👂 不露声色 - Jam - 单曲 - 网易云音乐
目录
🌼前言
👊一,Python列表函数
👊二,Numpy常用函数
1,生成数组
2,描述数组属性
3,常用统计函数
4,矩阵运算
5,其他常见操作
👊三,Pandas常用函数
🌼补充
🌼前言
Python作为一款面向对象,跨平台并开源的计算机语言,是机器学习实践的首选工具
入门Python机器学习,应从了解并掌握Python的Numpy,Pandas,Matplotlib包开始
学习Python和完成机器学习的有效途径是:以特定的机器学习应用场景和数据为出发点,沿着由浅入深的数据分析脉络,逐个解决数据分析实际问题
👊一,Python列表函数
先看代码
L = []
L.append(1)
print(L)
L.extend((666,'pretty','xs'))
print(L)
L.insert(2,'儿砸')
print(L)
print('\n')
L.remove('儿砸')
print(L)
print("删除并返回列表最后一个元素\n",L.pop())
print(L)
print(L[1])
print('左闭右开\n',L[0:2])
L2 = ['0.0',233]
print(L + L2,'\n')
print('\n')
print(L2*2) #列表的复制
L3 = [1,2,3,5,3]
L4 = [1,2,3]
print(L3 < L4)
print('\n')
print(L3.count(3)) #3出现2次
print(L3.index(3)) #3首次出现的索引
L3.reverse()
print(L3) #列表翻转
L3.sort() #列表元素排序
print(L3)
print('\n')
print(L)
L = L3 #列表复制
print(L)
print('\n')
print(L3)
L = L3[1:3] #切片复制
print(L)
再看知识点
1,

L = []
L.append(1)
print(L)
L.extend((666,'pretty','xs'))
print(L)
L.insert(2,'儿砸')
print(L)[1]
[1, 666, 'pretty', 'xs']
[1, 666, '儿砸', 'pretty', 'xs']2,

L.remove('儿砸')
print(L)
print("删除并返回列表最后一个元素",L.pop())
print(L)
print(L[1])
print('左闭右开',L[0:2])[1, 666, 'pretty', 'xs']
删除并返回列表最后一个元素 xs
[1, 666, 'pretty']
666
左闭右开 [1, 666]3,

L2 = ['0.0',233]
print(L + L2,'\n')
print('\n')
print(L2*2) #列表的复制
L3 = [1,2,3,5,3]
L4 = [1,2,3]
print(L3 < L4)[1, 666, 'pretty', '0.0', 233]
['0.0', 233, '0.0', 233]
False4,
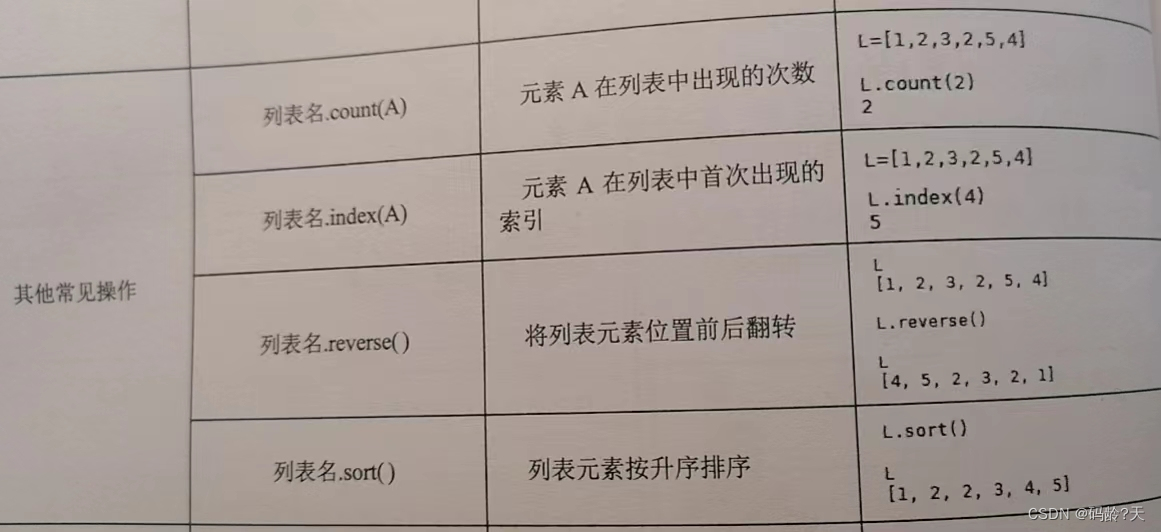
print(L3.count(3)) #3出现2次
print(L3.index(3)) #3首次出现的索引
L3.reverse()
print(L3) #列表翻转
L3.sort() #列表元素排序
print(L3)2
2
[3, 5, 3, 2, 1]
[1, 2, 3, 3, 5]5,

print(L)
L = L3 #列表复制
print(L)
print('\n')
print(L3)
L = L3[1:3] #切片复制
print(L)[1, 666, 'pretty']
[1, 2, 3, 3, 5]
[1, 2, 3, 3, 5]
[2, 3]👊二,Numpy常用函数
1,Numpy的数据组织方式是数组(Array)
-----------------------------------------------------------
2,jupyter notebook可以直接导入numpy等库,但是vs code需要安装这个包,否则会报错
error: no module named numpy
具体步骤
1,Ctrl+ Shift+` 生成新终端
2,输入pip install numpy(回车)
3,等待安装完毕
pandas, matplotlib等包的安装同上
------------------------------------------------------------
1,生成数组
np.arange(n) 生成从0到n-1的,步长为1的一维数组
np.random.randn(n) 随机生成n个服从标准的正太分布数组
