leetcode 71~80 学习经历
- 71. 简化路径
- 72. 编辑距离
- 73. 矩阵置零
- 74. 搜索二维矩阵
- 75. 颜色分类
- 76. 最小覆盖子串
- 77. 组合
- 78. 子集
- 79. 单词搜索
- 80. 删除有序数组中的重复项 II
- 小结
71. 简化路径
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 ‘/’ 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (…) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,‘//’)都被视为单个斜杠 ‘/’ 。 对于此问题,任何其他格式的点(例如,‘…’)均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
始终以斜杠 ‘/’ 开头。
两个目录名之间必须只有一个斜杠 ‘/’ 。
最后一个目录名(如果存在)不能 以 ‘/’ 结尾。
此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含 ‘.’ 或 ‘…’)。
返回简化后得到的 规范路径 。
示例 1:
输入:path = “/home/”
输出:“/home”
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:path = “/…/”
输出:“/”
解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
示例 3:
输入:path = “/home//foo/”
输出:“/home/foo”
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:path = “/a/./b/…/…/c/”
输出:“/c”
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/simplify-path
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
啊。。。又没有认真读题。。。任何其他格式的点(例如,‘…’)均被视为文件/目录名称,好吧,因为老顾之前做采集,碰到过路径里有这种乱七八糟格式的东西,但 ./ 表示当前路径,…/表示上级路径 …/ 等于 …/…/,也就是三个点返回两级路径,四个点返回三级路径的样子。。。结果一提交。。。。没通过
class Solution:
def simplifyPath(self, path: str) -> str:
path += '/'
while path.count('//') + path.count('/./') > 0:
path = path.replace('//','/').replace('/./','/')
lv = path[:-1].split('/')
arr = []
for i in range(1,len(lv)):
if len(set(lv[i]) - {'.'}) > 0:
arr.append(lv[i])
if set(lv[i]) == {'.'}:
if len(lv[i]) > 2: # 没有这个判定,.../ 就返回两级目录
arr.append(lv[i])
else:
z = len(lv[i]) - 1
while z > 0 and len(arr) > 0:
arr.pop(-1)
z -= 1
return '/' + '/'.join(arr)
这明显有多余的判断了,针对这个题目优化下
class Solution:
def simplifyPath(self, path: str) -> str:
arr = []
for p in path.split('/'):
if len(p) == 0 or p == '.':
continue
elif p != '..':
arr.append(p)
elif len(arr) > 0:
arr.pop()
return '/' + '/'.join(arr)
16ms大佬的答案。。。。十分雷同了
72. 编辑距离
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:插入一个字符
删除一个字符
替换一个字符
示例 1:
输入:word1 = “horse”, word2 = “ros”
输出:3
解释:
horse -> rorse (将 ‘h’ 替换为 ‘r’)
rorse -> rose (删除 ‘r’)
rose -> ros (删除 ‘e’)
示例 2:
输入:word1 = “intention”, word2 = “execution”
输出:5
解释:
intention -> inention (删除 ‘t’)
inention -> enention (将 ‘i’ 替换为 ‘e’)
enention -> exention (将 ‘n’ 替换为 ‘x’)
exention -> exection (将 ‘n’ 替换为 ‘c’)
exection -> execution (插入 ‘u’)
提示:
0 <= word1.length, word2.length <= 500
word1 和 word2 由小写英文字母组成
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/edit-distance
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
额。。。。这题是真不会,看了下目录,71到80题,好几个这类的题目,老顾都不会,嗯,这才开始有了真实的学习感觉了,在先用4天琢磨完79题,又用三天琢磨完76题,开始啃这个骨头。没思路,先看官方题解。
。。。。。。真@@一脸懵逼。。。。题解这么简单的吗???一个二维数组解决?就和当初第一次看到01背包的时候一样的懵逼。。。。这个真心不知道该说是学会了,还是学废了
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
m,n = len(word1),len(word2)
dp = [[0 for _ in range(n + 2)] for _ in range(m + 2)]
dp[0][2:] = list(word2)
dp[1][2:] = list(range(1,n + 1))
for i in range(2,m + 2):
dp[i][0],dp[i][1] = word1[i - 2],i - 1
