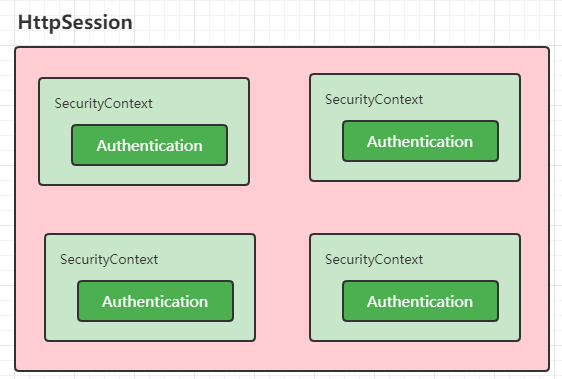
最简单的线性回归模型-标量
接上篇,由于batchsize为1,因此loss有很大的波动,这篇我们讨论batchsize大于1的情况。若batchsize数量为N,则
y
=
w
x
+
b
y=wx+b
y=wx+b的损失函数为:
L
=
∑
i
=
1
N
(
w
x
i
∗
+
b
−
y
i
∗
)
2
=
(
w
x
T
+
b
e
T
−
y
T
)
(
w
x
+
b
e
−
y
)
\begin{aligned} L&=\sum_{i=1}^{N}(wx_i^*+b-y_i^*)^2\\ &=(w\boldsymbol{x}^T+b\boldsymbol{e}^T-\boldsymbol{y}^T)(w\boldsymbol{x}+b\boldsymbol{e}-\boldsymbol{y}) \end{aligned}
L=i=1∑N(wxi∗+b−yi∗)2=(wxT+beT−yT)(wx+be−y)
为了方便计算在对损失函数乘一个数值,不影响其极值,因此将损失函数变为:
L
=
1
2
∑
i
=
1
N
(
w
x
i
∗
+
b
−
y
i
∗
)
2
L=\frac{1}{2}\sum_{i=1}^{N}(wx_i^*+b-y_i^*)^2
L=21i=1∑N(wxi∗+b−yi∗)2
求出
w
w
w和
b
b
b的梯度:
∂
L
∂
w
=
∑
i
=
1
N
(
w
x
i
∗
+
b
−
y
i
∗
)
x
i
∗
=
∑
i
=
1
N
w
x
i
∗
2
+
∑
i
=
1
N
b
x
i
∗
−
∑
i
=
1
N
y
i
∗
x
i
∗
=
w
x
T
x
+
b
e
T
x
−
y
T
x
=
(
w
x
T
+
b
e
T
−
y
T
)
x
\begin{aligned} \frac{\partial{L}}{\partial{w}}&=\sum_{i=1}^{N}(wx_i^*+b-y_i^*)x_i^*\\ &=\sum_{i=1}^{N}wx_i^{*2}+\sum_{i=1}^{N}bx_i^*-\sum_{i=1}^{N}y_i^*x_i^*\\ &=w\boldsymbol{x}^T\boldsymbol{x}+b\boldsymbol{e}^T\boldsymbol{x}-\boldsymbol{y}^T\boldsymbol{x}\\ &=(w\boldsymbol{x}^T+b\boldsymbol{e}^T-\boldsymbol{y}^T)\boldsymbol{x} \end{aligned}
∂w∂L=i=1∑N(wxi∗+b−yi∗)xi∗=i=1∑Nwxi∗2+i=1∑Nbxi∗−i=1∑Nyi∗xi∗=wxTx+beTx−yTx=(wxT+beT−yT)x
∂
L
∂
b
=
∑
i
=
1
N
(
w
x
i
∗
+
b
−
y
i
∗
)
=
(
w
x
T
+
b
e
T
−
y
T
)
e
\begin{aligned} \frac{\partial{L}}{\partial{b}}&=\sum_{i=1}^{N}(wx_i^*+b-y_i^*)\\ &=(w\boldsymbol{x}^T+b\boldsymbol{e}^T-\boldsymbol{y}^T)\boldsymbol{e} \end{aligned}
∂b∂L=i=1∑N(wxi∗+b−yi∗)=(wxT+beT−yT)e
其中
x