import numpy as np
a = np.arange(5)
b = np.random.randn(5)
print(a)
print(b)[0 1 2 3 4]
[-0.42588491 -0.37133298 0.62970363 0.74290308 -0.28438498]2,描述数组属性
.ndim 返回数组维度
.shape 返回数组各维度长度
.dtype 返回数组元素数据类型
import numpy as np
arr = np.array([[1,2,3,5],[2,3,4,5]])
print(arr.ndim) #二维数组维度是2
print(arr.shape) #二维长度2,一维长度4
print(arr.dtype) #返回数组数据类型2
(2, 4)
int323,常用统计函数
np.sum() 求和
np.mean() 平均值
np.max() 最大值
np.min() 最小值
np.cumsum() 累积求和(前缀和)
np.sqrt() 平方根
import numpy as np
arr = np.array([[1,2,3,5],[2,3,4,5]])
print(np.sum(arr))
print(np.mean(arr))
print(np.max(arr))
print(np.min(arr))
print(np.cumsum(arr))
print(np.sqrt(arr))25
3.125
5
1
[ 1 3 6 11 13 16 20 25]
[[1. 1.41421356 1.73205081 2.23606798]
[1.41421356 1.73205081 2. 2.23606798]]4,矩阵运算
np.dot() 矩阵乘法(点乘)
.T 矩阵转置
np.linalg.inv() 矩阵求逆
np.linalg.det() 计算行列式
np.linalg.eig() 求特征值和特征向量
np.linalg.svd() 奇异值分解
import numpy as np
arr1 = np.array([2,3])
arr2 = np.array([1,2])
print(np.dot(arr1, arr2)) #矩阵乘法
arr = np.arange(6).reshape(2,3) #元素0-5的2行3列矩阵
print(arr)
print(arr.T) #矩阵转置
print()
arr = np.array([[1,2],[3,4]])
print(arr)
print(np.linalg.inv(arr)) #矩阵求逆
print(np.linalg.det(arr)) #计算行列式
print()
arr = np.diag([1,2,3])
print(np.linalg.eig(arr)) #特征值和特征向量
print()
print(np.linalg.svd(arr)) #奇异值分解8
[[0 1 2]
[3 4 5]]
[[0 3]
[1 4]
[2 5]]
[[1 2]
[3 4]]
[[-2. 1. ]
[ 1.5 -0.5]]
-2.0000000000000004
(array([1., 2., 3.]), array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]]))
(array([[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.]]), array([3., 2., 1.]), array([[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.]]))5,其他常见操作
np.sort(数组名) 数组各元素排序
np.rint() 各元素四舍五入取整
np.sign() 各元素取符号值
np.where(条件, x, y) 满足条件返回x,不满足返回y
import numpy as np
arr = np.array([4,5,3,2,6]) #排序
print(np.sort(arr)) #不改变原值, 需要直接打印或赋值
arr = np.array([3.2, 1.4, 3.7, 6.5]) #四舍五入
print(np.rint(arr)) #不会改变原值
print()
arr = np.array([-1.8, 1.4, 2, -3])
print(arr)
print(np.sign(arr)) #取符号值
print()
arr = np.array([1,2,3,4])
print(np.where(arr < 4, arr*2, arr-5))
#满足返回第一个, 不满足返回第二个[2 3 4 5 6]
[3. 1. 4. 6.]
