概述
Face Mesh是一个解决方案,可在移动设备上实时估计468个3D面部地标。它利用机器学习(ML)推断3D面部表面,只需要单个摄像头输入,无需专用深度传感器。利用轻量级模型架构以及整个管道中的GPU加速,该解决方案提供实时性能,对于实时体验至关重要。
此外,该解决方案还捆绑了Face Transform模块,弥合了面部地标估计和实用的实时增强现实(AR)应用之间的差距。它建立了一个度量的3D空间,并使用面部地标屏幕位置来估计该空间内的面部变换。

面部变换数据包括常见的3D基元,包括面部姿势变换矩阵和三角形面网格。在底层采用了一种轻量级的统计分析方法,称为Procrustes分析,以驱动强大、高效和可移植的逻辑。分析在CPU上运行,并在ML模型推断之上具有最小的速度/内存占用。
模型算法
我们的机器学习过程由两个实时深度神经网络模型组成,它们共同工作:一个检测器在完整图像上运行,并计算面部位置;一个3D面部地标模型在这些位置上运行,并通过回归预测近似的3D表面。准确地裁剪面部极大地减少了常见数据增强的需求,如由旋转、平移和缩放变化组成的仿射变换。
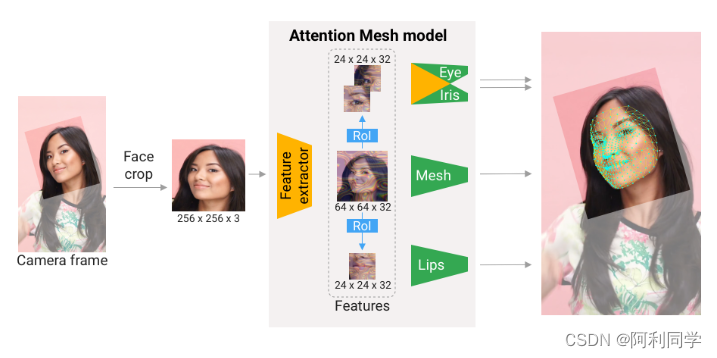
相反,它使网络能够将大部分容量专注于坐标预测准确性。此外,在我们的管道中,裁剪也可以基于上一帧中识别的面部地标生成,只有当地标模型无法再识别面部存在时,才会调用面部检测器重新定位面部。这种策略类似于我们的解决方案,它使用手掌检测器和手部地标模型。
该管道实现为使用面部地标模块中的面部地标子图的MediaPipe图,使用专用面部渲染器子图进行渲染。面部地标子图在内部使用来自面部检测模块的面部检测子图。
结论和代码
除了面部地标模型外,我们还提供另一个模型,它将注意力集中在语义上有意义的面部区域上,从而更准确地预测唇部、眼睛和虹膜周围的地标,但需要更多计算资源。它可以实现AR化妆和AR操纵等应用。

# For static images:
#全部代码 -----qq1309399183<---------
IMAGE_FILES = []
drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1)
with mp_face_mesh.FaceMesh(
static_image_mode=True,
max_num_faces=1,
refine_landmarks=True,
min_detection_confidence=0.5) as face_mesh:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
# Convert the BGR image to RGB before processing.
results = face_mesh.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# Print and draw face mesh landmarks on the image.
if not results.multi_face_landmarks:
continue
annotated_image = image.copy()
for face_landmarks in results.multi_face_landmarks:
print('face_landmarks:', face_landmarks)
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_tesselation_style())

![[数据结构与算法(严蔚敏 C语言第二版)]第1章 绪论(学习复习笔记)](https://img-blog.csdnimg.cn/dd1bb8c16e3f4cc8908ea592ae7d3c8b.png)