一.前言
(一).项目简介
高并发内存池(ConCurrentMemoryPool),其原型是google的开源项目tcmalloc。
全称是thread-cache-malloc,即线程缓存malloc。应用场景是多线程环境下管理内存,相较于malloc库函数而言,tcmalloc效率更高,多线程环境下完全可以替代malloc。其中go语言直接用tcmalloc作为内存分配器。
本项目实现了tcmalloc最核心的功能,可以理解为简化版tcmalloc。
tcmalloc源码如下:
https://gitee.com/mirrors/tcmalloc/tree/master
(二).环境和知识储备
环境:
本项目为linux和windows双环境,开发平台为VS2019。
知识储备:
1.常见的数据结构。如:链表、哈希桶
2.C/C++知识。如:类和对象、STL、编译与链接、指针等
3.操作系统知识。如:进程与线程、多线程调度、内存管理、互斥锁等
4.单例模式
...
(三).内存池——池化技术
内存池就是在向系统申请空间时,不是按照所需大小申请,而是提前申请一大片空间。当再次申请时就能够直接在提前申请的空间中拿。释放内存时同理,不是直接还给系统,而是先交还给申请的空间,当进程结束时统一释放给系统。这个提前申请的大片空间就叫做内存池,这种管理内存的机制就叫做池化技术。
内存池的好处是当程序频繁申请内存时能够减少系统调用的次数,从而提高程序效率。
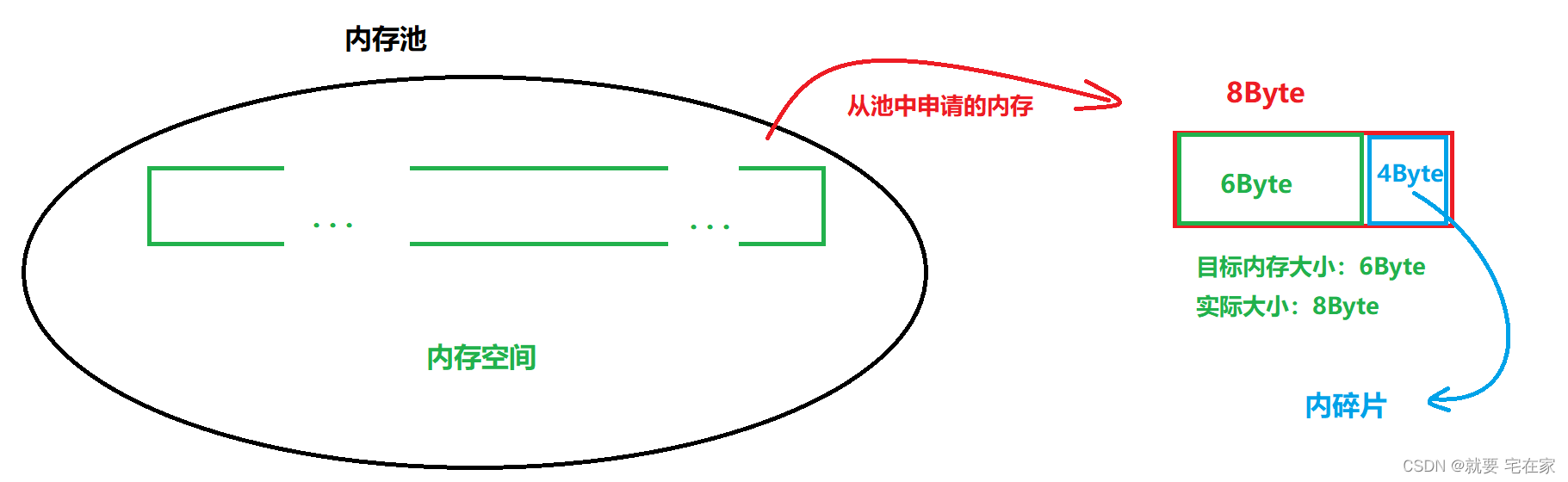
(四).内存碎片
内存池在提高效率同时需要解决内存碎片的问题,解决方式在正文中会讲解,这里主要阐述什么是内存碎片。
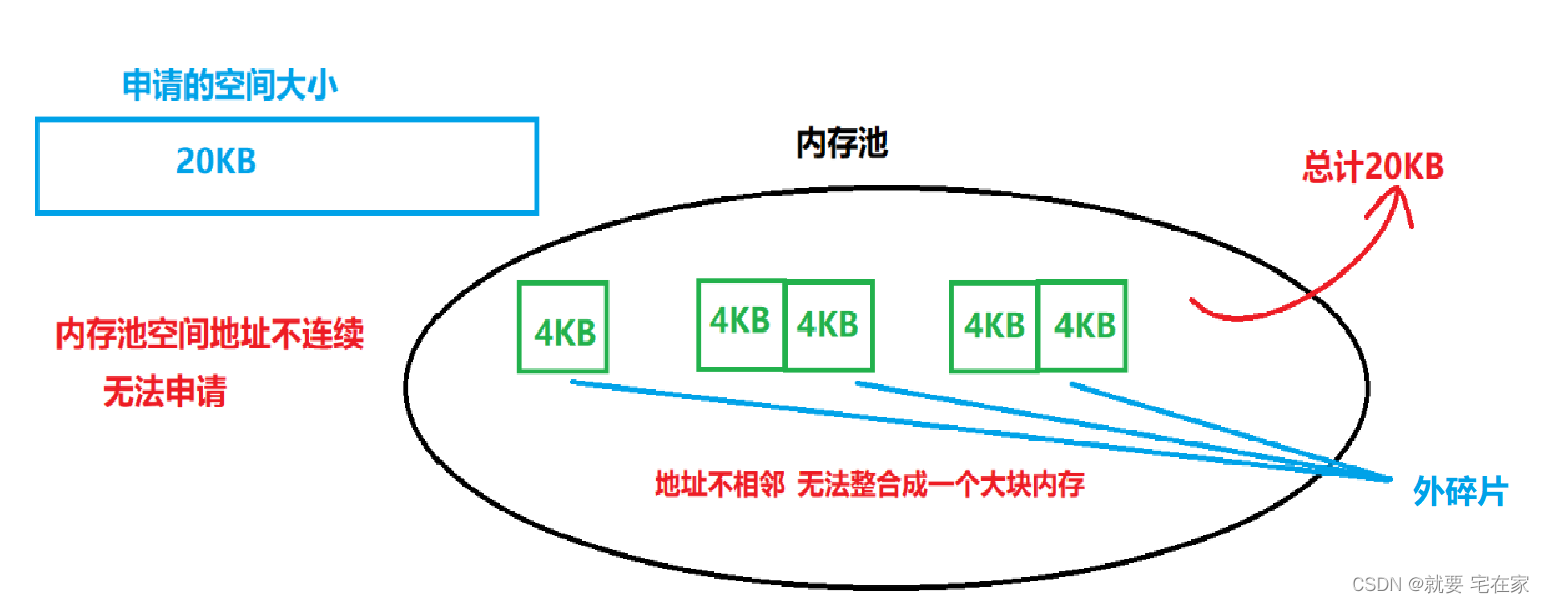
内存碎片分为外碎片和内碎片。
外碎片是指当前内存池中内存块是零散的,当有线程申请空间时,如果申请空间大小大于池中任何一块小内存但又小于现有池中空间总大小,依旧无法分配空间给线程,而这些池中“零散”的内存块就是外碎片。
图示如下:

内碎片是指申请内存时为了便于内存池管理内存,如果申请大小不是特定值时会进行内存对齐,分配给线程的内存大小大于申请值,这些大于申请值的空间就是内碎片。
图示如下:

二.高并发内存池总体结构和设计思路
首先,我们要清楚,设计高并发内存池的目的是为了解决malloc和free函数在多线程应用中的性能问题,当多线程环境中可能会频繁向系统申请内存,采用高并发内存池技术能够显著降低向系统申请内存的频次,旨在提高多线程编程中申请、释放内存的效率。因此基于池化技术,高并发内存池有三层缓存结构。结构上从小到大依次是thread cache线程缓存、central cache中心缓存、page cache页缓存。
高并发内存池整体结构示意图如下:

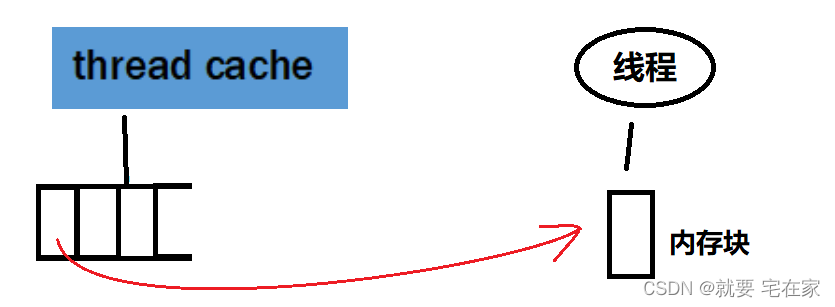
Thread Cache线程缓存的服务对象是具体的线程,因此每一个线程都有专属于自己的thread cache。thread cache内部会存储一部分内存,线程申请内存时直接从thread cache中申请。如果申请的内存大小thread cache给的起,那么内存对齐后将相关内存交给线程使用;如果申请的内存大小超过thread cache现有量,那么thread cache会向central cache中获取,然后交付给线程。也就是说从表面来看,线程永远都是直接从thread cache中获取内存,与线程直接接触的只有thread cache。
