HBase默认采用异步复制的方式同步数据,即客户端执行完put之后,RegionServer的后台线程不断地推送HLog的Entry到Peer集群。这种方式一般能满足大多数场景的需求,例如跨集群数据备份、HBase集群间数据迁移等。但是HBase 1.x版本的复制功能,无法保证Region迁移前后的HLog的Entry按照严格一致的顺序推送到备集群,某些极端情况下可能造成主从集群数据不一致。为此,社区在HBase 2.x版本上实现了串行复制来解决这个问题。
另外,默认的异步复制无法满足强一致性的跨机房热备需求。因为备份机房的数据肯定会落后主集群,一旦主集群异常,无法直接切换到备份集群,因此,社区提出并研发了同步复制。
一、复制场景及原理
1,场景
现在有一个SSD的HBase集群被业务方A访问,业务方A对HBase集群的延迟和可用性要求非常高。现在又收到业务方B的需求,希望对表TableX跑数据分析任务(用MapReduce或者Spark来实现)。对HBase来说,这种任务都是用大量的scan去扫全表来实现的。如果直接去扫SSD在线集群,会极大影响集群的延迟和可用性,对业务方A来说不可接受。另外,业务方B的数据分析任务是一个每天定期跑的任务,希望每次分析的数据都尽可能是最新的数据。
如何解决这个问题?,思路是用一批成本较低的HDD机器搭建一个离线的HBase集群,然后把表TableX的全量数据导入离线集群,再通过复制把增量数据实时地同步到离线集群,业务方B的分析任务直接跑在离线集群上。这样既满足了业务方B的需求,又不会对业务方A造成任何影响。
操作步骤:
(1)先确认表TableX的多个Column Family都已经将REPLICATION_SCOPE设为1。
(2)在SSD集群上添加一条DISABLED复制链路,提前把主集群正在写入的HLog堵在复制队列中。
add_peer '100', CLUSTER_KEY => "zk1,zk2,zk3:11000:/hbase-hdd", STATE => "DISABLED",
TABLE_CFS => { "TableX" => []
(3)对TableX做一个Snapshot,并用HBase内置的ExportSnapshot工具把Snapshot拷贝到离线集群上。注意,不要使用distcp拷贝snapshot,因为容易在某些情况下造成数据丢失。
(4)待Snapshot数据拷贝完成后,从Snapshot中恢复一个TableX表到离线集群。
(5)打开步骤1中添加的Peer:
enable_peer '100'
(6)等待peer=100,所有堵住的HLog都被在线集群推送到离线集群,也就是两个集群的复制延迟等于0,就可以开始在离线集群上跑分析任务了。
