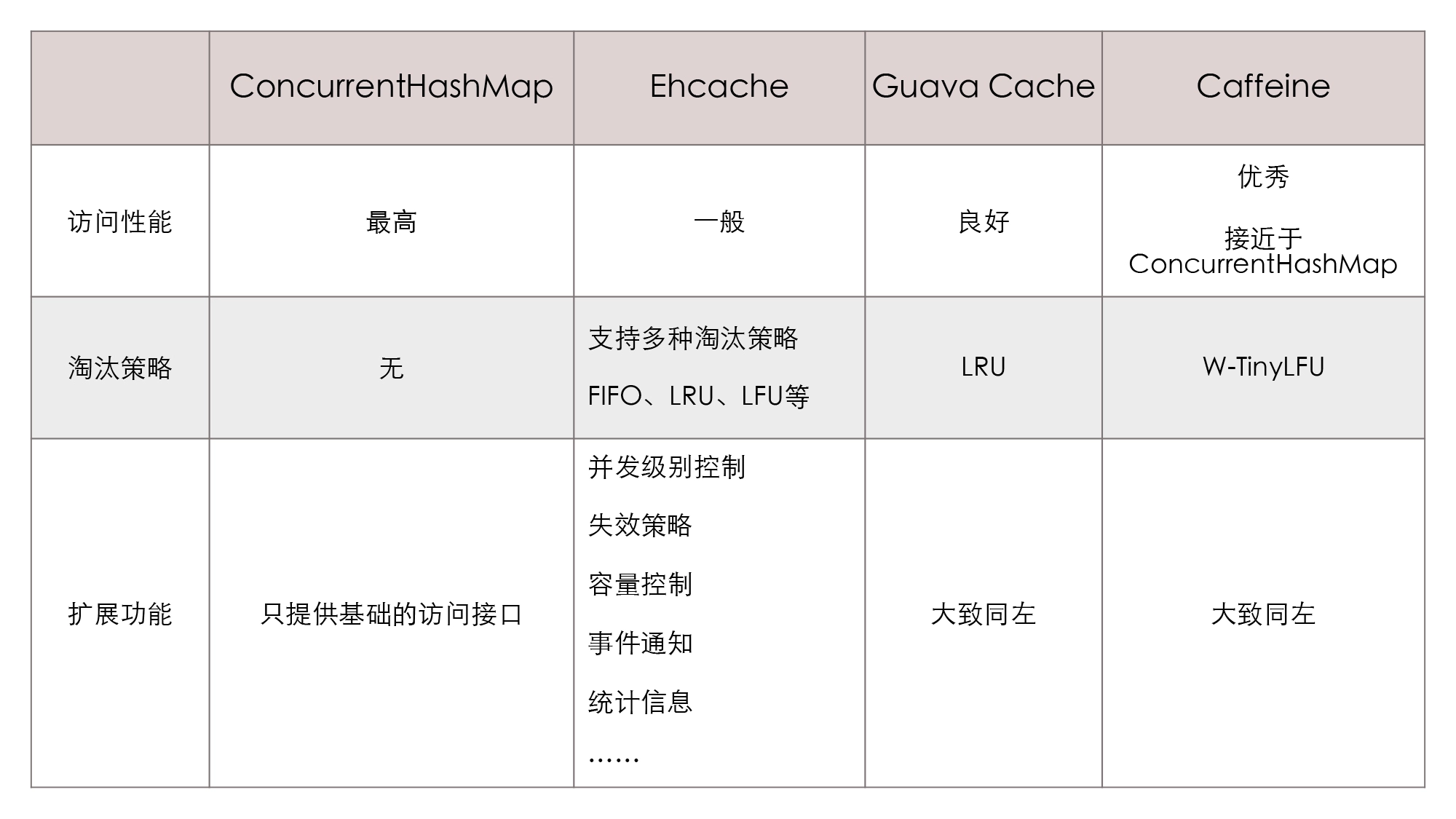
Spark 存储系统
- MemoryStore
- DiskStore
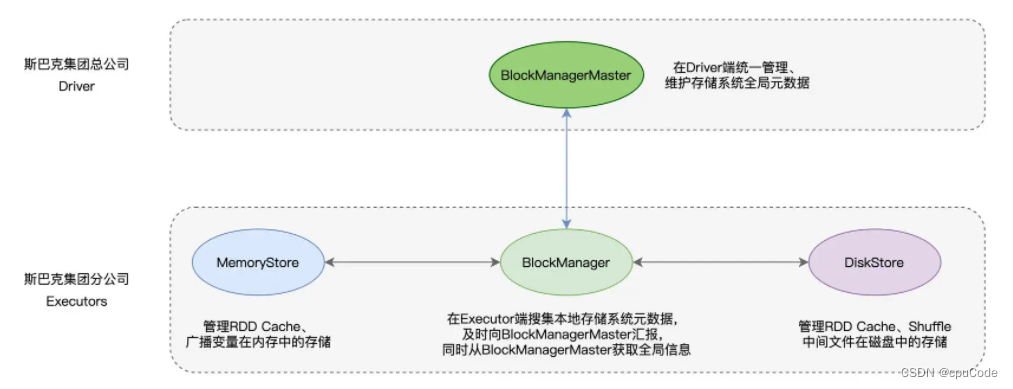
Spark 存储系统架构:
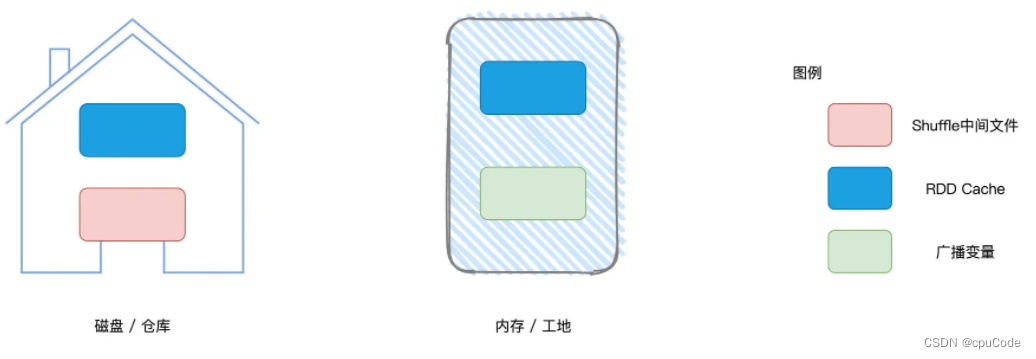
Spark 存储系统维护的数据 :
- Shuffle 中间文件 :Shuffle Map 输出数据 , 消耗节点磁盘
- 广播变量 :在 Executors 内保存所有数据 ,消耗节点的内存
- RDD Cache : 将 RDD 缓存到内存/磁盘 ,消耗内存,又消耗磁盘
BlockManagerMaster/BlockManager 之间交换的信息 (Executors 的数据状态) :
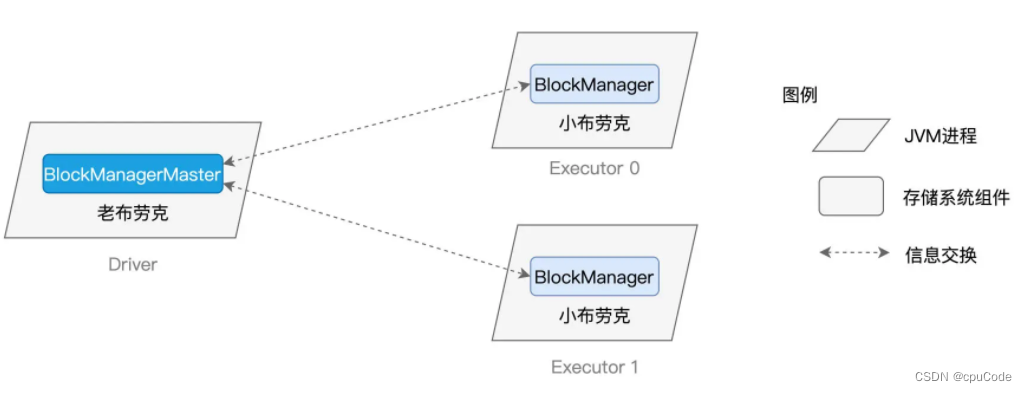
BlockManager 负责:管理数据块的元数据(Meta data),这些元数据记录并维护数据块的地址、位置、尺寸以及状态
