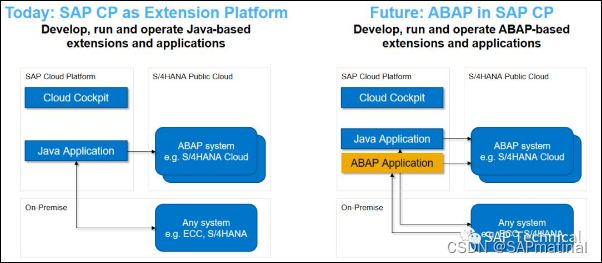
Pytorch深度学习入门与实战
- Pytorch简介
- Pytorch特点
- PyTorch安装环境要求
- PyTorch兼容的Python版本
- 搭建开发环境
- 下载Miniconda
PyTorch是一个灵活容易学习python库,在学术和研究领域PyTorch是最受欢迎的深度学习库。
PyTorch是Tensorflow最强有力的竞争对手。
PyTorch框架的产生受到Torch和Chainer这两个框架的启发。
与Torch使用Lua语言相比,PyTOrch是一个python优先的框架,我们可以继承PyTorch类然后自定义。
与Chainer类型,PyTorch框架具有自动求导的动态图功能,也就是所谓define by run,即当python解释器运行到相应的行时,才创建计算图。
Pytorch特点
- 易于使用的API——它就像python一样简单。
- python的支持——PyTorch可以顺利地与python数据科学集成。它非常类似于Numpy.
- 动态计算图——取代了具有特定优势的静态图,pytorch为我们提供了一个框架,以便可以在运行时构建计算图,甚至在运行时更改它们。
- 部署简单——pytorch提供了可用于大规模部署Pytorch模型的工具torchserve.TorchServe是pytorch开源项目的一部分,是一个易于使用的工具,用于大规模部署Pytorch模型。
- 支持分布式训练——pytorch可实现研究和生产中的分布式训练和性能优化。
- 支持移动端——Pytorch支持从python到IOS和安卓系统部署的端到端工作流程。
- 强大的生态系统——pytorch具有丰富的工具和库等生态系统,为计算机视觉、NLP等方面的开发提供便利。
- 内置开放神经网络交换协议(ONNX)——可以很方便与其他深度学习框架互操作。
PyTorch安装环境要求

PyTorch兼容的Python版本
windows上的Pytorch仅支持python 3.7-3.9,不支持python 2.x
搭建开发环境
推荐使用Miniconda搭建python环境
Miniconda是最小的conda安装环境,它提供了:
1.Conda包管理工具
2.python
下载Miniconda
CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
为了使用CUDA,需要安装cudatolkit,在这里我们与pytorch一并都使用conda安装。
检查显卡驱动

GPU版本安装
这样网站会给出我们具体的安装命令,我们在anaconda prompt(miniconda3)命令行中参考网站给出的安装命令执行安装即可。
依赖库安装

