一、Go语言特性
- 语法简单
- 并发性。Go语言引入了协程goroutine,实现了并发编程
- 内存分配。Go语言为了解决高并发下内存的分配和管理,选择了tcmalloc进行内存分配(为了并发设计的高性能内存分配组件,使用cache为当前线程提供无锁分配,多个central在不同线程间平衡内存单元复用。在更高层次,heap管理大块的内存分配,用以切片成不同等级的复用内存块。快速分配和二级平衡机制,可以更高性能的进行内存分配)
- 垃圾回收。在Go中指针的运算被阻止,故垃圾回收会容易点
- 静态链接。Go的便衣只需要编译后的一个可执行文件(将运行时依赖的库直接打包到可执行文件内部),无需附加任何东西,就能部署
- 标准库。Go的标准库比较丰富
- 工具链。无论是编译、格式化、错误检查、帮助文档还是第三方包下载更新都能有对应的工具
二、Go的变量
1.变量的声明
- Go是静态语言,因此其变量必须要有明确的类型,这样编译器才能检查变量正确性
- 声明变量语法:
var 变量名 变量类型
//举例:声明两个变量都为int指针类型
var a, b *int
(1) 变量的声明
- 当一个变量被声明后,系统会自动初始化一个值。int类型初始值为0,float类型初始值为0.0,bool类型初始值为false,string类型初始值为空字符串,切片、函数、指针类型初始值为nil
- 变量命名遵循驼峰命名法,即首个单词小写,每个新单词首字母大写。如GoStudy
- 批量声明变量的格式:
//方式一:使用关键字var和花括号{},可以将一组变量定义放在一起
var{
a int
b string
c byte
d []float32
e func()bool
f struct{
x int
}
}
//方式二:把变量定义和初始化放在一起:名字 := 表达式。
//但这种方式有以下限制:1.不能提供数据类型;2.只能用在函数内部
func main(){
x := 10
a, s := 1, "abc"
}
2.变量的初始化
- 当一个变量被声明后,系统会自动初始化一个值。int类型初始值为0,float类型初始值为0.0,bool类型初始值为false,string类型初始值为空字符串,切片、函数、指针类型初始值为nil
(1) 变量初始化语法
//方式一:var 变量名 类型 = 表达式
var a int = 10
//方式二:省略其类型,采用编译器推导类型的格式L:var 变量名 = 表达式
var a = 10
//方式三:更精简的写法,省略关键字var: 变量名 := 表达式
a := 10
//注意:
1.由于使用了:=,而不是=,因此方式三的写法的左边变量名必须是没有定义过的变量,若该变量定义过,则编译器会报错
