链表
| 题目 | 题型 |
|---|---|
| 203. 移除链表元素 - 力扣(LeetCode) | 辅助头节点解决移出head问题 |
| 707. 设计链表 - 力扣(LeetCode) | 辅助头节点 |
| 206. 反转链表 - 力扣(LeetCode) | 迭代 / 递归 |
| 19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode) | 辅助头节点、双指针先后顺序 |
| 面试题 02.07. 链表相交 - 力扣(LeetCode) | 双指针、技巧—遍历完A继续遍历B |
| 142. 环形链表 II - 力扣(LeetCode) | 快慢指针 |
| 24. 两两交换链表中的节点 - 力扣(LeetCode) | 反转链表的迭代 + 递归 |
-
203. 移除链表元素 - 力扣(LeetCode)
设置一个新的头节点指向链表头节点。
class Solution { public ListNode removeElements(ListNode head, int val) { ListNode newhead = new ListNode(-1); newhead.next = head; ListNode temp = newhead; while(temp!= null && temp.next != null){ if(temp.next.val == val){ temp.next = temp.next.next; }else{ temp = temp.next; } } return newhead.next; } } -
707. 设计链表 - 力扣(LeetCode)
添加size,表示当前链表长度。
//单链表 class ListNode { int val; ListNode next; ListNode(){} ListNode(int val) { this.val=val; } } class MyLinkedList { int size; ListNode head; //初始化链表 public MyLinkedList() { size = 0; head = new ListNode(0); } //获取第index个节点的数值,注意index是从0开始的,第0个节点就是头结点 public int get(int index) { //如果index非法,返回-1 if (index < 0 || index >= size) { return -1; } ListNode currentNode = head; //包含一个虚拟头节点,所以查找第 index+1 个节点 for (int i = 0; i <= index; i++) { currentNode = currentNode.next; } return currentNode.val; } //在链表最前面插入一个节点,等价于在第0个元素前添加 public void addAtHead(int val) { addAtIndex(0, val); } //在链表的最后插入一个节点,等价于在(末尾+1)个元素前添加 public void addAtTail(int val) { addAtIndex(size, val); } public void addAtIndex(int index, int val) { if (index > size) { return; } if (index < 0) { index = 0; } size++; //找到要插入节点的前驱 ListNode pred = head; for (int i = 0; i < index; i++) { pred = pred.next; } ListNode toAdd = new ListNode(val); toAdd.next = pred.next; pred.next = toAdd; } //删除第index个节点 public void deleteAtIndex(int index) { if (index < 0 || index >= size) { return; } size--; if (index == 0) { head = head.next; return; } ListNode pred = head; for (int i = 0; i < index ; i++) { pred = pred.next; } pred.next = pred.next.next; } } -
206. 反转链表 - 力扣(LeetCode)
法一:递归解法:
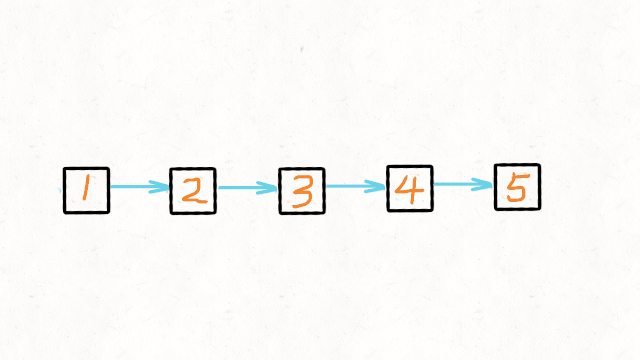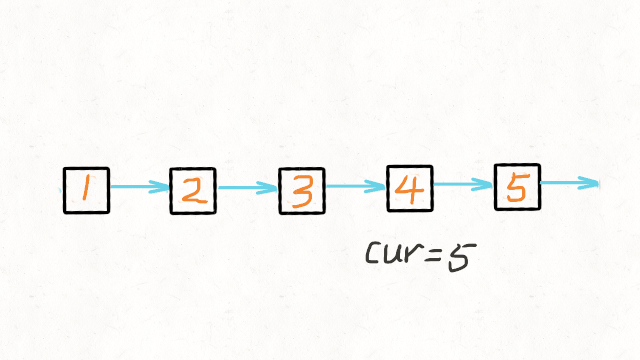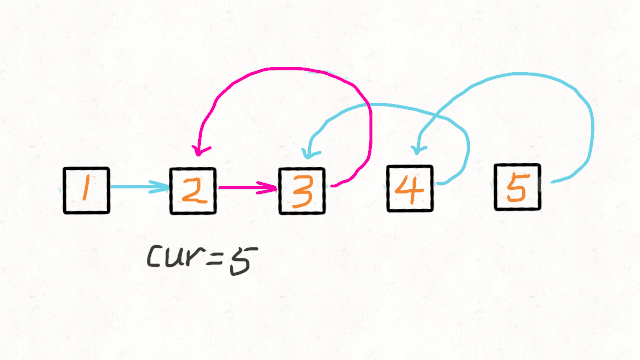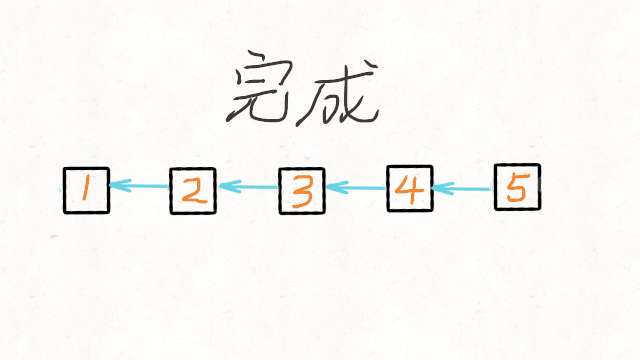
//反转链表递归解法 class Solution { public ListNode reverseList(ListNode head) { //递归终止条件是当前为空,或者下一个节点为空 if(head==null || head.next==null) { return head; } //这里的cur就是最后一个节点 ListNode cur = reverseList(head.next); //这里请配合动画演示理解 //如果链表是 1->2->3->4->5,那么此时的cur就是5 //而head是4,head的下一个是5,下下一个是空 //所以head.next.next 就是5->4 head.next.next = head; //防止链表循环,需要将head.next设置为空 head.next = null; //每层递归函数都返回cur,也就是最后一个节点 return cur; } }法二:迭代法,提前保存nextNode,即使temp指针变向,也可以往下遍历。使用last保存前一个节点。