Central Cache中心缓存的服务对象是thread cache,并且每个进程中只有一个central cache。central cache内部也存有一部分内存,当thread cache没有能力直接给线程分配内存时,便会向central cache索取。central cache根据申请的内存大小,分配适量内存给thread cache(超过或等于申请大小,不存在小于的情况)。如果central cache内部存储的容量也不够就会向page cache申请,从page cache中获取内存后经过切分再将适量内存划分给thread cache。
Page Cache页缓存的服务对象是central cache,与central cahce一样每个进程中只有一个。page cahce提前从系统中获取一整块内存(1MB),当central cache向page cache申请内存时,便会分配一部分给central cache。如果page cache内部剩余的内存不够分配了,便会再次向系统申请(1MB)。也就是说,线程中所有申请的内存本质上是page cache从系统中获取的;换句话说,只有page cache会跟系统直接交互。
这里我们举个买书的例子来说明这三层缓存结构之间的关系。每个买书的顾客就是一个线程,书报亭就是thread cache,当地邮局就是central cache,邮政总局就是page cache,书籍制造厂就是系统。顾客从书报亭中购买书籍,而书报亭中书籍不够时就会向当地邮局订购一批书籍,当地邮局如果书籍不够了又会向邮政总局申请一大批该书籍,邮政总局又是从书籍制造厂手中直接采购书籍。也就是说内存是page cache通过系统申请后切一部分给central cache,central cache经过切分后再划分适量内存给thread cache,线程再从thread cache中拿走需求的内存。
当然,过程再细致一点来讲就是如下步骤,具体内容后续都会讲解,这里只需要有这个印象即可:
因为尚未接触内存池内部结构,因此流程图中尚有表述不明确的地方,比如thread cache是怎么管理这些内存块的,span的结构是什么都尚不能很好表述。
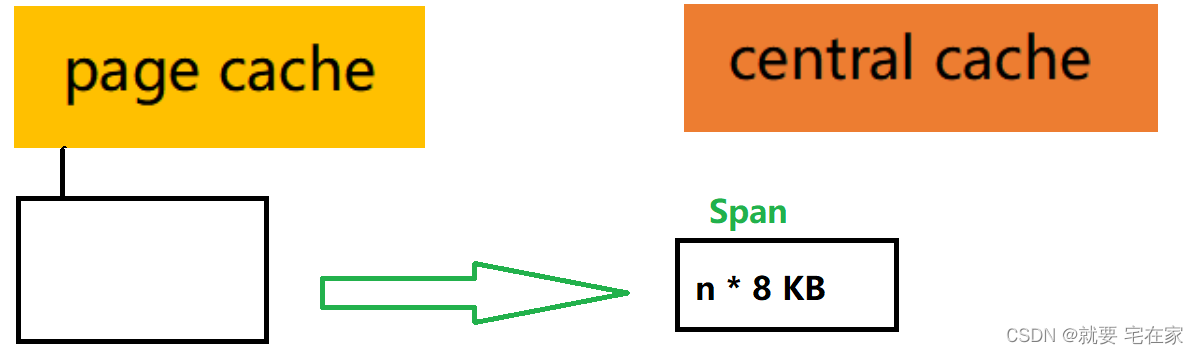
①系统分配1MB内存(可自定义)给page cache

②page cache再将(n * 8)KB内存分配给central cache,8KB称为一个页,这(n * 8)KB内存称为一个span。
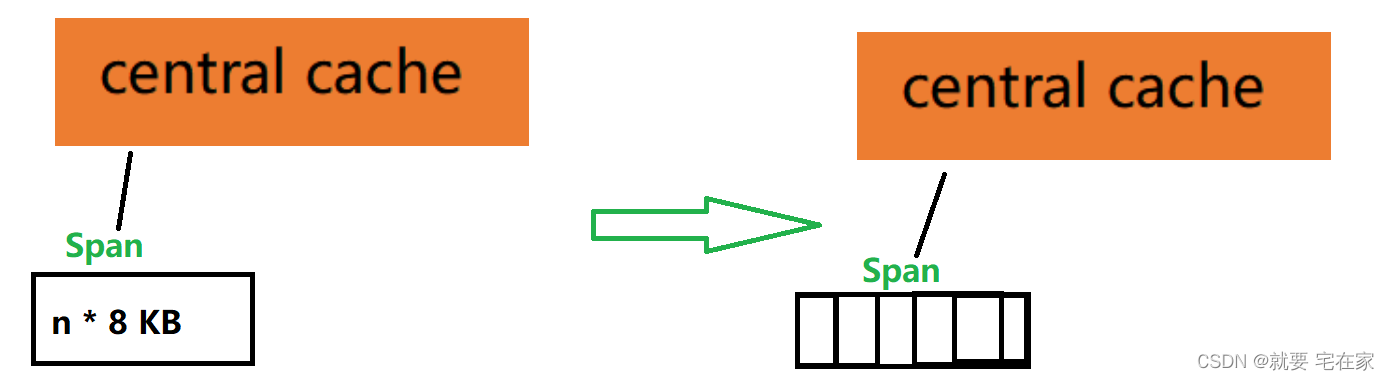
③central cache切分这一个span为多个内存块,内存块大小为线程申请内存大小经过内存对齐后的结果。
④thread cache通过慢增长算法从central cache中获取n个内存块。
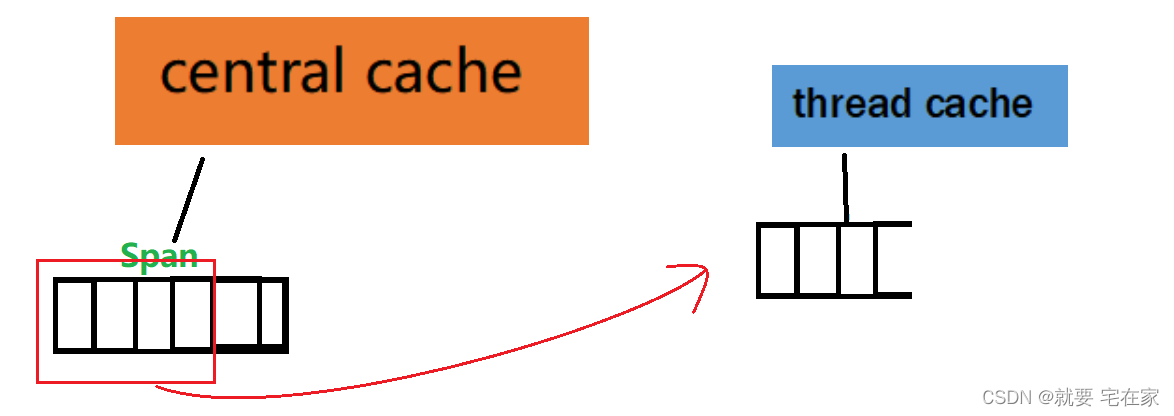
⑤thread cache将一个内存块分配给线程。
三.Thread Cache设计方法
(一).大体思路
首先我们知道,thread cache内部要有申请和释放内存的成员函数,同时作为存储内存的“池子”,它应该有管理内存的数据结构(哈希桶)。因此,thread cache应该设计成一个类。
