安装 transformers 库。
!pip install transformers
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_datasets as tfds
from transformers import BertTokenizer
from sklearn.model_selection import train_test_split
from transformers import TFBertForSequenceClassification
import warnings
warnings.filterwarnings('ignore')
加载 IMDB 数据集。
# 加载IMDB数据集
train_dataset = tfds.load(name='imdb_reviews', # 数据集名称
split='train', # 切分为训练集
as_supervised=True # 返回 (input, label)
)
test_dataset = tfds.load(name='imdb_reviews',
split='test',
as_supervised=True)
设置要调用的预训练模型名称。
BERT 是一种自然语言处理模型,能够理解文本的含义。bert-base-uncased和bert-base-cased是 BERT 的两个预训练模型。
bert-base-uncased的 “uncased” 表示它是一个不区分大小写的模型。这意味着在预处理数据中,所有单词都被转换为小写字母。这种模型的优点是在处理文本时能够忽略大小写,从而减少模型需要处理的单词数量,减少计算量。
bert-base-cased的 “cased” 表示它是一个区分大小写的模型。在预处理数据中,保留了单词的原始大小写形式。这种模型的优点是在处理文本时可以更好地保留单词的信息,因为不同的大小写形式可能具有不同的含义。
在实际应用中,使用哪种模型取决于任务本身需要处理的文本是否区分大小写。例如,如果一个任务需要处理大小写敏感的文本,那么 bert-base-cased 可能是更好的选择。如果一个任务不需要处理大小写敏感的文本,那么 bert-base-uncased 可能是更好的选择。
bert_name = 'bert-base-uncased' # 不区分大小写,Love = love
tokenizer = BertTokenizer.from_pretrained(bert_name,
add_special_tokens=True,
do_lower_case=True,
max_length=150,
pad_to_max_length=True)
这段代码使用 Hugging Face Transformers 库中的
BertTokenizer类来初始化一个分词器对象。
bert_name是一个字符串,指定要使用哪个预训练的 BERT 模型。例如,它可以是 “bert-base-uncased”,表示使用基础的小写版本的 BERT。
add_special_tokens是一个布尔值,表示是否在输入序列中添加特殊标记。这些标记包括在序列开头的 [CLS] 标记和在序列中的句子对之间的 [SEP] 标记。
do_lower_case是一个布尔值,表示是否将所有输入文本转换为小写。
max_length是一个整数,指定经过分词后的输入序列的最大长度。如果序列长度超过这个值,它将被截断。如果长度不够,分词器将使用特殊标记来填充序列。
pad_to_max_length是一个布尔值,表示是否将输入序列填充到 max_length 指定的最大长度。如果为 True,则分词器将使用特殊标记来填充序列,使其长度与 max_length 相同。如果为 False,则分词器将不填充序列,并返回长度小于 max_length 的序列。
总的来说,这段代码设置了一个分词器对象,用于将输入文本标记化为可以喂入 BERT 模型进行文本分类或其他自然语言处理任务的格式。
# tokenizer的返回结果
tokenizer.encode_plus("The Chinese New Year is coming.",
add_special_tokens=True,
max_length=15,
pad_to_max_length=True,
return_attention_mask=True,
return_token_type_ids=True)
这段代码使用了
encode_plus函数来对给定的文本进行编码, 生成可用于输入到预训练模型的 tokens 和其他信息。
具体来说,它的参数如下:
"The Chinese New Year is coming.": 给定的文本,需要进行编码的文本,当然这只是一个示例啦。
add_special_tokens=True: 是否在 tokens 中添加特殊 tokens(例如,[CLS], [SEP])以供模型使用。
max_length=15: 编码后 tokens 的最大长度限制。如果 tokens 的长度不合法,将进行截断或填充。
pad_to_max_length=True: 是否在 tokens 末尾填充0以使它们具有相同的长度。
return_attention_mask=True: 是否返回 attention mask。这个 mask 指示哪些 tokens 是实际输入和哪些tokens是填充的。
return_token_type_ids=True: 是否返回 token type IDs。这个 ID 指示 tokens 属于哪个句子,对于单句输入,它将为0。
