day2
- 1.二分
- (1)789. 数的范围
- (2)四平方和
- (1)哈希表做法
- (2)二分做法
- (3)1227. 分巧克力
- (4)113. 特殊排序
- (5)1460. 我在哪?
- 2.双指针
- (1)1238. 日志统计
- (2)1240. 完全二叉树的权值
- (3)字符串删减
- (4)799. 最长连续不重复子序列
- (5)800. 数组元素的目标和
- (6)判断子序列
1.二分
(1)789. 数的范围

思路:
需要找到一个值的区间。比如1 2 2 3 4 5 找2的区间,即[1,2]
因为数组是有序的,所以可以使用二分查找。
(1)使用二分查找找左边界
(2)使用二分查找找右边界
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=100010;
int n,q;
int a[N];
int find1(int t) //找到当前查找数的区间左边界
{
int res=-1;
int l=0,r=n-1;
int mid=(l+r)>>1;
while(l<=r)
{
mid=(l+r)>>1;
if(a[mid]>t)r=mid-1;
else if(a[mid]<t)
l=mid+1;
else
{
res=mid;
r=mid-1;
}
}
return res;
}
int find2(int t)
{
int res=-1;
int l=0,r=n-1;
int mid=(l+r)>>1;
while(l<=r)
{
mid=(l+r)>>1;
if(a[mid]>t)r=mid-1;
else if(a[mid]<t)
l=mid+1;
else
{
res=mid;
l=mid+1;
}
}
return res;
}
int main()
{
cin>>n>>q;
for(int i=0;i<n;i++)
cin>>a[i];
while(q--)
{
int t;
cin>>t;
cout<<find1(t)<<" "<<find2(t)<<endl;
}
return 0;
}
(2)四平方和