for j in range(2,n + 2):
if dp[0][j] != dp[i][0]:
dp[i][j] = min(dp[i - 1][j],dp[i][j - 1],dp[i - 1][j - 1]) + 1
else:
dp[i][j] = min(dp[i - 1][j],dp[i][j - 1],dp[i - 1][j - 1] - 1) + 1
return dp[-1][-1]
这就和背包问题一样,见过了,并看过解法,那么就知道怎么解了,但绝对不能说会了。。。天知道里面的数学推导过程是个什么鬼。。。
然后看看头部答案的答案,懵逼树下俺和我。。。。真有完全看天书一样的推导出来的,就如同我在寻因找祖的文章里,有大佬用数学公式做出来,却完全看不懂一样,闪了。。。。
73. 矩阵置零
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
示例 1:
输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[1,0,1],[0,0,0],[1,0,1]]
示例 2:
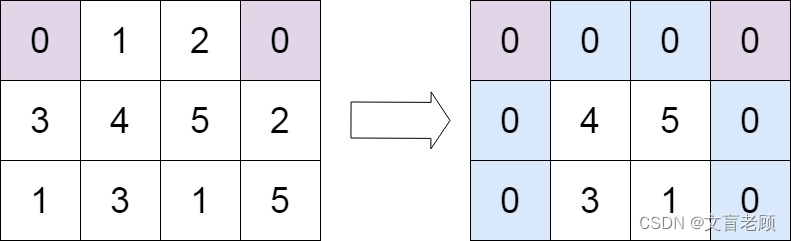
输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]

来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/set-matrix-zeroes
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这个没啥说的,为了避免边扫描边修改造成多余的修改,先扫描记录然后再来一遍修改
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
m,n = len(matrix),len(matrix[0])
row = set()
col = set()
for i in range(m):
for j in range(n):
if matrix[i][j] == 0:
row.add(i)
col.add(j)
for i in range(m):
for j in range(n):
if i in row or j in col:
matrix[i][j] = 0
不知道怎么节约空间了
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
row = 0
col = 0
for i in range(len(matrix)):
for j in range(len(matrix[0])):
if matrix[i][j] == 0:
row += 1 << i if (row >> i) % 2 == 0 else 0
col += 1 << j if (col >> j) % 2 == 0 else 0
i = 0
while row > 0:
if row % 2 == 1:
matrix[i][:] = [0] * len(matrix[0])
row = row >> 1
i += 1
i = 0
while col > 0:
if col % 2 == 1:
for j in range(len(matrix)):
matrix[j][i] = 0
col = col >> 1
i += 1
没什么差别啊,然后看了看大佬的节约内存的答案,只能说,老顾对二进制不熟,位运算理解不透彻
col % 2 == 1 ==> col & 1 == 1
col += 1 << j if … ==> col |= 1 << j 少了 if 判断
74. 搜索二维矩阵
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
示例 1:
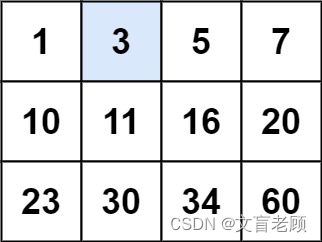
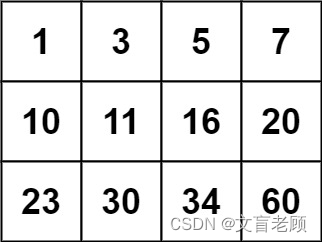
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
示例 2:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13
输出:false
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/search-a-2d-matrix
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
二分查找里套个二分查找。。。
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
u,d = 0,len(matrix) - 1
while u <= d:
c = (u + d) // 2
if matrix[d][0] == target:
return True
if matrix[c][0] == target:
return True
elif matrix[c][0] > target:
d = c - 1
else:
if u != c:
u = c
else:
if matrix[d][0] < target:
u = d
l,r = 0,len(matrix[u]) - 1
while l <= r:
if l == r and matrix[u][l] != target:
break
m = (l + r) // 2
if matrix[u][m] == target:
return True
elif matrix[u][m] > target:
r = m - 1
else:
l = m + 1
break
return False
大佬真多啊,36ms才刚及格
16ms 的大佬,把二分弄成函数了,good job
75. 颜色分类
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
必须在不使用库内置的 sort 函数的情况下解决这个问题。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
示例 2:
输入:nums = [2,0,1]
输出:[0,1,2]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/sort-colors
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
原地排序,快速排序?
