概述
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
背景
早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。ps. 目前内部使用的同步,已经支持mysql5.x和oracle部分版本的日志解析
基于日志增量订阅&消费支持的业务:
- 数据库镜像
- 数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- search build
- 业务cache刷新
- 价格变化等重要业务消息
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
工作原理
Mysql的BinLog
它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间。主要用来备份和数据同步。
binlog 有三种模式:STATEMENT、ROW、MIXED
- STATEMENT 记录的是执行的sql语句
- ROW 记录的是真实的行数据记录
- MIXED 记录的是1+2,优先按照1的模式记录
举例说明
举例来说,下面的sql
COPYupdate user set age=20
对应STATEMENT模式只有一条记录,对应ROW模式则有可能有成千上万条记录(取决数据库中的记录数)。
MySQL主备复制原理
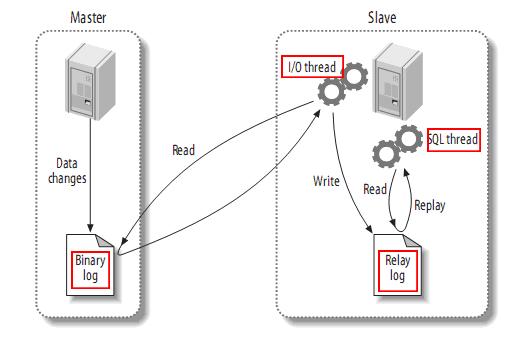
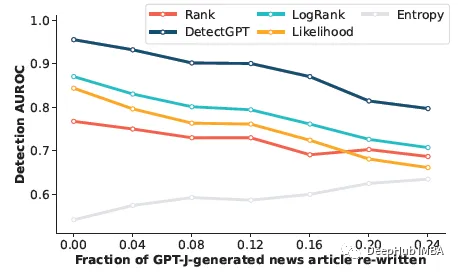
- Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
- Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
- Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master- info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
- Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
当然这个过程本质上还是存在一定的延迟的。
mysql的binlog文件长这个样子。
COPYmysql-bin.003831
mysql-bin.003840
mysql-bin.003849
mysql-bin.003858
启用Binlog注意以下几点:
- Master主库一般会有多台Slave订阅,且Master主库要支持业务系统实时变更操作,服务器资源会有瓶颈;