[-1.8 1.4 2. -3. ]
[-1. 1. 1. -1.]
[ 2 4 6 -1]👊三,Pandas常用函数
Pandas的重要数据组织方式是数据框(DataFrame)
1,文件读取
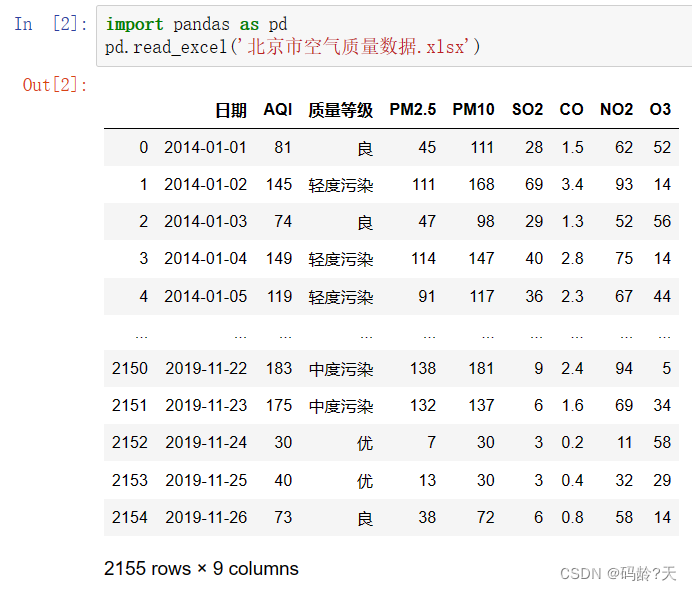
pd.read_excel(文件名)
2,描述数据框属性
数据框名.values (数据框的)值
.ndim 维度
.shape 各维长度
.columns 列名
.sum() 各列元素求和
.mean() 各列元素求均值
.max() 各列元素求最大值
.min() 各列元素最小值
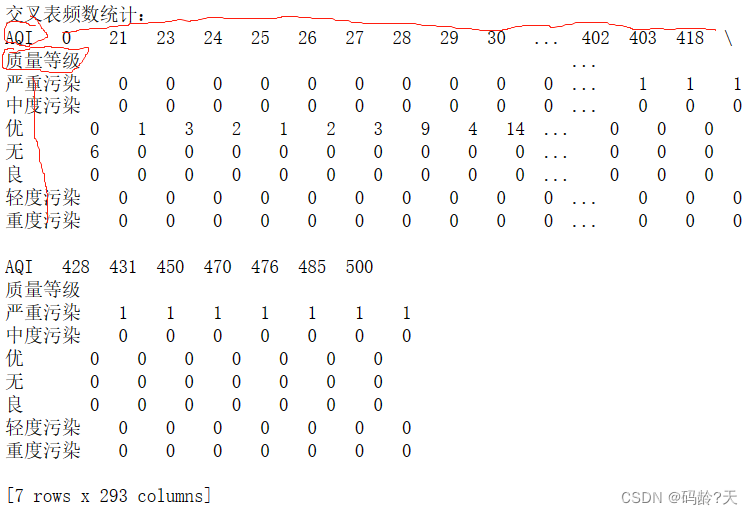
pd.crosstab() 交叉表频数统计
import pandas as pd
df = pd.read_excel('北京市空气质量数据.xlsx')
from pandas import Series,DataFrame
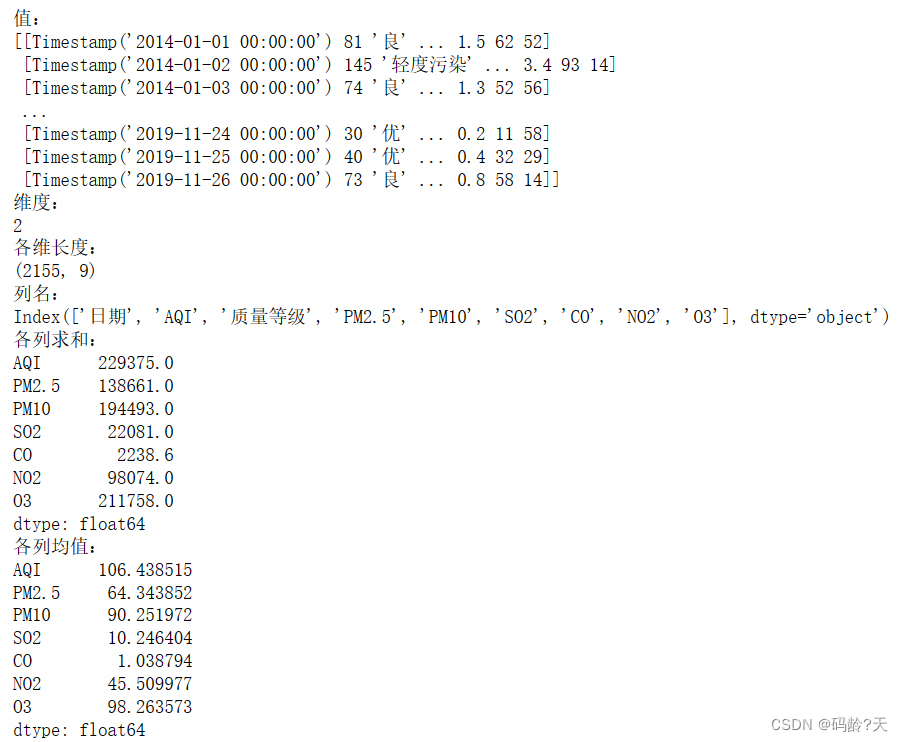
print('值:\n{0}'.format(df.values))
print('维度:\n{0}'.format(df.ndim))