class Solution:
def sortColors(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
i,j,c = 0,1,False
while True:
while j < len(nums) and nums[j] == nums[j - 1]:
j += 1
if j >= len(nums):
if not c:
break
i += 1
j = i + 1
c = False
if j == len(nums):
break
if nums[i] > nums[j]:
nums[i],nums[j] = nums[j],nums[i]
c = True
if nums[j - 1] > nums[j]:
nums[j - 1],nums[j] = nums[j],nums[j - 1]
c = True
j += 1
然后又一脸蒙的发现,原来自己考虑的还是少。。。一共三种颜色,只有0,1,2,碰到0扔前边,碰到2扔后边。。。不要考虑泛用性。。。。大佬的思路真是清奇
76. 最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
解释:最小覆盖子串 “BANC” 包含来自字符串 t 的 ‘A’、‘B’ 和 ‘C’。
示例 2:
输入:s = “a”, t = “a”
输出:“a”
解释:整个字符串 s 是最小覆盖子串。
示例 3:
输入: s = “a”, t = “aa”
输出: “”
解释: t 中两个字符 ‘a’ 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/minimum-window-substring
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
在没有参考题解和答案的情况下,自己终于搞出一版。。。效率上。。。难以言喻啊,提交肯定超时
class Solution:
def minWindow(self, s: str, t: str) -> str:
m,n = len(s),len(t)
if m < n: # 长度不够
return ''
elif s.count(t) > 0: # 直接有字串
return t
elif len(set(t) - set(s)) > 0: # 缺少对应字母
return ''
k = Counter(t)
l = Counter(s)
d = {}
for i in k:
if k[i] > l[i]: # 对应字母数量不够
return ''
for i in range(m):
if s[i] in k: # 记录下标
if s[i] not in d:
d[s[i]] = [i]
else:
d[s[i]].append(i)
def dfs(p,u,ans):
c = []
for v in p:
c += d[v][p[v]:p[v] + k[v]]
if max(c) - min(c) + 1 < len(ans):
ans = s[min(c):max(c) + 1]
for v in p:
if v in u:
continue
z = False
for i in range(p[v],len(d[v]) - k[v] + 1):
z = True
tmp = dfs({z:p[z] if z != v else i for z in p},{v}.union(u),ans)
if len(tmp) < len(ans):
ans = tmp
if z:
break
return ans
return dfs({v:0 for v in k},set(),s)
感觉还不如硬用循环来一次爽利,完全没有头绪,还是认命了,去学习,嗯,双指针滑动。。。。
结果也是一言难尽,按官方题解抄的答案。。。竟然还是超时,再琢磨琢磨
一通操作猛如虎,一看成绩。。。还不如250
class Solution:
def minWindow(self, s: str, t: str) -> str:
m,n = len(s),len(t)
if m < n: # 长度不够
return ''
elif len(set(t) - set(s)) > 0: # 缺少对应字母
return ''
k = Counter(t)
d = {v:0 for v in k}
d['from'] = 0
d['to'] = n - 1
for i in range(n):
if s[i] in k:
d[s[i]] += 1
ans = s
def check(k,d):
for v in k:
if d[v] < k[v]:
return False
return True
while d['to'] < m + 1:
if check(k,d):
z = s[d['from']:d['to'] + 1]
