文章目录
- 线程的基础概念
- 线程控制
- 内核LWP和线程ID的关系
线程的基础概念
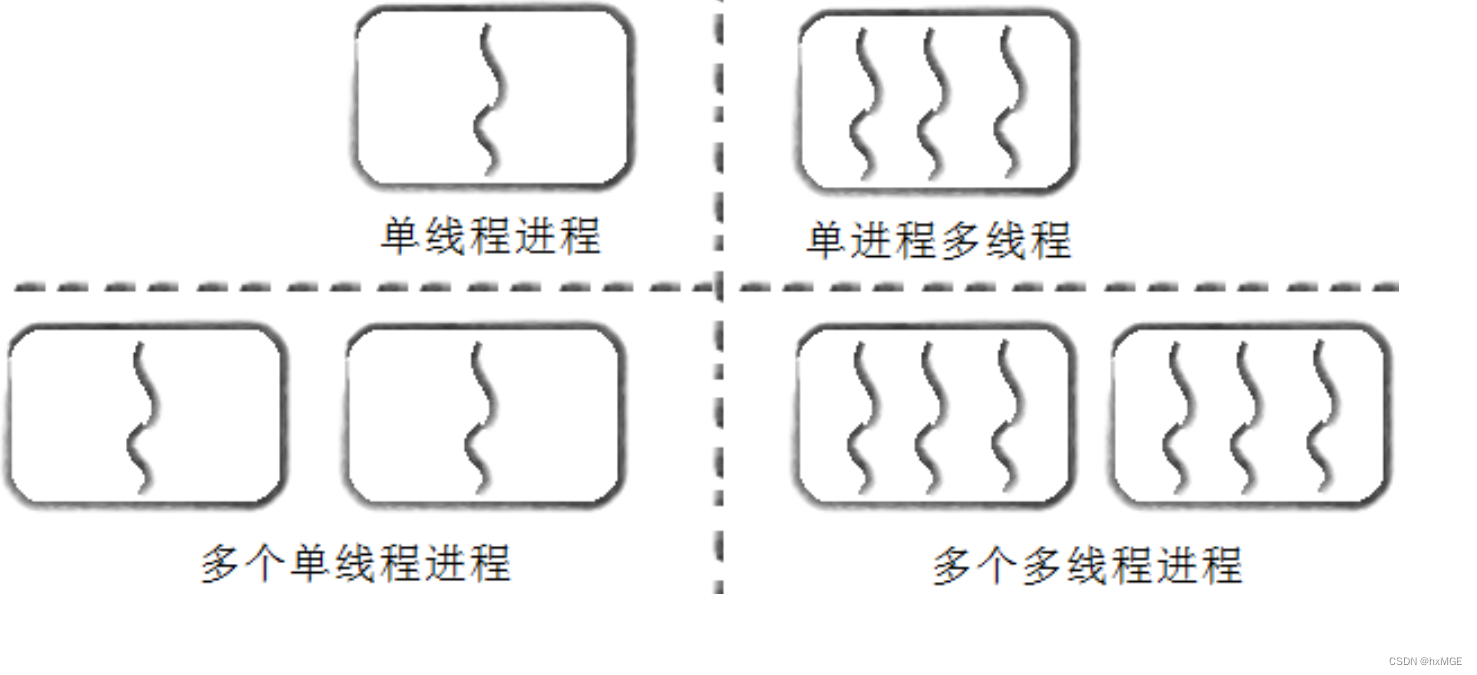
一般教材对线程描述是:是在进程内部运行的一个分支(执行流),属于进程的一部分,粒度要比进程更加细和轻量化
一个进程中是可能存在多个线程的,可能是1:1也可能是1:n,所以线程也应由OS管理,管理就离不开“先描述,再组织”,所以线程也应该类似PCB一样有线程控制块TCB,但Linux中没有专门为线程设计的TCB,而是用进程PCB来模拟线程
通过某些函数方法,可以在同一个进程中只创建task_struct,让这些PCB共享同一个地址空间,把当前进程的资源(代码+数据)划分成若干份,让每个PCB使用执行一部分。
站在CPU的角度,CPU只看PCB,不关心是否共享一份地址空间,此时CPU看到的PCB就是一个需要被调度的执行流
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ovbkmZxa-1677869543495)(G:\Typora\图片保存\image-20221222011520050.png)]](https://img-blog.csdnimg.cn/74c85eb61fc24fd082255c860affbbb4.png)
Linux中是用进程来模拟线程的,所以也叫轻量级进程(站在用户角度是线程),不用单独为线程设计算法,可直接用进程的一套相关方法,所以不用维护复杂的进程和线程的关系。OS只需要聚焦在线程间的资源分配上就可以了,所以CPU是只看PCB,不区分线程和进程。
进程与线程的区别:
-
进程具有独立性,可以有部分资源共享(基于管道、ipc资源下)
-
线程共享进程的数据,但是也有属于自己的数据
-
进程是资源分配的基本单位,承担系统资源分配的基本实体
-
线程是CPU调度的基本单位,承担进程资源一部分的基本实体
线程的优点:
-
创建一个新的线程的代价比创建一个进程小得多。创建一个线程虽然也需要创建数据结构,但是并不需要重新开辟资源,只需要将进程的部分资源分配给线程。创建一个进程不仅需要创建大量数据结构,还需要重新创建资源。
-
与进程之间的切换相比,线程之间的切换需要操作系统做的工作少。线程只是进程的部分资源,切换的资源少。
-
线程占用的资源比进程少
-
能充分利用多处理器的可并行数量
-
在等待慢速的I/O任务结束的同时,程序可以执行其它的计算任务
-
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现。
-
I/O密集型应用,为了提高性能,将I/O操作重叠,线程可以同时等待不同的I/O操作。I/O操作是与外设交互数据,会很慢。
线程的缺点:
-
性能缺失
一个处理器只能处理一个线程,如果线程数比可用处理器数多,会有较大的性能损失,会增加额外的同步和CPU调度的开销,而资源却是不变的 -
健壮性降低
编写多线程时, 可能因为共享的变量, 导致一个线程修改此变量, 影响另外一个线程。(线程不是对立的,所以线程之间缺乏保护) (多线程之间的变量是同一个变量;多进程之间变量不是同一个变量,一开始是共享父进程的,但在改变时发生写时拷贝)
-
缺乏访问的控制
进程时访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响 -
编程难度相对高
线程异常:
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃 ;线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,该进程内的所有线程也就随即退出
线程用途:
- 合理的使用多线程,能提高CPU密集型程序的执行效率
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是 多线程运行的一种表现)
线程与进程的关系
线程控制
因为是用进程模拟的线程,所以Linux下不会给我们提供直接操作线程的接口,而给线程提供的是在同一个地址空间创建PCB的方法、分配资源给指定的PCB的接口等等,需要用户自己创建一些函数方法如创建线程、释放线程、等待线程等,对用户不太友好。
所以一般我们在使用的线程相关函数方法,都是由系统级别的工程师在用户层对Linux轻量级进程提供的方法进行封装打包成的库。
下面主要介绍pthread库
- 创建线程函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wsdkuadx-1677869543496)(G:\Typora\图片保存\image-20221223164100513.png)]](https://img-blog.csdnimg.cn/0ef29d17bb7e44cd8fe793aeb54580e4.png)
- threaad:输出型参数,会获取刚创建的线程ID