print('各维长度:\n{0}'.format(df.shape))
print('列名:\n{0}'.format(df.columns))
print('各列求和:\n{0}'.format(df.sum()))
print('各列均值:\n{0}'.format(df.mean()))
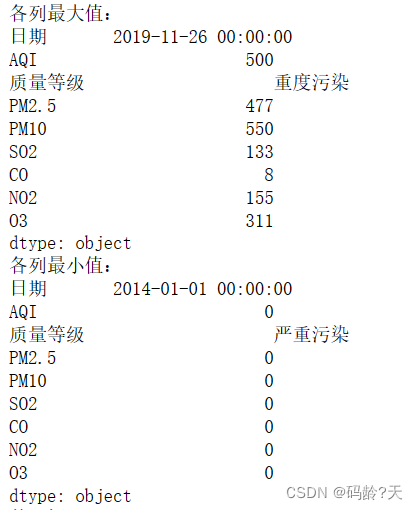
print('各列最大值:\n{0}'.format(df.max()))
print('各列最小值:\n{0}'.format(df.min()))
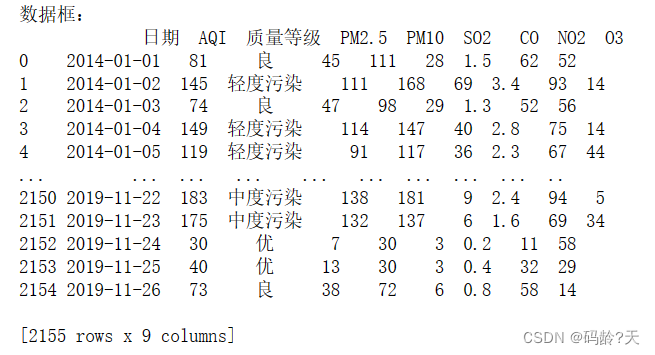
print('数据框:\n{0}'.format(df))
print('\n交叉表频数统计:\n{0}'.format(pd.crosstab(df.质量等级,df.AQI)))输出
3,空值操作
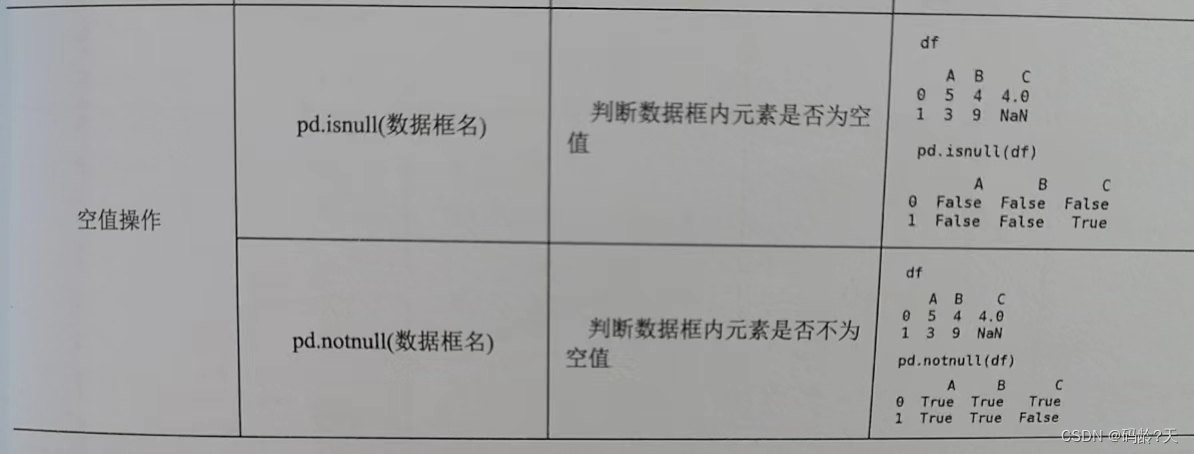
pd.isnull(数据框名) 判断数据框内元素是否为空值
pd.notnull(数据框名) 不为空值
数据框名.dropna() 删除含有空数据的全部行

4,其他常见操作
数据框名.groupby() 数据框按指定列分组计算