注意:为什么需要在步骤2创建一个DISABLED的Peer?
因为步骤3要完成Snapshot到离线集群的拷贝,可能需要花费较长时间。业务方A在此期间会不断写入新数据到TableX,如果不执行步骤2,则会造成离线集群丢失在拷贝Snapshot过程中产生的增量数据,造成主备集群数据不一致。提前创建一个DISABLED的Peer,可以使拷贝Snapshot过程中产生的增量数据都能堆积在Peer的复制队列中,直到拷贝Snapshot完成并enable_peer之后,由在线集群的RegionServer把这一段堵在复制队列中的HLog慢慢推送到离线集群。这样就能保证在线集群和离线集群数据的最终一致性。
2,管理流程的设计和问题
复制功能在HBase 1.x版本上实现的较为粗糙。Peer是指一条从主集群到备份集群的复制链路。一般在创建Peer时,需要指定PeerId、备份集群的ZooKeeper地址、是否开启数据同步,以及需要同步的namespace、table、column family等,甚至还可以指定这个复制链路同步到备份集群的数据带宽。
在HBase 1.x版本中,创建Peer的流程大致如下:HBase客户端在ZooKeeper上创建一个ZNode,创建完成之后客户端返回给用户创建Peer成功。这时HBase的每一个RegionServer会收到创建ZNode的Watch Event,然后在预先注册的CallBack中添加一个名为ReplicationSource,的线程。该Peer在ZooKeeper上维持一个HLog复制队列,写入时产生的新HLog文件名会被添加到这个复制队列中。同时,ReplicationSource不断地从HLog复制队列中取出HLog,然后把HLog的Entry逐个推送到备份集群。
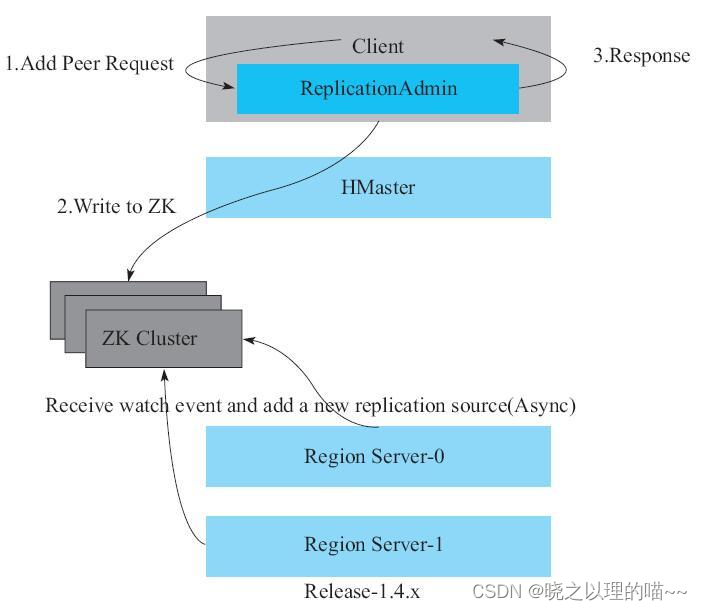
注意:在HBase 1.x版本的复制功能实现上,存在一些比较明显的问题:
(1)暴露太大的ZooKeeper权限给客户端。HBase客户端必须拥有写ZooKeeper的ZNode的权限,若用户误写ZooKeeper节点,则可能造成灾难性的问题。
(2)创建、删除、修改Peer这些操作都直接请求ZooKeeper实现,不经过RegionServer或者Master服务,HBase服务端无法对请求进行认证,也无法实现Coprocessor。
(3)HBase写了ZNode就返回给客户端。RegionServer添加ReplicationSource线程是异步的,因此客户端无法确认是否所有的RegionServer都成功完成Replication线程创建。若有某一个RegionServer初始化复制线程失败,则会造成该Peer同步阻塞。另外,这种方式也无法实现后续较为复杂的管理流程,如串行复制和同步复制。