2.在多个短变量声明和复制中,至少又一个新声明的变量出现在左值中,即使其他变量名可能是重复声明的,编译也不会出错,如下所示:
res1, err := MyTest(2)
res2, err := MyTest(3)
(2) 多重赋值
- Go语言的多重赋值,用于变量值的互换
/*
var a int = 100
var b int = 200
a, b = b, a
*/
package main
import "fmt"
func main(){
var a int = 100
b := 200
fmt.Println("a = ", a," b = ", b)
b, a = a, b
fmt.Println("a = ", a," b = ", b)
}
结果:

3.匿名变量
- Go语言中支持没有名称的变量、类型或者方法,这些统称为匿名变量,匿名变量是为了增强代码的灵活性
- 匿名变量是一个下划线"_"(被称为空白标识符),_可以像其他标识符一样用于变量的声明或者赋值(任何类型都可以赋值给它),但一旦赋值给这个标识符的值都会被抛弃,因此这些值无法在后续代码中使用
- 匿名变量,没有内存空间,不会给它分配内存
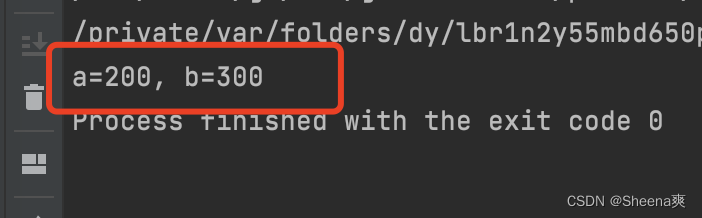
package main
import "fmt"
func GetTheData()(int, int){
a := 200
b := 300
return a, b
}
func main(){
a, _ := GetTheData()
_, b := GetTheData()
fmt.Printf("a=%d, b=%d",a, b)
}
结果:
4.变量作用域
- 局部变量:函数内定义的变量,作用域是函数体内,函数调用结束后,变量会被销毁。形参的作用域跟局部变量一样。
- 全局变量:函数外定义的变量,全局变量的声明必须用关键字var。若全局变量和局部变量同名,在函数内以局部变量为准。
三、Go的常量和const
- 和C++一样,Go中是用const关键字来定义常量,常量是在编译时创建的,值在创建后就不会改变
//常量的声明
const a = 3.1415926
//常量的批量声明
const{
b = 2.12345
c = 1.23455
}
1.无类型常量
- Go语言中有个与其他语言不一样的地方,虽然一个常量可以是任意一个明确的基础类型的值,例如,可以是int类型的值或者string类型的值;但许多常量没有一个明确的基础类型
//math.Pi可无类型的浮点数常量,可直接用于任意需要浮点或者复数的地方
var x float32 = math.Pi
var y complex128 = math.Pi
var z float64 = math.Pi