.sort_values() 指定列的数值大小排序
.apply() 对列特定运算
.drop_duplicates() 去除指定列下面的重复行
.replace() 数值替换
pd.merge() 数据框合并
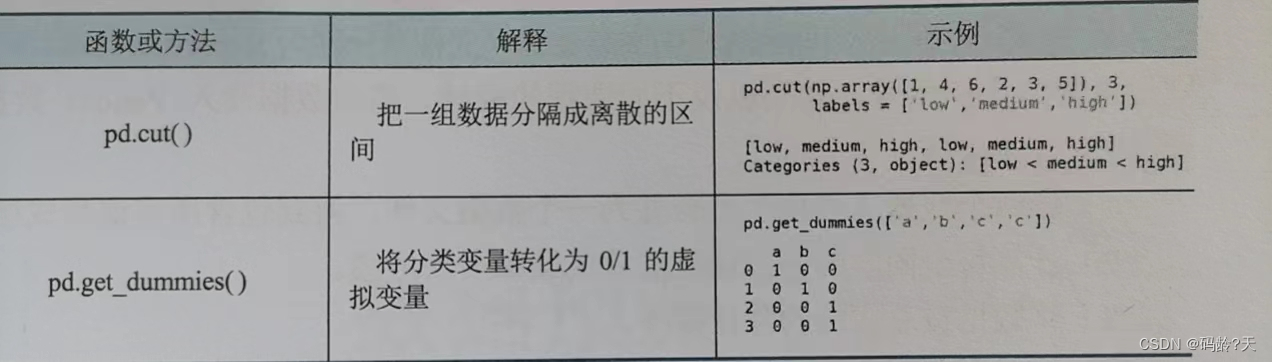
pd.cut() 将一组数据分隔成离散的区间
pd.get_dummies() 分类变量转化为0/1的虚拟变量


🌼补充
1)Pandas的for循环时实现程序循环控制的常见途径,for循环基本格式如下:
for 变量 in 序列:
循环体
变量依次从序列中取值,控制循环次数并多次执行循环体的操作
2)用户自定义函数:实现某种特定计算功能的程序段。具有一定通用性,会被主程序经常调用。
需首先以独立程序段的形式,定义用户自定义函数,然后才可以在主程序中调用,基本格式如下:
def 函数名(参数):
函数体
其中,def为用户自定义的关键字;函数名是函数调用的依据;参数是须向函数体提供的数据参数;函数体用于定义函数的具体处理流程。
3)匿名函数:一种简单,短小的用户自定义函数,一般课直接嵌在主程序中。
基本格式如下:
lambda 参数: 函数表达式
其中,lambda为匿名函数关键字