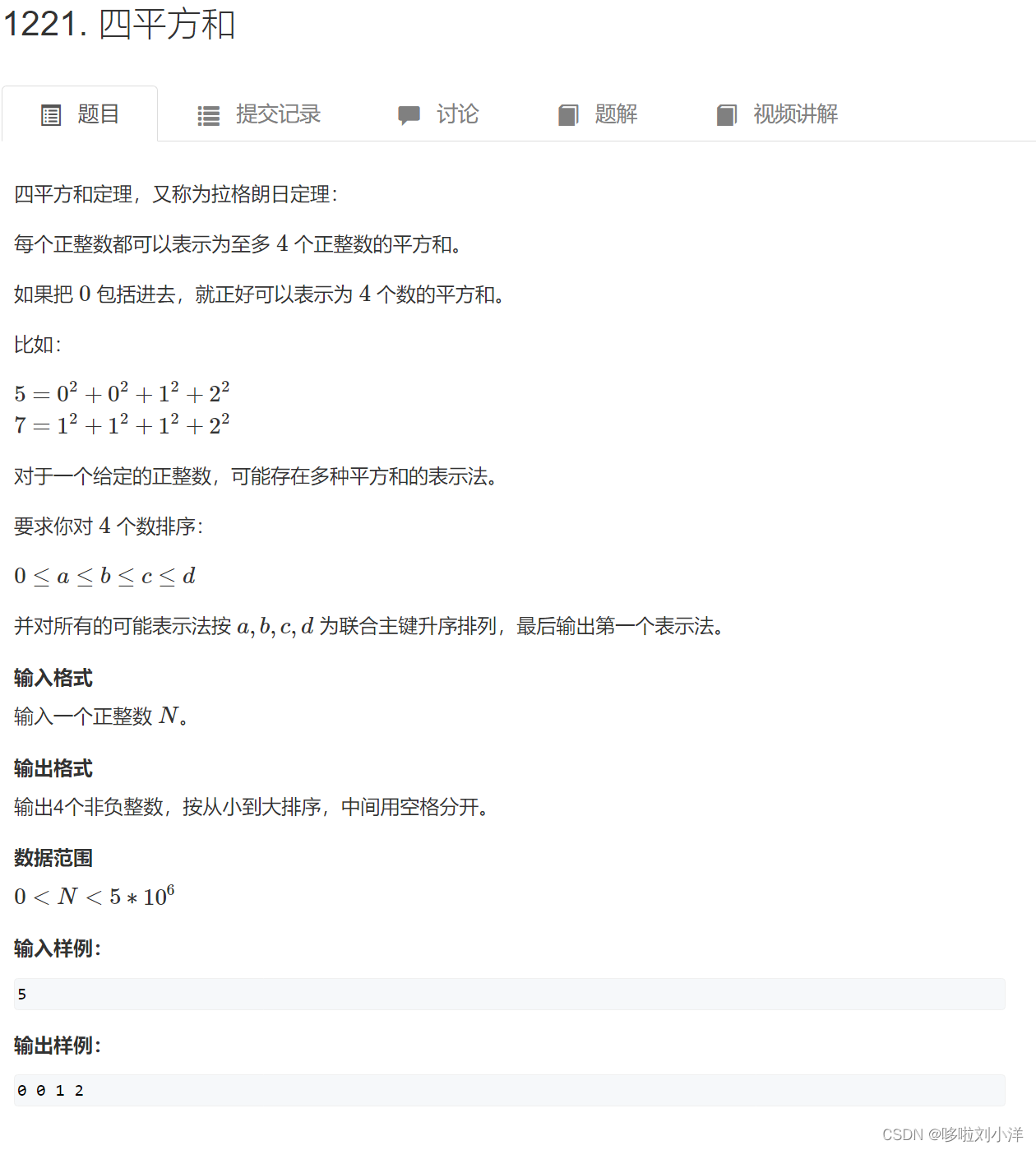
经典哈希问题,二分问题。
第一步:先找出两个数的平方和的所有组合(不超过n)
第二步:n减去两个数的平方和,剩下的数看是否在第一步预处理过。
为什么可以保证字典序最小呢:
(1)在第二步中,a,b是从小到大枚举的,且可以保证a<=b恒成立,为什么?如果a>b成立,那么把a,b置换一下,一样成立。然后第一次成立就会结束,所以不可能遇到a>b的情况
(2)C[k],D[k]也是一样的道理。在第一步就可以证明。
(1)哈希表做法
#include<iostream>
#include<cstring>
using namespace std;
const int N=5000010;
int C[N],D[N];
int n;
int main()
{
cin>>n;
memset(C,-1,sizeof C);
//第一步:将所有两个数的组合都算出来
for(int a=0;a*a<=n;a++)
{
for(int b=a;b*b+a*a<=n;b++)
{
int k=a*a+b*b;
if(C[k]==-1)
{
C[k]=a,D[k]=b;
}
}
}
//第二步,将n减去ab两个数的组合,剩下的看之前是否存储,如果有,直接输出。而且一定满足字典序最小
for(int a=0;a*a<=n;a++)
{
for(int b=a;b*b+a*a<=n;b++)
{
int k=n-a*a-b*b;
if(C[k]!=-1)
{
cout<<a<<" "<<b<<" "<<C[k]<<" "<<D[k]<<endl;
return 0;
}
}
}
return 0;
}
(2)二分做法
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=5000010;
struct Sum
{
int s,c,d; //s表示a*a+b*b
bool operator<(const Sum &t)const //为什么重载小于号
{
if(s!=t.s)return s<t.s;
if(c!=t.c)return c<t.c;
return d<t.d;
}