- 若math.Pi已经被确定为特定类型之后,那么结果的精度可能不一样。若需要一个精确的值,则需要进行显式类型转换
const Pi float64 = math.Pi
var x float32 = Pi //x的精度就会改变
var y float32 = (float32)Pi //y进行了类型转换,精度不会变
var z complex128 = (complex128)Pi //z进行了类型转换,精度不会变
四、Go的数据类型
1.Go的基本数据类型
| 类型名 | 含义 |
|---|---|
| bool | 布尔型,true、false |
| string | 字符串类型 |
| int、int8、int32、int64 | 有符号整型 |
| uint、uint8、uint16、uint32、uint64、uintptr | 无符号整型 |
| byte | 字符类型 |
| rune | 字符类型 |
| float32、float64 | 浮点型 |
| complex64、complex128 | 复数类型 |
2.整型
(1) 有符号整型
- int8表示8位有符号整型,范围是-128~127
- int16表示16位有符号整型,范围是-32768~32767
- int32表示32位有符号整型,范围是-2147483648~2147483647
- int64表示64位有符号整型,范围是-9223372036854775808~9223372036854775807
- int根据编译器和计算机硬件的不同数值大小不同,在32位机器中为32位=4字节,在64位机器中位64位=8字节
(2) 无符号整型
- uint8表示无符号8位,范围是0~255
- uint16表示无符号16位,范围是0-65535
- uint32表示无符号32位,范围是0~4294967295
- uint64表示无符号64位,范围是0~18446744073709551615
- uint:根据不同的底层平台,32 位系统是32位,64 位系统是64位
3.浮点型
- float32:32位浮点型
- float64:64位浮点型
4.布尔类型
- 布尔类型的值只有两种:true或false,默认是false
- 布尔类型无法参与数值运算,也无法与其他类型进行转换
5.复数类型
- 复数是有两个浮点数组成,一个是实部,一个是虚部。
- 复数的类型有两种:complex128(64位实数和虚数)和complex64(32位实数和虚数),复数的默认类型是complex128
- 复数也可以用 == 和 != 进行相等比较,只有两个复数的虚部和实部都相等时,它们才相等
- 复数的声明方式:
//var name complex128 = complex(x,y)
