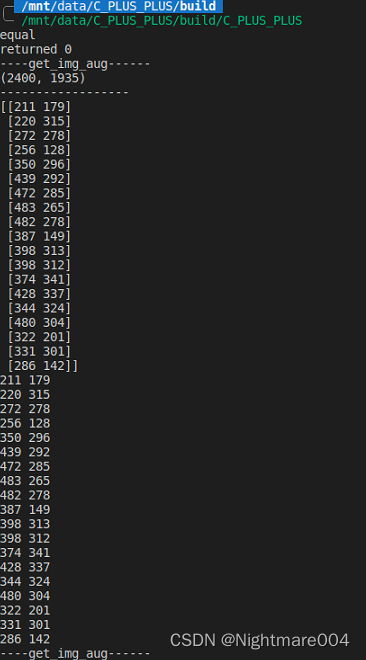
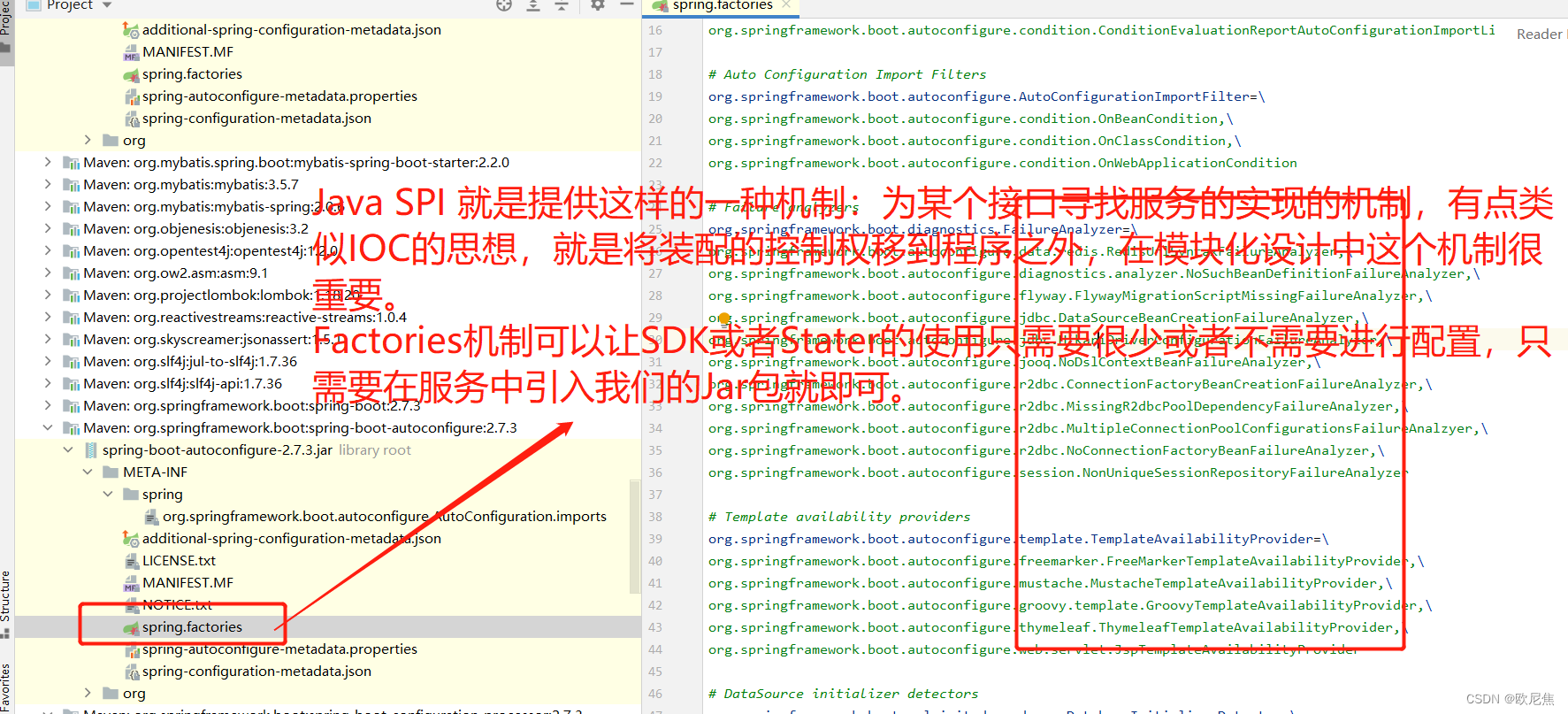
SpanBERT出自Facebook,就是在BERT的基础上,针对预测spans of text的任务,在预训练阶段做了特定的优化,它可以用于span-based pretraining。这里的Span翻译为“片段”,表示一片连续的单词。SpanBERT最常用于需要预测文本片段的任务。SpanBERT: Improving Pre-training by Representing and Predicting Spans
SpanBERT所做的预训练调整主要是以下三点:1.使用一种span masking来代替BERT的mask;2.加入另外一个新的训练目标:Span Boundary Objective (SBO);3.使用单个句子而非一对句子,并且不使用Next Sentence Prediction任务。这样,SpanBERT使用了两个目标函数:MLM和SBO。