- attr:传入的是线程的属性(优先级、运行栈等等)一般传入NULL,交给OS默认处理。
- start_routine:创建线程后所执行的方法
- arg:一般会传给第三个参数的函数方法
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
void* ThreadRun(void* args)
{
std::string name = (char*)args;
while(true)
{
std::cout << "当前处于新线程,新线程ID是:" << pthread_self() << ", args: " << name << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid[5];
for(int i = 0;i < 5;i++)
pthread_create(&tid[i],nullptr,ThreadRun,(void*)"new thread");
while(true)
{
std::cout << "当前处于主线程,主线程ID是:" << pthread_self() << std::endl;
std::cout << "###################################################################" << std::endl;
for(size_t i = 0;i < 5;i++)
std::cout << "创建的新线程[" << i << "]ID是:" << tid << std::endl;
std::cout << "###################################################################" << std::endl;
sleep(3);
}
return 0;
}
犹豫是多线程打印,会有乱码现象。
代码中用到的pthread_self(),作用是在谁的线程下用,就获取谁的线程 ID
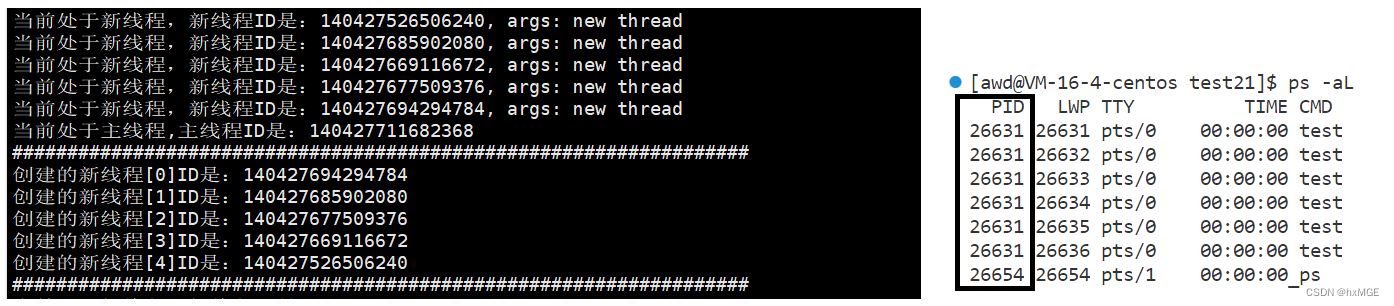
可以看到的是,他们的PID都是一样的,所以线程是对进程的资源分配 ,LWP是内核提供的,和打印出来的id是不一样的,这里用的是原生线程库,打出来的id是其实是进程地址号
- 线程等待
进程退出有三种方式
- 代码正常运行,结果正确
- 代码正常运行,结果不对
- 程序异常,直接退出
前两点退出时不会产生信号,但会产生退出码,而程序异常会产生终止信号;线程分配的资源是进程的一部分,所以只要有一个线程执行的代码部分导致程序崩溃,整个进程会直接退出并产生终止信号,整个进程崩溃,所有线程也就崩溃了。
一般而言,线程也是需要等待的,否则也会出现类似僵尸进程那样的问题,已经退出的线程,其空间没有被释放,仍然在进程的地址空间内,占用资源还得维护数据
线程等待只能是在代码正常运行的前提下等待,而程序异常,进程就会直接退出了,OS会向进程发送退出信号,此时与线程无关,下图所示线程等待函数:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g8lH0kwN-1677869543496)(G:\Typora\图片保存\image-20221223182409990.png)]](https://img-blog.csdnimg.cn/154ac09a135a4f08865255a5aec156af.png)
-
thread:需要等待的线程的ID
-
retval:输出型参数,获取创建线程时指定的函数方法的返回值,(因为指定的函数方法返回值是指针返回,所以这里是二级指针)
pthread_join函数在等待时是阻塞式等待
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
void* ThreadRun(void* args)
{
sleep(3);
return (void*)"finish";
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,ThreadRun,(void*)"new thread");
void* status = NULL;
pthread_join(tid,&status);
std::cout << (char*)status << std::endl;
return 0;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jVsAbkzU-1677869543496)(G:\Typora\图片保存\image-20221223182123417.png)]](https://img-blog.csdnimg.cn/7ded8fd586eb4390aa31254c730d1780.png)
-
线程退出
线程退出的方法有三种
-