if len(z) < len(ans):
ans = z
if s[d['from']] in k:
d[s[d['from']]] -= 1
d['from'] += 1
while d['from'] < d['to'] and s[d['from']] not in k:
d['from'] += 1
if d['from'] > d['to']:
break
else:
d['to'] += 1
while d['to'] < m and s[d['to']] not in k:
d['to'] += 1
if d['to'] == m:
if d['from'] == 0:
return ''
break
d[s[d['to']]] += 1
return ans
看着就乱糟糟的,赶紧清理下冗余的部分
class Solution:
def minWindow(self, s: str, t: str) -> str:
m,n,ans = len(s),len(t),s
if m < n:
return ''
elif s.count(t) > 0:
return t
kt = Counter(t)
kd = {v:0 for v in kt}
for i in range(m):
if s[i] in kt:
kd[s[i]] += 1
if 'from' not in kd:
kd['from'] = i
kd['len'] = 1
kd['to'] = i
else:
kd['len'] += 1
if kd['len'] == n:
kd['to'] = i
break
if 'len' not in kd:
return ''
elif kd['len'] < n:
return ''
kd['len'] = 0
def check():
for k in kt:
if kt[k] > kd[k]:
return False
return True
while kd['to'] < m:
w = s[kd['from']:kd['to'] + 1]
if check():
kd['len'] = 1
if len(w) < len(ans):
ans = w
kd[s[kd['from']]] -= 1
while kd['from'] < kd['to'] and s[kd['from'] + 1] not in kt:
kd['from'] += 1
kd['from'] += 1
continue
while kd['to'] < m - 1 and s[kd['to'] + 1] not in kt:
kd['to'] += 1
kd['to'] += 1
if kd['to'] >= m:
if kd['len'] == 0:
ans = ''
break
kd[s[kd['to']]] += 1
return ans
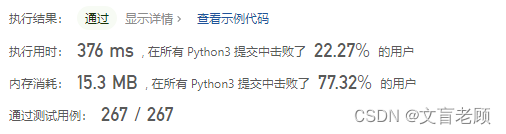
为了减少每次 Counter 统计,直接自己做个字典记录,左边移动,对应字符减少1个计数,右边移动,对应字符增加一个计数,但效率还是差强人意啊
然后,在268ms答案里,又发现一个思路,当已经有一次记录比字符串 t 小的时候,再向右滑动的时候,左边跟着一起滑动。。。嗯,因为只滑动右边,那滑动出来的结果肯定超过当前的长度了
好吧,再来写一版。。。。感觉没什么提高啊。。。
class Solution:
def minWindow(self, s: str, t: str) -> str:
def check():
for k in kt:
if kt[k] > kd[k]:
return False
return True
m,n,ans = len(s),len(t),''
if m < n:
return ''
elif s.count(t) > 0:
return t
kt = Counter(t)
kd = {v:0 for v in kt}
l,r,x = 0,0,0
while l < m and s[l] not in kt:
l += 1
r += 1
if l == m:
return ''
kd[s[l]] += 1
x = 1
while x < n and r < m - 1:
r += 1
if s[r] in kt:
x += 1
kd[s[r]] += 1
if x < n:
return ''
while r < m:
if check():
if not ans or r - l + 1 < len(ans):
ans = s[l:r + 1]
if s[l] in kt:
kd[s[l]] -= 1
l += 1
continue
r += 1
while r < m and s[r] not in kt:
if ans:
if s[l] in kt:
kd[s[l]] -= 1
l += 1