3,复制原理
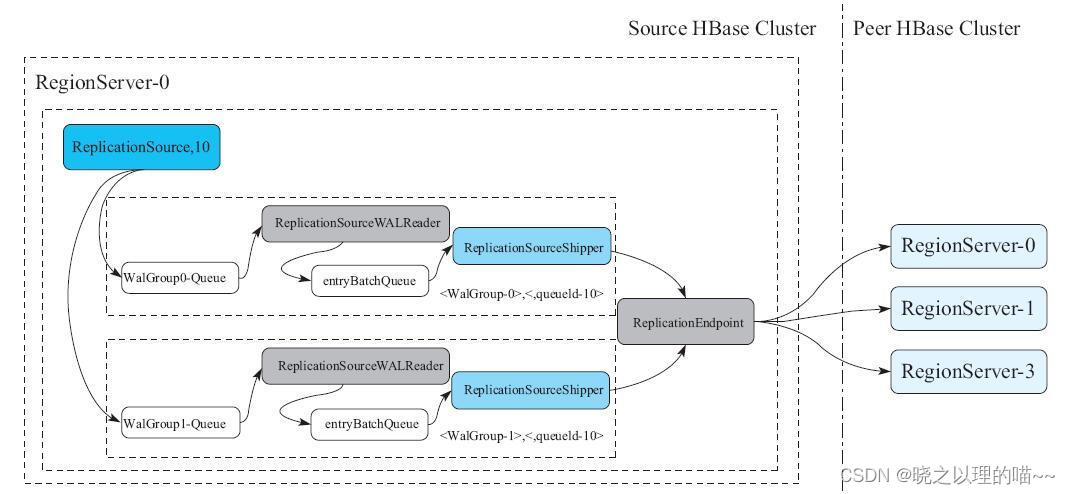
数据复制的基本流程:
(1)在创建Peer时,每一个RegionServer会创建一个ReplicationSource线程(线程名:replicationSource,10,这里10表示PeerId)。ReplicationSource首先把当前正在写入的HLog都保存在复制队列中。然后在RegionServer上注册一个Listener,用来监听HLog Roll操作。如果RegionServer做了HLog Roll操作,那么ReplicationSource收到这个操作后,会把这个HLog分到对应的walGroup-Queue里面,同时把HLog文件名持久化到ZooKeeper上,这样重启后还可以接着复制未复制完成的HLog。
(2))每个WalGroup-Queue后端有一个ReplicationSourceWALReader的线程,这个线程不断地从Queue中取出一个HLog,然后把HLog中的Entry逐个读取出来,放到一个名为entryBatchQueue的队列内。
(3))entryBatchQueue队列后端有一个名为ReplicationSourceShipper的线程,不断从Queue中取出Log Entry,交给Peer的ReplicationEndpoint。ReplicationEndpoint把这些Entry打包成一个replicateWALEntry操作,通过RPC发送到Peer集群的某个RegionServer上。对应Peer集群的RegionServer把replicateWALEntry解析成若干个Batch操作,并调用batch接口执行。待RPC调用成功之后,ReplicationSourceShipper会更新最近一次成功复制的HLog Position到ZooKeeper,以便RegionServer重启后,下次能找到最新的Position开始复制。
注意问题:
(1)为什么需要把HLog分成多个walGroup-Queue?
一个Peer可能存在多个walGroup-Queue,因为现在RegionServer为了实现更高的吞吐量,容许同时写多个WAL(HBASE-5699),同时写的N个WAL属于N个独立的Group。所以,在一个Peer内,为每一个Group设置一个walGroup-Queue。一种常见的场景是,为每个业务设置一个namespace,然后每个namespace写自己独立的WAL,不同的WAL Group通过不同的复制线程去推,这样如果某个业务复制阻塞了,并不会影响其他的业务(因为不同的namespace产生的HLog会分到不同的walGroup-Queue)。
