系列目录
分布式架构-流量治理-服务容错
分布式架构-流量治理-流量控制
引子
容错性设计(Design for Failure)是微服务的一个核心原则。随着拆分出的服务越来越多,随之而来会面临以下两个问题的困扰:
- 由于某一个服务的崩溃,导致所有用到这个服务的其他服务都无法正常工作,这便是雪崩效应。如何防止雪崩效应便是微服务架构容错性设计原则的具体实践。
- 服务虽然没有崩溃,但由于处理能力有限,面临超过预期的突发请求时,大部分请求直至超时都无法完成处理。
本章我们将围绕以上两个问题,提出服务容错、流量控制等一系列解决方案。
1. 容错性设计
微服务真正的崛起是在 2014 年, Martin Fowler 与 James Lewis 合写的文章《Microservices: A Definition of This New Architectural Term》中首次提出微服务。文中定义的微服务的概念:
微服务是一种通过多个小型服务组合来构建单个应用的架构风格,这些服务围绕业务能力而非特定的技术标准来构建。各个服务可以采用不同的编程语言,不同的数据存储技术,运行在不同的进程之中。服务采取轻量级的通信机制和自动化的部署机制实现通信与运维。文中列举了微服务的九个核心的业务与技术特征:
- 围绕业务能力构建(Organized around Business Capability)。
- 分散治理(Decentralized Governance)。开发团队有直接对服务运行质量负责的责任,也应该有着不受外界干预地掌控服务各个方面的权力,譬如选择与其他服务异构的技术来实现自己的服务。
- 通过服务来实现独立自治的组件(Componentization via Services)。强调通过“服务”(Service)而不是“类库”(Library)来构建组件。
- 产品化思维(Products not Projects)。避免把软件研发视作要去完成某种功能,而是视作一种持续改进、提升的过程。譬如,在微服务下,要求开发团队中每个人都具有产品化思维,关心整个产品的全部方面是具有可行性的。
- 数据去中心化(Decentralized Data Management)。微服务明确地提倡数据应该按领域分散管理、更新、维护、存储。
- 强终端弱管道(Smart Endpoint and Dumb Pipe)。弱管道(Dumb Pipe)反对 SOAP 和 ESB 的那一堆复杂的通信机制。微服务提倡类似于经典 UNIX 过滤器那样简单直接的通信方式,RESTful 风格的通信在微服务中会是更加合适的选择。
- 容错性设计(Design for Failure)。不再虚幻地追求服务永远稳定,而是接受服务总会出错的现实,要求在微服务的设计中,有自动的机制对其依赖的服务能够进行快速故障检测,在持续出错的时候进行隔离,在服务恢复的时候重新联通。
- 演进式设计(Evolutionary Design)。演进式设计则是承认服务会被报废淘汰。一个设计良好的服务,应该是能够报废的,而不是期望得到长存永生。
- 基础设施自动化(Infrastructure Automation)。基础设施自动化,如 CI/CD 的长足发展,显著减少了构建、发布、运维工作的复杂性。使用微服务的团队更加依赖于基础设施的自动化,人工是很难支撑成百上千乃至成千上万级别的服务的。
微服务的九个核心特征,是构建微服务系统的指导性原则,但不是技术规范,并没有严格的约束力。但容错性设计是不能妥协的,因为分布式系统的本质是不可靠的。下面我们来看一些常用的容错策略和容错设计模式。
2. 容错策略
面对故障,我们该做些什么?