r += 1
if r < m and s[r] in kt:
kd[s[r]] += 1
return ans
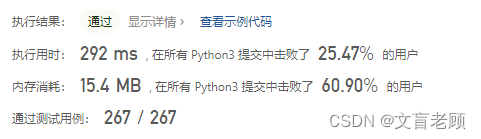
难道,是某些精髓我还没发现?看到240ms里,Counter 原来还有个 total 的方法。。。然后忍不住看了看头部答案。。。嗯,原理都差不多啊,也没多什么别的思路,就是分支更精准了
class Solution:
def minWindow(self, s: str, t: str) -> str:
m,n,ans = len(s),len(t),''
kt = collections.defaultdict(int)
for i in range(n):
kt[t[i]] += 1
l,r,useful = 0,0,0
while r < m:
if s[r] in kt:
kt[s[r]] -= 1
if kt[s[r]] >= 0:
useful += 1
while useful == n:
if not ans or r - l + 1 < len(ans):
ans = s[l:r + 1]
if s[l] in kt:
kt[s[l]] += 1
if kt[s[l]] > 0:
useful -= 1
l += 1
r += 1
print(ans,kt)
return ans
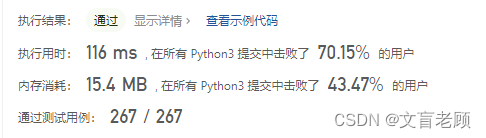
又了解了一点点,原来还有一个defaultdict,不用定义key就可以直接用啊,另外就是,自己记录状态,不用字典比较,效率果然不一样。然后,使用enumerate迭代出索引和字符,比每次去读指定索引字符又快一点点
class Solution:
def minWindow(self, s: str, t: str) -> str:
m,n,ans = len(s),len(t),''
kt = collections.defaultdict(int)
for i in range(n):
kt[t[i]] += 1
l,r,useful,lp,rp = 0,0,0,0,m + n
for r,c in enumerate(s):
if c in kt:
kt[c] -= 1
if kt[c] >= 0:
useful += 1
while useful == n:
if r - l < rp - lp:
lp,rp = l,r
lc = s[l]
if lc in kt:
kt[lc] += 1
if kt[lc] > 0:
useful -= 1
l += 1
if rp < m + n:
ans = s[lp:rp + 1]
return ans
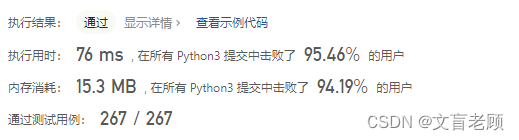
到这里就已经是极限了,即使按着56ms 大佬的思路来,自己写出来也就这样了
77. 组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
示例 2:
输入:n = 1, k = 1
输出:[[1]]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/combinations
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
先暴力来一次
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
if n == k:
return [[v + 1 for v in range(n)]]
ans = []
def dfs(v,r):
if len(r) == k:
ans.append(r)
return
for i in range(v,n + 1):
dfs(i + 1,r + [i])
dfs(1,[])
return ans

然后优化下分支判断
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
if n == k:
return [[v + 1 for v in range(n)]]
ans = []
def dfs(v,r):
if len(r) == k:
ans.append(r)
return
for i in range(v,n + 1):
if k <= n - i + 1 + len(r):
dfs(i + 1,r + [i])
dfs(1,[])
return ans

这差距还是蛮大的啊
这头部的答案都是什么?itertools 没用过啊。。。比我成绩好的,清一色用这个,还说是官方推荐使用的包。。。。
78. 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/subsets
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
