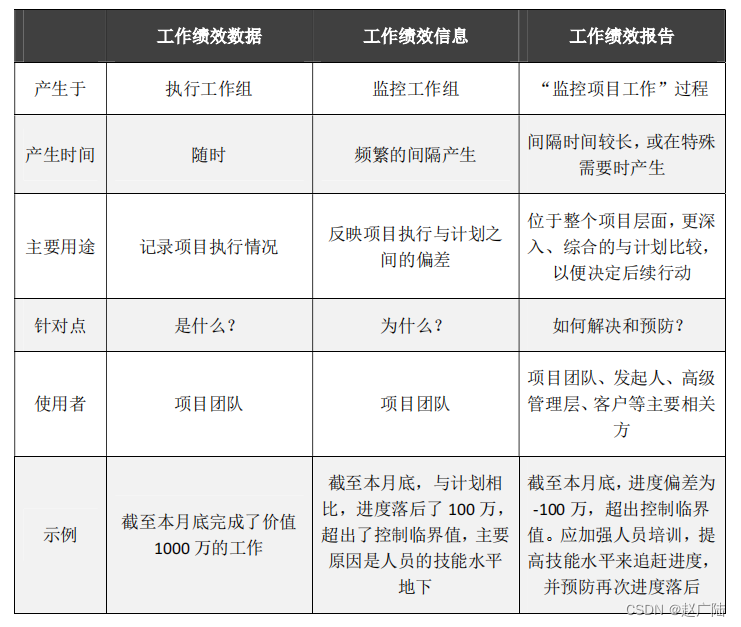
文章目录
- 1、RocksDB 摘要
- 1.1、RocksDB 特点
- 1.2、基本接口
- 1.3、编译
- 2、LSM - Tree
- 2.1、Memtable
- 2.2、WAL
- 2.3、SST
- 2.4、BlockCache
- 3、读写流程
- 3.1、读取流程
- 3.2、写入流程
- 4、LSM-Tree 放大问题
- 4.1、放大问题
- 4.2、compaction
RocksDB 是 Facebook 针对高性能磁盘开发开源的嵌入式持久化存储系统,采用了 WAL 机制和 LSM Tree 结构。RocksDB 所有类型的数据都是采用追加写,没有更新文件的操作。比较适合使用基于 Append Only 的高性能分布式文件系统。
1、RocksDB 摘要
1.1、RocksDB 特点
- 基于 LevelDB
- 嵌入式 KV 存储引擎
- 针对写密集型场景而提出的解决方案。例:日志系统、海量数据存储、海量数据分析
- 紧凑型存储。相同的数据量,更少的空间占用。
- 基于 LSM-Tree 的存储结构。
- 内存:MemTable
- 磁盘:SST | WAL
1.2、基本接口
- Open
- Get:获取 key
- Put:存放 key
- Delete:删除 key,具体在 compaction 中删除
- SingleDelete:针对从未修改过的 key,比 delete 删除快
- Merge:合并新写入的数据。带来大量的读数据请求,提前获取 Merge 的增量数据,然后进行合并。
- Iterator:通过给定的 key 批量获取符合条件的 KV 记录。
1.3、编译
# 1、RocksDB
git clone https://github.com/facebook/rocksdb.git
cd rocksdb
# 编译成调试模式
make
# 编译成发布模式
make static_lib
# 压缩库 Ubuntu
# gflags
sudo apt-get install libgflags-dev
# snappy
sudo apt-get install libsnappy-dev
# zlib
sudo apt-get install zlib1g-dev
# bzip2
sudo apt-get install libbz2-dev
# lz4
sudo apt-get install liblz4-dev
# zstandard
sudo apt-get install libzstd-dev
2、LSM - Tree
RocksDB 架构基于 LSM-Tree, log structured merge tree 存储结构,其核心就是利用顺序写来提升写性能。
LSM-Tree 组成
- 内存:可写的 MemTable + 只读的 Immutable Memtable
- 磁盘:WAL + 多层级 SST
LSM-Tree VS B+ Tree
- LSM-Tree:顺序写,追加更新。问题:数据冗余,需要后台线程 compaction
- B+ Tree:随机写,就地更新。问题:磁盘随机 IO < 磁盘顺序 IO,且锁粒度大
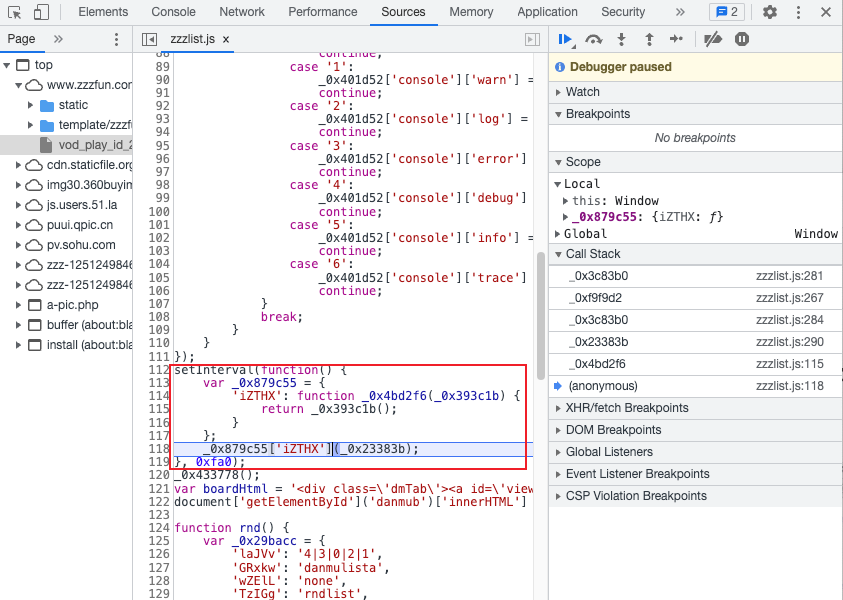
接下来,从整体上先介绍 RocksDB 架构图,如图所示:

用户的数据需要同时写到内存中的 Memtable 数据结构和磁盘 WAL 日志。可写的 Memtable 用于快速索引查询的缓存数据,并采用了跳表数据提升查找数据的速度。定时转换成只读的 Immutable Memtable,保存到 SST 文件中(flush 磁盘操作)。在此期间,若出现服务故障,重启系统会从 WAL 中将数据通过 Redo 的方式回复到 Memtable。
为了定期 compact (合并压缩)数据,将 Immutable Memtable 分为多个层次。Level 0 层允许数据重复,文件间无序,文件内部有序;Level 1 ~ Level N 没有数据重复,跨层可能有重复,文件间是有序的。数据逐层愈冷,压缩程度愈高。SST 文件为每一层的主要存储方式。
