现pyflink环境为1.16 ,下面介绍下常用的datastream算子。
现我整理的都是简单的、常用的,后期会继续补充。
官网:https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/dev/python/datastream/intro_to_datastream_api/
from pyflink.common import Configuration
from pyflink.datastream import StreamExecutionEnvironment
#构建环境,构建环境时,可添加配置参数,也可默认
# https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/dev/python/python_config/
config = Configuration()
config.set_integer("python.fn-execution.bundle.size", 1000)
env = StreamExecutionEnvironment.get_execution_environment(config)
#默认 无参
env = StreamExecutionEnvironment.get_execution_environment()
#添加配置
env.set_parallelism(1) #添加配置:并行度 其他配置可参考官网 https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/dev/datastream/execution/execution_configuration/
数据输入
1.from_collection
从集合Collection中读取数据,用的比较多的。但是一般都是本地测试或者单机运行的时候用。
主要就是两个参数
1:collection(必填) 数组类型-就是传入的数据,数据类型需要对应。
2:type_info(非必填) TypeInformation类型,定义数据的scheam,通过Types.ROW_NAMED定义列名,后面的数组是定义数据类型,三个对应上就行
ds = env.from_collection(
[('a', 'id=1', 1), ('a', 'id=2', 2), ('a', 'id=3', 3), ('b', 'home=1', 1), ('b', 'home=2', 2)],
type_info=Types.ROW_NAMED(["key", "url", "value"], [Types.STRING(), Types.STRING(), Types.INT()]))
2.read_text_file
逐行读取给定的文件并创建一个数据流,该数据流包含一个字符串每一行的内容。
两个参数:
1.file_path :文件路径 类型 'file:///some/local/file' or 'hdfs://host:port/file/path'
2.charset_name:默认utf-8
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
ds1 = env.read_text_file("D:\\tmp\\requirements.txt")
ds1.print()
env.execute()3.from_source
传递source来获取datastream类型的数据。
主要参数:
source:source数据源
watermark_strategy: Watermark生成策略,有单调递增策略(forMonotonousTimestamps)、固定乱序长度策略(forBoundedOutOfOrderness)等等有需要自己百度下。
source_name:名称
type_info:类型
下面就是生成单调递增的1-10的数据
seq_num_source = NumberSequenceSource(1, 10)
ds = env.from_source(
source=seq_num_source,
watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(), #单调递增的策略
source_name='seq_num_source',
type_info=Types.LONG())
ds.print()
ds.execute()还可读取文件,通过FileSource.for_record_stream_format方法读取文件。input_path为文件路径
ds = env.from_source(
source=FileSource.for_record_stream_format(StreamFormat.text_line_format(),
input_path)
.process_static_file_set().build(),
watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(),
source_name="file_source"
)4.add_source
自定义添加数据源,一般都是添加kafka。
add_source(self, source_func: SourceFunction, source_name: str = 'Custom Source', type_info: TypeInformation = None) -> 'DataStream':用户可以自定义kakfak的FlinkKafkaConsumer和 FlinkKafkaProducer
# 注意:file:///前缀不能省略
env.add_jars("file:///.../flink-sql-connector-kafka_2.11-1.12.0.jar")
deserialization_schema = JsonRowDeserializationSchema.builder() \
.type_info(type_info=Types.ROW([Types.LONG(), Types.LONG()])).build()
kafka_source1 = FlinkKafkaConsumer(
topics='test_source_topic',
deserialization_schema=deserialization_schema,
properties={'bootstrap.servers': 'localhost:9092', 'group.id': 'test_group'})
source_ds = env.add_source(kafka_source1).name('source_kafka')map_df = source_ds.map(lambda row: json.loads(row))
kafka_producer = FlinkKafkaProducer(
topic='test_source_topic',
serialization_schema=SimpleStringSchema(),
producer_config={'bootstrap.servers': 'localhost:9092'})
map_df.add_sink(kafka_producer).name('sink_kafka')但是你要用的是1.16版本,那么会提示你FlinkKafkaConsumer不支持了
class KafkaSource(Source):
"""
The Source implementation of Kafka. Please use a :class:`KafkaSourceBuilder` to construct a
:class:`KafkaSource`. The following example shows how to create a KafkaSource emitting records
of String type.