(2)哪些复制相关的信息是记录在ZooKeeper的?
复制过程中主要有两个重要的信息存放在ZooKeeper上:
1)Peer相关的信息
2)每个RegionServer都在/hbase/replication/rs下有一个独立的目录,用来记录这个Peer下有哪些HLog,以及每个HLog推送到哪个Position。
二、串行复制
1,非串行复制导致的问题
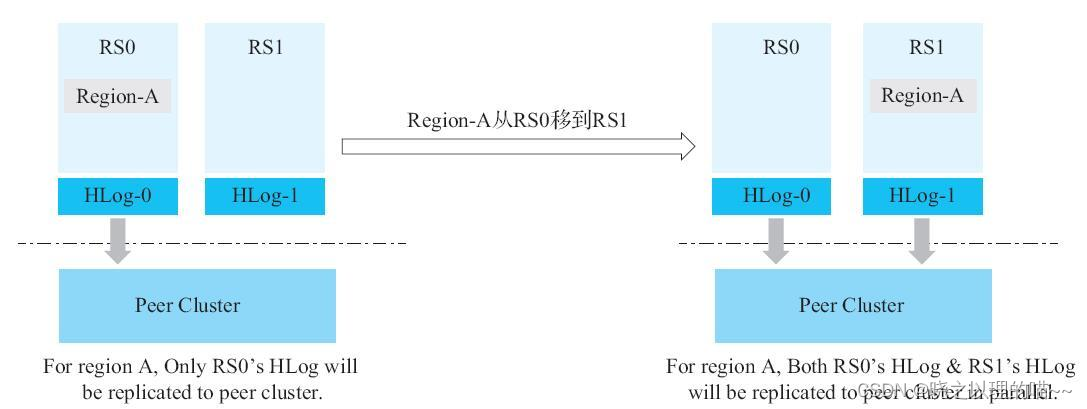
设想这样一个场景:现在有一个源集群往Peer集群同步数据,其中有一个Region-A落在RegionServer0(简称RS0)上。此时,所有对Region-A的写入,都会被记录在RegionServer0对应的HLog-0内。但是,一旦Region-A从RegionServer0移到RegionServer1上,之后所有对Region-A的写入,都会被RegionServer1记录在对应的HLog-1内。这时,就至少存在两个HLog同时拥有Region-A的写入数据了,而RegionServer0和RegionServer1都会为Peer开一个复制线程(ReplicationSource)。也就是说,RegionServer0和RegionServer1会并行地把HLog-0和HLog-1内包含Region-A的数据写入Peer集群。
不同的RegionServer并行地把同一个Region的数据往Peer集群推送,主要注意的问题:
第一个问题:
写入操作在源集群的执行顺序和Peer集群的执行顺序不一致。
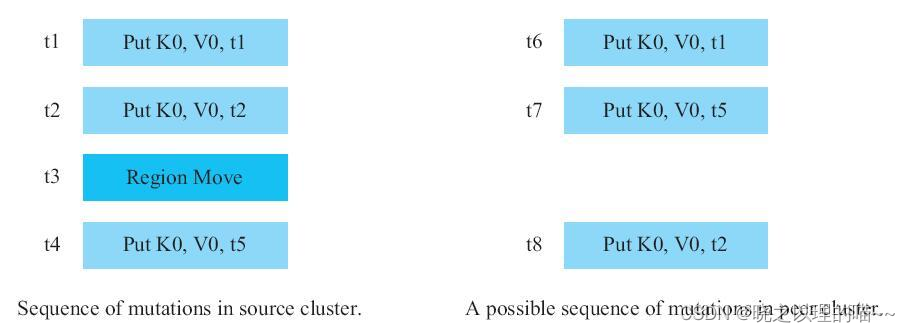
Region-A在源集群的写入顺序为:
1)t1时间点执行:Put,K0,V0,t1。
2)t2时间点执行:Put,K0,V0,t2。
3)在t3时间点,Region-A从RegionServer0移到RegionServer1上。
4)t4时间点执行:Put,K0,V0,t5。
由于RegionServer可能并行地把同一个Region的数据往Peer推送,那么数据到了Peer集群的写入顺序可能变成:
1)t6时间点执行:Put,K0,V0,t1。
2)t7时间点执行:Put,K0,V0,t5。
3)t8时间点执行:Put,K0,V0,t2。