函数中return
-
main函数return代表主线程和进程退出
-
其他线程函数中return,代表当前线程退出
-
-
通过pthread_exit函数终止线程
](https://img-blog.csdnimg.cn/a6bb5f0c68be45de8868cac8d45f91b1.png)
参数是要传入的退出状态
void* ThreadRun(void* args)
{
std::string name = (char*)args;
std::cout << name << " running. . ." << std::endl;
sleep(3);
pthread_exit((void*)123);
std::cout << "exit fail" << std::endl;
return (void*)"finish";
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,ThreadRun,(void*)"new thread");
void* status = NULL;
pthread_join(tid,&status);
printf("%d\n",(int*)status);
return 0;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wFkoQuxU-1677869543497)(G:\Typora\图片保存\image-20221223194429944.png)]](https://img-blog.csdnimg.cn/4dfd1c80fbdc4ddf9ea99adc22ac2738.png)
-
通过pthread_cancel函数取消线程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FmTkx3LF-1677869543497)(G:\Typora\图片保存\image-20221223195240763.png)]](https://img-blog.csdnimg.cn/6702579809bc446185d587130ec84728.png)
只需要传入要取消的线程的id即可
成功返回0,失败返回-1
void* ThreadRun(void* args) { std::string name = (char*)args; std::cout << name << " running. . ." << std::endl; sleep(10); return (void*)"finish"; } int main() { pthread_t tid; pthread_create(&tid,nullptr,ThreadRun,(void*)"new thread"); sleep(1); std::cout << "cancel sub thread. . ." << std::endl; sleep(5); pthread_cancel(tid); void* status = NULL; pthread_join(tid,&status); printf("%d\n",(int*)status); return 0; }![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LhJGzBKU-1677869543497)(G:\Typora\图片保存\image-20221223195949508.png)]](https://img-blog.csdnimg.cn/11a102bdcb05465bb343ea89cdbd7826.png)
取消后的线程退出码是 -1 代表是PTHREAD_ CANCELED的意思
注意:不建议在子线程中取消主线程的做法,这样会导致进入僵尸进程的状态。因为主线程会退出而没有资源可以等待子线程退出,子线程就造成资源浪费了
void* ThreadRun(void* args)
{
sleep(5);
pthread_cancel((pthread_t)args);
while(1)
{
std::cout << " running. . ." << std::endl;
sleep(1);
}
return (void*)"finish";
}
int main()
{
pthread_t tid;
pthread_t g_tid = pthread_self();
pthread_create(&tid,nullptr,ThreadRun,(void*)g_tid);
void* status = NULL;
pthread_join(tid,&status);
printf("%d\n",(int*)status);