::
>>> source = KafkaSource \\
... .builder() \\
... .set_bootstrap_servers('MY_BOOTSTRAP_SERVERS') \\
... .set_group_id('MY_GROUP') \\
... .set_topics('TOPIC1', 'TOPIC2') \\
... .set_value_only_deserializer(SimpleStringSchema()) \\
... .set_starting_offsets(KafkaOffsetsInitializer.earliest()) \\
... .build()
.. versionadded:: 1.16.0
"""所以1.16之后 官方建议用KafkaSource和KafkaSink
from pyflink.common import SimpleStringSchema, WatermarkStrategy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import DeliveryGuarantee
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer, KafkaSink, \
KafkaRecordSerializationSchema
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:///path/to/flink-sql-connector-kafka.jar")
kafka_source = KafkaSource \
.builder() \
.set_bootstrap_servers('localhost:9092') \
.set_group_id('MY_GROUP') \
.set_topics('test_source_topic') \
.set_value_only_deserializer(SimpleStringSchema()) \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.build()
ds = env.from_source(kafka_source, WatermarkStrategy.no_watermarks(), "kafka source")
ds = ds.map(lambda x: x[0])
env.execute('datastream_api_demo')
但是把这个报错,跟自定义分区一样,不知道啥情况,等以后在研究研究,1.16也可以使用FlinkKafkaConsumer和 FlinkKafkaProducer,通过add_source来使用。
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:139)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:83)
at org.apache.flink.runtime.scheduler.DefaultScheduler.recordTaskFailure(DefaultScheduler.java:256)
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:247)
at org.apache.flink.runtime.scheduler.DefaultScheduler.onTaskFailed(DefaultScheduler.java:240)
at org.apache.flink.runtime.scheduler.SchedulerBase.onTaskExecutionStateUpdate(SchedulerBase.java:738)
at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:715)map(映射)
map是大家非常熟悉的大数据操作算子,主要用于将流中进行转换形成新的数据流,简单来说 就是一一映射,进来什么样出去就什么样。
from pyflink.common import Types
from pyflink.datastream import MapFunction, StreamExecutionEnvironment
##函数类实现,有点类似java的富含数类。
class MyMapFunction(MapFunction):
# 这个还可以实现open方法,当作全局调用
def __init__(self, str_p):
self.str_p = str_p
def map(self, value):
dd = value[1].split('|')
return dd[0] + "_" + self.str_p
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
data_stream = env.from_collection(
collection=[(1, 'aaa|bb'), (2, 'bb|a'), (3, 'aaa|a')],
type_info=Types.ROW([Types.INT(), Types.STRING()]))
# mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.ROW([Types.STRING(), Types.STRING()]))
mapped_stream = data_stream.map(MyMapFunction("pj"), output_type=Types.STRING())
#亦可以使用lambda匿名函数来实现
# maplambda_fun = data_stream.map(lambda x: x * 3)
# mapped_stream.print()
mapped_stream.print()
env.execute("1")
aaa_pj
bb_pj
aaa_pjfilter(过滤)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置转换过滤条件,对于一个流内元素进行判断,若为true则输出正常,为false则过滤元素。
filter只负责筛选数据,数据操作不要在filter实现
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, FilterFunction
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
data_stream = env.from_collection(
collection=[(1, 'aaa|bb'), (2, 'bb|a'), (3, 'aaa|a')],
type_info=Types.ROW([Types.INT(), Types.STRING()]))
class myFilterFunction(FilterFunction):
def __init__(self, condition):
self.condition = condition
def filter(self, value):
if value[1] == self.condition:
return value
result = data_stream.filter(myFilterFunction('aaa|bb'))
result1 = data_stream.filter(lambda x: x[1] == 'aaa|bb')
result.print()
env.execute()
+I[1, aaa|bb]flatMap(扁平映射)
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般集合类型)拆分成一个一个的个体使用。
map:进去是个体,出来也是个体;进去是集合,出来也是集合。
flatmap:进去是集合,出来是个体,当都是个体时跟map就没差了。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, FlatMapFunction
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
data_stream = env.from_collection([(1, 'aaa@bb'), (2, 'bb@a'), (3, 'aaa@a')])
#继承 FlatMapFunction ,这种写法主要作用就是为了实现抽象类,比如open实现全局变量长连接等
class myFlatMapFunciotn(FlatMapFunction):
def flat_map(self, value):
yield value[1].split("@")[0]
result = data_stream.flat_map(myFlatMapFunciotn(), result_type=Types.STRING())
# 如果业务处理中只是为了实现一些数据处理任务,可以直接编写函数实现,效果是一样的。
def split(value):
yield value[1].split("@")[0]
result1 = data_stream.flat_map(split)
result1.print()
env.execute("1")aaa
bb
aaa聚合算子( Aggregation)
直观上看,基本转换算子确实是在"转换",因为它们都是基于当前数据,去做了处理和输出。而在实际应用中,我们往需要对大量的数据进行统计或整合,从而提炼出更有用的信息。
计算的结果不仅依赖当前数据,还跟之前的数据有关,相当于要把所有的数据聚在一起进行汇总合并,这就是所谓的聚合,也对应这mapreduce中的reduce操作。
1.key_by
key_by是聚合前必须要用到的一个算子。keyby通过指定键,可以将一条流从逻辑上划分成不同的分区(partitions),这里说的分区,其实就是并行处理的子任务,也就对应这人物槽(task slot).
