileViT将 Transformer 视为一个模块,集成到卷积神经网络中,使模型同时具备局部性和全局性。
MPViT采用多路并行的 Encoder 和卷积实现全局特征和局部特征的共享,达到了 SOTA 性能。
特征融合
该方式从特征层面入手,一般采用并行分支结构,融合 CNN 和 Transformer 提取到的特
征来增强特征表达能力。
Peng 等人(2021)提出的Conformer模型设计了并行的 CNN 和 Transformer分支,采用桥接模块实现特征融合。将 Conformer 作为 Backbone,在 COCO 上的 mAP 达到了 44.9%。
DeiT 结合知识蒸馏的思想,通过将 CNN 学习到的特征引入到 Transformer的训练过程中,实现两种特征的融合。
机理融合
结构融合与特征融合通过串行或并行的方式实现 Transformer 与 CNN 的结合,但注意力
机制和卷积仍然是不同的两个部分,没有充分的利用它们之间的相关性,而机理融合通过深入挖掘二者之间的内在联系,合理的集成注意力和卷积。
ACmix深入分析了自注意力与卷积特征提取机理的相似性,通过共享特征映射参数实现自注意力和卷积的机理融合,ACmix 同时具有局部性和全局性,在迁移至目标检测任务中时,在 COCO 上的 mAP 达到了 51.1%。
小结
Transformer 骨干网络通过自注意力编码图像全局特征,为检测器提供了高质量中间特征,其全局建模能力是 CNN 所不具备的。
但其仍存在许多问题:
- Transformer骨干的研究尚处于起步阶段,仍然存在计算量大、丢失细节信息等问题,目前,针对这些问题的改进主要围绕注意力机制展开,如:通过限制注意力作用范围以及下采样输入序列来降低计算量;通过解耦注意力机制来避免因合并操作丢失细节信息。此外,对Transformer 多尺度特征的设计和利用也是解决信息丢失的重要方法。
- 虽然 Transformer骨干提高了各种检测器的性能,但 CNN 的局部信息提取能力同样是 Transformer所欠缺的,并且在小样本训练时 CNN 更具优势,因此,Transformer 和 CNN相结合是研究的趋势,除了结构融合和特征融合这种较为直观的结合方式,进一步探究注意力和卷积的特征提取机制,挖掘其中的相似性,在机理层面实现二者的融合也取得了很好的效果。
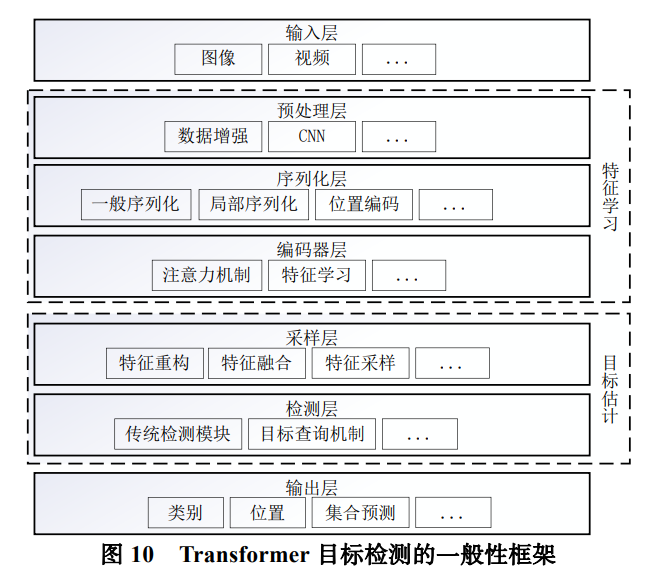
预处理层
预处理层的主要功能包括数据增强和特征预学习。其中,数据增强通过引入多种变换在原训练集的基础上生成更多虚假样本,丰富了样本的多样性,有助于提高模型的泛化能力和检测性能;特征预学习通过 CNN 对原始输入图片做初步的特征提取,在增强特征的同时降低了后续编码器模块的输入分辨率,减少了计算量。
序列化层
序列化层的主要功能为:将图像输入划分为词向量序列并进行位置编码。一般的序列划分方式在输入的全局范围内进行划分,序列中的全部词向量通过注意力机制进行直接的交互,而以 Swin Transformer 为代表的窗口机制则是一种局部方式,位于同一窗口或组别中的词向量可在后续层中进行局部的交互;由于Transformer 缺乏位置感知能力,所以通过位置编码为模型显式的添加位置信息,位置编码方式主要分为绝对位置编码和相对位置编码,绝对位置编码只考虑了词向量在序列中的位置信息,相对位置编码则考虑了序列中词向量对之间的相对位置关系。
编码器层
一般采用标准 Transformer 编码器结构,通过注意力机制对序列化特征进行交互。自注意力机制通过计算词向量之间的相关性得到注意力分布,基于注意力分布实现特征的加权聚合。该层是特征学习环节的重要组成部分。
采样层
采样层主要负责特征重构以及特征采样和合并。其中,如果后续检测层沿用了基于 CNN 的目标检测模型的检测网络,则需要将序列特征重构为空间特征图,再将其馈入到检测网络中。特征的采样和合并主要有两方面的功能:减少序列中的词向量个数,从而减少计算量以及处理 Transformer 层级特征,例如配合FPN等多尺度特征融合技术或 ResNet残差链接思想进一步的增强和利用层级特征。
检测层
检测层旨在根据多个尺度的特征对图像中目标的位置和类别信息进行处理和预测。检测层的实现方式主要有两类:第一类,传统的基于 CNN 的目标检测模型的检测网络。第二类,基于解码器结构的目标估计,如 DETR 中的目标查询机制,通过目标查询向量与图像特征进行交互,抽取潜在的目标位置信息和类别信息,然后采用全连接网络预测目标信息,形成检
测结果。