class Solution { public ListNode reverseList(ListNode head) { ListNode last = null; ListNode temp = head; while(temp != null){ ListNode nextNode = temp.next; temp.next = last; last = temp; temp = nextNode; } return last; } } -
19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode)
先让p1走k步。
再让p1和p2同时走,当
p1 == null时,p2也走到了倒数第k个节点。最后删除p2所在节点即可。
删除p2节点,我们需要p2的前一个节点,也就是p2_pre。
class Solution { public ListNode removeNthFromEnd(ListNode head, int n) { ListNode node = new ListNode(0,head); ListNode p1 = node; while(n > 0){ n --; p1 = p1.next; } ListNode p2 = node; while(p1.next != null){ p1 = p1.next; p2 = p2.next; } p2.next = p2.next.next; return node.next; } }法二:直接找倒数第k个节点
class Solution { public ListNode removeNthFromEnd(ListNode head, int n) { ListNode newhead = new ListNode(-1); newhead.next = head; if(head.next == null){ return null; } int count = -1; ListNode temp = newhead; while(temp != null){ temp = temp.next; count ++; } // System.out.println(count); int k = count - n - 1; ListNode l = newhead; while(k >= 0){ k--; l = l.next; } if(l.next != null){ l.next = l.next.next; } return newhead.next; } } -
面试题 02.07. 链表相交 - 力扣(LeetCode)
public class Solution { public ListNode getIntersectionNode(ListNode headA, ListNode headB) { ListNode p1 = headA; ListNode p2 = headB; while(p1 != p2){ if(p1 == null){ p1 = headB; }else{ p1 = p1.next; } if(p2 == null){ p2 = headA; }else{ p2 = p2.next; } } return p1; } } -
142. 环形链表 II - 力扣(LeetCode)
快慢指针技巧,fast指针走两步,slow指针走一步。当快慢指针相遇时,让其中一个指针指向头节点,此时在同步移动两个指针。等两个指针再次相遇,则说明找到环形起点。
public class Solution { public ListNode detectCycle(ListNode head) { ListNode fast = head; ListNode slow = head; while(true){ if(fast == null || fast.next == null) return null; fast = fast.next.next; slow = slow.next; if(fast == slow){ fast = head; break; } } while(fast != slow){ fast = fast.next; slow = slow.next; } return fast; } } -
24. 两两交换链表中的节点 - 力扣(LeetCode)
图:
- 2—>1,调用了反转链表函数:
ListNode newhead = reverse(a,b); - 1—>newHead调用自身的函数:
a.next = reverseKGroup(b,k);
最终实现的结果如下:
几个一组,就把k改为几。
class Solution { public ListNode swapPairs(ListNode head) { //a节点为当前组头节点,b节点为下一组的头节点。 ListNode a = head , b = head; for(int i = 0 ; i < k ; i++){ if(b == null) return head; b = b.next; } //获取下一组的新头节点。 ListNode newhead = reverse(a,b); //a的下一个节点指向下一组的新头节点。 a.next = swapPairs(b); return newhead; } //反转当前组,返回下一组的新的头节点,即反转链表的逻辑。 public ListNode reverse(ListNode a,ListNode b){ ListNode temp = a; ListNode last = null; while(temp != b){ ListNode newhead = temp.next; //先把当前节点向前指。 temp.next = last; //前驱节点换到当前节点。 last = temp; //往下遍历节点。 temp = newhead; } return last; } } - 2—>1,调用了反转链表函数:
CPU是如何执行程序的?