通过分区将数据流到不同的分区中,这样一来所有相同的key的数据都会发往同一个分区,也就是同一个人物槽中进行处理了。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
# data_stream = env.from_collection([(1, 'aaa@bb'), (2, 'bb@a'), (3, 'aaa@a')])
ds = env.from_collection(
[('a', 1), ('a', 2), ('a', 3), ('b', 1), ('b', 2)],
type_info=Types.ROW_NAMED(["key", "value"], [Types.STRING(), Types.INT()]))
result = ds.key_by(lambda x: x[0])
result.print(“1”)
env.execute()
+I[a,1]
+I[a,2]
+I[a,3]
+I[b,1]
+I[b,2]2.简单聚合
有了keyby分区之后我们就可以使用简单的聚合了,其实无论是sum、max、min等操作,直接DataStream 是不能直接使用的,因为必须分区后才能使用,这也是1.16版本后才可以使用的。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.set_parallelism(2)
ds = env.from_collection(
[('a', 'id=1', 1), ('a', 'id=2', 2), ('a', 'id=3', 3), ('b', 'home=1', 1), ('b', 'home=2', 2)],
type_info=Types.ROW_NAMED(["key", "url", "value"], [Types.STRING(), Types.STRING(), Types.INT()]))
# sum的参数可以是列名,也可以是position
# 该方法通过第一位(也就是key列)分区后,然后根据value列相加分别统计总数
#result = ds.key_by(lambda x: x[0]).sum("value")
result1 = ds.key_by(lambda x: x[0]).max("value")
result2 = ds.key_by(lambda x: x[0]).max_by("value")
result1.print("max:")
result2.print("max_by:")
env.execute()简单说下max和max_by的区别,它俩都是求指定字段的最小值,但是min只计算指定字段的最小心,其他字段会保留最初第一个数据的值,而min_by则会返回包含字段最小值的整条数据,min一样.
比如下面,观察下结果,max的结果中的url列的值是不变的,因为你只用了value来统计,而max_by是都变化的,用哪个就按照实际业务来把。
max:> +I[a,id=1,1]
max:> +I[a,id=1,2]
max:> +I[a,id=1,3]
max:> +I[b,home=1,1]
max:> +I[b,home=1,2]
max_by:> +I[a,id=1,1]
max_by:> +I[a,id=2,2]
max_by:> +I[a,id=3,3]
max_by:> +I[b,home=1,1]
max_by:> +I[b,home=2,2]3.归约聚合reduce
如果说简单聚合是对一些特定统计需求的实现,那么reduce算子就是一个一般化的聚合统计操作了。从MapReduce开始,我们就对reduce操作就不陌生了,他可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,在做一个聚合计算。
import random
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
##先生成一些随机数据
name_list = ["wang", "zhao", "yu"]
url_list = ["baidu.com", "taobao.com", "google.com", "yangshi.com"]
#name+url 统计下
result_list = []
for num in range(100):
result_tuple = (random.choice(name_list), random.choice(url_list))
result_list.append(result_tuple)
class MyReduceFunction(ReduceFunction):
# value1是归约后的结果,value2是新数据
def reduce(self, value1, value2):
return value1[0], value1[1] + value2[1]
ds = env.from_collection(result_list, type_info=Types.ROW_NAMED(["name", "url"], [Types.STRING(), Types.STRING()]))