{
'input_ids': [101, 1996, 2822, 2047, 2095, 2003, 2746, 1012, 102, 0, 0, 0, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]
}
此函数返回一个字典,其中包含以下键值对:
"input_ids": 编码后的 token 的列表,每个 token 都由一个整数表示。
"attention_mask": 一个由0和1组成的列表,用于指示哪些 tokens 是实际输入和哪些 tokens 是填充的。
"token_type_ids": 一个由0和1组成的列表,用于指示 tokens 属于哪个句子,对于单句输入,它将为0。
BERT 在处理文本时会对标点符号进行编码。
在 BERT 中,标点符号被视为一个独立的单词,与其他单词一样被嵌入到向量空间中。这意味着BERT在处理文本时不仅考虑了单词本身的含义,还考虑了它们之间的关系和上下文。
例如,在句子中使用逗号或句号可能会改变整个句子的含义,因此 BERT 会将这些标点符号编码为一个单独的词,并考虑它们在上下文中的作用。这种方法有助于提高 BERT 在处理自然语言处理任务中的性能,因为它能够更好地捕捉文本中的复杂性和细微差别。
特殊意义的编码。
[CLS] = 101;[SEP] = 102;[PAD] = 0
def bert_encode(text):
text = text.numpy().decode('utf-8')
encode_result = tokenizer.encode_plus(text,
add_special_tokens=True,
max_length=150,
pad_to_max_length=True,
return_attention_mask=True,
return_token_type_ids=True)
input_ids = encode_result['input_ids']
token_type_ids = encode_result['token_type_ids']
attention_mask = encode_result['attention_mask']
return input_ids, token_type_ids, attention_mask
text = text.numpy().decode('utf-8')
输入的 Tensor 张量对象是一个包含了 UTF-8 编码的文本字符串的张量。
首先,它使用 numpy() 方法将张量对象转换为 NumPy 数组对象。
然后,使用 NumPy 数组对象的 decode() 方法将 UTF-8 编码的字符串转换为 Python 字符串。
# 对数据集进行转换
bert_encode_train = [bert_encode(text) for text, label in train_dataset]
bert_encode_label = [label for text, label in train_dataset]
bert_encode_train = np.array(bert_encode_train) # 类型转换 tensor -> array
bert_encode_label = tf.keras.utils.to_categorical(bert_encode_label, num_classes=2) # 标签类型转换
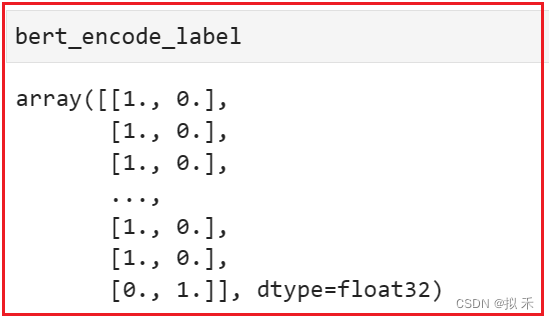

划分数据集。
X_train, X_val, y_train, y_val = train_test_split(bert_encode_train,
bert_encode_label,
test_size=0.2,
random_state=520)
将
X_train和X_val分为三部分。
train_inputs_ids, train_token_type_ids, train_attention_masks = np.split(X_train, 3, axis=1) # 拆分
val_inputs_ids, val_token_type_ids, val_attention_masks = np.split(X_val, 3, axis=1)
减掉多余的1维。
train_inputs_ids = train_inputs_ids.squeeze()
train_token_type_ids = train_token_type_ids.squeeze()
train_attention_masks = train_attention_masks.squeeze()
val_inputs_ids = val_inputs_ids.squeeze()
val_token_type_ids = val_token_type_ids.squeeze()
val_attention_masks = val_attention_masks.squeeze()
定义构建训练和验证批数据的函数
combine_dataset。
def combine_dataset(input_ids, token_type_ids, attention_mask, label):
data_format = {'input_ids' : input_ids,
'token_type_ids' : token_type_ids,