- 需要同步的数据表一定要有主键;
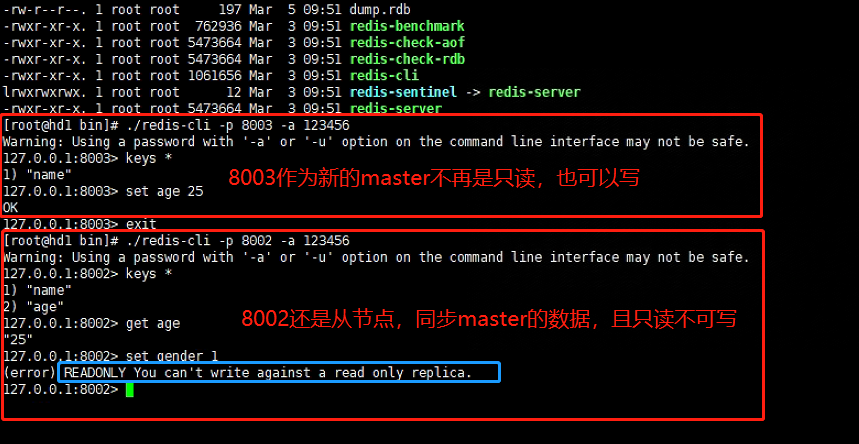
canal能够同步数据的原理
理解了mysql的主从同步的机制再来看canal就比较清晰了,canal主要是听过伪装成mysql从server来向主server拉取数据。
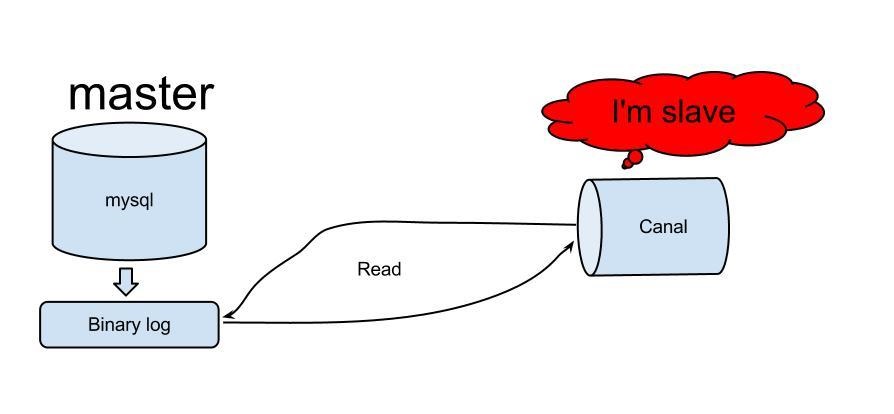
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
Canal架构
canal的设计理念
canal的组件化设计非常好,有点类似于tomcat的设计。使用组合设计,依赖倒置,面向接口的设计。
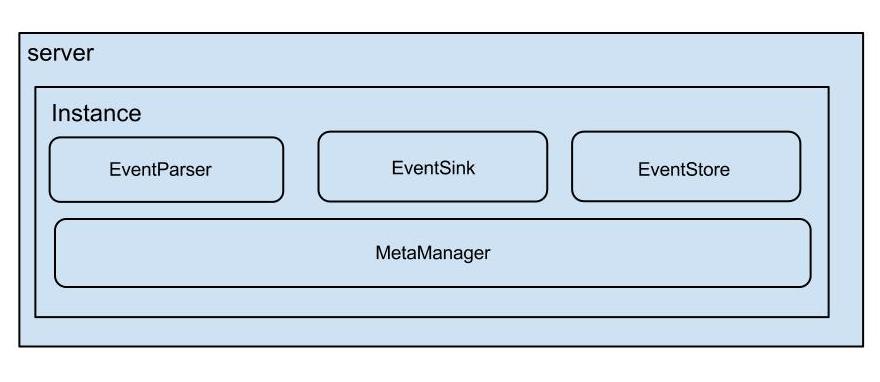
canal的组件
- canal server 这个代表了我们部署的一个canal 应用
- canal instance 这个代表了一个canal server中的多个 mysql instance ,从这一点说明一个canal server可以搜集多个库的数据,在canal中叫 destionation。
每个canal instance 有多个组件构成。在conf/spring/default-instance.xml中配置了这些组件。他其实是使用了spring的容器来进行这些组件管理的。
instance 包含的组件
这里是一个cannalInstance工作所包含的大组件。截取自
conf/spring/default-instance.xml
COPY<bean id="instance" class="com.alibaba.otter.canal.instance.spring.CanalInstanceWithSpring">
<property name="destination" value="${canal.instance.destination}" />
<property name="eventParser">
<ref local="eventParser" />
</property>
<property name="eventSink">
<ref local="eventSink" />
</property>
<property name="eventStore">
<ref local="eventStore" />
</property>
<property name="metaManager">
<ref local="metaManager" />
</property>
<property name="alarmHandler">