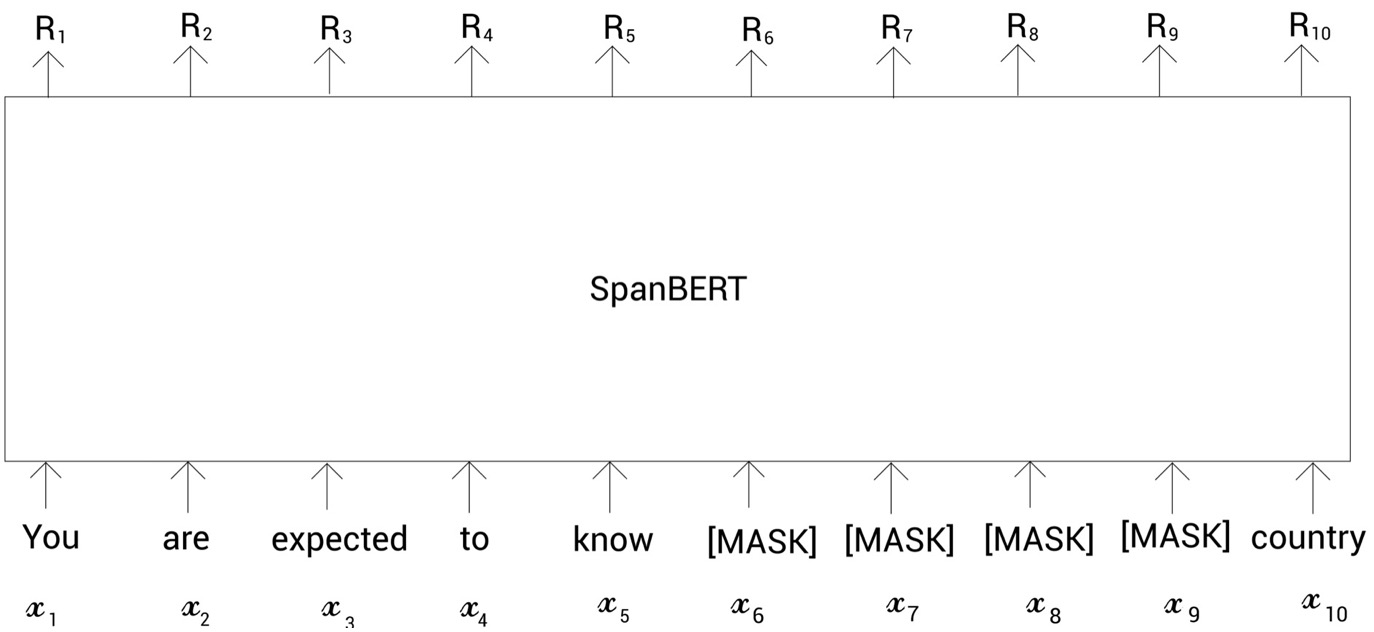
1 Span Masking
给定一个tokens序列 X = ( x1 , x2 , . . . , xn ),每次都会通过采样文本的一个片段(span),得到一个子集 Y ∈ X,直到满足15%的mask。在每次采样过程中,首先,随机选取一个片段长度,然后再随机选取一个起点,这样就可以到一个span进行mask了;span的长度会进行截断,即不超过10,并且实验得到p取0.2效果最好;
另外,span的长度是指word的长度,而不是subword,这也意味着采样的单位是word而非subword,并且随取的起点必须是一个word的开头。
与BERT一样,mask机制仍然为:80%替换为[MASK],10%保持不变,10%用随机的token替换。但不用的是,span masking是span级别的,即同一个span里的所有tokens会是同一种mask。
举例说明:
在SpanBERT中,不是对标记进行随机掩码,而是对连续片段进行掩码.