}sum[N];
int n;
int m;
int main()
{
cin>>n;
for(int c=0;c*c<=n;c++)
for(int d=c;c*c+d*d<=n;d++)
sum[m++]={c*c+d*d,c,d};
sort(sum,sum+m);
for(int a=0;a*a<=n;a++)
{
for(int b=a;b*b+a*a<=n;b++)
{
int t=n-a*a-b*b;
int l=0,r=m-1;
while(l<r)
{
int mid=(l+r)>>1;
if(t<=sum[mid].s)
r=mid;
else
l=mid+1;
}
if(t==sum[l].s) //或者t==sum[r].s 因为最终l==r
{
cout<<a<<" "<<b<<" "<<sum[r].c<<" "<<sum[r].d<<endl;
return 0;
}
}
}
return 0;
}
(3)1227. 分巧克力

还以为有什么技巧咧,看半天。。就一个暴力做法。。。二分正方形的边长
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e5+10;
int n,k;
int H[N],W[N];
bool check(int t)
{
long long res=0;
for(int i=0;i<n;i++)
{
res+=H[i]/t*(W[i]/t);
if(res>=k)return true;
}
return false;
}
int main()
{
cin>>n>>k;
for(int i=0;i<n;i++)
cin>>H[i]>>W[i];
int l=1,r=1e5;
while(l<r)
{
int mid=(l+r+1)>>1; //为什么+1,这是因为避免死循环,为什么会死循环。博客里面有相关文章
if(check(mid))l=mid;
else
r=mid-1;
}
cout<<l<<endl;
return 0;
}
(4)113. 特殊排序
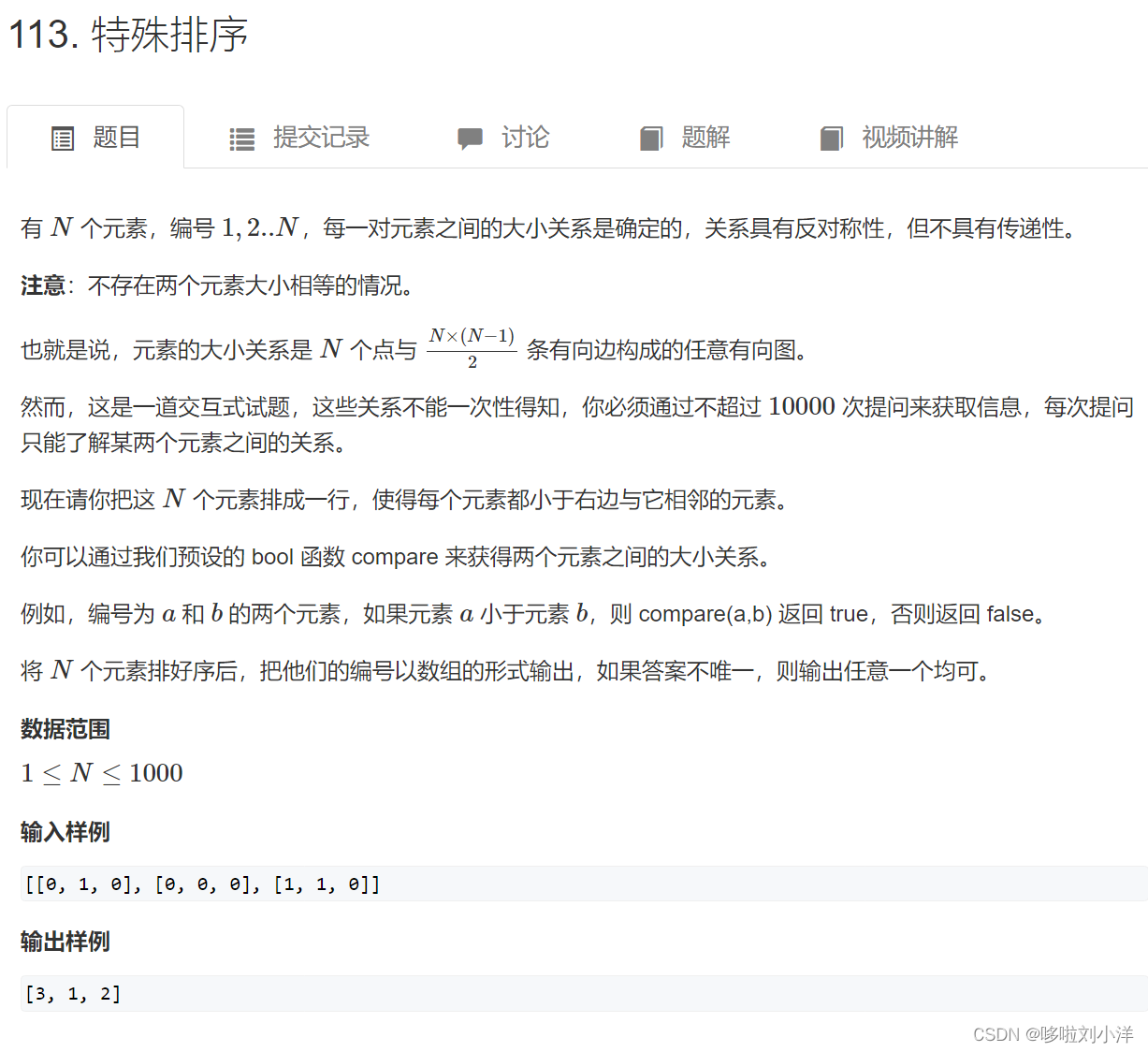
难难难!!!