result = ds \
.map(lambda x: (x.name + "_" + x.url, 1)) \ # 通过map先将数据映射成name_url 1的格式
.key_by(lambda x: x[0]) \ #通过name分区
.reduce(MyReduceFunction()) #事先reducefunction方法
result.print("reduce:")
env.execute()截取最后的输出,可以看到会累计打印出每个分区的访问累计数。
reduce:> ('wang_google.com', 14)
reduce:> ('wang_yangshi.com', 9)
reduce:> ('wang_taobao.com', 7)
reduce:> ('zhao_google.com', 9)
reduce:> ('yu_baidu.com', 8)
reduce:> ('zhao_taobao.com', 6)
reduce:> ('yu_yangshi.com', 12)
reduce:> ('zhao_yangshi.com', 10)
reduce:> ('zhao_google.com', 10)
reduce:> ('wang_baidu.com', 4)
reduce:> ('yu_yangshi.com', 13)但是就想要累计数最多的那个分区(也就是name_url),我们可以通过使用max,也可以使用reduce
import random
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, ReduceFunction
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
name_list = ["wang", "zhao", "yu"]
url_list = ["baidu.com", "taobao.com", "google.com", "yangshi.com"]
result_list = []
for num in range(100):
result_tuple = (random.choice(name_list), random.choice(url_list))
result_list.append(result_tuple)
class MyReduceFunction(ReduceFunction):
def reduce(self, value1, value2):
return value1[0], value1[1] + value2[1]
class MyReduceFunction2(ReduceFunction):
def reduce(self, value1, value2):
return value1 if value1[1] > value2[1] else value2
ds = env.from_collection(result_list, type_info=Types.ROW_NAMED(["name", "url"], [Types.STRING(), Types.STRING()]))
result = ds \
.map(lambda x: (x.name + "_" + x.url, 1)) \
.key_by(lambda x: x[0]) \
.reduce(MyReduceFunction()) \
.key_by(lambda x: "key") \ ##我们将所有分区结果都放到一个分区内,当数据量大时不要这样干,数据量小可以
.reduce(MyReduceFunction2()) ##通过第二个reducefunction 获取结果
result.print("reduce:")
env.execute()截取最后输出结果,通过打印可以看出来,这次只会打印当前累计数最大的组合名称,当有别的组合超过当前最大组合的累计数量才会替换,否则只会打印最大的。
reduce:> ('zhao_baidu.com', 10) # 当没有其他组合的数量超过·zhao_baidu.com·时,一直打印当前
reduce:> ('zhao_baidu.com', 10)
reduce:> ('wang_baidu.com', 11) #当·wang_baidu.com· 最多时就会打印该组合
reduce:> ('wang_baidu.com', 11)
reduce:> ('zhao_baidu.com', 11)
reduce:> ('zhao_baidu.com', 11)
reduce:> ('zhao_baidu.com', 11)
reduce:> ('wang_baidu.com', 12)
reduce:> ('wang_baidu.com', 12)
reduce:> ('wang_baidu.com', 13)
reduce:> ('wang_baidu.com', 13)
