NeurIPS2022——Masked Autoencoders As Spatiotemporal Learners
Keywords: Videos;object detection;
文章目录
- NeurIPS2022——Masked Autoencoders As Spatiotemporal Learners
- 研究动机
- 本文贡献
- Introduction & Related work
- 整体架构:
- Experiment Data pre-processing
- 可视化及结果:
- Conclusion
- Related
研究动机
深度学习趋向于使用统一方法解决不同领域问题,Bert在nlp,MAE在图像上取得了不错成果,因此作者将MAE扩展到video上做spatiotemporal表征
kaiming组,和上一个videoMAE类似,区别在于本文的spacetime-agnostic masking是时空随机的,而不是上文的tube-masking并消融证明时空随机更优。编码器解码器的结构也和videomae一致。
本文贡献
- 消融证明spacetime-agnostic masking更优
- 尽量少的领域知识或者归纳偏见就能学到强的representation —— transformer、vit
- mask ratio 是一个重要的超参数,并且不同数据种类有很大不同
Introduction & Related work
深度学习趋向使用统一的方法解决不同领域问题(语言、视频、声音),可促使模型几乎完全从数据中学习有用的知识
- transformer:图像和语言领域都取得不错成果。
- SSL:BERT中的denoising/masked autoencoding methodology被证明是有效的
- 引入更少的领域知识(归纳偏见),促使模型纯粹地从数据中学习有用的知识
Denosing autoencoder:DAE
从损坏的输入中重建干净的信号。提出学习表示的通用方法。
-
NLP: BERT是其很成功的发展
-
CV:迁移了很多NLP的方法。特别是transformer
-
iGPT: pixel as a token
ViT: patch as a token
重建:
-
MAE: pixel
-
BEiT: token(dVAE tokenizer )
(dVAE 可以通过perceptual or adversarial losses 来提升)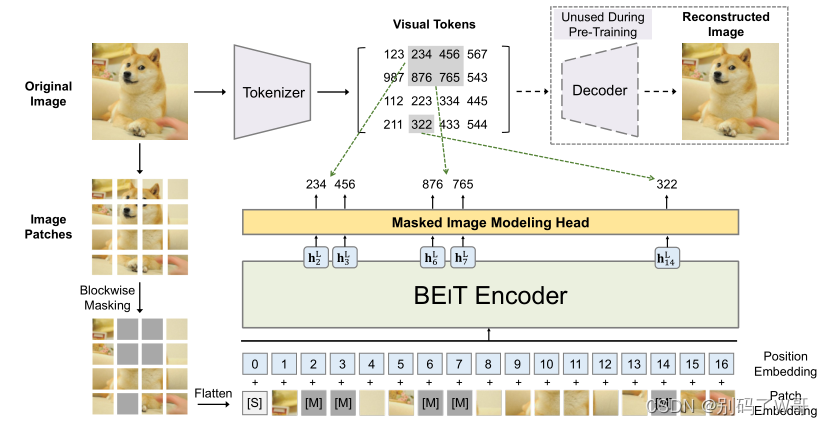
-
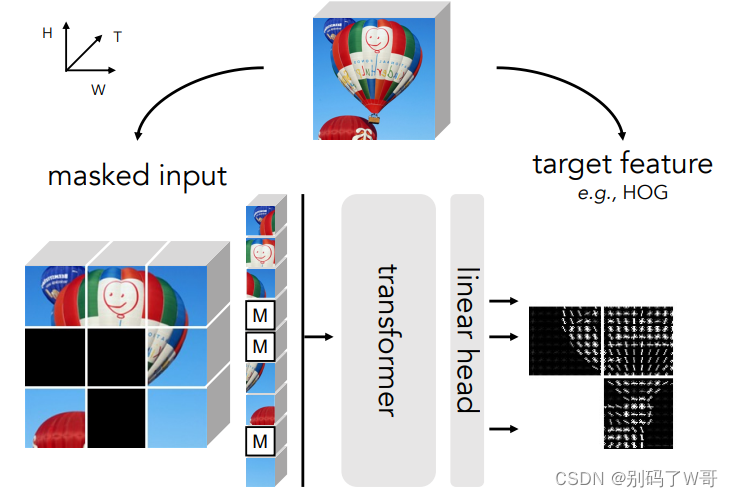
MaskFeat :HoG作为预测目标是很有效的。
如何评价FAIR提出的MaskFeat:一种适用图像和视频分类的自监督学习方法?