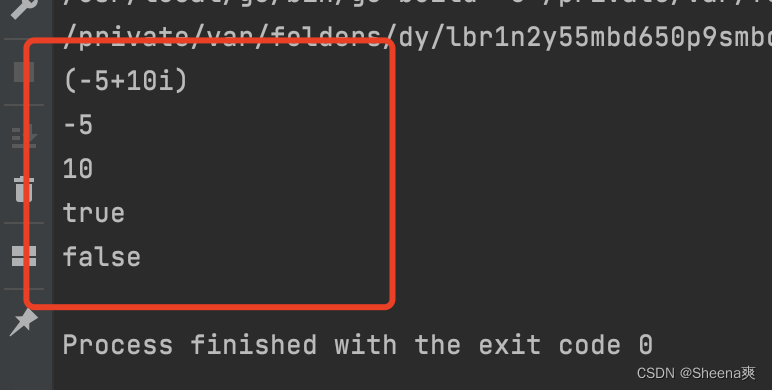
package main
import "fmt"
func main(){
var x complex128 = complex(1,2) //1 + 2i
var y complex128 = complex(3,4) //3 + 4i
fmt.Println(x * y)
fmt.Println(real(x * y))
fmt.Println(imag(x * y))
var z complex128 = complex(-5,10)
var w complex128 = complex(5,10)
fmt.Println(x * y == z)
fmt.Println(x * y == w)
}
结果:
6.字符类型
- Go语言中字符类型有以下两种:
(1)一种是uint8类型即byte类型,代表一个ASCII码字符
(2)另一种是rune类型,代表一个UTF-8字符,当需要处理中文、日文或其他字符时,则需要用到rune类型。等价于int32类型 - byte类型时uint8的别名,使用举例:var ch byte = ‘A’
- 在ASCII码中,A的值时65,使用16进制表示为41,故下面写法是等效的:var ch byte = 65 或 var ch byte = ‘\x41’
- Go语言支持UTF-8即Unicode字符,该字符称为Unicode代码点或者runes,并在内存中用int来表示,一般使用格式U+hhhhh,其中h表示一个16进制数
- 在书写Unicode字符时,需要在16进制数前加上\u或者\U。若需要使用到4字节,则使用\u前缀;若需要使用到8字节,则使用\U前缀。
package main
import "fmt"
func main(){
var ch int = '\u0041'
var ch2 byte = 'A'
var ch3 int = '\U00000061'
fmt.Println(ch, ch2, ch3)
fmt.Printf("ch=%c, ch2=%c, ch3=%c", ch,ch2,ch3)
}
结果:

- Unicode包中内置了一些用于测试字符的函数,这些函数的返回值都是一个布尔值,如下:
(1)判断是否是字母:unicode.IsLetter(ch)
(2)判读是否是数字:unicode.IsDigit(ch)
(3)判断是否为空白字符:unicode.IsSpace(ch)
package main
import (
"fmt"
"unicode"
)
func main(){
var ch rune = 'A'
var gi rune = '1'
var sp rune = ' '