这里列举几种常用容错策略的优缺点、应用场景总结如下表:| 容错策略 | 描述 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
|
故障转移(Failover)
| 对于幂等服务,调用出现故障,系统不会立即向调用者返回失败结果,而是自动切换到其他服务副本, 尝试其他副本能否返回成功调用的结果,从而保证了整体的高可用性。 | 系统自动处理,调用者对失败的信息不可见 | 增加调用时间,额外的资源开销 | 调用幂等服务 对调用时间不敏感的场景 |
| 快速失败 (Failfast) | 对于非幂等的服务,重复调用就可能产生脏数据,引起的麻烦远大于单纯的某次服务调用失败,此时就 应该以快速失败作为首选的容错策略。 | 调用者有对失败的处理完全控制权 不依赖服务的幂等性 | 调用者必须正确处理失败逻辑,如果一味只是 对外抛异常,容易引起雪崩 | 调用非幂等的服务 超时阈值较低的场景 |
| 安全失败 (Failsafe) | 部分旁路服务失败了也不应该影响核心业务的正确性。旁路逻辑调用失败了,正确返回,并返回一个符 合要求的数据类型的对应零值,然后自动记录一条服务调用出错的日志备查即可。 | 不影响主路逻辑 | 只适用于旁路调用 | 调用链中的旁路服务 |
| 沉默失败 (Failsilent) | 当请求失败后,就默认服务提供者一定时间内无法再对外提供服务,不再向它分配请求流量,将错误隔 离开来,避免对系统其他部分产生影响。 | 控制错误不影响全局 | 出错的能力将在一段时间内不可用 | 频繁超时的服务 |
| 故障恢复 (Failback) | 故障恢复一般不单独存在,而是作为其他容错策略的补充措施,通常默认会采用快速失败+故障恢复的 策略组合。塞进MQ消息,系统自动异步重试调用。 | 调用失败后自动重试,也不影响主路逻辑 | 重试任务可能产生堆积,重试仍然可能失败 | 调用幂等服务,调用链中的旁路服务 |
| 并行调用 (Forking) | 同时向多个服务副本发起调用,只要有其中任何一个返回成功,那调用便宣告成功,这是一种在关键场 景中使用更高的执行成本换取执行时间和成功概率的策略。 | 尽可能在最短时间内获得最高的成功率 | 额外消耗机器资源,大部分调用可能都是无用功 | 资源充足且对失败容忍度低的场景 |
| 广播调用 (Broadcast) | 广播调用与并行调用是相对应的,广播调用则是要求所有的请求全部都成功,这次调用才算是成功, 任何一个服务提供者出现异常都算调用失败, | 支持同时对批量的服务提供者发起调用 | 资源消耗大,失败概率高 | 只适用于批量操作的场景,通常会被用于 实现“刷新分布式缓存”这类的操作。 |
仔细分析这7种常见容错策略,故障转移、快速失败、安全失败、沉默失败比较常见;故障恢复+快速失败经常结合使用,提供一种延迟重试、最终一致性策略,在现代分布式业务中很常见;并行/广播调用几乎很少用,只在特定目的场景使用。
3. 容错设计模式
要实现某种容错策略,我们该如何去做?
为了实现各种各样的容错策略,开发人员总结出了一些被实践证明是有效的服务容错设计模式,譬如微服务中常见的断路器模式、舱壁隔离模式,重试模式,等等,以及将在下一节介绍的流量控制模式,如滑动时间窗模式、漏桶模式、令牌桶模式,等等。
3.1 断路器模式
断路器模式是微服务架构中最基础的容错设计模式。基本思路:通过代理(断路器对象)来一对一地(一个远程服务对应一个断路器对象)接管服务调用者的远程请求。断路器会持续监控并统计服务返回的成功、失败、超时、拒绝等各种结果,当出现故障(失败、超时、拒绝)的次数达到断路器的阈值时,它状态就自动变为“OPEN”,后续此断路器代理的远程访问都将直接返回调用失败,而不会发出真正的远程服务请求。通过断路器对远程服务的熔断,避免因持续的失败或拒绝而消耗资源,因持续的超时而堆积请求,最终的目的就是避免雪崩效应的出现。由此可见,断路器本质是一种快速失败策略的实现方式,它的工作过程可以通过下面图:

3.2 舱壁隔离模式
舱壁隔离模式是常用的实现服务隔离的设计模式,舱壁这个词是来自造船业的舶来品,它原本的意思是设计舰船时,要在每个区域设计独立的水密舱室,一旦某个舱室进水,也只是影响这个舱室中的货物,而不至于让整艘舰艇沉没。这种思想就很符合容错策略中失败静默策略。
1.服务调用维度有两种常见实现:
- 线程隔离:为每个服务单独设立线程池,这些线程池默认不预置活动线程,只用来控制单个服务的最大连接数。典型的就是Hystrix的线程隔离设计。缺点是对性能影响较大。(大概会为每次服务调用增加约 3 毫秒至 10 毫秒的延时)原理如下图:
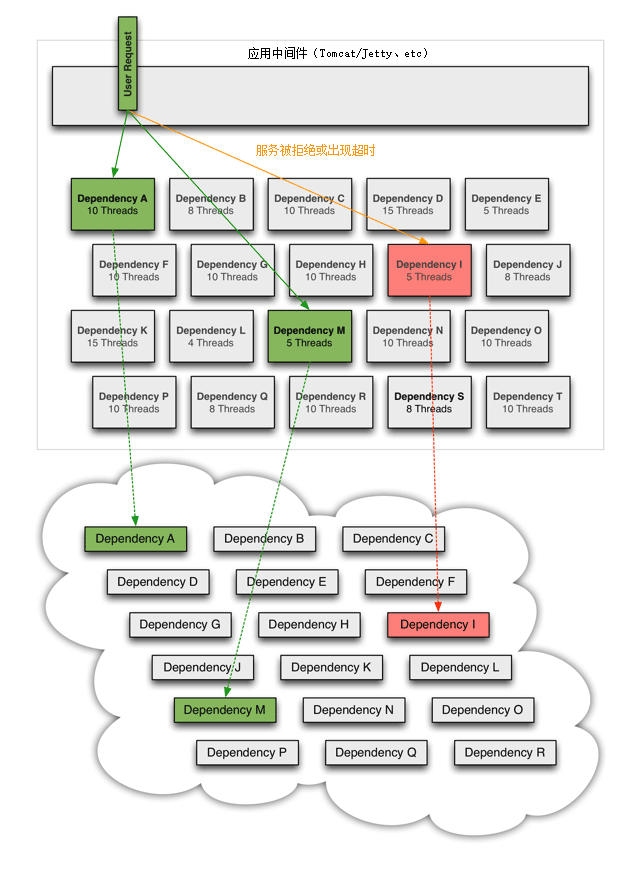
- 信号量机制(Semaphore):控制一个服务并发调用最大次数。为每个远程服务维护一个线程安全的计数器即可,当服务开始调用时计数器加 1,服务返回结果后计数器减 1,一旦计数器超过阈值就限流。(Semaphore懂点计算机的都知道了,这个linux内核原语;应用层语言Java中也有这个类)。
2.实际上舱壁隔离还可以从其它维度来实现,比如:按功能、按子系统、按用户类型、地域等等。
3.3 重试模式
故障转移和故障恢复策略都需要对服务进行重复调用,差别是同步的/后台异步进行的。这两个策略都需要使用重试模式来实现。重试模式适合解决系统中的瞬时故障,简单的说就是有可能自己恢复(Resilient,称为自愈,也叫做回弹性)的临时性失灵,网络抖动、服务的临时过载(典型的如返回了 503 Bad Gateway 错误)这些都属于瞬时故障。适合做重试的服务调用的条件有:
- 仅在主路逻辑的关键服务上进行同步的重试,不是关键的服务,一般不把重试作为首选容错方案,尤其不该进行同步重试。
- 仅对由瞬时故障导致的失败进行重试。功能完善的服务治理工具会提供具体的重试策略配置(如 Envoy 的Retry Policy),可以根据包括 HTTP 响应码在内的各种具体条件来设置不同的重试参数。
- 仅对具备幂等性的服务进行重试。
- 重试必须有明确的终止条件,常用的终止条件有两种:超时终止、次数终止。
本节介绍的容错策略和容错设计模式,最终目的均是为了避免服务集群中某个节点的故障导致整个系统发生雪崩效应,但仅仅做到容错,只让故障不扩散是远远不够的,我们还希望系统或者至少系统的核心功能能够表现出最佳的响应的能力,不受或少受硬件资源、网络带宽和系统中一两个缓慢服务的拖累。下一节,我们将面向如何解决集群中的短板效应,去讨论服务质量、流量管控等话题。
===========参考================
全文学习整理自:凤凰架构:https://icyfenix.cn/distribution/traffic-management/failure.html

![[深入理解SSD系列 闪存2.1.5] NAND FLASH基本读操作及原理_NAND FLASH Read Operation源码实现](https://img-blog.csdnimg.cn/img_convert/72f13a2b5cb2911feebdafaf3c42842e.png)






![[MySQL核心]2.select单表查询常见操作](https://img-blog.csdnimg.cn/fecff9377cf04eb0adfa189e7d65b94a.png)