可以看到,时间戳为t5的Put操作反而在时间戳为t2的Put操作之前写入到Peer集群。那么,在Peer集群的[t7,t8)时间区间内,用户可以读取到t1和t5这两个版本的Put,但这种状态在源集群是永远读取不到的。
对于那些依赖HBase复制功能的消息系统来说,这意味着消息的发送顺序可能在复制过程中被颠倒。对那些要求消息顺序严格一致的业务来说,发生这种情况是不可接受的。
第二个问题:
在极端情况下,可能导致主集群数据和备集群数据不一致。

由于写入操作在Peer集群执行可能乱序,左侧源集群的写入顺序到了Peer集群之后,就可能变成如右侧所示写入顺序。如果Peer集群在t7和t9之间,执行了完整的Major Compaction,那么执行Major Compaction之后,K0这一行数据全部都被清理,然后在t9这个时间点,时间戳为t2的Put开始在Peer集群执行。
这样最终导致的结果就是:源集群上rowkey=K0的所有cell都被清除,但是到了Peer集群,用户还能读取到一个多余的Put(时间戳为t2)。在这种极端情况下,就造成主备之间最终数据的不一致。对于要求主备集群最终一致性的业务来说,同样不可接受。
2,串行复制的设计思路
为了解决非串行复制的问题,先思考一下产生该问题的原因。根本原因在于,Region从一个RegionServer移动到另外一个RegionServer的过程中,Region的数据会分散在两个RegionServer的HLog上,而两个RegionServer完全独立地推送各自的HLog,从而导致同一个Region的数据并行写入Peer集群。
解决思路就是:把Region的数据按照Region移动发生的时间点t0分成两段,小于t0时间点的数据都在RegionServer0的HLog上,大于t0时间点的数据都在RegionServer1的HLog上。让RegionServer0先推小于t0的数据,等RegionServer0把小于t0的数据全部推送到Peer集群之后,RegionServer1再开始推送大于t0的数据。这样,就能保证Peer集群该Region的数据写入顺序完全和源集群的顺序一致,从而解决非串行复制带来的问题。
从整个时间轴上来看,Region可能会移动N次,因此需要N个类似t0这样的时间点,把时间轴分成N+1个区间。只要依次保证第i(0≤i<N)个区间的数据推送到Peer集群之后,再开始推送第i+1个区间的数据,那么非串行复制的问题就能解决。
HBase社区版本的实现有三个重要的概念:
(1)Barrier:和上述思路中t0的概念类似。具体指的是,每一次Region重新Assign到新的RegionServer时,新RegionServer打开Region前能读到的最大SequenceId(对应此Region在HLog中的最近一次写入数据分配的Sequence Id)。因此,每Open一次Region,就会产生一个新的Barrier。Region在Open N次之后,就会有N个Barrier把该Region的SequenceId数轴划分成N+1个区间。
(2)LastPushedSequenceId:表示该Region最近一次成功推送到Peer集群的HLog的SequenceId。事实上,每次成功推送一个Entry到Peer集群之后,都需要将LastPushedSequenceId更新到最新的值。
(3)PendingSequenceId:表示该Region当前读到的HLog的SequenceId。
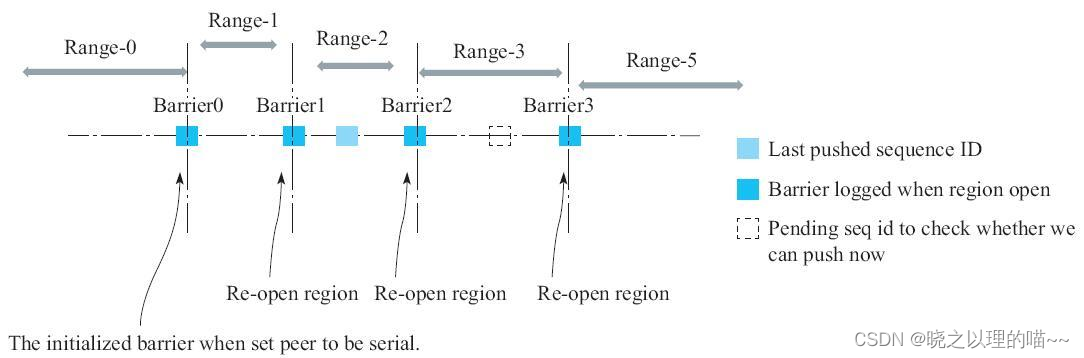
HBase集群只要对每个Region都维护一个Barrier列表和LastPushedSequenceId,就能按照规则确保在上一个区间的数据完全推送之后,再推送下一个区间的数据。以图10-7所示的情况为例,LastPushedSeqenceId在Range-2区间内,说明Range-2这个区间有一个RegionServer正在推送该Region的数据,但是还没有完全推送结束。那么,负责推送Range-3区间的RegionServer发现上一个区间的HLog还没有完全推送结束,就会休眠一段时间之后再检查一次上一个区间是否推送结束,若推送结束则开始推本区间的数据;否则继续休眠。
串行复制功能由小米HBase研发团队设计并提交到社区,目前已经整合到HBase 2.x分支。对此功能有需求的读者,可以尝试使用此功能。
三、同步复制
通常,我们所说的HBase复制指的是异步复制,即HBase客户端写入数据到主集群之后就返回了,然后主集群再异步地把数据依次推送到备份集群。这样存在的一个问题是,若主集群因意外或者Bug无法提供服务时,备份集群的数据是比主集群少的。这时,HBase的可用性将受到极大影响,如果把业务切换到备份集群,则必须接受备份集群比主集群少的这个事实。
事实上,有些在线服务业务对可用性和数据一致性要求极高,这些业务期望能为在线集群搭建备份集群,一旦主集群可用性发生抖动,甚至无法提供服务时,就马上切换到备份集群上去,同时还要求备份集群的数据和主集群数据保持一致。这种需求是异步复制没法保证的,而HBase 2.1版本上实现的同步复制可以满足这类需求。
1,设计思路
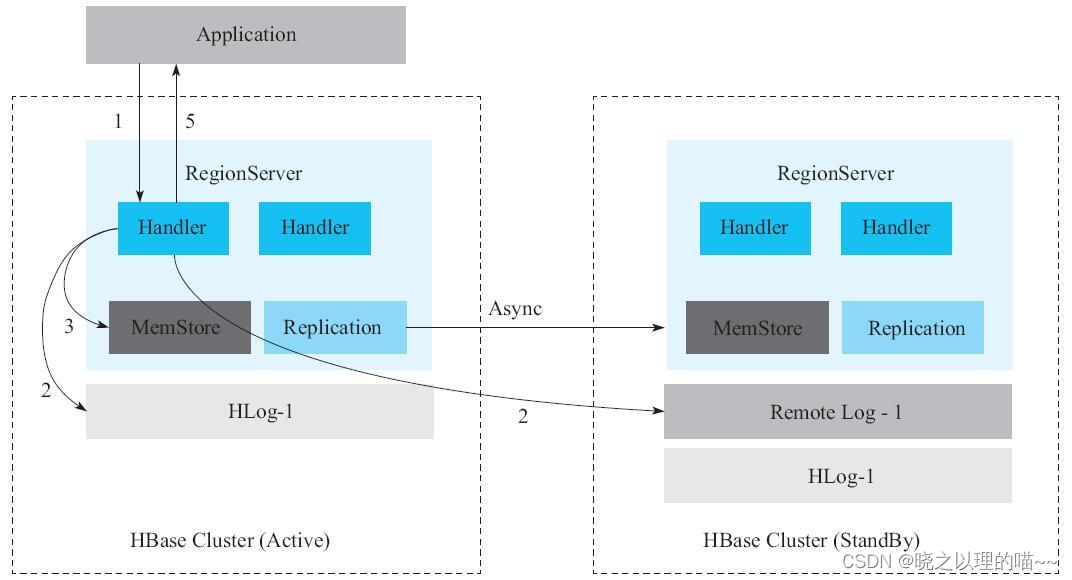