不仅如此,thread cache会有向central cache申请内存的过程,因此也需要定义一个向central cache申请内存的接口。
当然,基于设计原因,释放内存内容将单独作为一个章节,从central cache获取内存函数将在central cache设计中介绍。
//<ThreadCache.h>
class ThreadCache {
public:
void* Allocate(size_t size);//分配内存
void Deallocate(void* obj, size_t size);//回收内存
void* fetchFromCentralCache(...);//从central cache获取内存
private:
...//管理内存的数据结构,哈希桶
};(二).自由链表与哈希桶
①整体结构
thread cache内部只能申请小于256KB的内存,当申请空间大于256KB时会直接从page cache中获取,这一点我们在项目优化中会具体讲解。现在我们需要解决一下thread cache内部采用什么数据结构作为内存池的问题。作为一个能申请不同空间大小的内存池,最好是按照大小划分区域存储,也就是说当申请内存时会根据申请的大小在对应空间直接分配一个数据块。而不是说thread cache内部就是一整块内存,使用时按照大小直接“刮”一块,这样虽然能完成分配空间的任务但是可能会产生外碎片。最好是从central cache中获得内存后就直接把内存按照固定大小划分好。因此,thread cache采用了哈希桶的结构存储内存。
哈希桶中每一个桶被称为自由链表,本质就是一个定长数组,下标从0开始对应不同的内存块,下标越大对应的内存块越大,数组每个元素是指针类型用来链接相同大小的内存块们,换句话说自由链表是由数据块连接而成。当申请内存时,会根据自由链表下标索引到对应的数组元素,然后分配空间。当然,自由链表下标也不是每一个字节都有对应,而是采用固定大小,当申请内存时会直接分配固定大小。也就是说申请的内存大小会对齐到自由链表某一个下标表示的特定值(内存对齐)。
第一个自由链表存储8Byte大小的内存块,因此申请内存时最少分配8字节,第二个自由链表对应16字节数据块,之后是24字节以此类推。但并不是说每个下标都间隔8字节,越往后间隔越大,最大的间隔数是8KB。哈希桶共有208个自由链表,最后一个自由链表存储的是256KB大小数据块。举个例子,当我申请6字节空间时,thread cache会直接分配8字节空间给我;当申请14字节时会直接分配16字节。
自由链表下标和内存间隔示意如下:
对应申请内存范围(Byte) | 下标之间内存间隔(对齐数) | 自由链表对应下标(从0开始) |
[1 , 128] | 8Byte | [0 , 16) |
(128 , 1024] | 16Byte | [16 , 72) |
(1024 , 8*1024] | 128Byte | [72 , 128) |
(8*1024 , 64*1024] | 1024Byte(1KB) | [128 , 184) |
(64*1024 , 256*1024] | 8 * 1024Byte(8KB) | [184 , 208) |
自由链表图示如下:

那可能会有人有疑问,这样当申请内存与固定大小不同时,不是会产生内碎片的问题么?