-
冯诺依曼模型
冯诺依曼模型定义了计算机基本结构:运算器、控制器、存储器(内存)、输入输出设备。
图:存储单元、输入输出设备、CPU之间的关系。
-
内存
我们的程序和数据都是存储在内存,存储的区域是线性的。
在计算机数据存储中,存储数据的基本单位是字节(*byte*),1 字节等于 8 位(8 bit)。每一个字节都对应一个内存地址。
-
中央处理器(CPU)
-
中央处理器也就是我们常说的 CPU,32 位和 64 位 CPU 最主要区别在于一次能计算多少字节数据:
- 32 位 CPU 一次可以计算 4 个字节;
- 64 位 CPU 一次可以计算 8 个字节;
-
CPU内部还有一些组件,常见的有寄存器,控制单元和逻辑运算单元
-
控制单元:负责控制CPU的工作。
-
逻辑运算单元:负责运算。
-
寄存器:相当于内存,但是在CPU内部,计算速度更快。寄存器有以下几种:
- 通用寄存器:存放需要运算的数据。
- 程序计数器:存储CPU要执行的下一条指令的地址。
- 指令寄存器:存放当前正在执行的指令。
-
-
-
总线
负责各种设备之间的通信。CPU读取内存数据时,要通过三个总线
- 先通过地址总线来指定内存的地址。
- 再通过控制总线来指定读或写的命令。
- 最后通过数据总线来传递数据。
-
线路位宽与CPU位宽
-
线路位宽
CPU 想要操作「内存地址」就需要「地址总线」:
- 如果地址总线只有 1 条,那每次只能表示 「0 或 1」这两种地址,所以 CPU 能操作的内存地址最大数量为 2(2^1)个(注意,不要理解成同时能操作 2 个内存地址);
- 如果地址总线有 2 条,那么能表示 00、01、10、11 这四种地址,所以 CPU 能操作的内存地址最大数量为 4(2^2)个。
那么,想要 CPU 操作 4G 大的内存,那么就需要 32 条地址总线,因为
2 ^ 32 = 4G。(32位对应有232个地址,对应的内存数是232 * 8bit=4Gbyte即4GB) -
CPU位宽
- CPU 的位宽最好不要小于线路位宽,否则工作起来会非常复杂且麻烦。如果用 32 位 CPU 去加和两个 64 位大小的数字,不能一次性计算出结果。但是64 位 CPU 就可以一次性算出加和两个 64 位数字的结果,因为 64 位 CPU 可以一次读入 64 位的数字,并且 64 位 CPU 内部的逻辑运算单元也支持 64 位数字的计算。
-
但是并不代表 64 位 CPU 性能比 32 位 CPU 高很多,很少应用需要算超过 32 位的数字,所以如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别的,只有当计算超过 32 位数字的情况下,64 位的优势才能体现出来。
-
另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为
2^64。
-
-
程序执行的基本过程
-
一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后程序计数器根据指令长度自增,开始顺序读取下一条指令。
- 程序计数器自增的长度与CPU位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
- CPU还会分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
-
CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 CPU 的指令周期
-
-
1GHz表示该CPU的时钟频率是1G,表示1秒会发出1G次数的脉冲信号,每一次脉冲信号的高低电平就是一个时钟周期。时钟周期时间越短,CPU运算的越快。
-
在内存中,数据段与正文段是分开的。
图:数据段:存放数据;正文段:存放指令。
磁盘比内存慢几倍?
