文章目录
- 一、卷积
- 二、池化
- 三、Batch Norm
- 四、经典卷积网络简单介绍
一、卷积
卷积连续函数形式:
F
(
x
)
=
∫
f
(
t
)
g
(
x
−
t
)
d
t
F(x)=\int f(t)g(x-t)dt
F(x)=∫f(t)g(x−t)dt
物理意义是一个函数在另一个函数上的加权叠加。在2D卷积中指卷积核在数据矩阵中分割出的矩阵和卷积核相乘得到矩阵汇总的过程
卷积层参数:
- 卷积核大小(Kernel Size):卷积的视野,通常为3x3、5x5
- 步长(Stride):遍历图像时卷积核的移动的步长
- 填充(Padding):处理样本边界方式。可以边界外完全不填充但会使输出特征图的尺寸小于输入特征图尺寸;另一种是对边界外进行填充再卷积,使输出特征图的与输入特征图的尺寸一致
- 通道(Channel):卷积层的通道数(层数)
单通道卷积与多通道卷积(2D):
输出为2D的矩阵数据。每个通道都有对应的卷积核以及产生对应结果,将多个结果累加求和得到最终结果即可,它综合了各个通道上的信息,有多少个卷积核,就有多少个featuremap。如下用了2个&
动态图地址
二、池化
pooling是一般在卷积层后整合提取特征的作用,即增加特征整合度又防止无用参数增加时间复杂度。它的操作是指定而不是学习,一般有如下常见类型:
- Max pooling:每块取最大的,提取更明显的特征(边缘)
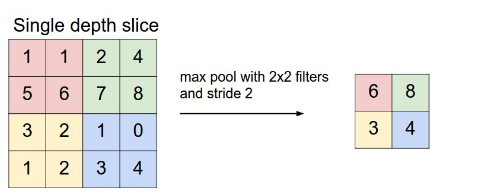
- AVE pooling:计算feature map的均值,提取更加平滑
- SUM Pooling:本质同AVE
说到底还是一个特征选择,信息过滤的过程。就是损失一部分信息,这是一个和计算性能的妥协,随着运算速度的不断提高,有些网络都开始少用或者不用pooling层了