没什么可说的,递归穷举吧
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
ans = []
def dfs(n,r):
ans.append(r)
for i in range(n,len(nums)):
if nums[i] not in r:
dfs(i + 1,r + [nums[i]])
dfs(0,[])
return ans
大佬太多了。。。。。
然后发现,我多写了个判断
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
ans = []
def dfs(n,r):
ans.append(r)
for i in range(n,len(nums)):
dfs(i + 1,r + [nums[i]])
dfs(0,[])
return ans
79. 单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
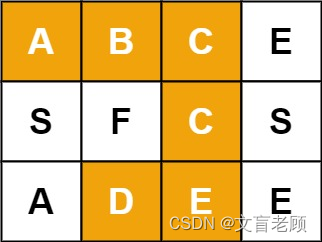
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCCED”
输出:true
示例 2:
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “SEE”
输出:true
示例 3:
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCB”
输出:false
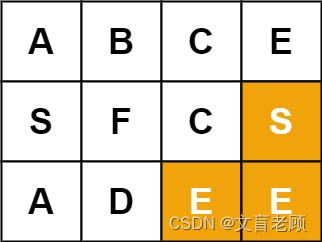

来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/word-search
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
在没有学习任何算法前,老顾先用暴力方式完成一次提交
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m,n = len(board),len(board[0])
def findString(s,arr):
i,j = arr[-1]
if word == s:
return True
nxt = word[len(s)]
if next == '':
return True
if i > 0 and [i - 1,j] not in arr and board[i - 1][j] == nxt:
if findString(s + nxt,arr + [[i - 1,j]]):
return True
if j > 0 and [i,j - 1] not in arr and board[i][j - 1] == nxt:
if findString(s + nxt,arr + [[i,j - 1]]):
return True
if i < m - 1 and [i + 1,j] not in arr and board[i + 1][j] == nxt:
if findString(s + nxt,arr + [[i + 1,j]]):
return True
if j < n - 1 and [i,j + 1] not in arr and board[i][j + 1] == nxt:
if findString(s + nxt,arr + [[i,j + 1]]):
return True
return False
for i in range(m):
for j in range(n):
if board[i][j] == word[0] and findString(word[0],[[i,j]]):
return True
return False
竟然不是最后5%。。。
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m,n = len(board),len(board[0])
def findString(s,pos,d):
i,j = pos
d.add(i * 10 + j)
if word == s:
return True
nxt = word[len(s)]
if i > 0 and board[i - 1][j] == nxt and (i - 1) * 10 + j not in d:
if findString(s + nxt,[i - 1,j],set().union(d)):
return True
if j > 0 and board[i][j - 1] == nxt and i * 10 + j - 1 not in d:
if findString(s + nxt,[i,j - 1],set().union(d)):