关键在于对“无序二分”的合理证明。
二分一定是有道理才能的。光看难懂,要仔细体会。不会的小伙伴可以私信,我这个菜鸟看了30分钟才看懂😢
// Forward declaration of compare API.
// bool compare(int a, int b);
// return bool means whether a is less than b.
class Solution
{
public:
vector<int> specialSort(int N)
{
vector<int>res;
res.push_back(1); //使用插入排序+二分,res就是排序主体,开始数组只有1个元素,当然是有序的
for(int i=2;i<=N;i++)
{
//这里规定找到第一个小于i的位置,且该位置后面一个数大于i。然后让i插入到第一个小于i的位置后面的一个位置
//这是合理的.
//如果当前数x比i小,那么i一定可以在x右边放下:如果x右边所有的数都比i小,那么i放在最右端
//如果x右边有一个数比i大,那么i放在该数位置,该数以及后面的数右移。
//所以找到第一个小于i的数且后面大于i的数(也可以没有)即可
//注意,如果没有小于i的数,那么i放在第一位
int l=0,r=res.size()-1;
while(l<r)
{
int mid=(l+r+1)>>1;
if(compare(res[mid],i))l=mid; //如果mid小于i,那么i一定可以插入到mid后面(也可能可以插入到mid左边)
else
r=mid-1;
}
res.push_back(i);
//最后l==r,[l,l+1]分别表示小于i,大于i的数
for(int j=res.size()-2;j>r;j--)
swap(res[j],res[j+1]);
//判断r是否合理。如果i比res[r]小,则和我们假设不符合,那么就只有一种可能,i比所有数都小,自然也比第一个数小,这个时候i只可能是第二个数,那么和第一个数交换位置即可
if(compare(i,res[r]))swap(res[r],res[r+1]);
//也可写 if(compare(res[r+1],res[r])swap(res[r],res[r+1]);
}
return res;
}
};
(5)1460. 我在哪?
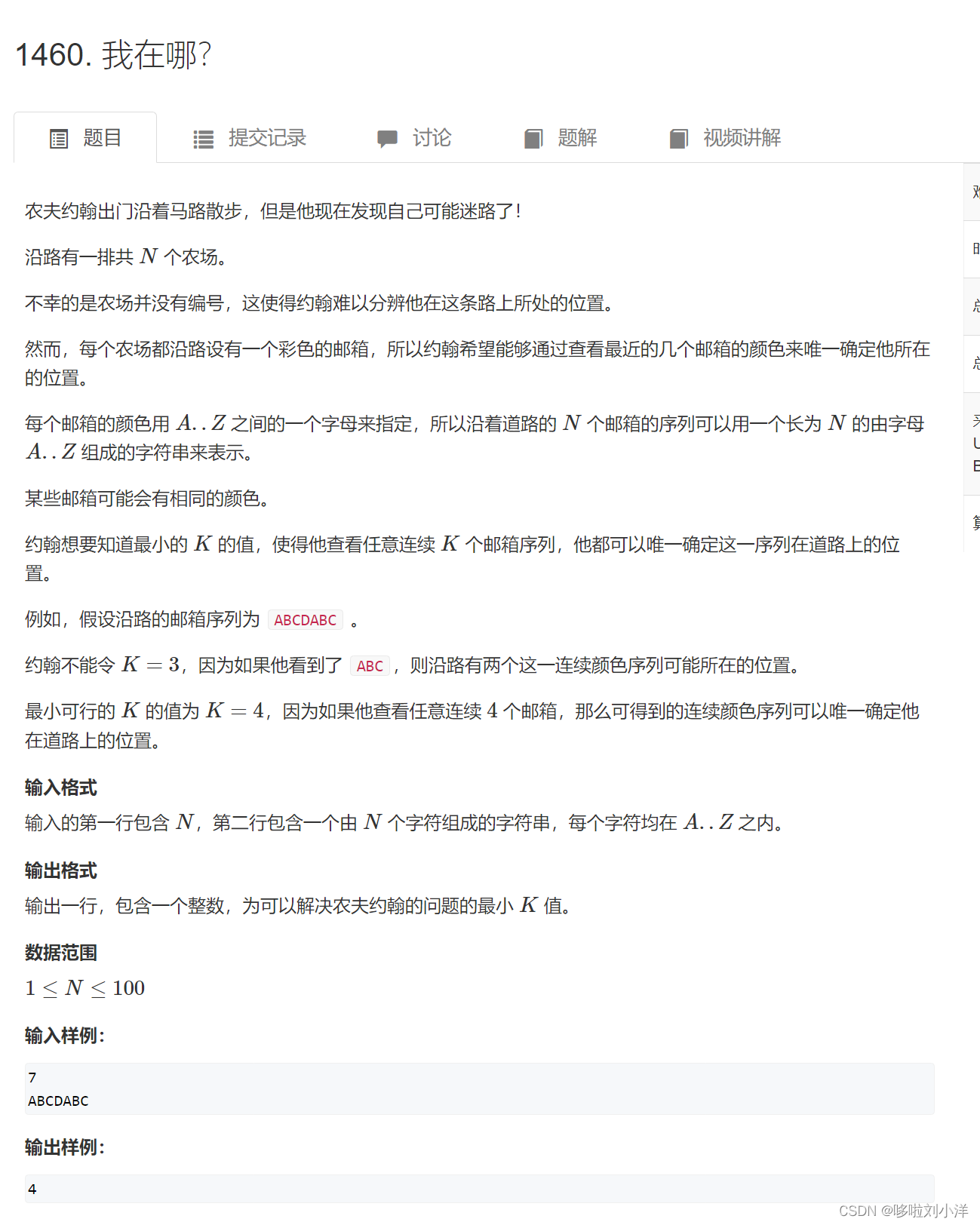
这道题数据很小,可以直接暴力解决。直接枚举所有连续的字符串的组合,找到唯一的那一个,记录下长度即可,非常简单。但是标签是二分,待我去看看题解如何解答。。
//目的找到一个最小长度且没有重复的字符串
#include<iostream>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
const int N=110;