2 Span Boundary Objective
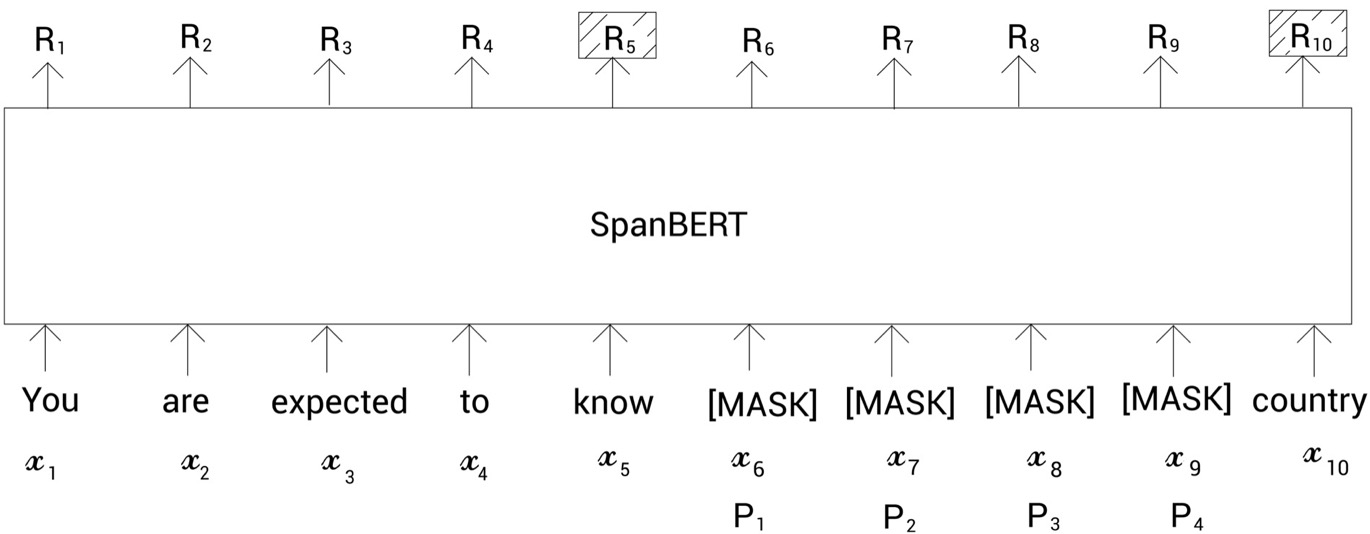
这个新增的预训练任务概括起来其实就是:仅使用span边界的tokens的表征,来预测该span内的这些mask的tokens原来对应哪些tokens,这其实与mlm类似,但它不使用上下文的所有tokens的表征。对masked span中的整体内容进行预测。
如果模型只使用片段边界标记表示来预测任何掩码的标记,那它是如何区分不同的被掩码的标记呢?比如,为了预测掩码的标记,我们的模型只使用片段边界标记表示
和
,然后为了预测掩码的标记
,我们的模型还是使用
和
。那这样的话,模型如何区别不同的掩码标记呢?因此,除了片段边界标记表示,模型还使用掩码标记的位置嵌入信息。这里的位置嵌入代表了掩码标记的相对位置。假设我们要预测掩码标记
。现在,在所有的掩码标记中,我们检查掩码标记
的位置。
如下图所示,掩码标记是所有掩码标记的第二个位置。所以现在,除了使用片段边界标记表示,我们也使用该掩码标记的位置嵌入,即
。通过外边界tokens的表征【R5】、【R10】和
相对位置embedding,用它去预测token
,与BERT中的MLM任务一样。
计算公式如下所示:
其中s表示span的起始位置,s-1表示的是span的左侧边界token;e表示的是span的结束位置,e+1表示的是span的右侧边界token,p表示的是位置信息。
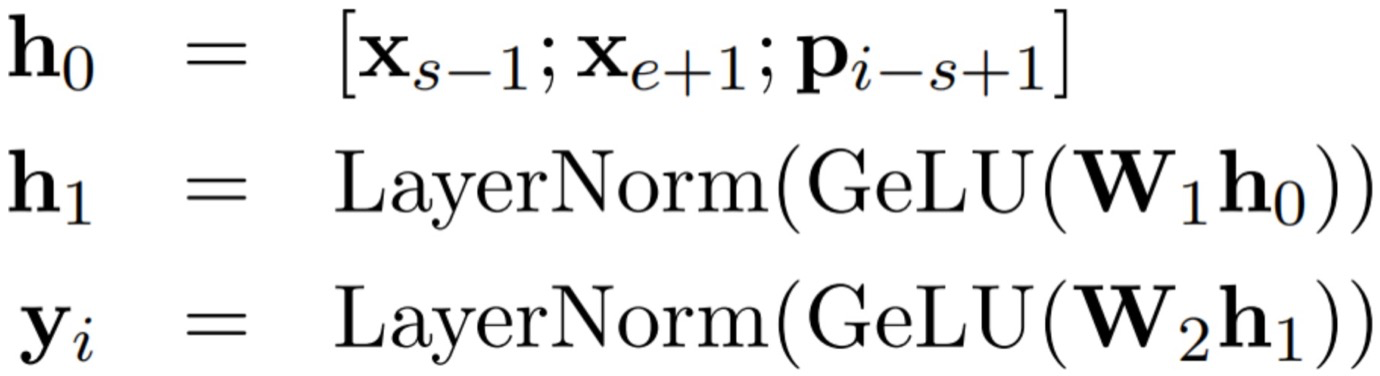
使用预测掩码标记
,训练过程中,将
喂给一个分类器,它返回预测的词表中所有单词的概率分布。
在MLM目标中,为了预测掩码标记,我们只要使用标记标记
即可。将
喂给一个分类器,它返回预测的词表中所有单词的概率分布。
SpanBERT的损失函数是MLM损失和SBO损失的总和。我们通过最小化这个损失函数来训练SpanBERT。在预训练之后,我们可以把预训练的SpanBERT用于任何下游任务。
3 Single-Sequence Training
BERT中包含着一个next sentence prediction的任务,这个任务的input是两个text的序列 , 预测二者是否是上下文。作者通过实验发现,这样的一种设置会比去掉NSP objective而只使用一个sequence的效果要差。因而作者猜测,single-sequence training比bi-sequence training+NSP的效果要好,分析原因如下:
- 模型能够从更长的full-length contexts中受益更多;
- 以从另外一个document中得到的context为条件,往往会给masked language model中添加许多noise。
因此,作者去掉了NSP objective以及two-segment sampling procedure,并仅仅采样出一个单独的continuous segment(这个segment中至多有512个tokens)。
Reference:
https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2
https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2