reduce:> ('wang_baidu.com', 13)物理分区(Physical Partitioning)
分区就是将数据进行重新分布,传递到不同的流分区去进行下一步处理。
前面介绍的key_by它就是按照键的哈希值来进行重新分区的操作,只不过这种分区操作只能保证把数据按key来分开,至于能不能分的均匀、每个key去哪个分区,这些都是无法控制的,所以常说key_by是一种逻辑分区操作,是一种"软分区"。
那下面我们介绍下什么是物理分区,也就是"硬分区"。物理分区是真正的分区策略,精准的调配数据,告诉每个数据该去哪个分区。
常见的物理分区策略有随机配( Random)、轮询分配( Round-Robin)、重缩放( Rescale和广播( Broadcast),下边我们分别来做了解。
1.随机分区
随机分区服从均匀分布,所以可以把流中的数据随机打乱,均匀的传递到下游任务分区,因为是随机的,所以就算数据一样,分区可能也可能不会相同。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 这里我们设施并行度是1 ,这里设置多少取决配置,我是本地执行那么就是cpu核数
ds = env.from_collection(
[('a', 'id=1', 1), ('a', 'id=2', 2), ('a', 'id=3', 3), ('b', 'home=1', 1), ('b', 'home=2', 2)],
type_info=Types.ROW_NAMED(["key", "url", "value"], [Types.STRING(), Types.STRING(), Types.INT()]))
ds.shuffle().print("shuffle:").set_parallelism(4) # 经过shuffle后我们设置并行度为4
env.execute()打印后我们可以看到,其中4条均匀分配到4个分区,多出一条随机到其中一个分区。
shuffle::4> +I[a,id=3,3]
shuffle::3> +I[a,id=2,2]
shuffle::2> +I[a,id=1,1]
shuffle::1> +I[b,home=1,1]
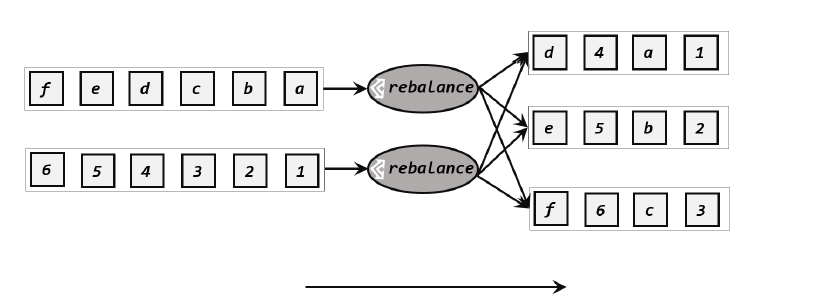
shuffle::2> +I[b,home=2,2]2.轮询分区(rebalance)
轮询也是一种常见的重分 区方式。简单来说就“发牌”,按照先后顺序将数据做依次分发。其实跟随机分区没啥太大的区别,只不过轮询使用的是Round-Robin负载均衡算法,比random更平均的分配到下游计算任务中。
import random
from pyflink.datastream import StreamExecutionEnvironment
name_list = ["wang", "zhao", "yu"]
url_list = ["baidu.com", "taobao.com", "google.com", "yangshi.com"]
result_list = []
for num in range(100):
result_tuple = (random.choice(name_list), random.choice(url_list))
result_list.append(result_tuple)
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 这里我们设施并行度是1 ,这里设置多少取决配置,我是本地执行那么就是cpu核数
ds = env.from_collection(
result_list
)
ds.rebalance().print("rebalance:").set_parallelism(4) # 经过rebalance后我们设置并行度为4
env.execute()
......
rebalance::3> ('wang', 'google.com')
rebalance::2> ('yu', 'taobao.com')
rebalance::1> ('wang', 'baidu.com')
rebalance::2> ('zhao', 'taobao.com')
rebalance::3> ('wang', 'google.com')
rebalance::3> ('wang', 'google.com')
rebalance::3> ('zhao', 'yangshi.com')
rebalance::4> ('yu', 'baidu.com')
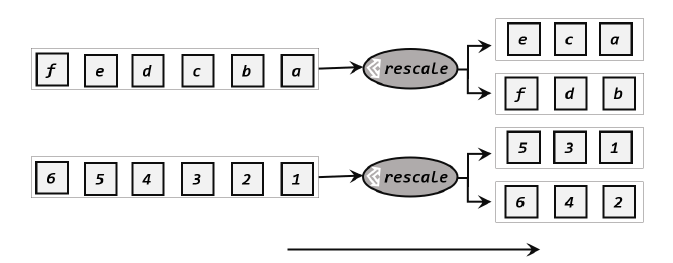
rebalance::3> ('zhao', 'google.com')3.重缩放分区 (rescale)
重缩放分区和轮询分区的算法都一样,都是使用Round-Robin负载均衡算法,但是跟轮询的差别是重缩放只会将数据发送到下游并行任务的一部分。如果发牌人有多个,那么轮询是每个发牌人都面向所有人发牌,而重缩放是分成小团体,发牌人只给自己的团体内的所有人轮流发牌。
什么时候该用重缩放?