读取数据时,先读内存 Memtable,若没有再读磁盘 SST 文件。
参考论文:Chen G J, Wiener J L, Lyer S, et al. Realtime data processing at facebook[C]. Proceedings of the 2016 International Conference on Management of Data. 2016: 1087-1098.
2.1、Memtable
Memtable 内存数据结构,其中的数据总是最新的。同时服务于读和写,写操作先插入 Memtable;读数据先查询 Memtable。当 Memtable 写满,修改为只读的 Immutable Memtable,并被新的 Memtable 替换。后台线程会该 Immutable Memtable 异步落盘(flush)到一个 SST 文件,落盘后销毁 Memtable。
Memtable 基于跳表实现。跳表是多层级有序链表,其特点是:
- 从最高层次开始跳跃查找,并记录跳跃路径,查询时间
O(logn) - 找到待插入位置后,插入节点,并随机层高
- 根据跳跃路径,构建层级链表关系

跳表应用场景
- 范围查询
- 快速有序地列出所有的节点
- 并发粒度非常低。相较红黑树加锁整棵树,只将相邻的结点操作加锁
重要参数
# 一个 memtable 的大小
write_buffer_size
# 管理 memtable 使用的总内存数
db_write_buffer_size
# 刷盘到 SST 文件的最大 memtable 数
max_write_buffer_number
复习:其他常见的层级数据结构
- 跳表:多层级有序链表
- B+ 树:叶子节点包含所有的数据,非叶子节点只包含索引 key 信息
- 时间轮:按照定时任务到期时间轻重缓急进行分层
2.2、WAL
WAL, Write Ahead Log。RocksDB 中的 DML 操作同时写入内存 Memtable 和磁盘 WAL 日志文件。当系统崩溃时,WAL 日志可以完整恢复 Memtable 中的数据,以保 WAL中的数据通过 redo 的方式恢复到 Memtable。
重要参数
# WAL 文件的最大大小
DBOptions::max_total_wal_size
# WAL 文件的删除时间
DBOptions::WAL_ttl_seconds
2.3、SST
SST, Sorted String Table,有序键值对集合,是 LSM - Tree 在磁盘中的数据结构。与 B+ Tree 就地更新不同(找到元数据所在页并修改值),LSM-Tree 直接 append 写到磁盘,再同通过合并的方式取出冗余数据。
为了加快 key 的查询速度
- 建立索引
- 布隆过滤器(Bloom Filter):判断某个字符串一定不在该集合,若该字符串存在,可能有误差。
- 原理:位图 + N 个哈希算法。key 经过 N 个哈希后,若对应的位图是 0,则 key 不存在
- 场景限制:不支持删除 key,而 SST 本身不会被修改,所以可以使用。
SST 文件格式
- Footer:程序启动位置,存储 IndexBlock 和 MetaIndexBlock 的位置
- IndexBlock:存储 DataBlock 的位置
- MetaIndexBlock:存储了过滤元数据、属性信息、压缩字典索引的位置
- DataBlock:存储有序的数据记录

引用论文:Cho M, Choi W, Park S H. A Study on WAF reduction and SST file size on RocksDB[C]. Proceedings of the Korea Information Processing Society Conference. Korea Information Processing Society, 2017: 709-712