三、Batch Norm
假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障,Normalization 的目的是为了把输入转化成均值为 0 方差为 1 的数据,使得每层网络的输入保持相同分布,同时加快收敛速度和效果。其基本原理如下:

形象图:
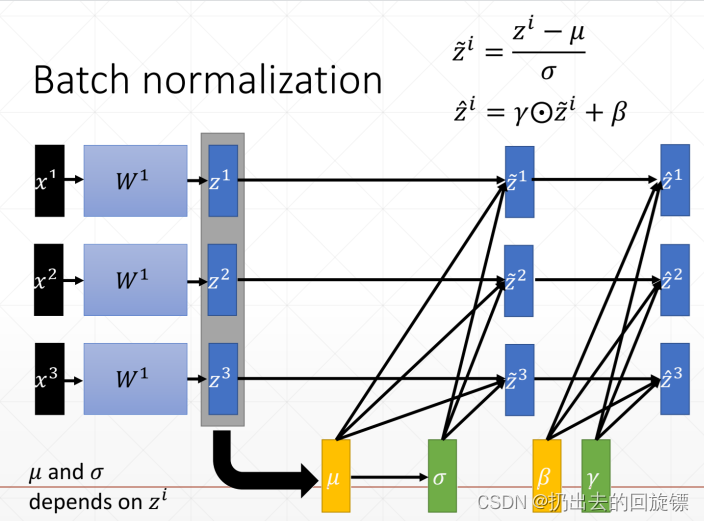
注意事项:
- β \beta β和 γ \gamma γ分别为平移参数和缩放参数 ,保证没次数据归一化后还有保留的有学习来的特征,加速训练
- 测试时使用训练时计算好的mean和var
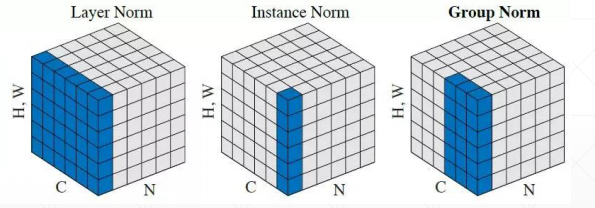
- 其他相关norm方法:
四、经典卷积网络简单介绍
LeNet-5
卷积神经网络的开山之作,用于手写字识别。由1个输入层(通常不视为网络层次)、2个卷积层、2个池化层、3个全连接层组成(最后一个也作为输出层)
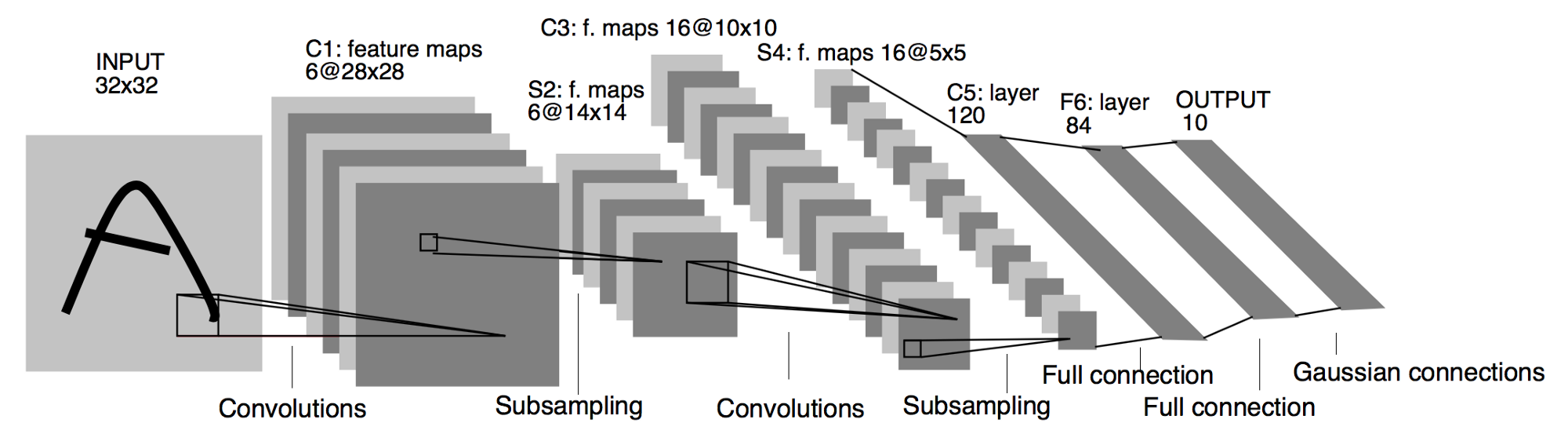
| 层次名称 | 类型 | 输出大小 | 核大小 | padding | stride | 卷积核个数 |
|---|---|---|---|---|---|---|
| Input | 输入层 | 32x32 | None | None | None | 1 |
| C1 | 卷积层 | 28x28 | 5x5 | 0 | 1 | 6 |
| S2 | 下采样层 | 14x14 | 2x2 | 0 | 2 | 6 |
| C3 | 卷积层 | 10x10 | 5x5 | 0 | 1 | 16 |
| S4 | 下采样层 | 5x5 | 2x2 | 0 | 2 | 16 |
