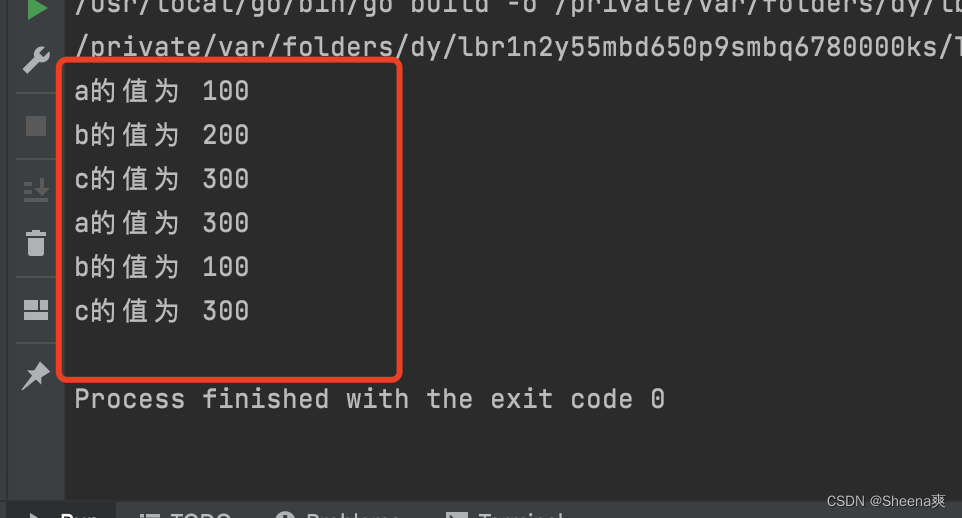
进行数据的初始整理的准备
主要是进行伪序列字典的设置,以及训练数据集的准备。
期间需要的一些问题包括在读取文件信息的时候,需要跳过文件的第一行或者前两行,如果使用循环判断的话,会多进行n次的运算,这是不划算的,所以学到了两个方法分别应用到两个文件读取中。
f=open(r'C:\\Users\\Dell\\Desktop\\deephlapan-master\\deephlapan\\model\\MHC_pseudo.dat',encoding='utf-8')
pesudo_list = {}
# 跳过第一行
lines = f.readlines()[1:]
for line in lines:
s = line.strip().split('\t')
pesudo_list[s[0]]=s[1]
f.close()
# print(pesudo_list)
import csv
import pandas as pd
aa_idx = {'A':1, 'C':2, 'D':3, 'E':4, 'F':5, 'G':6, 'H':7, 'I':8, 'K':9, 'L':10, 'M':11, 'N':12, 'P':13,
'Q':14, 'R':15, 'S':16, 'T':17, 'V':18, 'W':19, 'Y':20, 'X':21}
# 跳过前两行
df = pd.read_excel(r"C:\\Users\\Dell\\Desktop\\sup_data\\train_data.xlsx",
skiprows=2, names=["HLA","Peptide","Label"])
input=[]
for i in range(len(df)):
shuru=pesudo_list[df['HLA'][i]]+df['Peptide'][i]
for j in range(49-len(shuru)):
shuru+='X'
input.append(shuru)
print(input)
进行one-hot编码
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
之所以使用One-Hot编码,是因为在很多机器学习任务中,特征并不总是连续值,也有可能是离散值(如上表中的数据)。将这些数据用数字来表示,执行的效率会高很多。
这个过程的目的是增加输入序列的信息量。
完成编码后的代码:
f=open(r'C:\\Users\\Dell\\Desktop\\deephlapan-master\\deephlapan\\model\\MHC_pseudo.dat',encoding='utf-8')
pesudo_list = {}
lines = f.readlines()[1:]
for line in lines:
s = line.strip().split('\t')
pesudo_list[s[0]]=s[1]
f.close()
# print(pesudo_list)
import csv
import pandas as pd
aa_idx = {'A':1, 'C':2, 'D':3, 'E':4, 'F':5, 'G':6, 'H':7, 'I':8, 'K':9, 'L':10, 'M':11, 'N':12, 'P':13,
'Q':14, 'R':15, 'S':16, 'T':17, 'V':18, 'W':19, 'Y':20, 'X':21}
df = pd.read_excel("C:\\Users\\Dell\\Desktop\\sup_data\\train_data1.xlsx",
skiprows=2, names=["HLA","Peptide","Label"])
inputs=[]
input_code=[]
for i in range(len(df)):
shuru=pesudo_list[df['HLA'][i]]+df['Peptide'][i]
for j in range(49-len(shuru)):
shuru+='X'
inputs.append(shuru)
onehot=[]
for char in shuru:
onehot.append(aa_idx[char])
print(onehot)
onehot_encoded = list()
for value in onehot:
letter = [0 for _ in range(len(aa_idx))]
letter[value-1] = 1
onehot_encoded.append(letter)
print(onehot_encoded)
# input_code.append(aa_idx[char] for char in shuru)
print(input_code)
进行one-hot编码的结果类似如下(49*21):
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]]
完成数据的准备了,开始着手设计训练模型
因为这是我第一次训练模型,所以会遇到很多问题,我并不觉得稀奇,也早做好了心理准备。遇到的问题很多,因为是解决后的回顾整理,所以会在介绍的时候简略一些:
问题1:model.add的时候,先添加了embedding层,但是被系统提示为no name。
解决:将embedding改为layers.embedding,这个问题在之后GRU层也出现过。
问题2:embedding层的参数选择和设置
解决:这里本质上其实是对于one-hot和embedding两个方式的不理解,如果以我上面提到的那种one-hot之后的数据作为输入的话,其实是不行的,因为embedding的输入格式有要求,所以我之前是把二维数据flatten成一维输入的,然而事实上,是我搞错了one-hot+embedding这个方式的理解,其实这个组合的意思是one-hot只要编码,不用转01二进制,由embedding来做这个工作,参数则是编码最大值+1.
问题3:堆叠循环层失败
解决:事实上,我一开始就是add(GRU)连着两行(不是只有这个,就是那两行是这个意思),这样的肯定是不行的,因为循环层的输出有两种格式,如果徐亚堆叠,就需要所有中间层都是返回完整的输出序列(3D张量),而不是只返回最后一个时间步的输出。
中间乱七八糟的报错还有好一些,不过作为回顾的话,没有太大的总结必要。
最后甭管咋样,反正是能训练了。
考虑到本地电脑的运算性能,在数据的选取上比较保守,以熟悉训练流程作为主要的目的,接下来就是挪到服务器上,上数据看看具体效果了。