fmt.Println(unicode.IsLetter(ch))
fmt.Println(unicode.IsLetter(gi))
fmt.Println(unicode.IsDigit(ch))
fmt.Println(unicode.IsDigit(gi))
fmt.Println(unicode.IsSpace(sp))
}
结果:

7.字符串类型
- Go语言中字符串的内部实现使用UTF-8编码,通过rune类型,可以方便地对每个UTF-8字符进行访问。Go也支持按照传统地ASCII码地方式逐字符进行访问
- 可以用反引号’'来定义多行字符串
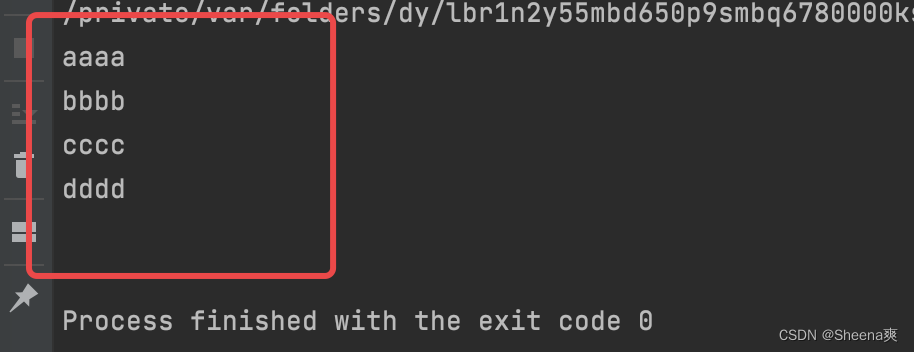
package main
import (
"fmt"
)
func main(){
const str = `aaaa
bbbb
cccc
dddd
`
fmt.Println(str)
}
结果:
8.数据类型转换
- Go语言不存在隐式类型转换,因此类型转换必须要显式的声明:valueOfTypeB = typeB(valueOfTypeA)
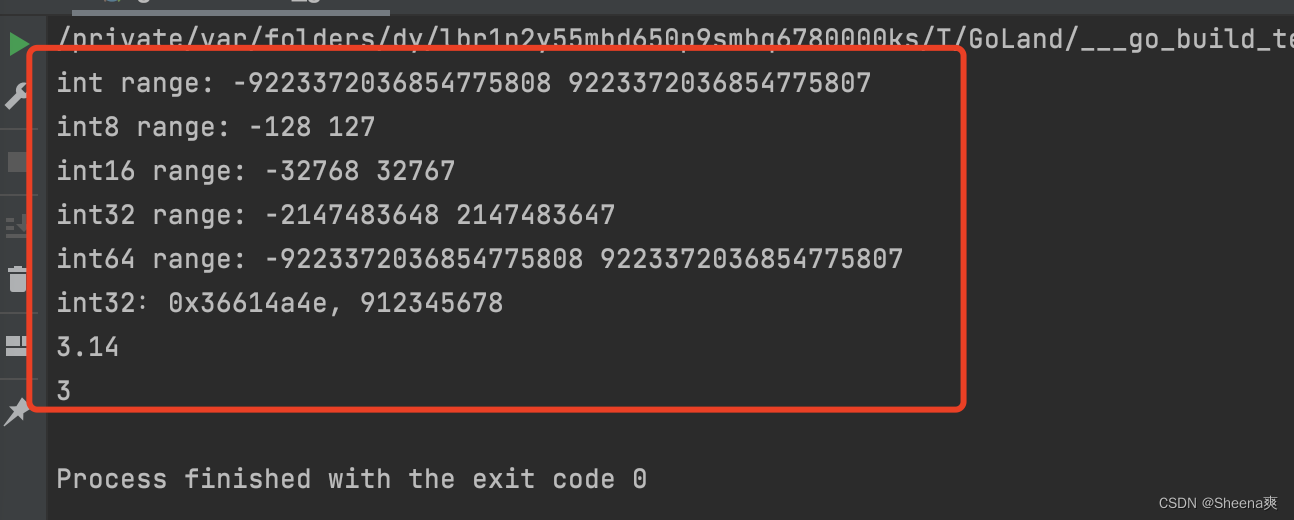
package main
import (
"fmt"
"math"
)
func main(){
fmt.Println("int range:", math.MinInt, math.MaxInt)
fmt.Println("int8 range:", math.MinInt8, math.MaxInt8)
fmt.Println("int16 range:", math.MinInt16, math.MaxInt16)
fmt.Println("int32 range:", math.MinInt32, math.MaxInt32)
fmt.Println("int64 range:", math.MinInt64, math.MaxInt64)
var a int32 = 912345678
//将a转换为十六进制,会发生数值截断
fmt.Printf("int32:0x%x, %d\n", a,a)
var pi float32 = 3.14
fmt.Println(pi)
fmt.Println(int(pi))
}
结果:
9.指针
- 指针在Go语言中可被拆分成两个核心概念:
(1)类型指针,允许对这个指针类型的数据进行修改,传递数据可以使用指针,而不需要进行数据之间的拷贝。类型指针不能进行偏移和运算。
(2)切片,由指向起始元素的原始指针、元素数量和容量组成 - 指针相关的概念:指针地址、指针类型、指针取值
(1) 指针地址和指针类型