return 0;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6sFL15Cs-1677869543498)(G:\Typora\图片保存\image-20221223203927069.png)]](https://img-blog.csdnimg.cn/76378c59494d40dbbee075d320473c09.png)
如图所示:进入了僵尸进程,以及类似僵尸进程的线程状态(主线程 defunct)
- 线程分离
若不想阻塞式的等待线程退出,可以使用线程分离函数;分离之后的线程不需要被join,运行完毕后会自动释放资源
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WDoqmLHI-1677869543498)(G:\Typora\图片保存\image-20221223222753176.png)]](https://img-blog.csdnimg.cn/4d9fa9a8871a4f048a115cf965cec954.png)
传入要分离的线程id即可
void* ThreadRun(void* args)
{
pthread_detach(pthread_self());
std::cout << " running. . ." << std::endl;
sleep(1);
return (void*)"finish";
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,ThreadRun,(void*)"hello");
sleep(3);
void* status = NULL;
int ret = pthread_join(tid,&status);
printf("ret:%d,status:%s\n",ret,(char*)status);
return 0;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X1F2IqD1-1677869543498)(G:\Typora\图片保存\image-20221223222813924.png)]](https://img-blog.csdnimg.cn/bec939a1429c4af18a7a13beec859dc5.png)
只要线程分离了,就不可在使用join去等待了,会等待失败
内核LWP和线程ID的关系
我们使用的pthread原生线程库是存在磁盘当中的,在使用时会被加载到内存当中,通过页表映射到进程地址空间的共享区(堆区和栈区之间的区域)所有的进程都共用同一份库(只是进程空间中进程自己认为独占这个库)
而每个线程共享的是同一份进程地址空间,但是每个线程也会有自己的私有数据部分如线程栈(主线程栈是在栈区的)、上下文数据、属性等等。这些线程私有的部分组成线程的数据块(可以想象成类似于task_struct的线程struct),数据块其实是存储在线程库中的,通过页表映射到进程地址的共享区。
(创建线程的时候,用mmap系统调用从heap分配出来的)
在使用pthread_create创建线程时,线程库会生成一个ID号来表示新创建的线程,这个ID由函数的第一个参数可以获取到;而线程ID就是这些数据块在共享区映射的地址,每个线程id就是每个线程的数据块在共享区的地址,通过id号便能找到线程的所有数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z1FzwW8l-1677869543498)(G:\Typora\图片保存\image-20221224021321882.png)]](https://img-blog.csdnimg.cn/cceb5f914852489995f238a62e483a88.png)
线程id就是:线程存储在线程库中的数据,通过内存映射到进程地址空的共享区的地址标号,有了这个标号就能找到线程的所有的私有数据
LWP和线程id的关系是什么?
LWP是在内核层面的,线程id是在用户层面的。
前面说过在Linux中没有提供专门的线程方法,使用进程模拟的线程,所以Liunx中的线程其实是轻量级进程,依旧用的task_struct,所以CPU调度知认PCB;那进程由PID,线程也该有个数字来标识这些task_struct,那这个标识就是LWP,所以LWP实际上是供CPU调度使用的(类似文件描述符一样)
线程id是用户层的,LWP是内核层的,那id怎么知道他是对应哪个task_struct的呢?所以线程的数据块一定也包含一个LWP,形成1:1的关系(也有1:n,即一个线程id包含多个LWP,在用户层面看来是一个线程)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lfYM5XQC-1677869543499)(G:\Typora\图片保存\image-20221224023454692.png)]](https://img-blog.csdnimg.cn/1a673e04f635479cafdec3ea3f44b523.png)