机器学习基础与PyTorch实现简单线性回归
机器学习基础
什么是机器学习呢?所谓机器学习,就是让计算机从数据中学习到规律,从而做出预测。很多时候,我们很难直接编写一个算法解决问题,比如一张图片,很难编写算法直接正确预测这张图片是猫还是狗。
为了解决这个问题,人们想到数据驱动方法,也就是让计算机从现有的大量的带标签图片中学习规律,一旦计算机学习到了其中的规律,当我们输入一张新的图片给计算机时,它就可以准确的预测出这张图片到底是猫还是狗。
这里有两个关键的因素,
一是大量的可学习数据,比如带标签的猫狗图片;
二是学习的主体,我们一般称之为模型。
如何理解模型呢?
你可以把模型认为是一个映射函数,它包含一些参数,这些参数可以与输入进行计算得到一个输出,我们一般称之为预测结果。
所谓模型学习的过程,就是模型修正其参数、改进映射关系的过程。
可以简单的把模型的学习过程总结如下,以预测图片是猫还是狗为例:
1.创建模型;
2.输入一张带标签的图片;
3.使用模型对此图片做出预测;
4.将预测结果与实际标签比较,产生的差距为损失;
5.以减小损失为优化目标,根绝损失优化模型参数;
6.循环重复上述第2-5步。
损失函数
损失函数:使用均方误差作为成本函数,也就是预测值和真实值之间差的平方取均值。
成本函数与损失函数:优化的目标(y代表实际的收入):找到合适的W和b,使得(f(x)-y)的平方越小越好,也就是求解合适的参数w和b.`
模型的创建如下所示:
class EIModel(nn.Module):定义类继承自nn.Module
def __init__(self):
super(EIModel, self).__init__()
self.linear = nn.Linear(in_features=1, out_features=1)
def forward(self, inputs):
logits = self.linear(inputs)
return logits
model = EIModel()模型实例化
opt = torch.optim.SGD(model.parameters(), lr=0.0001)优化器
for epoch in range(5000):训练5000次
for x, y in zip(X, Y):
y_pred = model(x)
loss = loss_fn(y_pred, y)计算损失
opt.zero_grad()梯度清零
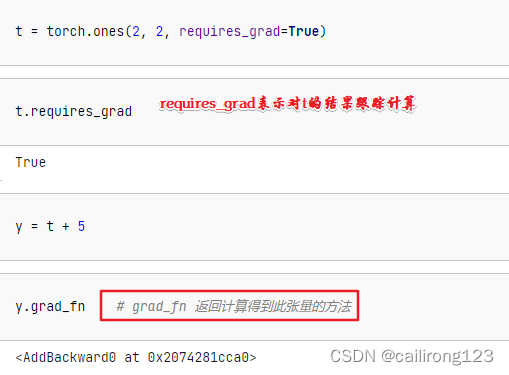
loss.backward()损失反向传播
opt.step()优化参数
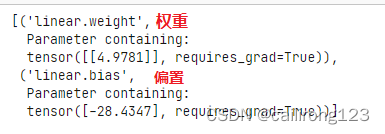
list(model.parameters())返回优化后的模型参数
list(model.named_parameters())
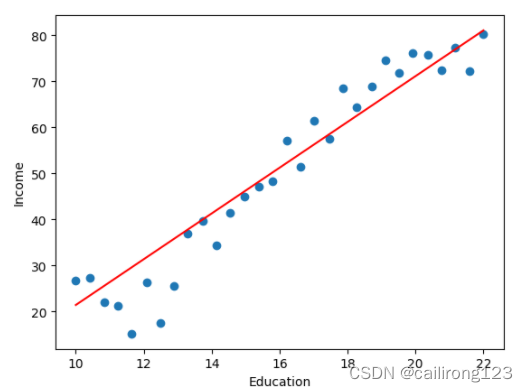
plt.scatter(data.Education, data.Income)绘制优化后的模型参数
plt.xlabel('Education')
plt.ylabel('Income')
plt.plot(X, model(X).detach().numpy(), c='r')
*** 创建模型的总结:
1.输入数据处理
2.创建模型
3.训练
4.预测、评价
张量与基本数据类型
Tensor(张量)
Pytorch最基本的操作对象是Tensor(张量),它表示一个多维矩阵张量类似于NumPy的ndarrays,张量可以在GPU上使用以加速计算。
张量是基于向量和矩阵的推广,我们可以将标量视为零阶张量,向量视为一节张量,矩阵就是二阶张量。
张量是支持高效的科学计算的数组,它可以是一个数(标量)、一维数组(向量)、二维数组(矩阵)和更高维的数组(高阶数据)。
张量(tensor)和NumPy的数组ndarray通常可以共享相同的底层内存,无需复制数据。
import torch
import numpy as np
t = torch.FloatTensor([1, 2, 3])创建float32类型的数据
t = torch.LongTensor([1, 2])创建int64位类型的数据
Tensor的最基本数据类型

torch.rand(2,3) 在0和1之间随机分布的随机数,创建一个两行三列的tensor数据
t = torch.randn(2, 3) 随机创建一个2*3的正态分布
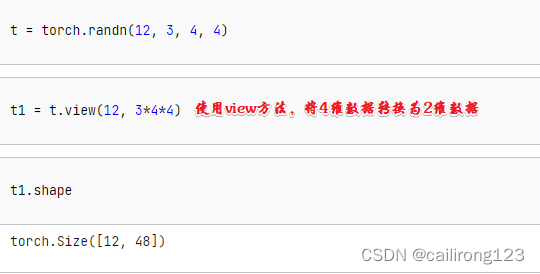
shape返回tensor的形状 dtype返回tensor的类型
t.add_(t1) 代表t+t1的运算结果返回给t,就地改变t的值
torch.abs(t)代表求t的绝对值
t.T # 转置 shape : (3, 2) 大写的T代表转置,表示将23的矩阵t,转换为32的矩阵T
matmul 矩阵乘法
t.matmul(t.T) 表示一个23的矩阵t,与一个32的矩阵T,进行矩阵乘法运算。
t@(t.T)等同于t.matmul(t.T)
t.sum().item()将tensor的数据类型转换为python的浮点型数据进行打印
t1 = torch.from_numpy(np.random.randn(3, 4)) 表示将numpy类型的数据,转换为array类型
t1.numpy() 表示将array类型的数据转换为numpy类型