-
我们大脑正在思考的东西,就好比CPU中的寄存器,处理速度最快,但是能存储的数据也最少。
-
我们大脑中的记忆,就好比CPU Cache,中文称为 CPU 高速缓存,处理速度相比寄存器慢了一点,但是能存储的数据也稍微多了一些。
- CPU Cache 通常会分为 L1、L2、L3 三层,其中 L1 Cache 通常分成「数据缓存」和「指令缓存」,L1 是距离 CPU 最近的,因此它比 L2、L3 的读写速度都快、存储空间都小。我们大脑中短期记忆,就好比 L1 Cache,而长期记忆就好比 L2/L3 Cache。
-
当我们大脑记忆中没有资料的时候,可以从书桌或书架上拿书来阅读,那我们桌子上的书,就好比内存,我们虽然可以一伸手就可以拿到,但读写速度肯定远慢于寄存器。
-
图书馆书架上的书,就好比硬盘,能存储的数据非常大,但是读写速度相比内存差好几个数量级,更别说跟寄存器的差距了。
-
寄存器
最靠近 CPU 的控制单元和逻辑计算单元的存储器,就是寄存器了,它使用的材料速度也是最快的,因此价格也是最贵的,那么数量不能很多。
寄存器的数量通常在几十到几百之间,每个寄存器可以用来存储一定的字节(byte)的数据。比如:
- 32 位 CPU 中大多数寄存器可以存储
4个字节; - 64 位 CPU 中大多数寄存器可以存储
8个字节。
寄存器的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写,CPU 时钟周期跟 CPU 主频息息相关,比如 2 GHz 主频的 CPU,那么它的时钟周期就是 1/2G,也就是 0.5ns(纳秒)。
- 32 位 CPU 中大多数寄存器可以存储
-
CPU Cache
CPU Cache 用的是一种叫 SRAM(Static Random-Access Memory,静态随机存储器) 的芯片。
SRAM 之所以叫「静态」存储器,是因为只要有电,数据就可以保持存在,而一旦断电,数据就会丢失了。
在 SRAM 里面,一个 bit 的数据,通常需要 6 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间下,能存储的数据是有限的,不过也因为 SRAM 的电路简单,所以访问速度非常快。
CPU 的高速缓存,通常可以分为 L1、L2、L3 这样的三层高速缓存,也称为一级缓存、二级缓存、三级缓存。
-
L1 高速缓存
-
L1 高速缓存的访问速度几乎和寄存器一样快,通常只需要
2~4个时钟周期,而大小在几十 KB 到几百 KB 不等。 -
每个 CPU 核心都有一块属于自己的 L1 高速缓存,指令和数据在 L1 是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存。
-
-
L2 高速缓存
- L2 高速缓存同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB不等,访问速度则更慢,速度在
10~20个时钟周期。
- L2 高速缓存同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB不等,访问速度则更慢,速度在
-
L3 高速缓存
- L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等,具体值根据 CPU 型号而定。访问速度相对也比较慢一些,访问速度在
20~60个时钟周期。
- L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等,具体值根据 CPU 型号而定。访问速度相对也比较慢一些,访问速度在
-
内存
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。
DRAM 存储一个 bit 数据,只需要一个晶体管和一个电容就能存储,但是因为数据会被存储在电容里,电容会不断漏电,所以需要「定时刷新」电容,才能保证数据不会被丢失,这就是 DRAM 之所以被称为「动态」存储器的原因,只有不断刷新,数据才能被存储起来。
DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问的速度会更慢,内存速度大概在
200~300个 时钟周期之间。 -
SSD/HDD硬盘
SSD(Solid-state disk) 就是我们常说的固体硬盘,结构和内存类似,但是它相比内存的优点是断电后数据还是存在的,而内存、寄存器、高速缓存断电后数据都会丢失。内存的读写速度比 SSD 大概快
10~1000倍。当然,还有一款传统的硬盘,也就是机械硬盘(Hard Disk Drive, HDD),它是通过物理读写的方式来访问数据的,因此它访问速度是非常慢的,它的速度比内存慢
10W倍左右。由于 SSD 的价格快接近机械硬盘了,因此机械硬盘已经逐渐被 SSD 替代了。
-
存储器的层次关系
CPU 并不会直接和每一种存储器设备直接打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。
比如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,CPU Cache 不会直接把数据写到硬盘,也不会直接从硬盘加载数据,而是先加载到内存,再从内存加载到 CPU Cache 中。
另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据。
-
存储器之间的实际价格和性能差距
CPU L1 Cache 随机访问延时是 1 纳秒,内存则是 100 纳秒,所以 CPU L1 Cache 比内存快
100倍左右。SSD 随机访问延时是 150 微秒,所以 CPU L1 Cache 比 SSD 快
150000倍左右。最慢的机械硬盘随机访问延时已经高达 10 毫秒,我们来看看机械硬盘到底有多「龟速」:
- SSD 比机械硬盘快 70 倍左右;
- 内存比机械硬盘快 100000 倍左右;
- CPU L1 Cache 比机械硬盘快 10000000 倍左右;
不同的存储器之间性能差距很大,构造存储器分级很有意义,分级的目的是要构造缓存体系。
如何写出让CPU跑的更快的代码?