SSL on Video:
时间维度是视频数据自监督学习的重点:
相关主题包括时间相干性(‘slowness’)[79, 25],未来预测 [61, 72, 70, 45, 44, 71, 16],对象运动 [1, 75, 49, 76],时间排序 [46 , 23, 38, 78, 81],时空对比 [58, 62, 30, 22, 51, 56] 等。
但是, 本文使用的方法在很大程度上和时空无关(前面强调好多遍了)
视频数据使用掩码方法,之前也有人在做 [65, 73, 77]。
但是, 本文更简单(重建像素)、更少的领域知识。而且本文更省计算。
整体架构:
随机mask视频中的时空patch,并学习自动编码器来重建它们
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ESY4iSdn-1678156935694)(C:%5CUsers%5C%E7%8E%8B%E4%B8%80%E4%BA%8C%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20230306160402774.png)]](https://img-blog.csdnimg.cn/75baffa7ff7844688ff233e57beb60fa.png)
Patch embedding
原始ViT给一段video clip,在时空维度上分割为不重叠的patch并拉平经过linear projection,再加入position embedding。此处强调,patch和pos embeding是唯一具有时空相关性的过程(只需要很少的归纳偏置)。
Masking
本文使用图a策略,采用随机的spacetime-agnostic sampling,相比其他方式将更为高效,并且90%最佳
b:tube masking——只是空间随机,传播到全部时间上
c:frame masking——只是时间随机,传播到所有空间位置
d:cube masking——在时空中基于块的采样,去除较大区域
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8lGNNFo7-1678156935696)(C:%5CUsers%5C%E7%8E%8B%E4%B8%80%E4%BA%8C%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20230307092627391.png)]](https://img-blog.csdnimg.cn/6bb2603fb9124bfea30010da1bed1959.png)
Autoencoding
- Encoder:vaniila ViT;
- Decoder:更小的vaniila ViT,因为decoder需要处理的token的复杂度小于encode(约1/20)
- Patch prediction:原则上可以简单地预测一个完整的时空patch(t×16×16),但在实践中发现预测patch的单个时间片(16×16)就足够了,这使预测层的大小保持可控;
- Training loss:MSE,在unknown patches上取平均值。
Experiment Data pre-processing
默认16 frames,224 * 224: 起始帧随机抽,然后时间维度上步长4抽取16帧。
空间维度:random crop 和 random horizontal flipping。
patch 切分:
使用 temporal patch size : 2,spatial patch size : 16 * 16—— 2 * 16 * 16
对于 input :16 * 224 * 224,将会产生的patch数目是:8 * 14 * 14个tokens
pos embedding:
Encoder——separable positional embeddings
我们有两个位置嵌入,一个用于空间,另一个用于时间,时空位置嵌入是它们的和。这种可分离的实现可以防止位置嵌入在3D中变得太大。
我们使用 learnable positional embeddings ;sin-cos变量[67]的工作原理类似。
setting:
batchsize:512
optim:AdamW
可视化及结果:
masking ratio = 90% 第一行为原视频,中间为masked video,下一层为MAE output
The video size 为16×224×224,the spacetime patch size 为2×16×16
Each sample has 8×14×14=1568 tokens with 156 being visible.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7XLI8iPm-1678156935697)(C:%5CUsers%5C%E7%8E%8B%E4%B8%80%E4%BA%8C%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20230306162907057.png)]](https://img-blog.csdnimg.cn/b42e803a734546a493d5d411db7ddb5b.png)
90%的masking ratio表现最好
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HmdwFKga-1678156935697)(C:%5CUsers%5C%E7%8E%8B%E4%B8%80%E4%BA%8C%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20230307101554940.png)]](https://img-blog.csdnimg.cn/bd37485638874d29b2ec928db93e6c98.png)
Ablation experiments
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3LSyIt0V-1678156935698)(C:%5CUsers%5C%E7%8E%8B%E4%B8%80%E4%BA%8C%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20230307101624445.png)]](https://img-blog.csdnimg.cn/0e0287c1db54424287cd313e3e4e662e.png)
Conclusion
本文有几个观察结果:
- 尽量少的领域知识或者归纳偏见就能学到强的representation —— transformer、vit
- mask ratio 是一个重要的超参数,并且不同数据种类,有很大不同。
- 对真实世界未经整理的数据进行预训练,令人鼓舞的结果(ins的实验)
高维视频数据仍然是扩展的主要挑战
Related
视频多模态预训练/检索模型
怎么看待Masked Autoencoders as spatiotemporal learners?