同步复制的核心思想是,RegionServer在收到写入请求之后,不仅会在主集群上写一份HLog日志,还会同时在备份集群上写一份RemoteWAL日志,如图10-8所示。只有等主集群上的HLog和备集群上的RemoteWAL都写入成功且MemStore写入成功后,才会返回给客户端,表明本次写入请求成功。除此之外,主集群到备集群之间还会开启异步复制链路,若主集群上的某个HLog通过异步复制完全推送到备份集群,那么这个HLog在备集群上对应的RemoteWAL则被清理,否则不可清理。因此,可以认为,RemoteWAL是指那些已经成功写入主集群但尚未被异步复制成功推送到备份集群的数据。
对主集群的每一次写入,备份集群都不会丢失这次写入数据。一旦主集群发生故障,只需要回放RemoteWAL日志到备集群,备集群马上就可以为线上业务提供服务。这就是同步复制的核心设计。
2,集群复制的几种状态
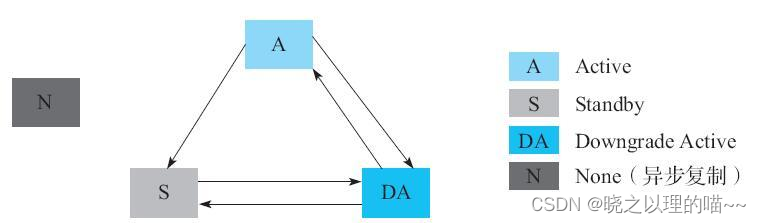
为了方便实现同步复制,我们将主集群和备集群的同步复制状态分成4种
(1)Active(简称A):这种状态的集群将在远程集群上写RemoteWAL日志,同时拒绝接收来自其他集群的复制数据。一般情况下,同步复制中的主集群会处于Active状态。
(2)Downgrade Active(简称DA):这种状态的集群将跳过写RemoteWAL流程,同时拒绝接收来自其他集群的复制数据。一般情况下,同步复制中的主集群因备份集群不可用卡住后,会被降级为DA状态,用来满足业务的实时读写。
(3)Standby(简称S):这种状态的集群不容许Peer内的表被客户端读写,它只接收来自其他集群的复制数据。同时确保不会将本集群中Peer内的表数据复制到其他集群上。一般情况下,同步复制中的备份集群会处于Standby状态。
(4)None(简称N):表示没有开启同步复制。
集群的复制状态是可以从其中一种状态切换到另外一种状态的。
3, 建立同步复制

建立同步复制过程有三步:
(1)在主集群和备份集群分别建立一个指向对方集群的同步复制Peer。这时,主集群和备份集群的状态默认为DA。
(2)通过transit_peer_sync_replication_state命令将备份集群的状态从DA切换成S。
(3)将主集群状态从DA切换成A。
4,备集群故障处理流程
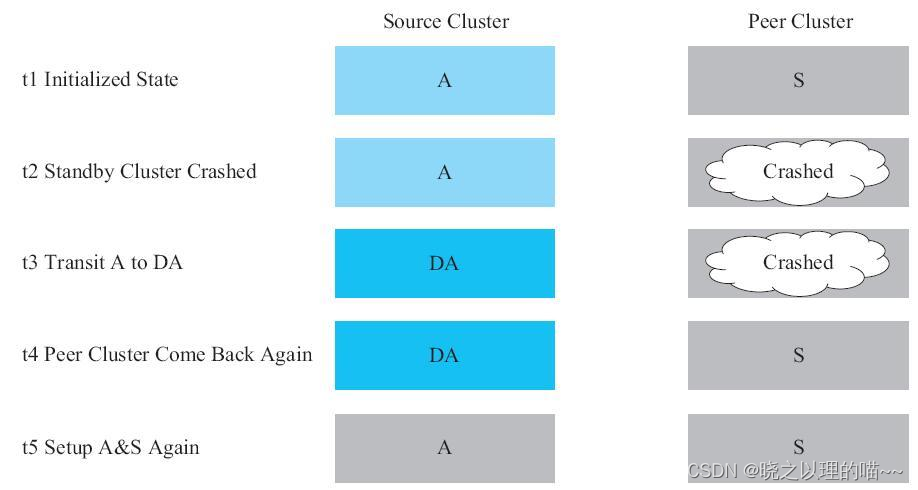
当备份集群发生故障时,处理流程:
(1)先将主集群状态从A切换为DA。因为此时备份集群已经不可用,那么所有写入到主集群的请求可能因为写RemoteWAL失败而失败。我们必须先把主集群状态从A切成DA,这样就不需要写RemoteWAL了,从而保证业务能正常读写HBase集群。后续业务的写入已经不是同步写入到备份集群了,而是通过异步复制写入备份集群。