确实会产生内碎片,但是与这些内碎片相比,分配固定的内存大小更有利于回收时管理且能降低外碎片的发生。同时采用上图中下标映射特定的字节数能把内碎片降低到10%左右。举个例子,如果我申请了129个字节,那么经过内存对齐后会给我144Byte,这样有144-129=15个字节是浪费的也就是内碎片,浪费率为15/144 ≈ 10%;同理当申请1025个字节时,会分配1152Byte,内碎片为127Byte,浪费率约为11%。
②内存块的连接方式
有了自由链表的大体框架,我们该处理另一个问题了,自由链表中每个元素所指的内存块们该怎么连接起来呢?
这个问题其实很好解决,以32位机器为例,地址可以用一个指针类型表示,也就是说存储一个地址需要4Byte,而内存块最小为8Byte。只需要每个内存块的前4字节记录下一个内存块的起始地址即可。
以8Byte为例,图示如下:

获取数据块前4个字节空间的函数代码如下:
static void*& getPtr(void* ptr)//ptr:指向传入的数据块
{
return *((void**)ptr);
}这个代码该怎么理解呢,首先我们知道ptr指向传入的数据块,如果是普通的解引用那么获取的是整个数据块的大小。但是将ptr强转成void**二级指针后,再经过解引用就能够获取一个指针大小的空间,而这么做的意义是能够兼容32位机器和64位机器。因为在64位下存储地址需要8Byte,而指针在64位下正好就是8Byte。也就是说不管是32位还是64位,获得的空间都是正好能够存储一个地址的。同时因为数据块的前4或8字节空间需要存储的是下一个数据块的起始地址,因此应该是指针类型的空间,而通过解引用二级指针获取的就是一个指针类型空间。
③封装自由链表和哈希桶
有了上述储备知识,我们就能够封装自由链表进而封装哈希桶了。本质上自由链表就是一个无头单向链表。增加删除的方式与普通链表没有区别,就是连接下一个结点的方式采用本节点空间记录下一个结点地址的方式(前一个小标题内容)。因为自由链表其他缓存层可能会用因此再定义一个头文件<CommonHead.h>用于存放共用内容。
伪代码如下:
//<CommonHead.h>
//自由链表
struct FreeList {
//头插法
void push(void* obj) {
getPtr(obj) = _head;
_head = obj;
_size++;
}
//头删法
void* pop() {
assert(_head);
void* ret = _head;
_head = getPtr(ret);
_size--;
return ret;
}
bool empty();//判空
//头插n个结点
void pushRange(void* start, void* end, size_t n);
//头删n个结点,start和end为输出型参数
void popRange(void*& start, void*& end, size_t n);
size_t size();
size_t _gainNum = 1;//后续会说明,用于慢增长算法
void* _head = nullptr;//头节点指针
size_t _size = 0;//记录当前有多少个内存块
};因为哈希桶本身就是由208个自由链表组成,所以哈希桶本质是一个自由链表数组。因此thread cache中存储内存的哈希桶采用自由链表数组即可。
//<CommonHead.h>
static const size_t LISTSIZE = 208;//自由链表表长
//<ThreadCache.h>
class threadCache {
...