-
Cache组成
- CPU Cache 是由很多个 Cache Line 组成的,Cache Line (缓存块)是 CPU 从内存读取数据的基本单位,而 Cache Line 是由各种标志(Tag)+ 数据块(Data Block)组成。
-
Cache访问机制
- CPU 读取数据的时候,无论数据是否存放到 Cache 中,CPU 都是先访问 Cache,只有当 Cache 中找不到数据时,才会去访问内存,并把内存中的数据读入到 Cache 中,CPU 再从 CPU Cache 读取数据。
- 这样的访问机制,跟我们使用「内存作为硬盘的缓存」的逻辑是一样的,如果内存有缓存的数据,则直接返回,否则要访问龟速一般的硬盘。
-
直接映射
-
CPU访问内存是以块来读取的,在CPU中,这一块的数据称为Cache Line,在内存中,这一块的数据称为内存块。
-
对于直接映射 Cache 采用的策略,就是把内存块的地址始终「映射」在一个 CPU Cache Line(缓存块) 的地址,至于映射关系实现方式,则是使用「取模运算」,取模运算的结果就是内存块地址对应的 CPU Cache Line(缓存块) 的地址。
-
-
Cache Line 结构
- 为了区分不同的内存块,在对应的CPU Cache LIne中会存储一个组标记(Tag),用来记录当前CPU Cache Line 中存储的数据对应的内存块,区分不同的内存块。
- 从内存加载过来的数据(Data)。
- 标记对应Cache Line 中数据是否有效的有效位(Valid bit)。
-
一个内存访问地址的信息
- 一个内存的访问地址,包括组标记、CPU Cache Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。而对于 CPU Cache 里的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成。
-
CPU访问内存地址经历的四个步骤
-
根据内存地址中索引信息,计算在 CPU Cache 中的索引,也就是找出对应的 CPU Cache Line 的地址;
-
找到对应 CPU Cache Line 后,判断 CPU Cache Line 中的有效位,确认 CPU Cache Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
-
对比内存地址中组标记和 CPU Cache Line 中的组标记,确认 CPU Cache Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行;
-
根据内存地址中偏移量信息,从 CPU Cache Line 的数据块中,读取对应的字。
CPU 在从 CPU Cache 读取数据的时候,并不是读取 CPU Cache Line 中的整个数据块,而是读取 CPU 所需要的一个数据片段,这样的数据统称为一个字(*Word*)。
-
-
写出让CPU跑得更快的程序
-
如果 CPU 所要操作的数据在 CPU Cache 中的话,这样将会带来很大的性能提升。 L1 Cache 通常分为「数据缓存」和「指令缓存」,这是因为 CPU 会分别处理数据和指令,因此,我们要分开来看「数据缓存」和「指令缓存」的缓存命中率
-
提升数据缓存的命中率
CPU会一次从内存中加载多少元素到 CPU Cache ,可以在Linux 里通过
coherency_line_size配置查看 它的大小,通常是 64 个字节。如果遇到遍历数组之类的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升。
-
提升指令缓存的命中率
使用显示分支预测工具,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
-
提升多核CPU的缓存命中率
L2 Cache和L1 Cache 是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,可以把线程绑定到某一个CPU核心上。
在 Linux 上提供了
sched_setaffinity方法,来实现将线程绑定到某个 CPU 核心这一功能。
-
数据类型篇
String
-
String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value其实不仅是字符串, 也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是
512M。 -
内部实现
String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)。
-
SDS 相比于 C 的原生字符串:
-
SDS 是二进制安全的。不会像C字符串碰到结束字符就停止读取。
-
SDS 获取字符串长度的时间复杂度是 O(1)。SDS 结构里用
len属性记录了字符串长度,所以复杂度为O(1)。 -
Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。
-
-
字符串对象的内部编码(encoding)有 3 种 :int、raw和 embstr。
- 如果一个字符串对象保存的是整数值,并且这个整数值可以用
long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成 long),并将字符串对象的编码设置为int。 - 如果字符串对象保存的是一个字符串,并且这个字符申的长度小于等于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为
embstr。 - 如果字符串对象保存的是一个字符串,并且这个字符串的长度大于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为