1.当数据接收方的数量是数据发送方数量的整数倍时,rescale的效率就会更高。
2. 轮询分区和重缩放的连接机制是不同的,重缩放主要是针对每一个任务和校友对应的部分任务找时间建立通信,可以节省资源。而轮询因为是面向所有的数据接收方,当taskmanger数量较多时,这种跨节点的网络传输必然影响效率。
import random
from pyflink.datastream import StreamExecutionEnvironment
name_list = ["wang", "zhao", "yu"]
url_list = ["baidu.com", "taobao.com", "google.com", "yangshi.com"]
result_list = []
for num in range(100):
result_tuple = (random.choice(name_list), random.choice(url_list))
result_list.append(result_tuple)
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 这里我们设施并行度是1 ,这里设置多少取决配置,我是本地执行那么就是cpu核数
ds = env.from_collection(
result_list
)
ds.rescale().print("rescale:").set_parallelism(4) # 经过rescale后我们设置并行度为4
env.execute()
结果跟轮询和随机都差不多,主要是效率问题。
4.广播(broadcast)
这种其实不应该说是重分区,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理,可以调用broadcast(),将输入数据复制并发送到下游算子所有并行任务中去。
我理解这个应该跟spark的广播变量是一个意思,就是输入数据不用每个分区都发了,将输入数据定义成广播变量,这样就不用每个分区都传递变量。 提高效率。
import random
from pyflink.datastream import StreamExecutionEnvironment
name_list = ["wang", "zhao", "yu"]
url_list = ["baidu.com", "taobao.com", "google.com", "yangshi.com"]
result_list = []
for num in range(100):
result_tuple = (random.choice(name_list), random.choice(url_list))
result_list.append(result_tuple)
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 这里我们设施并行度是1 ,这里设置多少取决配置,我是本地执行那么就是cpu核数
ds = env.from_collection(
result_list
)
ds.broadcast().print("broadcast:").set_parallelism(4) # 经过broadcast后我们设置并行度为4
env.execute()
5.全局分区(global)
就是将所有数据传递到一个分区中,换句话说就是强制让分区数=1,这个太极端了,基本不常用。但是数据量少,或者是特殊情况可以用。
6.自定义分区(custom)
上面都满足不了你了,那么咱就自定义把。
通过partition_custom方法来自定义分区。需要传递两个参数;第一个是自定义分区器(partitioner)对象,第二个是应用分区器的字段,它的指定方式与keyby指定key的方式基本一样,可以通过字段名称指定,也可以通过字段位置的索引来指定。
from typing import Any
from pyflink.datastream import StreamExecutionEnvironment, Partitioner, KeySelector
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
##将奇偶数分区
ds = env.from_collection(
[1, 2, 3, 4, 5, 6, 7, 8]
)
class myPartitioner(Partitioner):
def partition(self, key: Any, num_partitions: int) -> int:
return key % 2
class myKeySelector(KeySelector):
def get_key(self, value):
return value
ds.partition_custom(myPartitioner(), myKeySelector()).print("custom:").set_parallelism(2)
env.execute()但是执行有错误。应该是提交作业失败,重新提交,但是我也没试明白。不知道咋回事,等后续在研究把。
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:139)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:83)
at org.apache.flink.runtime.scheduler.DefaultScheduler.recordTaskFailure(DefaultScheduler.java:256)
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:247)
at org.apache.flink.runtime.scheduler.DefaultScheduler.onTaskFailed(DefaultScheduler.java:240)
at org.apache.flink.runtime.scheduler.SchedulerBase.onTaskExecutionStateUpdate(SchedulerBase.java:738)
at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:715)
数据输出
当数据流经过一系列的转换后,需要将计算结果进行输出,那么负责输出结果的算子称为Sink。
1.sink_to
上面1.16版本kafka输入数据,下面新版本的输出,同样都是有问题的,还是建议用旧版把。有新的研究会补充上。
from pyflink.common import SimpleStringSchema, WatermarkStrategy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import DeliveryGuarantee
from pyflink.datastream.connectors.kafka import KafkaSource, KafkaOffsetsInitializer, KafkaSink, \
KafkaRecordSerializationSchema
sink = KafkaSink.builder() \
.set_bootstrap_servers('localhost:9092') \
.set_record_serializer(
KafkaRecordSerializationSchema.builder()
.set_topic('test_sink_topic')
.set_value_serialization_schema(SimpleStringSchema())
.build()
) \
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE) \
.build()
ds.sink_to(sink)2.add_sink
也可以输出到jdbc中
jdbc_options = JdbcConnectionOptions.JdbcConnectionOptionsBuilder() \
.with_user_name("xxxxxx") \
.with_password("xxxxxx") \
.with_driver_name("com.mysql.cj.jdbc.Driver") \
.with_url("jdbc:mysql://localhost:3306/test_db") \
.build()
ds.add_sink(JdbcSink.sink("insert test_table(id, message) VALUES(null, ?)",
type_info=Types.ROW([Types.STRING()]),
jdbc_connection_options=jdbc_options))