'attention_mask' : attention_mask}
return data_format, label
# 训练批数据
train_ds = tf.data.Dataset.from_tensor_slices((train_inputs_ids,
train_token_type_ids,
train_attention_masks,
y_train)).map(combine_dataset).shuffle(100).batch(16)
这段代码创建了一个用于训练机器学习模型的数据集(train_ds)。该数据集包含三个输入张量 train_inputs_ids、train_token_type_ids、train_attention_masks 和一个目标变量 y_train。
首先,tf.data.Dataset.from_tensor_slices()方法将三个输入张量与目标变量 y_train 沿着第一个维度进行切片,形成了多个元组,每个元组包含四个分别对应的张量切片。这样每个元组就对应着一个样本。
然后,map()方法将 combine_dataset 函数映射到数据集的每个元素上。combine_dataset函数将四个输入张量打包成一个字典,键为字符串 ‘input_ids’、‘token_type_ids’ 和 ‘attention_mask’,值为对应的张量。这样,每个元组就被转换为了一个字典,其中包含了对应的输入数据和目标变量。
接下来,shuffle()方法将数据集中的元素进行随机洗牌,以增加模型的泛化能力。参数 100 指定了洗牌时所使用的缓冲区大小,即每次随机选取的元素数量。
最后,batch()方法将数据集中的元素按照指定的批大小进行分组,每个批包含了指定数量的样本。这里的批大小为 16,即每个批次包含了 16 个样本。这样,整个数据集被分成了若干个批次,每次训练模型时只需要处理一个批次的数据,从而减少了内存占用和计算时间。
# 验证批数据
val_ds = tf.data.Dataset.from_tensor_slices((val_inputs_ids,
val_token_type_ids,
val_attention_masks,
y_val)).map(combine_dataset).shuffle(100).batch(16)
加载模型。
from transformers import TFBertForSequenceClassification
bert_model = TFBertForSequenceClassification.from_pretrained(bert_name)
注意是
TFBertForSequenceClassification,可不敢写成TFBartForSequenceClassification。
我就犯了这个错,因为确实存在BART这个模型,细心一点,避免不必要的麻烦。
# 定义优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=2e-5)
# 定义损失函数
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
# 模型编译
bert_model.compile(optimizer=optimizer,
loss=loss,
metrics=['accuracy'])
bert_model.summary()
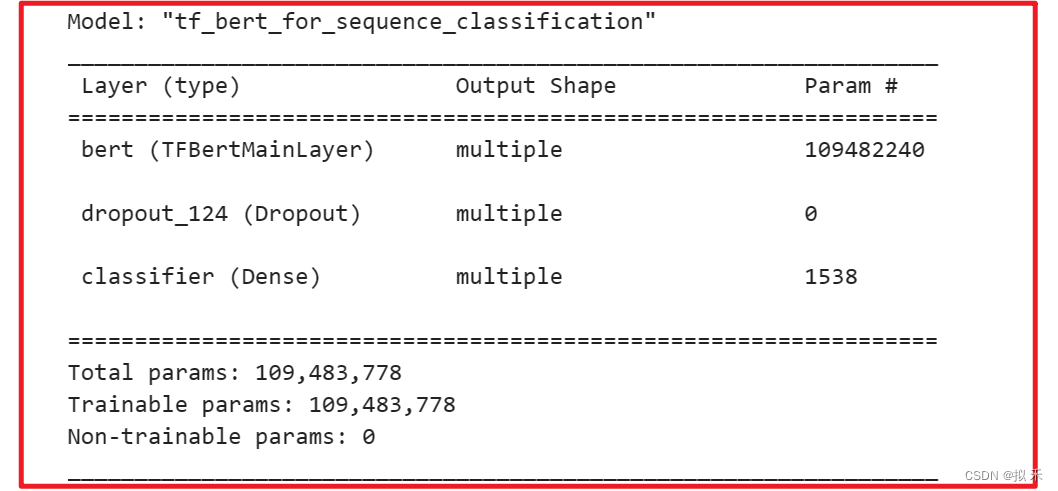
history = bert_model.fit(train_ds,
epochs=1,
validation_data=val_ds)
BERT 模型很大哈~,我垃圾电脑跑不起来,就用 Colab 训练了一轮,结果如下:

在测试集上进行测试,和训练集相同的预处理操作。
bert_test = [bert_encode(text) for text ,label in test_dataset]
bert_test_label = [label for text, label in test_dataset]
bert_test = np.array(bert_test)
bert_test_label = tf.keras.utils.to_categorical(bert_test_label, num_classes=2)
test_inputs_ids, test_token_type_ids, test_attention_masks = np.split(bert_test, 3, axis=1) # 拆分
test_inputs_ids = test_inputs_ids.squeeze()
test_token_type_ids = test_token_type_ids.squeeze()
test_attention_masks = test_attention_masks.squeeze()
test_ds = tf.data.Dataset.from_tensor_slices((test_inputs_ids,
test_token_type_ids,
test_attention_masks,
bert_test_label)).map(combine_dataset).shuffle(100).batch(16)
# 模型测试
bert_model.evaluate(test_ds)

只训练了一轮哦,最后效果还挺不错的哈。
在你想要放弃的那一刻,想想为什么当初坚持了那么久。