BlockManager 的存储抽象 :
- MemoryStore : 负责内存中的数据存取
- DiskStore : 负责磁盘中的数据访问
Spark 存储系统支持两种类型:
- 对象值(Object Values):字节数组还原成原始对象值:反序列化
- 字节数组(Byte Array) :对象值转为字节数组:序列化
MemoryStore
MemoryStore 用 MemoryEntry 封装了两种数据存储:存储对象值,字节数组
- 采用 LRU 逐一清除字典中最近、最久未使用的 Block
MemoryStore 用 LinkedHashMap 记录数据块的信息
- LinkedHashMap[BlockId, MemoryEntry]: Key 是 BlockId,Value 是 MemoryEntry 的链式哈希字典
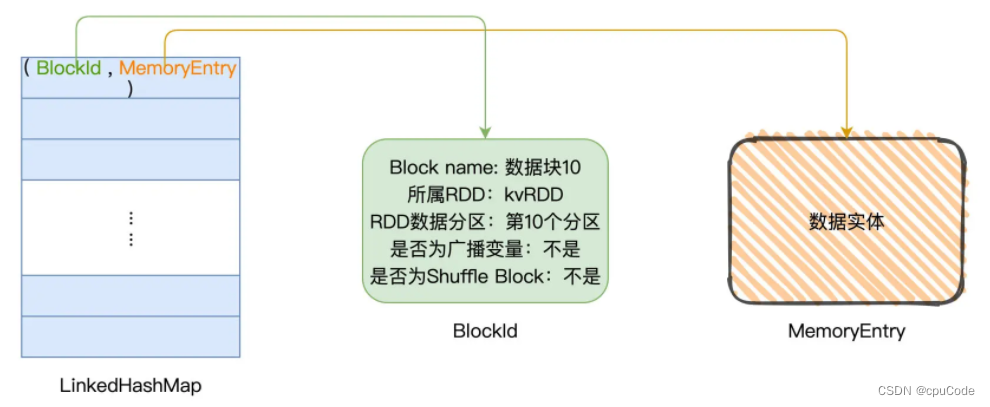