return True
if i < m - 1 and board[i + 1][j] == nxt and (i + 1) * 10 + j not in d:
if findString(s + nxt,[i + 1,j],set().union(d)):
return True
if j < n - 1 and board[i][j + 1] == nxt and i * 10 + j + 1 not in d:
if findString(s + nxt,[i,j + 1],set().union(d)):
return True
return False
for i in range(m):
for j in range(n):
if board[i][j] == word[0] and findString(word[0],[i,j],set()):
return True
return False
将验证信息放到集合里,效率搞了一点,居然提高了30%。。。
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m,n = len(board),len(board[0])
s = set(word)
d = {}
for i in range(m):
for j in range(n):
l = board[i][j]
k = i * 10 + j
if l in s:
if l in d:
d[l].add(k)
else:
d[l] = {k}
if len(s - set(d)) > 0:
return False
def findPath(pos,pth):
if pos >= len(word):
return True
l = word[pos]
for v in d[l]:
if v not in pth:
if len(pth) == 0 or (v % 10 == pth[-1] % 10 and abs(v // 10 - pth[-1] // 10) == 1) or (v // 10 == pth[-1] // 10 and abs(v %10 - pth[-1] % 10) == 1):
if findPath(pos + 1,pth + [v]):
return True
if findPath(0,[]):
return True
return False
又换了个写法,这次,直接扫描一遍表,把最后单词中出现的字母都扫描到字典里,然后按字典去找匹配,又提高了20%多。。。
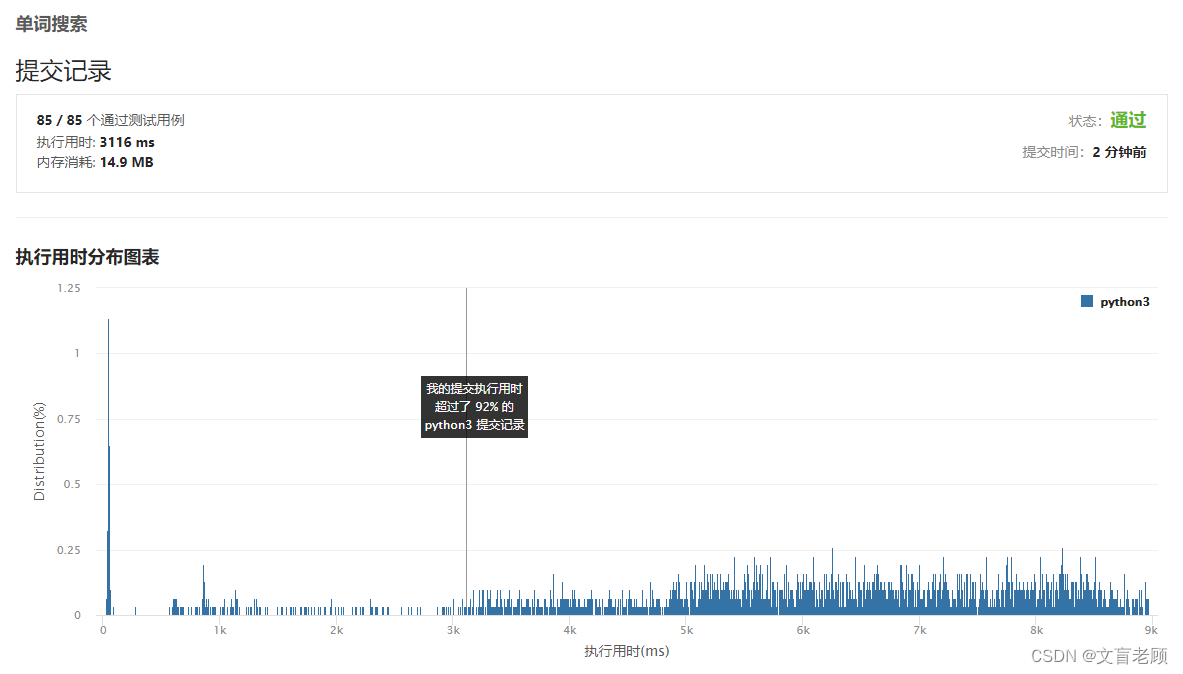
忍不住看了眼执行时间分布。。。好家伙。。。居然有40ms的?我再琢磨琢磨,实在不行了再参考前边的答案
先抄了官方题解的python答案,一运行。。。
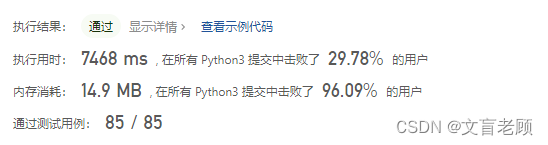
垃圾官方题解。。。。又一番琢磨,从新调整了下判断方式,了解到集合里可以存放元组
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m,n,ar = len(board),len(board[0]),((0,1),(0,-1),(1,0),(-1,0))
w = Counter(word)
d = Counter(chain(*board))
for k in w:
if k not in d:
return False
if w[k] > d[k]:
return False
def dfs(pos,pth):
c = len(pth)
if c == len(word):
return True
i,j = pos
l = word[c]
if board[i][j] != l:
return False
if c + 1 == len(word):
return True
for r in ar:
if 0 <= i + r[0] < m and 0 <= j + r[1] < n:
if (i + r[0],j + r[1]) not in pth:
if dfs((i + r[0],j + r[1]),{pos}.union(pth)):
return True
for i in range(m):
for j in range(n):
if dfs((i,j),set()):
return True
return False
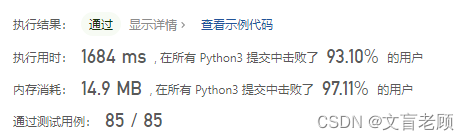
又有一点提升,进步就是这么一点一点尝试出来的
然后,现在明确的知道,用例中有这么一个
board = [
[‘a’,‘a’,‘a’,‘a’,‘a’,‘a’]
,[‘a’,‘a’,‘a’,‘a’,‘a’,‘a’]
,[‘a’,‘a’,‘a’,‘a’,‘a’,‘a’]