<ref local="alarmHandler" />
</property>
</bean>
EventParser设计
eventParser 最基本的组件,类似于mysql从库的dump线程,负责从master中获取bin_log
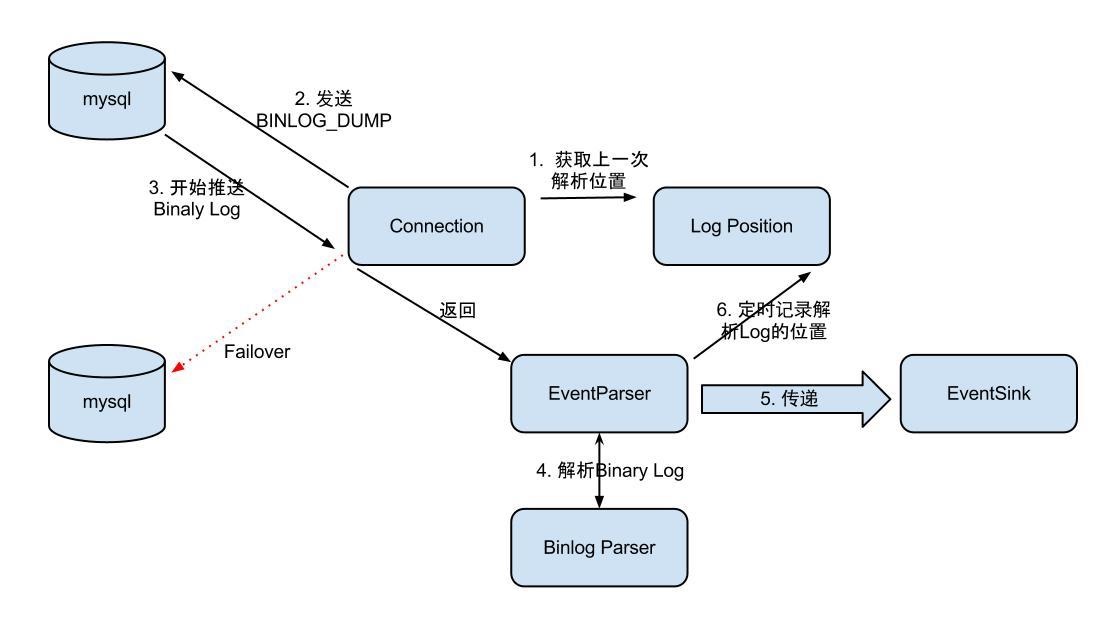
整个parser过程大致可分为几步:
- Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
- Connection建立链接,发送BINLOG_DUMP指令
// 0. write command number
// 1. write 4 bytes bin-log position to start at
// 2. write 2 bytes bin-log flags
// 3. write 4 bytes server id of the slave
// 4. write bin-log file name - Mysql开始推送Binaly Log
- 接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息
// 补充字段名字,字段类型,主键信息,unsigned类型处理 - 传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功
- 存储成功后,定时记录Binaly Log位置
EventSink设计
eventSink 数据的归集,使用设置的filter对bin log进行过滤,工作的过程如下。
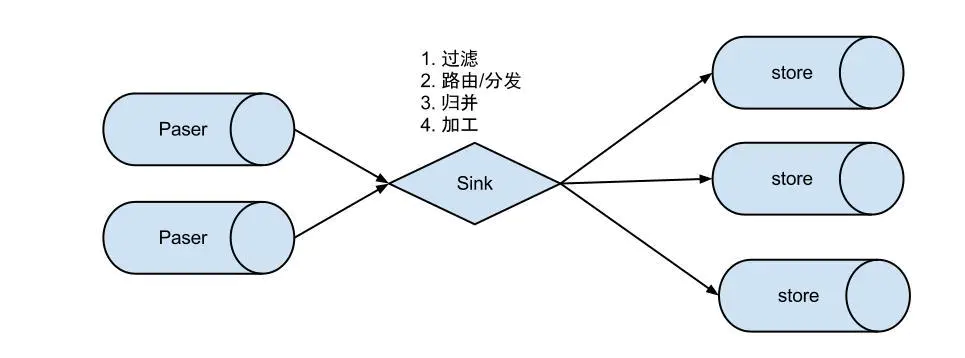
说明:
数据过滤:支持通配符的过滤模式,表名,字段内容等
数据路由/分发:解决1:n (1个parser对应多个store的模式)
数据归并:解决n:1 (多个parser对应1个store)
数据加工:在进入store之前进行额外的处理,比如join
数据1:n业务
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在mysql上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。
所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注
数据n:1业务
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。
所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并.