- 指针就是存放变量的地址,一个指针变量可以指向任何一个值的内存地址。按照编译器的不同在32bit和64bit机器上,指针大小不一样,在32位机器上指针的大小为4字节,在64位机器上指针的大小为8字节。默认值为nil。缩写为ptr。
- 每个变量都有一个地址,跟c++一样,&为取地址操作符,若想获取这个变量的地址,用&即可。*为解引用操作符,可以获取到指针所指向的地址中存的值。
- 指针的类型为T
package main
import "fmt"
func main(){
a := 100
b := 'a'
c := "hello world"
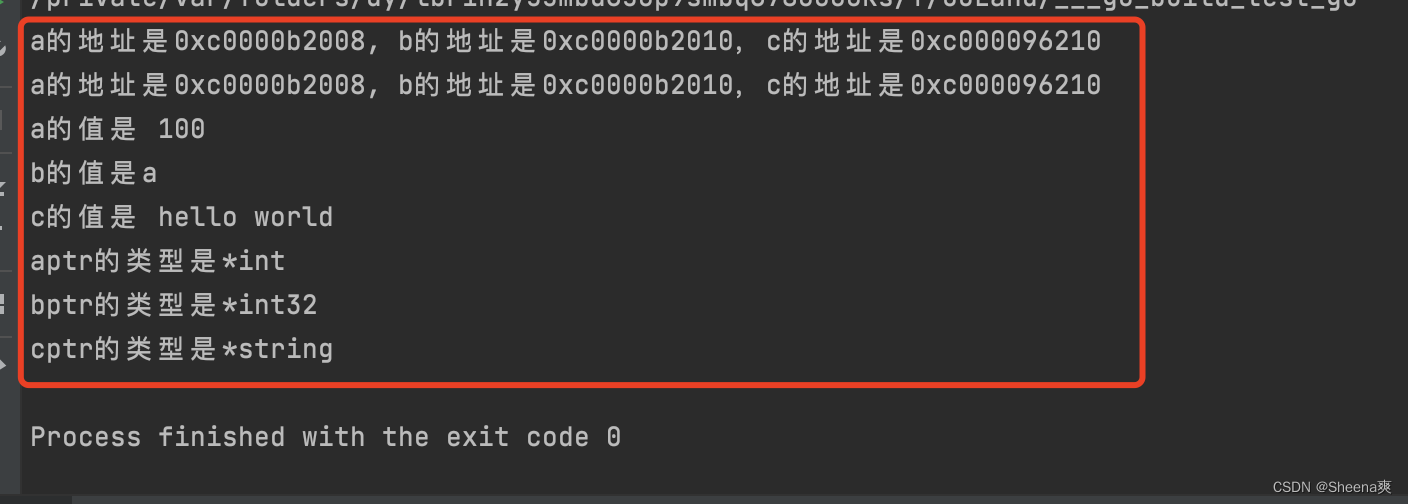
fmt.Printf("a的地址是%p, b的地址是%p,c的地址是%p\n", &a, &b, &c)
aptr := &a
bptr := &b
cptr := &c
fmt.Printf("a的地址是%p, b的地址是%p,c的地址是%p\n", aptr, bptr, cptr)
fmt.Println("a的值是", *aptr)
fmt.Printf("b的值是%c\n", *bptr)
fmt.Println("c的值是", *cptr)
//指针的类型
fmt.Printf("aptr的类型是%T\n", aptr)
fmt.Printf("bptr的类型是%T\n", bptr)
fmt.Printf("cptr的类型是%T\n", cptr)
}
结果:
- 创建指针的另一种方法:new()函数,new(类型)
package main
import "fmt"
func main(){
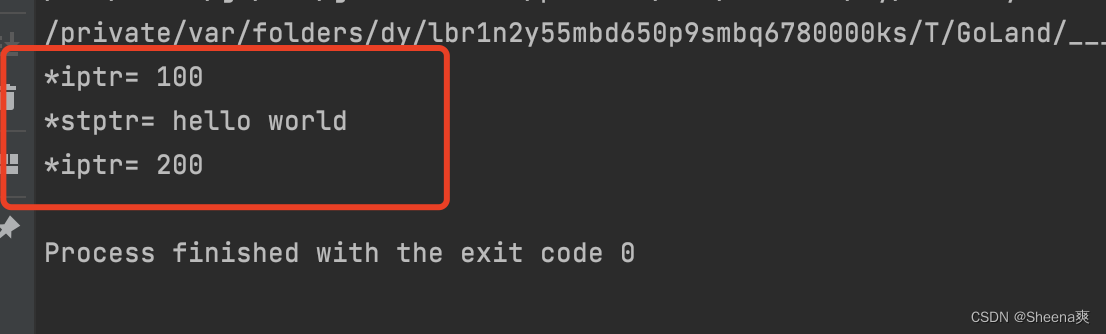
iptr := new(int)
stptr := new(string)
*iptr = 100
*stptr = "hello world"
fmt.Println("*iptr=",*iptr)
fmt.Println("*stptr=",*stptr)
a := 200
*iptr = a
fmt.Println("*iptr=",*iptr)
}
结果:
10.类型别名type关键字
(1) 类型别名
- Go中的类型别名的出现主要是为了解决代码升级时,迁移中存在的类型兼容性问题。在C++中,代码重构升级可以用宏快速定义一段新的代码,而Go语言中没有宏的概念。
- 写法:type int = rune
- 类型别名与类型定义表面上看只有一个等号的差异,实际区别如下:
package main
import "fmt"
type NewInt int //类型定义
type IntNew = int //类型别名
func main(){
var a NewInt //使用类型定义,定义的新类型