private:
FreeList _freelist[LISTSIZE];//哈希桶
};(三).Allocate申请内存函数
①整体流程
当申请内存时基于和malloc保持一致的目的,参数为我们申请的内存大小,返回值是分配的内存的起始地址。
整体思路上,首先将申请的内存大小进行内存对齐,再根据对齐后结果找到哈希桶中对应自由链表,再查看当前自由链表中是否有数据块,有的话直接分配,没有就向central cache申请。
//<ThreadCache.cpp>
void* ThreadCache::Allocate(size_t size) {
size_t realSize = sizeClass::roundUp(size);//获取内存对齐后需要申请的内存大小
size_t sub = sizeClass::index(size);//获取对应自由链表下标
if (!_freelist[sub].empty()) {//从自由链表中拿
return _freelist[sub].pop();
}
//从central cache中拿
return fetchFromCentralCache(sub, realSize);
}②内存对齐
申请内存时,首先要确定申请大小对应哈希桶中哪一个自由链表,也就是内存对齐到对应数据块确定分配空间大小。
在下述代码中,roundUp为thread cache调用的内存对齐函数。内部采用if条件判断当前大小在哪一个对齐数,根据对齐数调用_roundUp确定内存对齐后的结果。_roundUp中首先判断申请大小是否是对齐数的正整数,也就是某一个自由链表数据块的大小。如果是那么直接返回,不是就提升到对应数据块大小。举个例子,当申请16Byte时,对齐数为8Byte,16整除8正好与哈希桶中第二个自由链表数据块大小一致,那么直接分配就行。当申请17Byte时,对齐数为8Byte,但此时不能整除,因此需要对齐到第三个自由链表,也就是24Byte大小的数据块。
//<CommonHead.h>
static size_t _roundUp(size_t size, size_t align)
{
if (size % align == 0)
return size;
return (size / align + 1) * align;
}
static size_t roundUp(size_t size)
{ // 从所需空间大小推分配空间大小
if (size <= 128)
{
return _roundUp(size, 8);
}
else if (size <= 1024)
{
return _roundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _roundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _roundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _roundUp(size, 8 * 1024);
}
else
{
// 后续当申请内存大于256KB时会使用,此时不需要
return _roundUp(size, 1 << PAGE_SHIFT); // PAGE_SHIFT:13
}
}当然,_roundUp有一种改进方式:
原理就是将申请内存值+内存对齐数-1,意思是如果本身就是内存对齐那么结果在下一个对齐范围,否则在下下个范围中。之后和对齐数-1取反结果进行与运算获取最高位1,进而取得对齐后结果。
static inline size_t _roundUp(size_t size, size_t align)
{
return (((size)+align - 1) & ~(align - 1));
}举两个例子:
1.申请8Byte,对齐数8Byte
(((size)+align - 1) | ~(align - 1)) |
0000 1111 | 1111 1000 |
结果:0000 1000 = 8 | |
2.申请10Byte,对齐数8Byte
(((size)+align - 1) | ~(align - 1)) |
0001 0001 | 1111 1000 |
结果:0001 0000 = 16 | |
③索引下标
根据内存大小,我们需要判断该内存值对应哈希桶中哪一个自由链表,因此定义一个index函数专门获取对应的自由链表下标。
下述代码中,首先采用数组形式记录每一个内存对齐数有多少个下标,比如对齐数为8的是申请1-128Byte,对应数组下标为0-15共16个下标。
根据当前内存大小就能知道本对齐数前有多少个下标,进而调用_index推的当前内存是第几个下标。
//<CommonHead.h>
static size_t _index(size_t size, size_t align)
{
if (size % align == 0)
return size / align - 1;
return size / align;
}
static size_t index(size_t size)// 从分配空间大小推下标
{
static size_t prevIndex[4] = {16, 56, 56, 56};
if (size <= 128)
{
return _index(size, 8);
}
else if (size <= 1024)
{
return _index(size - 128, 16) + prevIndex[0];
}
else if (size <= 8 * 1024)
{
return _index(size - 1024, 128) + prevIndex[1] + prevIndex[0];
}
else if (size <= 64 * 1024)
{
return _index(size - 8 * 1024, 1024) + prevIndex[2] + prevIndex[1] + prevIndex[0];
}
else if (size <= 256 * 1024)
{
return _index(size - 64 * 1024, 8 * 1024) + prevIndex[3] + prevIndex[2] + prevIndex[1] + prevIndex[0];
}
else
{
throw std::bad_alloc();
}
}_index函数原理很简单,与_roundUp一样举例子就能写出来,同样有一个优化版本,但不再过多讨论:
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}(四).用户调用接口
对于每一个线程而言,不可能从thread cache中直接调用Allocate接口申请内存,这样会导致封装性下降。因此,我们应该专门创建头文件TCMalloc.h来定义使用高并发内存池申请内存的接口,而这个接口内部是调用的thread cache的Allocate接口。这样能提高代码的封装和可读性,当申请内存时程序员不用先定义一个thread cache对象然后再调用具体的成员函数。而是像malloc一样直接调用一个函数。
在TCMalloc.h中定义了两个函数:tcMalloc函数用于申请内存,tcFree用于释放内存。为了与malloc和free保持一致,tcMalloc的参数就是需要申请的内存大小(单位:Byte),tcFree的参数就是待释放内存的起始地址。
值得注意的是,由于每一个线程都有属于自己的thread cache因此不会出现线程安全问题,将thread cache对象声明在.h头文件中声明为指针类型,每个线程第一次调用时在tcMalloc函数中申请对象空间。windows中线程私有变量采用_declspec(thread)修饰,linux中采用__thread修饰。
//<ThreadCache.h>
class ThreadCache {
...