\boldsymbol{x}
x为每个batch中所有的
x
∗
x^*
x∗组成的N维列向量,
y
\boldsymbol{y}
y为每个batch中所有的
y
∗
y^*
y∗组成的N维列向量,
e
\boldsymbol{e}
e是长度为N的列向量,**使用向量表示可以让我们轻松使用numpy实现回归过程。**使用python实现结果如下:
import numpy as np
import random
import matplotlib.pyplot as plt
x = np.array([0.1,1.2,2.1,3.8,4.1,5.4,6.2,7.1,8.2,9.3,10.4,11.2,12.3,13.8,14.9,15.5,16.2,17.1,18.5,19.2])
y = np.array([5.7,8.8,10.8,11.4,13.1,16.6,17.3,19.4,21.8,23.1,25.1,29.2,29.9,31.8,32.3,36.5,39.1,38.4,44.2,43.4])
print(x,y)
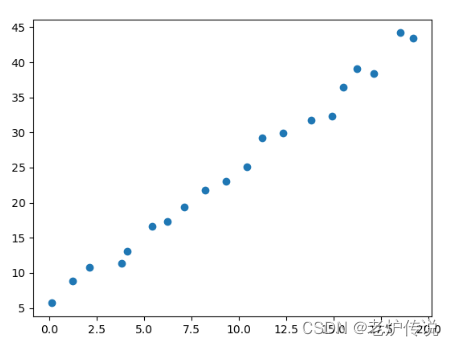
plt.scatter(x,y)
plt.show()
散点图如下:
回归过程使用numpy中的矩阵计算完全按照上述损失函数和梯度直接计算即可:
# 设定步长
step=0.001
# 存储每轮损失的loss数组
loss_list=[]
# 定义epoch
epoch=500
# 定义batch_size
batch_size=18
# 定义单位列向量e
e=np.ones(batch_size).reshape(batch_size,1)
# 定义参数w和b并初始化
w=0.0
b=0.0
#梯度下降回归
for i in range(epoch) :
#计算当前输入x和标签y的索引,由于x和y数组长度一致,因此通过i整除x的长度即可获得当前索引
index = i % int(len(x)/batch_size)
# 当前轮次的x列向量值为:
cx=x[index*batch_size:(index+1)*batch_size]
cx=cx.reshape(len(cx),1)
# 当前轮次的y列向量值为:
cy=y[index*batch_size:(index+1)*batch_size]
cy=cy.reshape(len(cy),1)
# 计算当前loss
curloss = (w*cx.T+b*e.T-cy.T).dot((w*cx+b*e-cy))
loss_list.append(float(curloss))
# 计算参数w和b的梯度
grad_w = (w*cx.T+b*e.T-cy.T).dot(cx)
grad_b = (w*cx.T+b*e.T-cy.T).dot(e)
# 更新w和b的值
w -= step*grad_w
b -= step*grad_b
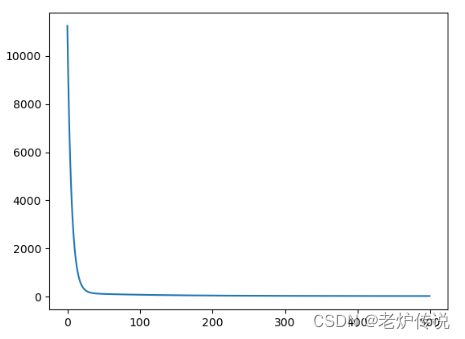
损失函数和最终拟合结果如下:
print(loss_list)
plt.plot(loss_list)
plt.show()
pred_y = w*x+b
plt.scatter(x,y)
plt.plot(x,pred_y.reshape(len(x)),c='r')
plt.show()
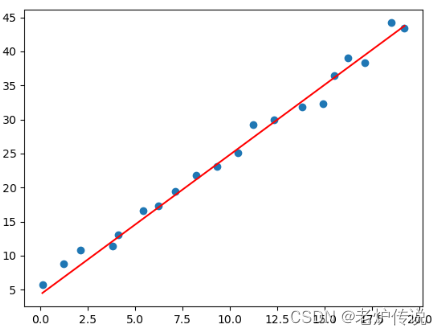
可以看到增大batsize后损失函数比较稳定。