- BlockId (数据结构) :标记 Block 的身份,记录了:Block 名字、所属 RDD、Block 对应的 RDD 数据分区、是否为广播变量、是否为 Shuffle Block
- MemoryEntry (对象) :承载数据实体,某个 RDD 的数据分区或广播变量,类似于数据实体的地址
MemoryEntry 有两个实现类:
- DeserializedMemoryEntry : 封装原始对象值 ,用 Array[T]来存储对象值序列,其中 T 是对象类型
- SerializedMemoryEntry : 序列化后的字节数组 ,使用 ByteBuffer 来存储序列化后的字节序列
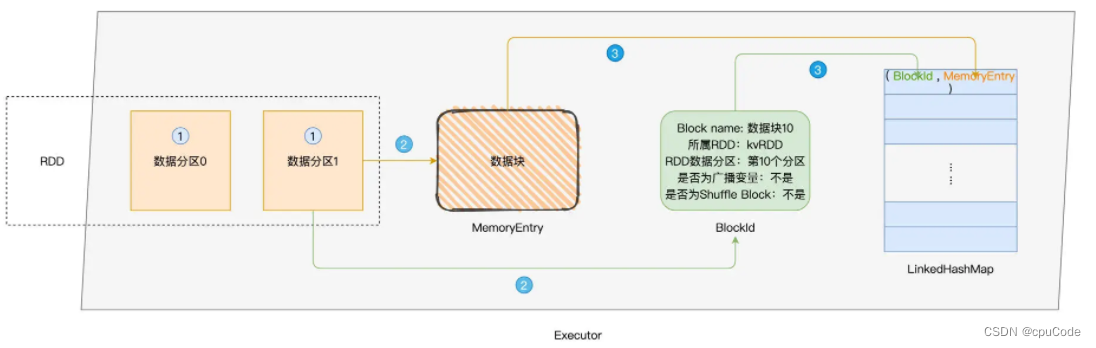
创建 RDD Cache 过程:
- 以数据分区为粒度,计算 RDD 执行结果,生成对应的数据块
- 将数据块封装到 MemoryEntry,同时创建数据块元数据 BlockId
- 将
(BlockId,MemoryEntry)键值对添加到 LinkedHashMap