2.4、BlockCache
背景:内核 page cache 不可定制。因此,用户可以在内存中指定 RocksDB 缓存块,传一个 Cache 对象给 RocksDB 实例。一个缓存对象可以在同一个进程的多个 RocksDB 实例之间共享。块缓存存储未压缩过的块,也可以设置块缓存去存储压缩后的块。
RocksDB 两种类型的缓存都通过分片来减轻锁冲突,容量被平均分配到每个分片,分片间不共享空间。默认情况下,每个缓存会被分成 64 个分片,每个分片至少 512 B。
默认情况下,索引和过滤块都在 BlockCache 外面存储,用户可以选择将它们缓存在 BlockCache 中;
- LRUCache:基于 LRU 算法,lru 列表 + 哈希表。
- ClockCache:基于 Clock 算法,clock 指针 + 环形列表 + 哈希表。
与 LRU 缓存比较,Clock 缓存有更好的锁粒度。LRU 缓存读取数据时,需要对所有分片加互斥锁,因为需要更新的 LRU 列表;而在 Clock 缓存上读取数据时,不需要申请该分片的互斥锁,只需要搜索并行的哈希表。只有在插入的时候需要每个分片的锁,锁粒度更小。因此,一定环境下,Clock 缓存性能更好。
3、读写流程
3.1、读取流程
- 先读内存 memtable
- 若不存在,读磁盘 SST

SST 查找流程
FindFiles。从 SST 文件中查找,如果在 L0,那么每个文件都得读,因为 L0 不保证 key 不重叠;如果在更深的层,key 保证不重叠,每层只需要读一个 SST 文件即可。L1 开始,每层可以在内存中维护一个 SST 的有序区间索引,在索引上二分查找即可。LoadIB + FB。IB, index block是 SST block 的索引;FB, filter block是一个布隆过滤器,可以快速排除 key 不在的情况,因此优先加载。SearchIB。二分查找 index block,找到对应的 blockSearchFB。用布隆过滤器过滤,如果没有,则返回;LoadDB。加载 block 到内存;SearchDB。block 中继续二分查找;ReadValue。找到 key 后读数据。若考虑 WiscKey KV 分离的情况,还需要去 vLog 中读取
3.2、写入流程
- 写入磁盘 WAL 文件
- 写入内存 memtable
- memtable 大小达到阈值后,冻结成 immutable memtable。后续的写入交给新的 memtable 和 WAL
- 后台 compaction 线程,将 immutable memtable 落盘成 level 0 的 SST,持久化后释放对应的 WAL
- 若插入新的 SST 后,当前层 Li 的总文件大小超出阈值,会从 level i 挑出一个文件和 level i + 1 层的重叠文件合并,直到所有层的大小都小于阈值。合并过程中,保证 level 1 以后各 SST 的 key 不重叠
4、LSM-Tree 放大问题
4.1、放大问题
- 读放大:描述物理读取的字节数相较于返回的字节数之比。RocksDB 读取操作需要分层依次查找,直到找到对应数据,该过程可能涉及多次 IO
- 写放大:描述磁盘上存储的数据字节数相较于数据库包含的逻辑字节数之比。所有的写入操作都是顺序写,而不是就地更新,无效数据不会马上被清理掉。
- 空间放大:描述实际写入磁盘的数据大小和程序要求写入的数据大小之比。为了减小读放大和空间放大,RocksDB 采用后台线程合并数据的方式来解决,但会造成对同一条数据多次写入磁盘
4.2、compaction
rocksdb 默认采用 leveled compaction(leveled & tiered)合并算法。compaction 操作会造成写放大,但会减少读放大,空间放大。
除 L0 外,其他层级不会出现重复数据。
- leveled:每一层只有一个文件,且每一层文件大小是上一层的 10 倍
- tiered:将文件分成拆分成大小相同的部分
将相邻层的重复数据进行合并。同时,也可以并行 compaction