EventStore设计
eventStore 用来存储filter过滤后的数据,canal目前的数据只在这里存储,工作流程如下
- 目前仅实现了Memory内存模式,后续计划增加本地file存储,mixed混合模式
- 借鉴了Disruptor的RingBuffer的实现思路
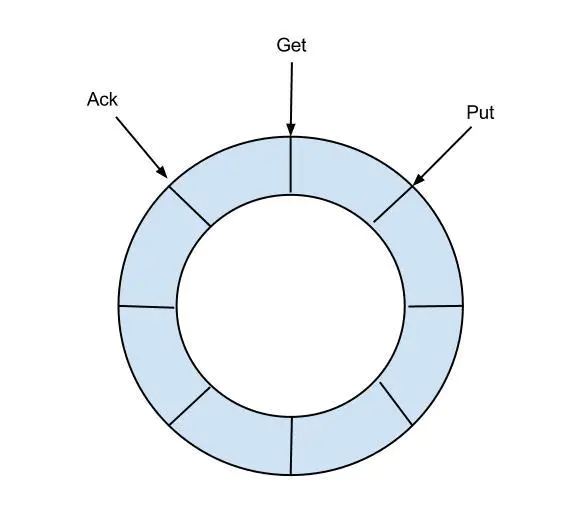
定义了3个cursor
- Put : Sink模块进行数据存储的最后一次写入位置
- Get : 数据订阅获取的最后一次提取位置
- Ack : 数据消费成功的最后一次消费位置
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
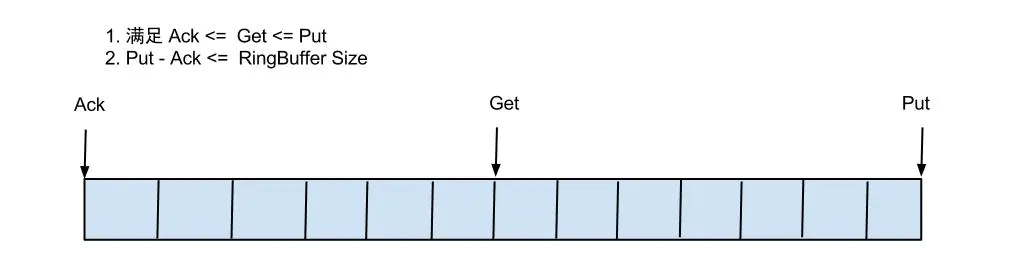
实现说明:
- Put/Get/Ack cursor用于递增,采用long型存储
- buffer的get操作,通过取余或者与操作。(与操作: cusor & (size - 1) , size需要为2的指数,效率比较高)
metaManager
metaManager 用来存储一些原数据,比如消费到的游标,当前活动的server等信息
alarmHandler
alarmHandler 报警,这个一般情况下就是错误日志,理论上应该是可以定制成邮件等形式,但是目前不支持
各个组件目前支持的类型
canal采用了spring bean container的方式来组装一个canal instance ,目的是为了能够更加灵活。
canal通过这些组件的选取可以达到不同使用场景的效果,比如单机的话,一般使用file来存储metadata就行了,HA的话一般使用zookeeper来存储metadata。
eventParser
eventParser 目前只有三种
- MysqlEventParser 用于解析mysql的日志
- GroupEventParser 多个eventParser的集合,理论上是对应了分表的情况,可以通过这个合并到一起
- RdsLocalBinlogEventParser 基于rds的binlog 的复制
eventSink
eventSink 目前只有EntryEventSink 就是基于mysql的binlog数据对象的处理操作
eventStore
eventStore 目前只有一种 MemoryEventStoreWithBuffer,内部使用了一个ringbuffer 也就是说canal解析的数据都是存在内存中的,并没有到zookeeper当中。
metaManager
metaManager 这个比较多,其实根据元数据存放的位置可以分为三大类,memory,file,zookeeper
Canal-HA机制
canal是支持HA的,其实现机制也是依赖zookeeper来实现的,用到的特性有watcher和EPHEMERAL节点(和session生命周期绑定),与HDFS的HA类似。
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
- canal server: 为了减少对mysql dump的请求,不同server上的instance(不同server上的相同instance)要求同一时间只能有一个处于running,其他的处于standby状态(standby是instance的状态)。
- canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
server ha的架构图如下
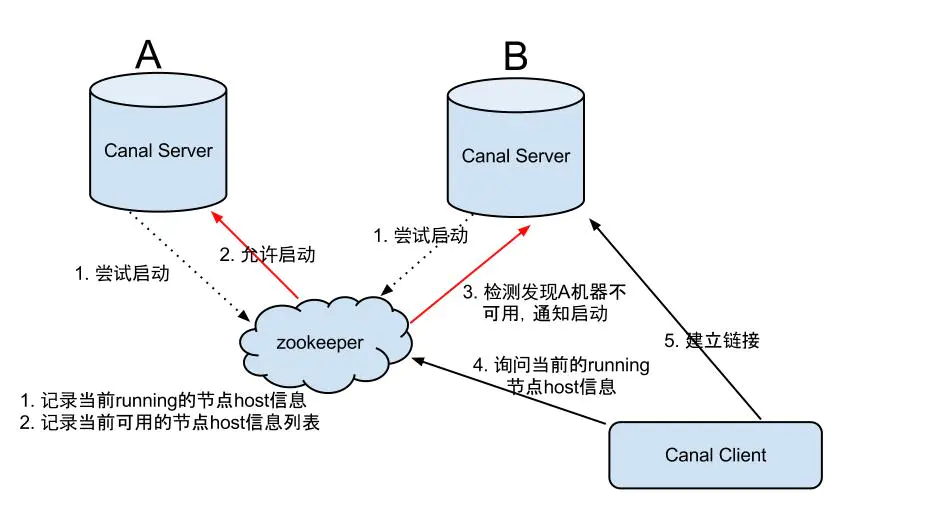
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper_进行一次尝试启动判断_(实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态。
- 一旦zookeeper发现canal server A创建的instance节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance。
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect。
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制.
canal的工作过程
dump日志
启动时去MySQL 进行dump操作的binlog 位置确定
工作的过程。在启动一个canal instance 的时候,首先启动一个eventParser 线程来进行数据的dump 当他去master拉取binlog的时候需要binlog的位置,这个位置的确定是按照如下的顺序来确定的(这个地方讲述的是HA模式哈)。
- 在启动的时候判断是否使用zookeeper,如果是zookeeper,看能否拿到 cursor (也就是binlog的信息),如果能够拿到,把这个信息存到内存中(MemoryLogPositionManager),然后拿这个信息去mysql中dump binlog
- 通过1拿不到的话(一般是zookeeper当中每一,比如第一次搭建的时候,或者因为某些原因zk中的数据被删除了),就去配置文件配置当中的去拿,把这个信息存到内存中(MemoryLogPositionManager),然后拿这个信息去mysql中dump binlog
- 通过2依然没有拿到的话,就去mysql 中执行一个sql
show master status这个语句会显示当前mysql binlog最后位置的信息,也就是刚写入的binlog所在的位置信息。把这个信息存到内存中(MemoryLogPositionManager),然后拿这个信息去mysql中dump binlog。
后面的eventParser的操作就会以内存中(MemoryLogPositionManager)存储的binlog位置去master进行dump操作了。
mysql的
show master status操作
COPYmysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000028
Position: 635762367
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 18db0532-6a08-11e8-a13e-52540042a113:1-2784514,