int n;
char str[N];
int res;
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
cin>>str[i];
unordered_map<string,int>Hash;
for(int len=1;len<=n;len++) //枚举长度
{
int cnt=0;
for(int start=1;start+len-1<=n;start++) //枚举起点
{
string temp="";
for(int j=start;j<=start+len-1;j++) //累计枚举区间的字符串
temp+=str[j];
Hash[temp]++;
if(Hash[temp]==1)cnt++;
}
if(cnt==n-len+1) //说明该长度的所有组合都是第一次出现
{
cout<<len<<endl;
return 0;
}
}
return
}
二分还真可以做,需要字符串哈希的我知识,也可以直接用stl
先贴一个代码
#include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_set>
using namespace std;
int n;
string str;
unordered_set<string> S;
bool check(int mid)
{
S.clear();
for (int i = 0; i + mid - 1 < n; i ++ )
{
string s = str.substr(i, mid);
if (S.count(s)) return false;
S.insert(s);
}
return true;
}
int main()
{
cin >> n >> str;
int l = 1, r = n;
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
cout << r << endl;
return 0;
}
2.双指针
(1)1238. 日志统计

双指针的习题:
思路:先给排序,排序规则:帖子编号从小到大,如果帖子编号一样,则给时间从小到大排序
然后用一个l,r指向一个帖子的区间,判断该帖子是否满足要求,然后判断下一个帖子
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 1e5 + 10;
int n, d, k;
int res[N];
int rc=0;
struct node
{
int id;
int ts;
node():id(0),ts(0){}
};
node a[N];
bool cmp(node &a, node& b)
{
if (a.id == b.id)return a.ts < b.ts;