| C5 | 卷积层 | 1x1 | 5x5 | 0 | 1 | 120 |
| F6 | 全连接层 | 84 | None | None | None | None |
| Output | (全连接层) | 10 | None | None | None | None |
AlexNet
2012年ISLVRC竞赛冠军设计,准确率提高了10%+。架构为5个卷积层和3个全连接层
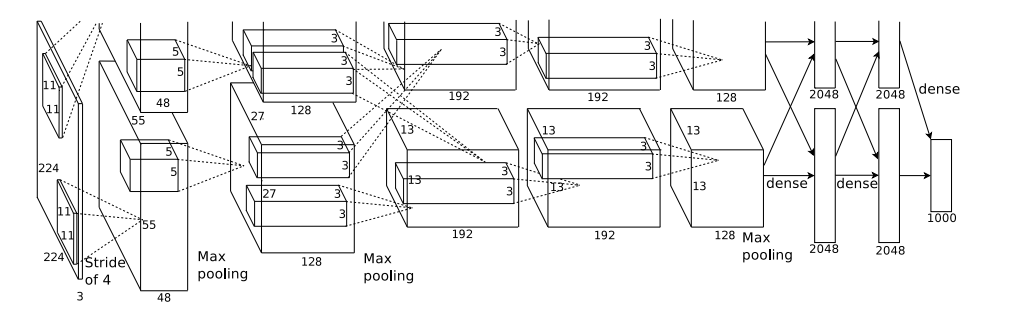
上图架构表示2个GPU分块计算,目前GPU显存足够,实际合并也不影响架构表示。由于后面出现模型层数都越来越多,就只介绍特点了:
- 使用GPU进行加速,速度为使用CPU的50倍。2张GTX 580 训练一周(现在训练几个月都很正常咯)
- 使用非线性的激活函数-ReLU(论文验证较深网络优于Sigmoid),解决梯度离散的问题
- 全连接前两层中使用Dropout ,有效限制过拟合
- 重叠池化,即padding>stride,可以使相邻像素之间交互和保留必要的联系
- 网络层数的增加以及数据的增加
VGG16
VGG最大的贡献就是证明了卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用,这个可以很好的节省参数(3个3x3的卷积核效果与7x7的类似,但参数少很多)
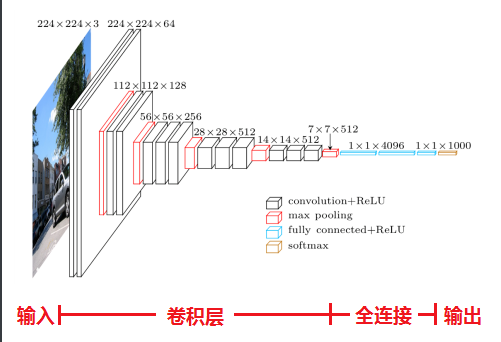
含有与参数的网络层一共16层,13个卷积层,5个池化层(不算网络层数),3个全连接层,特点如下:
- 采用多个小卷积核代替较大的卷积核,减少计算量
- 使用1x1的卷积,增加决策函数的非线性能力,更少的计算
- 更深的网络结构。。