};
static _declspec(thread) ThreadCache* tCache = nullptr;//thread cache对象声明
//linux: static __thread ThreadCache* tCache = nullptr;
//<TCMalloc.h>
void* tcMalloc(size_t size) {//对外的分配内存接口
if (size > CACHEMAX) {//如果申请大于256KB
...//后续说明
}
else {
if (tCache == nullptr) {//线程第一次调用thread cache对象
tCache = new threadCache;
tCache = tcPool.New();
}
}
return tCache->Allocate(size);
}
void tcFree(void* obj);//后续说明四.Central Cache设计方法
(一).总体思路
central cache的在高并发内存池中起到了承上启下的作用,因此相对于另外两层内存池要复杂一些。
与thread cache一样,central cache也是采用封装的方式实现的。除了存储内存的哈希桶外,对外有向thread cache提供和回收内存的成员函数,另外还有用于自身内部使用的成员函数。向page cache归还内存采用满足一定条件自动归还,释放内存章节会说明。
此外,central cache是所有线程共享,在多线程环境下需要考虑线程安全问题。设计思路采用单例模式中的饿汉模式,让central cache在程序初始化时创建唯一的一份。具体方式就是将声明与定义分离,定义在.cpp源文件中,链接时就只会有一份central cache对象。
为什么不采用懒汉模式?因为懒汉模式存在线程安全问题,需要再专门加锁。可参考这篇博客:Linux——线程同步(条件变量、POSIX信号量)和线程池
//<CentralCache.h>
class CentralCache {//设计成单例模式
public:
static CentralCache* getCentralCache();//获取单例对象
size_t getRangePage(void*& start, void*& end, size_t batchNum, size_t size);//向thread cache提供内存
void ReleaseListToSpans(void* start, size_t size);//从thread cache中回收内存
span* getOneSpan(spanList* spanlist, size_t size);//内部使用,获取一个span
private:
static CentralCache _centSingle;
SpanList _spanList[LISTSIZE];//哈希桶
private://单例模式,将默认构造私有,其他构造删除
centralCache() = default;
centralCache(const centralCache& cent) = delete;
centralCache& operator=(const centralCache& cent) = delete;
};
//<CentralCache.cpp>
CentralCache CentralCache::_centSingle;//饿汉模式(二).自由链表和哈希桶
与thread cache相同,central cache也是采用哈希桶的结构存储数据且哈希桶下挂的也是自由链表。但与thread cache不同,central cache自由链表并不是由数据块组成而是span。所谓span本质是自己定义的一种数据结构,其内部是数据块链表和相关属性信息。central cache的哈希桶每个自由链表存储的数据块大小与thread cache哈希桶一致,也就是说central cache和thread cache的哈希桶只有自由链表每个结点的结构不同,一个是span另一个是内存数据块。
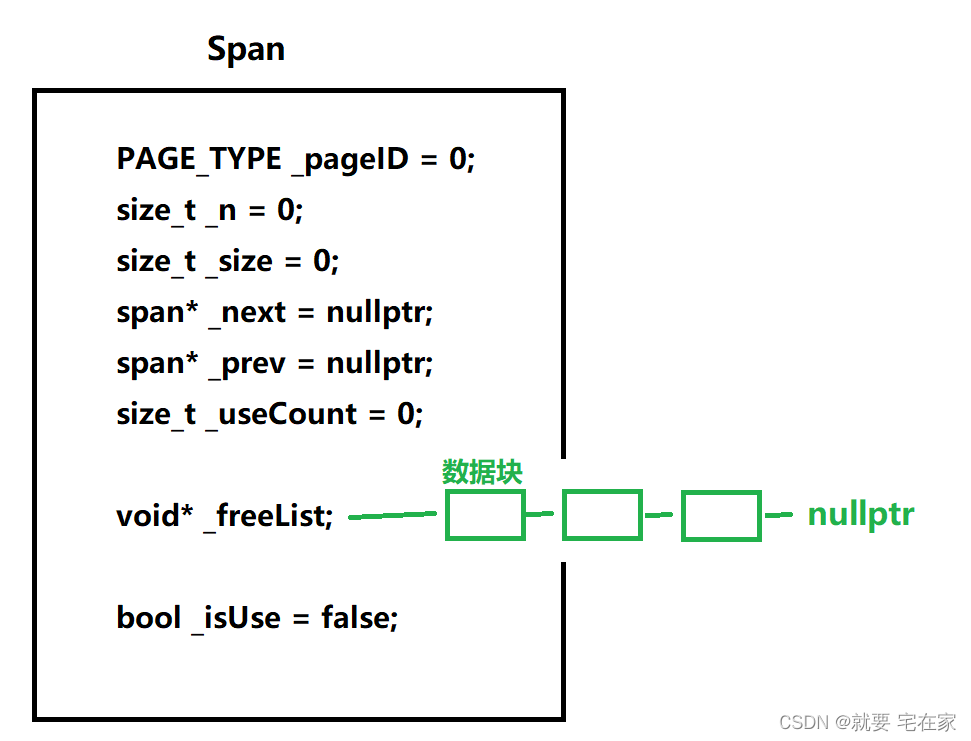