return a.id<b.id;
}
int main()
{
cin >> n >> d >> k;
for (int i = 0; i < n; i++)
cin >> a[i].ts >> a[i].id;
sort(a, a + n, cmp);
// for (int i = 0; i < n; i++)
// {
// cout << a[i].ts << " " << a[i].id << endl;
// }
//对帖子一个个进行判断
//一个指针指向起始时间,一个指向末尾时间
int l=0,r=0; //l,r分别是一个帖子的不同时间(开始时间和截至时间)
int cnt=0;
while(l<n&&r<n)
{
if(a[l].id==a[r].id) //帖子一样
{
if(a[r].ts-a[l].ts+1<=d)
{
cnt++;
r++;
}
else
{
l++;
cnt--;
}
if(cnt==k)
{
res[rc++]=a[l].id;
cnt=0;
int t=a[l].id;
while(a[l].id==t)
l++;
r=l;
}
}
else
{
l=r;
cnt=0;
}
}
for(int i=0;i<rc;i++)
cout<<res[i]<<endl;
return 0;
}
(2)1240. 完全二叉树的权值

思路:
先将每一层的权值算出来,然后用一个变量res记录最大值。因为层数从小到大遍历,遇到大的才更新,所以可以保证第一次遇到的最大值层数最小。
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 100010;
int n;
int a[N];
int main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i ++ ) scanf("%d", &a[i]);
LL maxs = -1e18;
int depth = 0;
for (int d = 1, i = 1; i <= n; i *= 2, d ++ )
{
LL s = 0;
for (int j = i; j < i + (1 << d - 1) && j <= n; j ++ )
s += a[j];
cout<<s<<endl;
if (s > maxs)
{
maxs = s;
depth = d;
}
}
printf("%d\n", depth);
return 0;
}
贴上自己第一次写的代码,说明功底还不够
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long ll;
const int N=1e6+10;
ll a[N];
ll deep[N]; //deep[i]=j表示深度为i的那一层的权值之和为j
int dc=1;