(2)在确保备份集群恢复后,可以直接把备份集群状态切换成S。在第1步到第2步之间的数据都会由异步复制同步到备份集群,第2步后的写入都是同步写入到备份集群,因此主备集群数据最终是一致的。
(3)最后把主集群状态从DA切换成A。
5,主集群故障处理流程
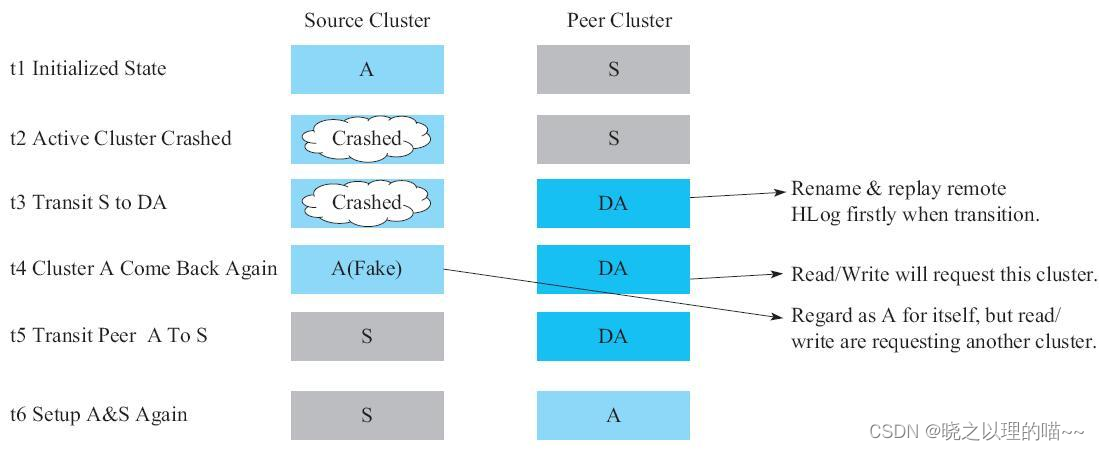
当主集群发生故障时,处理流程:
(1)先将备份集群状态从S切换成DA,切换成DA之后备份集群将不再接收来自主集群复制过来的数据,此时将以备份集群的数据为准。注意,S状态切换成DA状态的过程中,备集群会先回放RemoteWAL日志,保证主备集群数据一致性后,再让业务方把读写流量都切换到备份集群。
(2)t4时间点,主集群已经恢复,虽然业务已经切换到原来的备集群上,但是原来的主集群还认为自己是A状态。
(3)t5时间点,在上面“建立同步复制”中提到,备份集群建立了一个向主集群复制的Peer,由于A状态下会拒绝所有来自其他集群的复制请求,因此这个Peer会阻塞客户端写向备集群的HLog。这时,我们直接把原来的主集群切换成S状态,等原来备集群的Peer把数据都同步到主集群之后,两个集群的数据将最终保持一致。
(4)t6时间点,把备集群状态从DA切换成A,继续开启同步复制保持数据一致性。
四、同步复制和异步复制对比
1,读路径
异步复制:无影响
同步复制:无影响
2,写路径
异步复制:无影响
同步复制:需要写一份Remote WAL
3,网络带宽
异步复制:需要占用集群的1倍带宽。
同步复制:需要占用2倍宽带,其中1倍来自实现异步复制,另外1倍实现Remote WAL。
4,存储空间
异步复制:无需占用额外的存储空间。
同步复制:Remote WAL会占用1倍WAL存储空间
5,最终一致性
异步复制:若主集群无法恢复,则无法保 证数据的最终一致性。
同步复制:总能保证数据的最终一致性
6,可用性
异步复制:若主集群故障,则业务不可用。
同步复制:若主集群故障,只需要很少时间回放Remote WAL便可提供服务,可用性更高。
7,运维复杂性
异步复制:运维操作简单。
同步复制:操作较为复杂,需要在理解当前集群的状态的情况下手动(或独立的服务)切换主备集群。
8,写入性能对比
针对同步复制和异步复制的写场景,社区用YCSB做了一次压力测试。目前HBase 2.1版本,同步复制的写入性能比异步复制的写入性能下降13%左右(HBASE-20751)。后续,社区会持续对同步复制的写入性能进行优化,为对同步复制有需求的用户提供更好的性能体验。
文章来源:《HBase原理与实践》 作者:胡争;范欣欣
文章内容仅供学习交流,如有侵犯,联系删除哦!