GoogLeNet
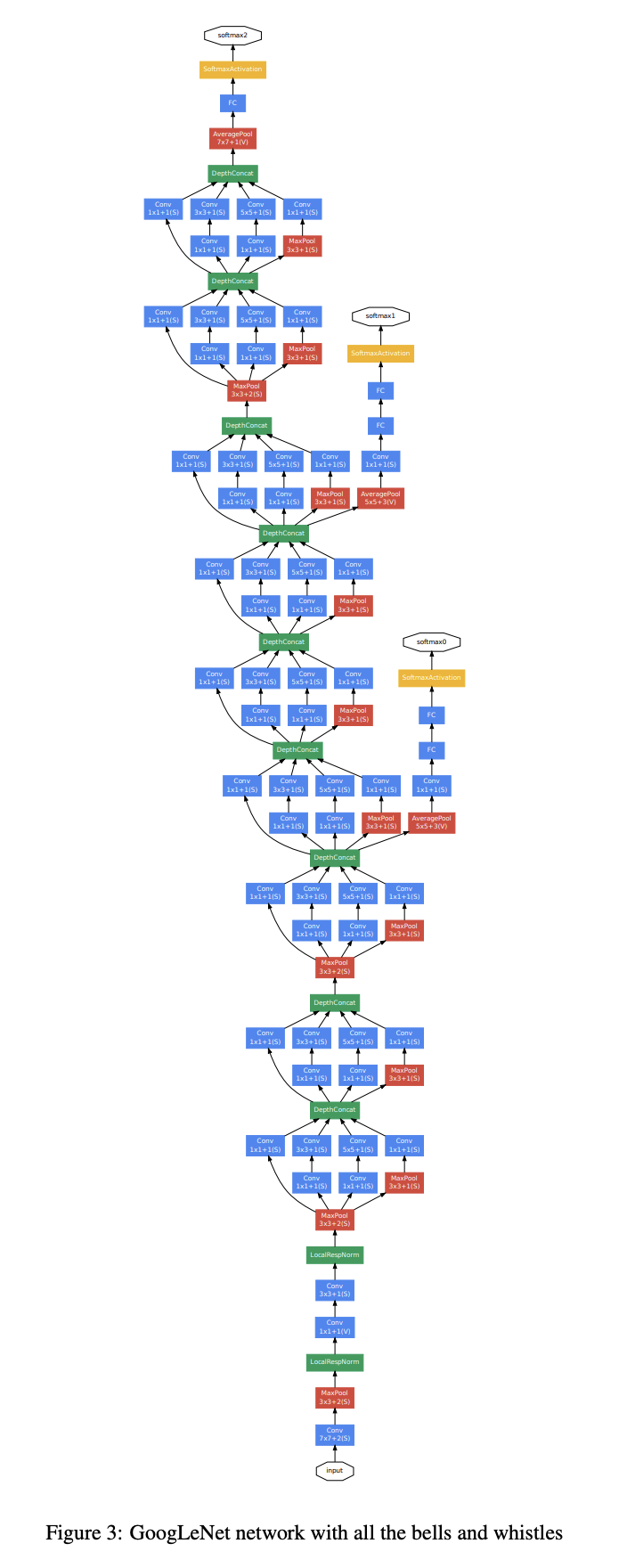
特点如下:
- Inception结构,融合不同尺度的特征信息。也采用1x1卷积核来降维减少参数再传递。
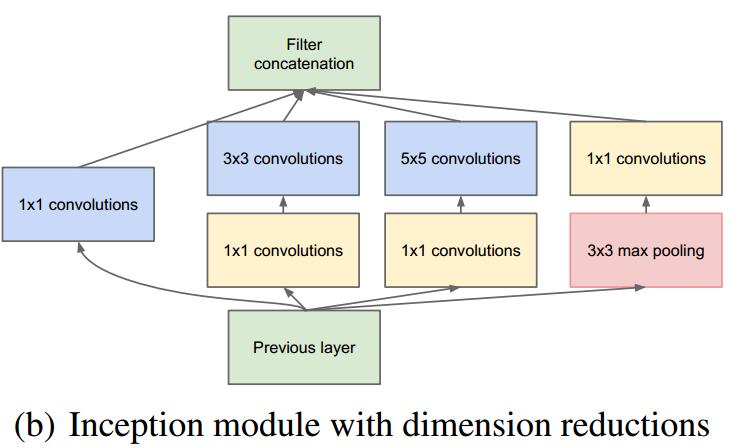
初代Inception结构如下:
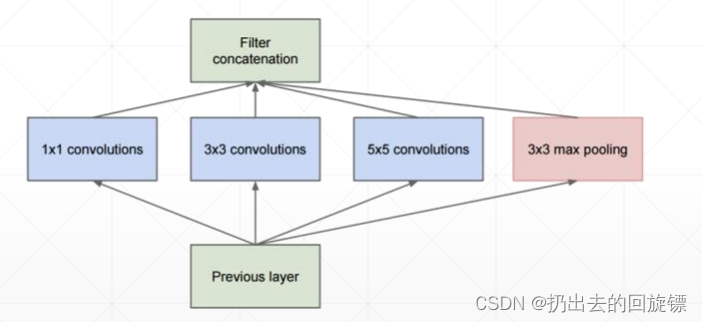
- 添加2个辅助分类器(提前输出)帮助训练,防止梯度爆炸和梯度消失
- 不使用全连接层而使用平均池化层,减少模型参数
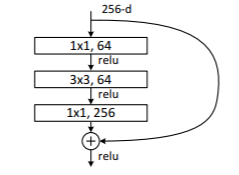
ResNet
解决了网路加深造成梯度爆炸和梯度消失的问题,主要想法来源VLAD和Highway Network,其重要思想的结构图如下:
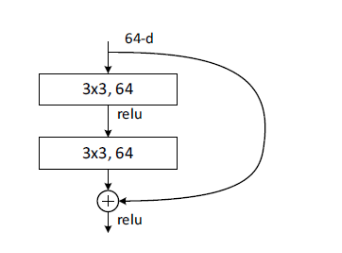
它提出了2种映射:恒等映射(identity mapping)x 和残差映射(residual mapping)F(x),加入后表示如下:
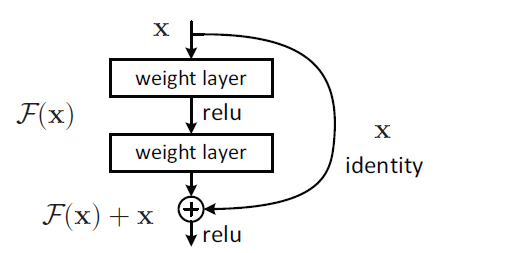
这样实现了shortcut connections,如果网络已经达到最优,继续加深网络,residual mapping将变为0,只剩下identity mapping,这样理论上网络会一直处于最优状态,网络的性能也就不会随着深度增加而降低。
当层数更深为了降低参数数目可以采用下面这种改进结构:
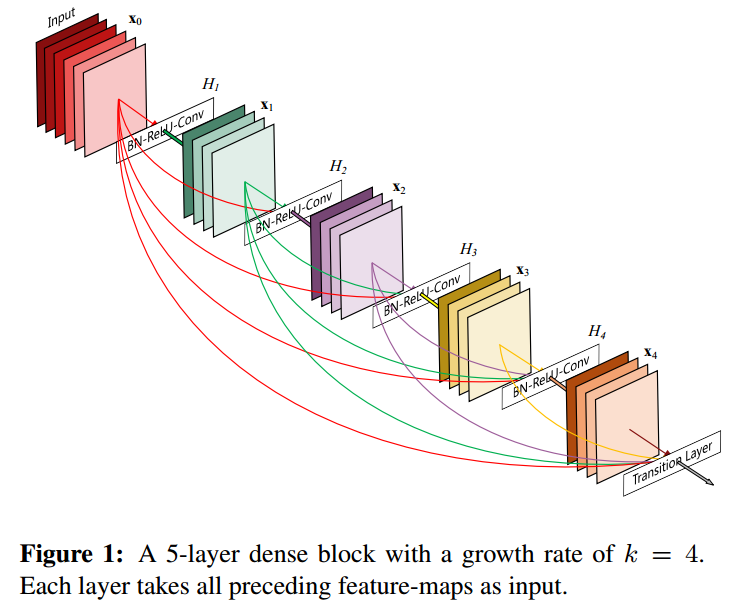
DenseNet
在ResNet上进行改进,每一个卷积层的输入为前面所有卷积层输出的,综合前面各环节得到的信息再决定当前层的行为