int n;
struct node
{
int d;
ll cnt;
};
node b[N];
bool cmp(node &a,node &b)
{
if(a.cnt==b.cnt)return a.d<b.d;
return a.cnt>b.cnt;
}
void count() //计算每一层的个数
{
int start=0; //一层的开始
int k=1; //一层的个数
while(start<=n) //计算每一层的权值
{
for(int i=start;i<min(n,start+k);i++)
{
deep[dc]+=a[i];
}
start+=k;
k*=2;
dc++;
}
}
int main()
{
cin>>n;
for(int i=0;i<n;i++)
cin>>a[i];
count();
// for(int i=1;i<dc;i++)
// cout<<deep[i]<<" ";
//将每一层的权值之和都算出来就简单了,想怎么做都可以,用一个结构体存下层数和大小,先按大小排序,
//cout<<dc<<endl;
//如果大小一样,就按照层数排序
for(int i=1;i<dc;i++)
{
b[i].d=i;
b[i].cnt=deep[i];
}
sort(b+1,b+dc,cmp);
cout<<b[1].d<<endl;
return 0;
}
(3)字符串删减

思路:
准备工作:
(1)变量ok,遇到x置为true,否则false
(2)left,right指针,left指向第一个遇到的x,right指向最后一个遇到的x
一次遍历即可
#include<iostream>
#include<cstring>
using namespace std;
const int N=110;
int n;
char a[N];
int res=0;
int main()
{
cin>>n;
for(int i=0;i<n;i++)
cin>>a[i];
int l,r;
int sum=0;
bool ok=false;
for(int i=0;i<n;i++)
{
if(a[i]=='x')
{
if(!ok)
{
l=r=i;
sum=1;
ok=true;
}
else
{
r++;
sum++;
}
}
else
{
ok=false;
if(sum>=3)
{
res+=sum-2;
sum=0;
}
}
}
if(sum>=3)res+=sum-2;
cout<<res<<endl;
return 0;
}
(4)799. 最长连续不重复子序列
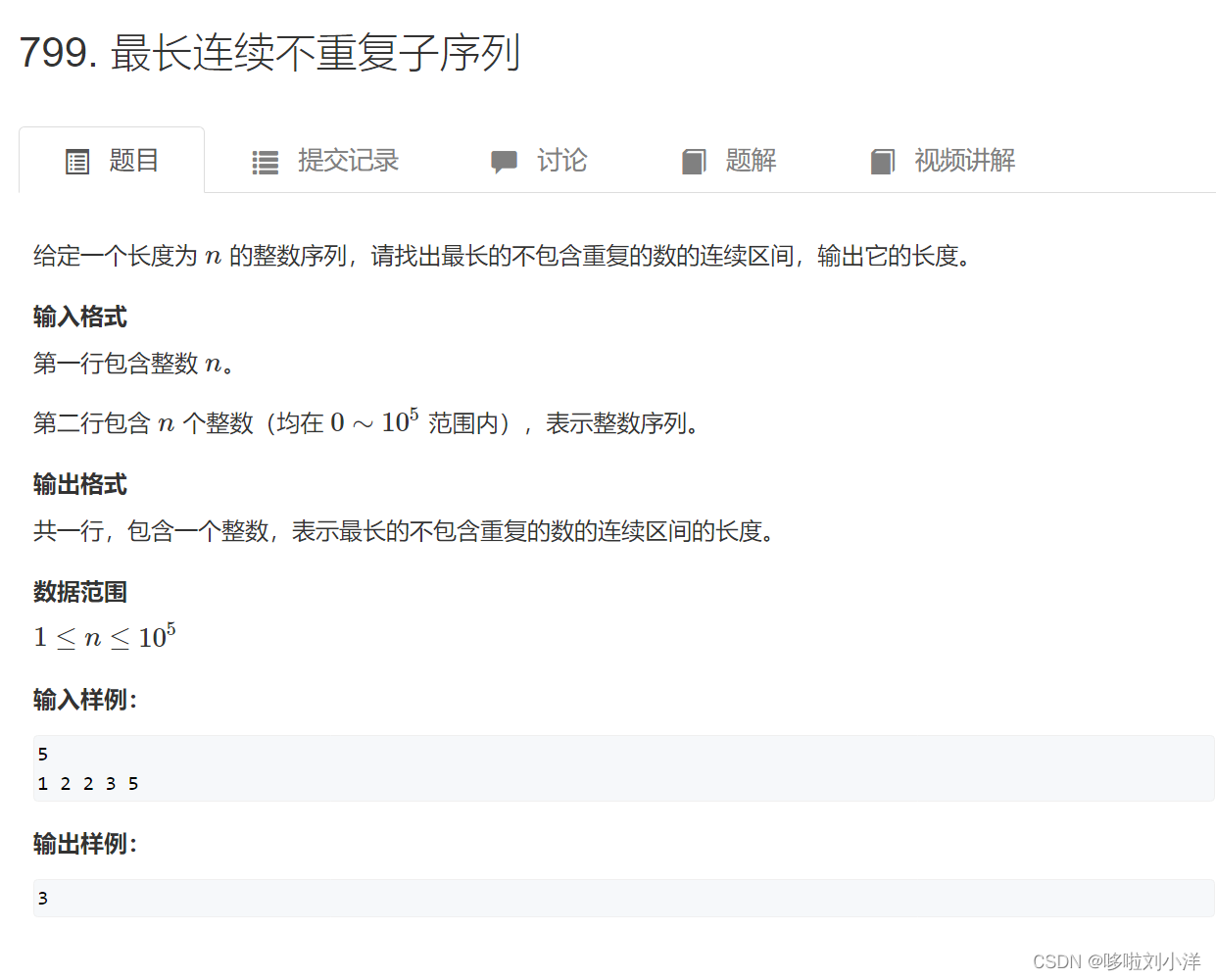
用一个哈希表实时记录出现的元素次数,两个指针指向前后一次遍历即可
#include<iostream>
#include<cstring>