318556ef-4e47-11e6-81b6-52540097a9a8:1-30002,
ac5a3780-63ad-11e8-a9ac-52540042a113:1-5,
be44d87c-4f25-11e6-a0a8-525400de9ffd:1-156349782
1 row in set (0.00 sec
归集(sink)和存储(store)
数据在dump回来之后进行的归集(sink)和存储(store)
sink操作是可以支撑将多个eventParser的数据进行过滤filter
filter使用的是instance.properties中配置的filter,当然这个filter也可以由canal的client端在进行subscribe的时候进行设置。如果在client端进行了设置,那么服务端配置文件instance.properties的配置都会失效
sink 之后将过滤后的数据存储到eventStore当中去。
目前eventStore的实现只有一个MemoryEventStoreWithBuffer,也就是基于内存的ringbuffer,使用这个store有一个特点,这个ringbuffer是基于内存的,大小是有限制的(bufferSize = 16 * 1024 也就是16M),所以,当canal的客户端消费比较慢的时候,ringbuffer中存满了就会阻塞sink操作,那么正读取mysql binlog的eventParser线程也会受阻。
这种设计其实也是有道理的。 因为canal的操作是pull 模型,不是producer push的模型,所以他没必要存储太多数据,这样就可以避免了数据存储和持久化管理的一些问题。使数据管理的复杂度大大降低。
上面这些整个是canal的parser 线程的工作流程,主要对应的就是将数据从mysql搞下来,做一些基本的归集和过滤,然后存储到内存中。
binlog的消费者
canal从mysql订阅了binlog以后主要还是想要给消费者使用。那么binlog是在什么时候被消费呢。这就是另一条主线了。就像咱们做一个toC的系统,管理系统是必须的,用户使用的app或者web又是一套,eventParser 线程就像是管理系统,往里面录入基础数据。canal的client就像是app端一样,是这些数据的消费方。
binlog的主要消费者就是canal的client端。使用的协议是基于tcp的google.protobuf,当然tcp的模式是io多路复用,也就是nio。当我们的client发起请求之后,canal的server端就会从eventStore中将数据传输给客户端。根据客户端的ack机制,将binlog的元数据信息定期同步到zookeeper当中。
canal的目录结构
配置父目录:
在下面可以看到
COPYcanal
├── bin
│ ├── canal.pid
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
└── conf
├── canal.properties
├── gamer ---目录
├── ww_social ---目录
├── wother ---目录
├── nihao ---目录
├── liveim ---目录