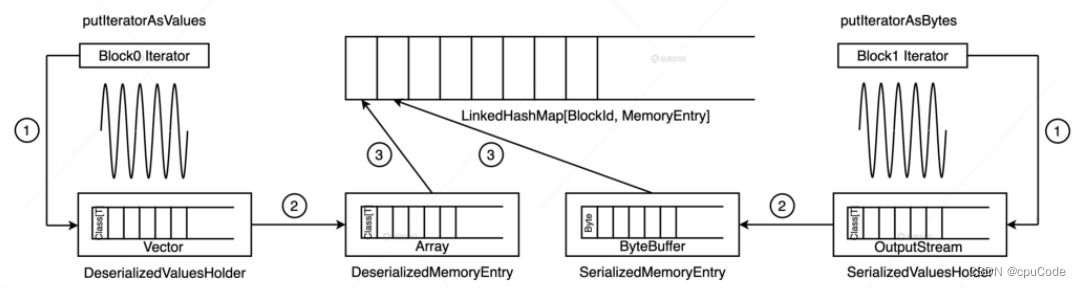
详细过程:
- 通过
putIteratorAsValues/putIteratorAsBytes,把 RDD 展开为数据值,把数据暂存到 ValuesHolder 结构中 - 为了节省内存开销,调用
toArray/toByteBuffer,把 ValuesHolder 转为 MemoryEntry 结构 - MemoryEntry 与 BlockId 对应 ,会一起被存入
LinkedHashMap[BlockId, MemoryEntry]链式哈希字典中
DiskStore
DiskStore :维护数据块与磁盘文件的对应关系,实现磁盘数据的存取访问
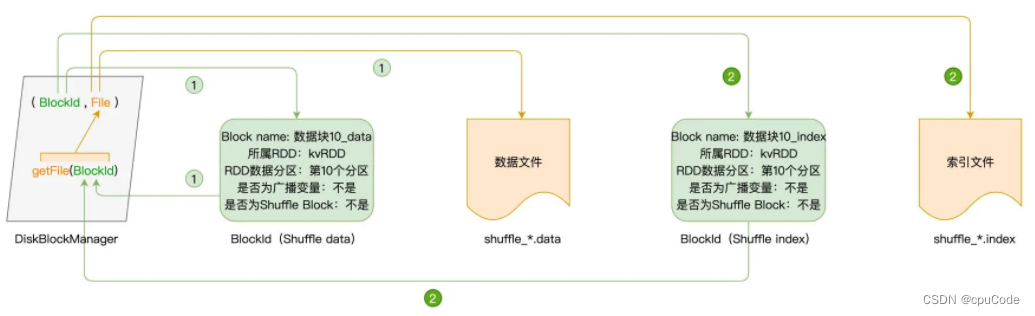
- DiskStore 利用 DiskBlockManager : 维护元数据
DiskStore 的数据存取过程:
- 在
spark.local.dir下创建目录和子目录,spark.diskStore.subDirectories控制子目录数,默认是 64