span可以理解成封装了数据块链表的结构体,但是只采用指针(_freelist)记录了链表的起始地址。此外记录了前一个span(_prev)、后一个span(_next)已被使用的数据块数量(_useCount)、数据块大小(_size)等信息。
在下面的代码中,_pageID、_n、_isUse三个成员是在从page cache获取span时会使用,暂时不需要了解。
//<CommonHead.h>
typedef size_t PAGE_TYPE;
struct Span {
PAGE_TYPE _pageID = 0;//起始页号
size_t _n = 0;//页的数量
size_t _size = 0;//自由链表每个块的大小
span* _next = nullptr;//下一个span
span* _prev = nullptr;
size_t _useCount = 0;//被使用的页数量
//FreeList _freeList;//span下挂的自由链表,这样亦可,但是使用封装的类会造成冗余
void* _freeList;//span下挂的自由链表
bool _isUse = false;//是否有线程正在使用该span
};这里可能会有疑问,为什么span中不采用已经封装好的自由链表呢。因为span中每个数据块都记录了下一个数据块的位置,本身就是一个链表。最主要是不太需要使用自由链表类中那么多的成员函数,减少封装能避免冗余。
span的结构如下:
central cache哈希桶的每一个桶就是一个自由链表,或者说每一个自由链表是由span构成的带头双向循环链表。因此需要封装一个SpanList类来作为双向循环链表。同时,基于线程安全问题,我们需要在每一个spanlist中加锁而不是将哈希桶整体上锁。这是因为central cache不管是分配内存还是归还内存都是在同一个spanlist中进行。换句话说thread cache是以数据块为单位向central cache申请内存,一次会批量申请多个相同大小的数据块,也就是说数据块一定是存在同一个spanlist中。因此只需要对每一个spanlist加锁即可。
class SpanList {//带头双向循环链表
public:
SpanList() {
//初始化带头双向循环链表
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
void insert(span* pos, span* tar);//指定位置插入
void push_front(span* node);//头插
Span* erase(span* node);//指定结点删除
Span* pop_front();//头删
bool empty();//判空
Span* begin();//获取头节点
Span* end();//获取尾节点(哨兵位结点)
std::mutex _mtx;//互斥锁
private:
Span* _head;//头节点
};central cache的哈希桶本质就是一个由spanlist组成的数组,这一点与thread cache很像。
//<CentralCache.h>
class CentralCache {//设计成单例模式
...
private:
...
//static const size_t LISTSIZE = 208;//自由链表表长
SpanList _spanList[LISTSIZE];//哈希桶
...
};spanlist和哈希桶结构示意图如下:

(三).向thread cache提供内存
①thread cache获取内存
虽然thread cache申请内存时提供一个数据块就够了,但是为了能减少接口的调用次数,thread cache会一次性申请多个数据块。具体申请多少个根据慢增长算法决定。我们在thread cache的自由链表类中设定一个变量作为计数从1开始。每申请一次计数++,每次都申请当前计数个数量。并且根据数据块大小设定最大值,计数达到最大值以后申请就只能申请最大值个。比如第一次申请是1个数据块,那么第二次申请就是2个,假如最大值是16,那么第17次申请时就只能申请16个数据块。
//<CommonHead.h>
struct FreeList {
...
size_t _gainNum = 1;//计数,用于确定thread cache申请数据块数量
...