├── logback.xml
├── spring ---目录
├── ym ---目录
└── xrm_ppp ---目录
这里是全部展开的目录
COPYcanal
├── bin
│ ├── canal.pid
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
└── conf
├── canal.properties
├── game_center
│ └── instance.properties
├── ww_social
│ ├── h2.mv.db
│ ├── h2.trace.db
│ └── instance.properties
├── wwother
│ ├── h2.mv.db
│ └── instance.properties
├── nihao
│ ├── h2.mv.db
│ ├── h2.trace.db
│ └── instance.properties
├── movie
│ ├── h2.mv.db
│ └── instance.properties
├── logback.xml
├── spring
│ ├── default-instance.xml
│ ├── file-instance.xml
│ ├── group-instance.xml
│ ├── local-instance.xml
│ ├── memory-instance.xml
│ └── tsdb
│ ├── h2-tsdb.xml
│ ├── mysql-tsdb.xml
│ ├── sql
│ └── sql-map
└── ym
└── instance.properties
Canal应用场景
同步缓存redis/全文搜索ES
canal一个常见应用场景是同步缓存/全文搜索,当数据库变更后通过binlog进行缓存/ES的增量更新。当缓存/ES更新出现问题时,应该回退binlog到过去某个位置进行重新同步,并提供全量刷新缓存/ES的方法,如下图所示。
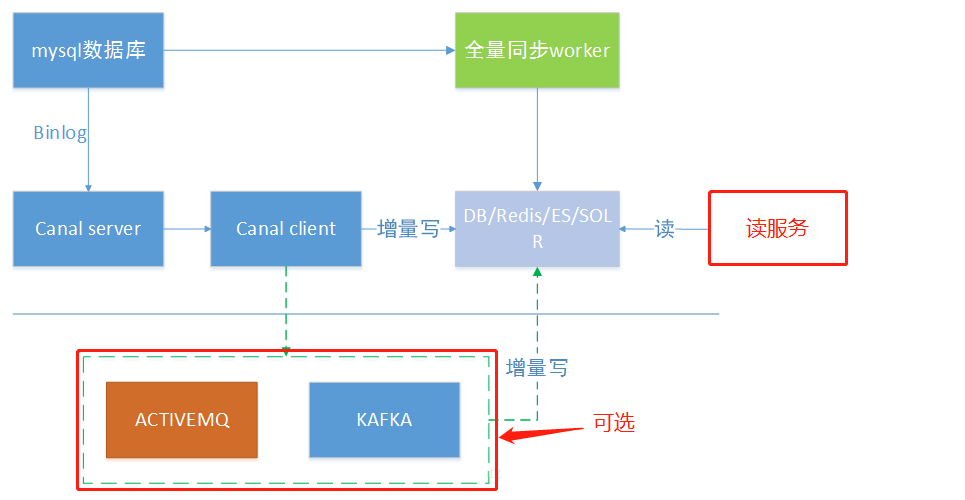
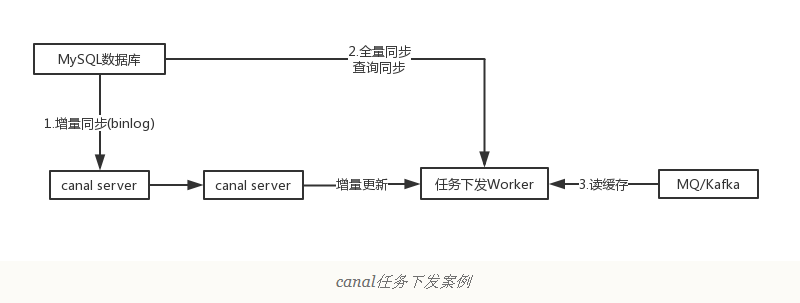
下发任务
另一种常见应用场景是下发任务,当数据变更时需要通知其他依赖系统。其原理是任务系统监听数据库变更,然后将变更的数据写入MQ/kafka进行任务下发,比如商品数据变更后需要通知商品详情页、列表页、搜索页等先关系统。这种方式可以保证数据下发的精确性,通过MQ发送消息通知变更缓存是无法做到这一点的,而且业务系统中不会散落着各种下发MQ的代码,从而实现了下发归集,如下图所示。
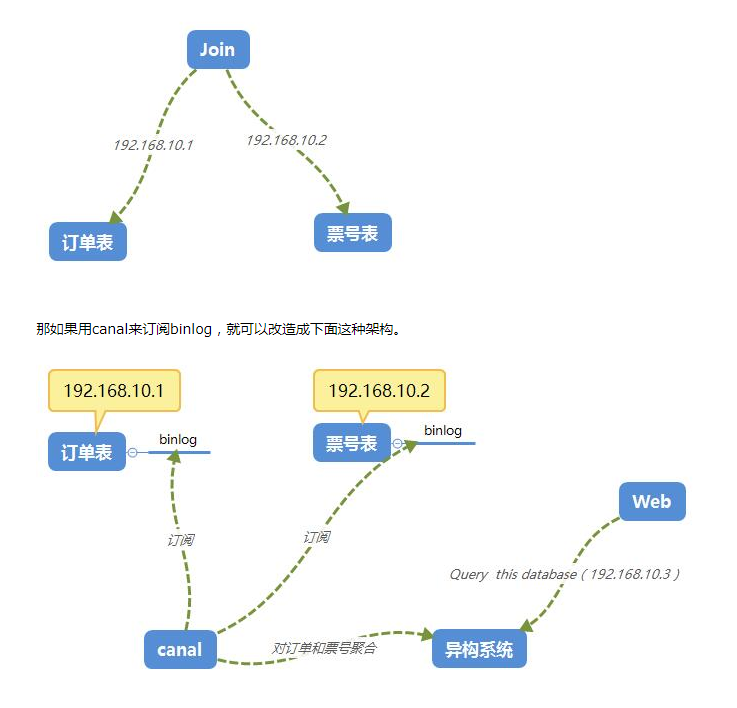
数据异构
在大型网站架构中,DB都会采用分库分表来解决容量和性能问题,但分库分表之后带来的新问题。比如不同维度的查询或者聚合查询,此时就会非常棘手。一般我们会通过数据异构机制来解决此问题。
所谓的数据异构,那就是将需要join查询的多表按照某一个维度又聚合在一个DB中。让你去查询。canal就是实现数据异构的手段之一。
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!