#include<algorithm>
#include<unordered_map>
using namespace std;
const int N = 1e5 + 10;
int a[N];
int n;
int res = 0;
int main()
{
cin >> n;
for (int i = 0; i < n; i++)
cin >> a[i];
unordered_map<int, int>Hash; //哈希表
int l = 0, r = 0;
while (l < n && r < n)
{
if (Hash.count(a[r]) == 0 || Hash[a[r]] == 0)
{
Hash[a[r]] = 1;
r++;
}
else
{
res = max(res, r - l);
while (l < n && a[l] != a[r])
{
Hash[a[l]] = 0;
l++;
}
Hash[a[l]] = 0;
l++;
}
}
res=max(res,r-l); //最后一次判断,以免漏掉
cout << res;
return 0;
}
(5)800. 数组元素的目标和

经典双指针,一前一后。用反证法证明不会漏过答案
#include<iostream>
#include<cstring>
using namespace std;
const int N=1e5+10;
int a[N];
int b[N];
int n,m;
int k;
int main()
{
cin>>n>>m>>k;
for(int i=1;i<=n;i++)
cin>>a[i];
for(int j=1;j<=m;j++)
cin>>b[j];
int l=1,r=m;
bool ok=true;
while(ok)
{
if(a[l]+b[r]>k)
r--;
else if(a[l]+b[r]<k)
l++;
else
ok=false;
}
cout<<l-1<<" "<<r-1<<endl;
return 0;
}
(6)判断子序列
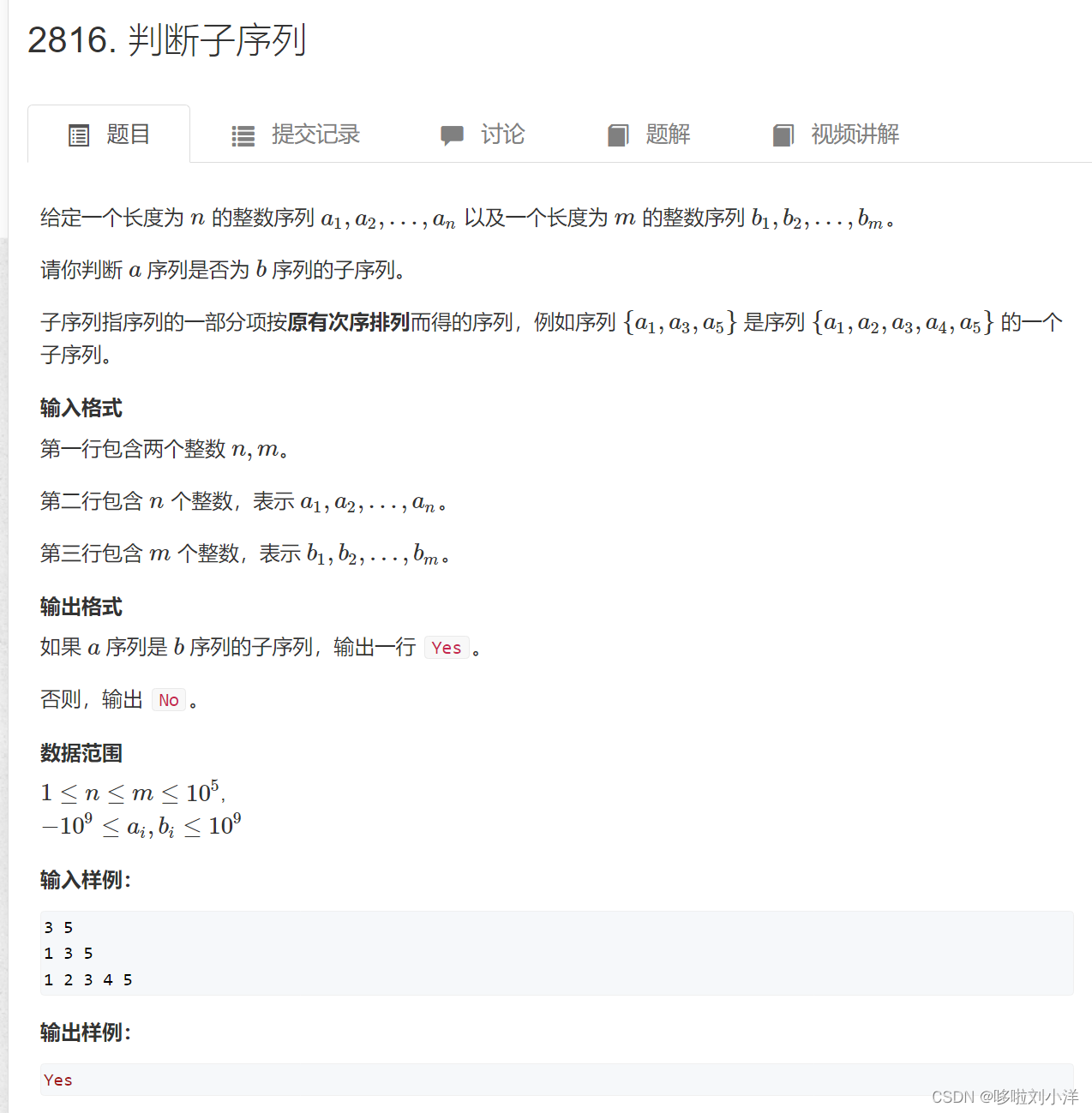
#include<iostream>
#include<cstring>
using namespace std;
const int N=1e5+10;
int n,m;
int a[N],b[N];
int main()
{
cin>>n>>m;
for(int i=0;i<n;i++)
cin>>a[i];
for(int i=0;i<m;i++)
cin>>b[i];
int i,j;
for(i=0,j=0;i<n&&j<m;j++)
{
if(a[i]==b[j])
i++;
}
if(i==n)cout<<"Yes";
else cout<<"No";
return 0;
}