raw: - embstr和raw
embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次;- 释放
embstr编码的字符串对象同样只需要调用一次内存释放函数; - 因为
embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。 - 缺点:embstr编码的字符串对象是只读的如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间。当我们对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。
- 如果一个字符串对象保存的是整数值,并且这个整数值可以用
-
应用场景
缓存对象:使用
SET user:1 '{"name":"xiaolin", "age":18}'。常规计数:
SET aritcle:readcount:1001 0之后INCR aritcle:readcount:1001分布式锁:
SET lock_key unique_value NX PX 10000- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
- 解锁过程有两步操作,检查是否为加锁客户端,之后解锁(将lock_key删除)。要使用Lua脚本。
共享session信息:使用session保存用户状态,使得同一个用户即使访问不同服务器都是同一个session,不需要重复登录。
List
-
List 列表是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。列表的最大长度为
2^32 - 1,也即每个列表支持超过40 亿个元素。 -
内部实现
List 类型的底层数据结构是由双向链表或压缩列表实现的:
- 如果列表的元素个数小于
512个(默认值,可由list-max-ziplist-entries配置),列表每个元素的值都小于64字节(默认值,可由list-max-ziplist-value配置),Redis 会使用压缩列表作为 List 类型的底层数据结构; - 如果列表的元素不满足上面的条件,Redis 会使用双向链表作为 List 类型的底层数据结构;
但是在 Redis 3.2 版本之后,List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表。
- 如果列表的元素个数小于
-
应用场景
消息队列:消息队列在存取消息时,必须要满足三个需求,分别是消息保序、处理重复的消息和保证消息可靠性。
-
消息保序:List 本身就是按先进先出的顺序对数据进行存取的,所以,如果使用 List 作为消息队列保存消息的话,就已经能满足消息保序的需求了。List 可以使用 LPUSH + RPOP (或者反过来,RPUSH+LPOP)命令实现消息队列。
Redis提供了 BRPOP 命令,替换RPOP命令。BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。和消费者程序自己不停地调用RPOP命令相比,这种方式能节省CPU开销。
-
重复消息处理: List 并不会为每个消息生成 ID 号,所以我们需要自行为每个消息生成一个全局唯一ID,生成之后,我们在用 LPUSH 命令把消息插入 List 时,需要在消息中包含这个全局唯一 ID。
消费者要记录已经处理过的消息的 ID。当收到一条消息后,消费者程序就可以对比收到的消息 ID 和记录的已处理过的消息 ID,来判断当前收到的消息有没有经过处理。如果已经处理过,那么,消费者程序就不再进行处理了。
-
保证消息可靠性:为了留存消息,List 类型提供了
BRPOPLPUSH命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存。
总结:
- 消息保序:使用 LPUSH + RPOP;
- 阻塞读取:使用 BRPOP;
- 重复消息处理:生产者自行实现全局唯一 ID;
- 消息的可靠性:使用 BRPOPLPUSH
List作为消息队列的缺点:
List 不支持多个消费者消费同一条消息,因为一旦消费者拉取一条消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费。
要实现一条消息可以被多个消费者消费,那么就要将多个消费者组成一个消费组,使得多个消费者可以消费同一条消息,但是 List 类型并不支持消费组的实现。Redis 从 5.0 版本开始提供的 Stream 数据类型了,Stream 同样能够满足消息队列的三大需求,而且它还支持「消费组」形式的消息读取。
-
Hash
Hash 是一个键值对(key - value)集合,其中 value 的形式如: value=[{field1,value1},...{fieldN,valueN}]。Hash 特别适合用于存储对象。
-
内部实现
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
- 如果哈希类型元素个数小于
512个(默认值,可由hash-max-ziplist-entries配置),所有值小于64字节(默认值,可由hash-max-ziplist-value配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构; - 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的 底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
- 如果哈希类型元素个数小于
-
应用场景
缓存对象:一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。比如购物车。