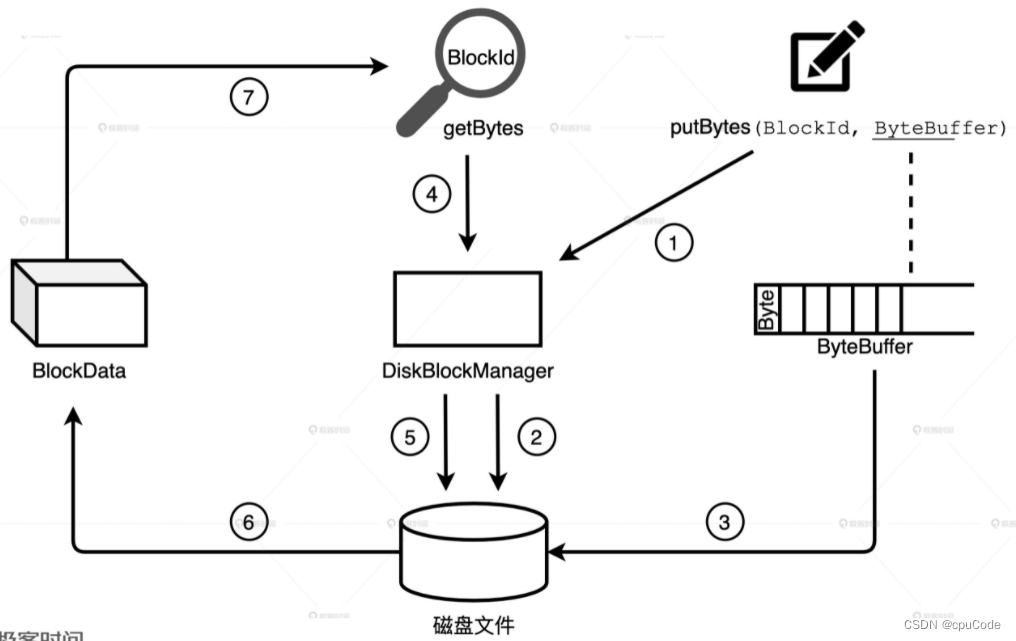
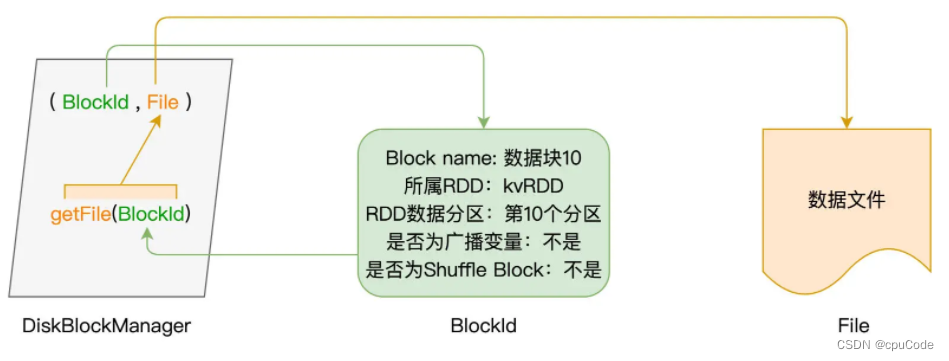
DiskBlockManager 是类对象 : 记录了逻辑数据块 Block 与磁盘中的物理文件的对应关系,每个 Block 都对应一个磁盘文件
- 通过
getFile(BlockId)把文件内容转为数据块 - 通过
putBytes把字节序列存入磁盘文件
获取 Shuffle 文件过程:
- Shuffle write:Shuffle manager 通过 BlockManager 调用
DiskStore.putBytes将数据块写入文件 - Shuffle read :Shuffle manager 通过 BlockManager 调用
DiskStore. getBytes方法,读取 data/index 文件,将文件内容转化为数据块,再通过网络分发到 Reducer 端进行聚合计算