fmt.Printf("a的类型为:%T\n",a)
var b IntNew //使用类型别名,定义的新类型
fmt.Printf("b的类型为:%T\n",b)
}
结果:
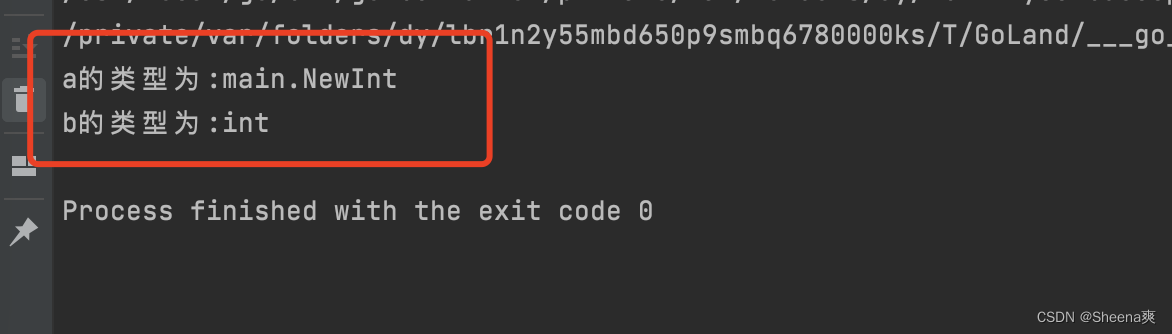
上述结果不难发现,a的类型是main.NewInt,即main包下定义的NewInt类型;b的类型还是int类型。而IntNew该类型只会在代码中存在,编译完成后就不会存在。
(2) 类型别名和类型定义的区别
- 类型定义:
(1)一个新定义的类型与源类型是两个不同的类型
(2)一个新定义的类型与源类型底层的类型是一样的,但是不能进行直接的赋值,可以进行显式的类型转换
(3)类型定义可以出现在函数体里
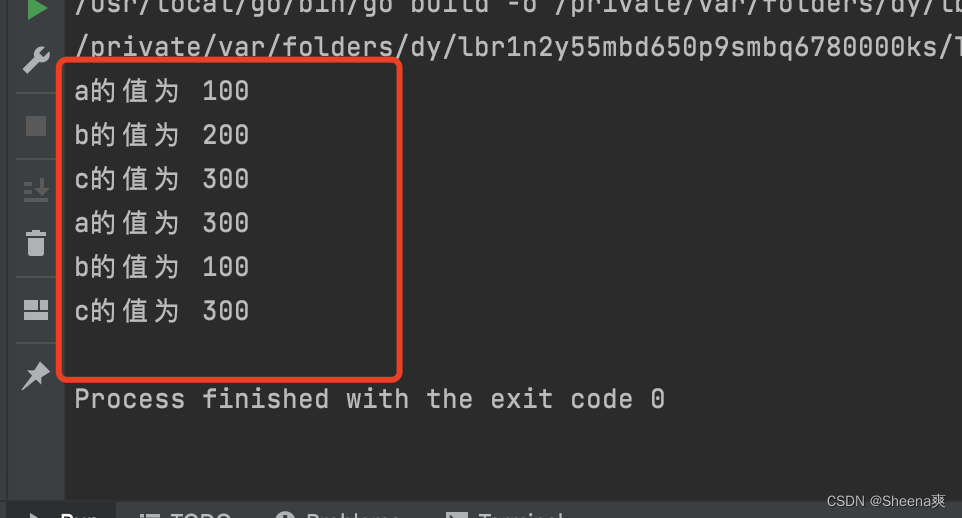
package main
import "fmt"
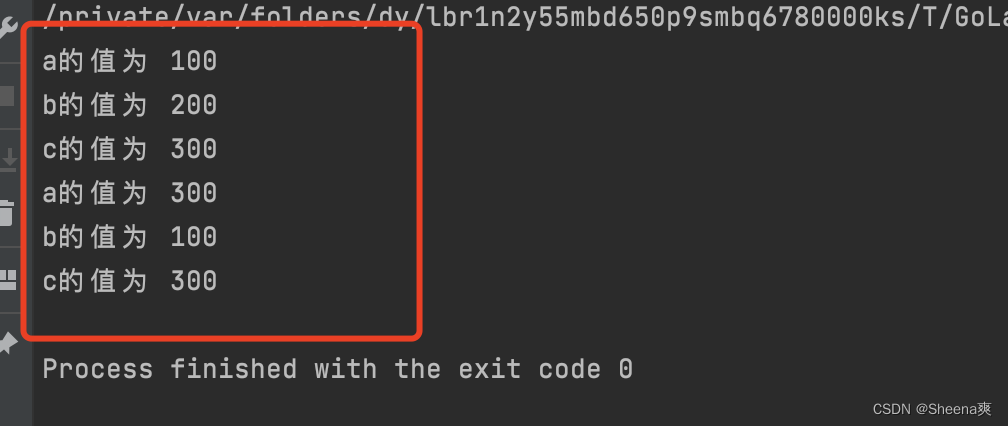
func main(){
type NewInt int //类型定义
var a NewInt = 100 //使用类型定义,定义的新类型
var b int = 200
var c int = 300
fmt.Println("a的值为", a)
fmt.Println("b的值为", b)
fmt.Println("c的值为", c)
b = int(a)
a = NewInt(c)
fmt.Println("a的值为", a)
fmt.Println("b的值为", b)
fmt.Println("c的值为", c)
}
结果:
- 类型别名:
(1)类型别名与源类型是同一种类型
(2)类型别名与源类型之间可以进行直接的赋值
package main
import "fmt"
func main(){
type IntNew = int //类型别名
var a IntNew = 100 //使用类型别名,定义的新类型
var b int = 200
var c int = 300
fmt.Println("a的值为", a)
fmt.Println("b的值为", b)
fmt.Println("c的值为", c)
b = a //类型别名与源类型就是同一类型,故可以直接相互赋值
a = c
fmt.Println("a的值为", a)
fmt.Println("b的值为", b)
fmt.Println("c的值为", c)
}
结果:











![[ 常用工具篇 ] windows安装phpStudy_v8.1_X64](https://img-blog.csdnimg.cn/51f6e599fca644e5a0b4ab0fbe4dcb47.png)