,[‘a’,‘a’,‘a’,‘a’,‘a’,‘a’]
,[‘a’,‘a’,‘a’,‘a’,‘b’,‘a’]
,[‘a’,‘a’,‘a’,‘a’,‘b’,‘a’]
]
word = ‘aaaaaaaaaaaaaabb’ # 反正就是很多a
现在所有时间比较长的结果,都是倒在这里的。。。。当然这个用例,如果我们把 word reverse 一下,当然会很快了。。。但如果用例是 word = ‘baaaaaaaaaaaaaaab’ 呢。。。。。让我死了吧,反正,在没有新的想法路子之前,搜索的效率也就这样了
然后在翻看答案的时候(只找比较接近的执行时间的,先不看28ms的),在880ms那里得到一个启发,判断入口比较少的作为起点,反正找单词,正向找和逆向找是一样的结果。可是,什么刚才我提到用例的时候,已经想到字符串翻转了,为什么不写出来看看呢?于是,再改一版
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
m,n,ar = len(board),len(board[0]),((0,1),(0,-1),(1,0),(-1,0))
w = Counter(word)
d = Counter(chain(*board))
for k in w:
if k not in d:
return False
if w[k] > d[k]:
return False
def dfs(pos,pth):
c = len(pth)
if c == len(word):
return True
i,j = pos
l = word[c]
if board[i][j] != l:
return False
if c + 1 == len(word):
return True
for r in ar:
if 0 <= i + r[0] < m and 0 <= j + r[1] < n:
if (i + r[0],j + r[1]) not in pth:
if dfs((i + r[0],j + r[1]),{pos}.union(pth)):
return True
rev = word[::-1] # 取 word 的翻转字符串
for i in range(len(rev)):
if rev[i] != word[i]: # 碰到第一个不同的字符跳出比较
if d[rev[i]] < d[word[i]]: # 找这个不同字符入口较少的作为查找依据
word = rev
break
for i in range(m):
for j in range(n):
if dfs((i,j),set()):
return True
return False
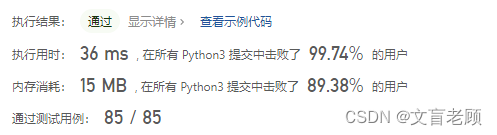
然后,得到的结果惊呆了老顾自己。。。。好家伙,就这么一个点子,直接进入到头部答案了。。。。
嗯。。虽然 baaaaaa…b 之类的还没解决,但目前也就这样了,其他头部答案估计也没必要参考了,唯一想不明白的是,为什么880ms的答案,已经用上字符串翻转了,还是这么长执行时间。。。
80. 删除有序数组中的重复项 II
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,1,2,3,3]
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 不需要考虑数组中超出新长度后面的元素。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-duplicates-from-sorted-array-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这个算是这次10题里最简单的了吧
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
if len(nums) < 3:
return len(nums)
i = 0
while i < len(nums) - 2:
while i < len(nums) - 2 and nums[i] == nums[i + 1] == nums[i + 2]:
nums.pop(i)
i += 1
return len(nums)
小结
这次10题,做的那叫一个艰辛,72,76都是最后做的,79陆陆续续的做了好几天,由于python也是刚接触,很多特性都是在做题中才了解到的,比如集合里不能放list,但是可以放tuple之类的小知识点
79题的感悟还是很深刻的,都已经测出用例了,也想到了翻转字符串,却没有实际去做,距离提高就差那么一小步
76题开始了解一些python指令的差异,并纠正了自己很多不良代码书写习惯
72题就真的很无语了。。。老顾真心是文盲,没上过大学啊,中学的知识也早在20年前丢光了啊。。。
还是慢慢补课吧,不需要学会,只要知道,以后就可以用到