};//<CommonHead.h>
static size_t getNodeNum(size_t size)// 确定threadCache一次申请数据块最大值
{
//256KB / 数据块大小
size_t num = CACHEMAX / size;
//最大值最小为2个数据块
if (num < 2)
{
num = 2;
}
//最大不超过512个
if (num > 512)
num = 512;
return num;
}知道了需要多少个数据,就可以传参调用central cache相关接口,参数中有两个输出型参数start和end,分别代表分配的起始数据块和结尾数据块。因为这些数据块内部已经连接好了,即central cache分配给thread cache的是一个数据块链表,因此直接调用自由链表相关函数将该链表入链即可。
//<ThreadCache.cpp>
void* ThreadCache::fetchFromCentralCache(size_t index, size_t size) {
size_t maxNum = sizeClass::getNodeNum(size);//一次分配获取该数据块个数的最大值
size_t batchNum = min(_freelist[index]._gainNum, maxNum);//实际所需的数量
if (batchNum == _freelist[index]._gainNum) {
//说明此时数量尚未达到最大值
_freelist[index]._gainNum++;
}
void* start = *end = nullptr;
从central cache获取批量个结点,返回值为实际获取的数量
size_t n = CentralCache::getCentralCache()->getRangePage(start, end, batchNum, size);
void* ret = start;
//如果获取结点的数量大于1,取第一个数据块分配给线程,其余放入自由链表中
if (n > 1) {
start = getPtr(start);
_freelist[index].pushRange(start, end, n - 1);
}
//否则只获取了一个结点,start应该等于end
else assert(start == end);
return ret;
}②central cache提供内存
上面我们已经通过调用接口知道了central cache有两个输出型参数,用于记录分配的首尾数据块,此外,还需要两个参数:需求的数据块个数和数据块大小。
我们通过传入的数据块大小确定是哈希桶中哪一个spanlist链表,将该spanlist上锁后调用自身getOneSpan函数从该spanlist中获得一个有数据块的span。
之后,根据我们需求的数量在span中截取数据块。如果span中数据块数量够多就拿目标个数,不够就全拿。也就是说实际获取的数据块个数取决于span中还有多少个数据块,可能少于目标个数,但这并不影响实际使用,因为实际上至少都会分配一个数据块。
当获取数据块后除了将首尾记录在输出型参数start和end外,还需要将实际个数记录在span的成员变量_useCount中,该变量含义是本span有多少个数据块已经分配给线程。回收内存时,当useCount为0说明该span中,所有被线程们使用的数据块都已经归还,那么这个span能被归还给page cache。
最后将指定的spanlist解锁。
<CentralCache.cpp>
size_t CentralCache::getRangePage(void*& start, void*& end, size_t batchNum, size_t size) {//返回分配了多少个页
size_t index = sizeClass::index(size);//获取数据块对应自由链表下标,确定是哈希桶中哪一个spanlist
_spanList[index]._mtx.lock();//加锁保护
Span* sp = getOneSpan(&_spanList[index], size);//找到一个有数据块的span
//根据该span下挂的自由链表,获取目标批量数的结点,将剩余结点依旧挂在span
start = sp->_freeList;
end = start;
size_t i = 0;//记录实际获取的数据块个数
while (i < batchNum - 1 && getPtr(end)) {
end = getPtr(end);
i++;
}
i++;
sp->_freeList = getPtr(end);
getPtr(end) = nullptr;//截取的链表的最后一个结点要指向空指针
sp->_useCount += i;//记录已使用数据块数量
_spanList[index]._mtx.unlock();//解锁
return i;
}③内部使用:获取一个span
上文中我们说过,central cache分配内存时需要根据内存大小找到哈希桶中对应的spanlist链表。之后根据链表调用内部函数获取一个span。本节就来实现这个获取span的函数getOneSpan。本函数旨在传入特定的spanlist链表和数据块大小获取一个非空span。
函数内部首先需要遍历spanlist来判断是否还有非空span,如果有就直接返回这个span,没有就从page cache中获取一个span。这里需要注意,因为只要求span非空就返回,所以并不关心thread cache需求数据块个数,这也就是为什么返回数据块可能会少于目标数量的根本原因。
同时还有一点需要注意:从page cache中获取的span的数据块是一整个,并没有经过切分链接的步骤!因此从page cache中获取span后要将该span的大数据块切分成多个目标大小的数据块,这就是为什么getOneSpan参数需要传入数据块大小。

将带有大块数据块的span切分好后返回即可。
整体代码如下,但是我们需要逐块分析一下:
<CentralCache.cpp>
Span* CentralCache::getOneSpan(SpanList* spanlist, size_t size) {//获取一个span,没有就从pageCache找
assert(spanlist && size != 0);
//遍历spanlist找非空span
if (!spanlist->empty()) {
Span* cur = spanlist->begin();
while (cur != spanlist->end()) {
//找到非空span,直接返回
if (cur->_freeList) return cur;
cur = cur->_next;
}
}
//没有非空span,从pageCache中获取
spanlist->_mtx.unlock();
PageCache::getPageCache()->_mtx.lock();
Span* sp = PageCache::getPageCache()->newSpan(sizeClass::getPageIndex(size));
sp->_size = size;//设定size大小,用于释放时确定空间大小
sp->_isUse = true;
PageCache::getPageCache()->_mtx.unlock();
//转换成目标span,入span链表(其实就是将从page cache中获得的下挂一个大数据块的span切分成下挂好几个数据块的span)
char* start = (char*)(sp->_pageID << PAGE_SHIFT);//计算起始地址
size_t length = sp->_n << PAGE_SHIFT;//计算pageCache分配的span的大小,单位:byte
char* end = start + length;
sp->_freeList = start;
void* cur = start;
start += size;
while (start < end) {
getPtr(cur) = start;
cur = start;
start += size
}
getPtr(cur) = nullptr;
spanlist->_mtx.lock();
//切好的span入span链表
spanlist->push_front(sp);
return sp;
}
首先是第一部分(3-12行),这一段很好理解,就是遍历spanlist中有没有非空的span,通过span下挂的自由链表是否指向空来判断span是否为空。
有意思的是第二部分(13-20行),这里面首先将spanlist的锁解开了,这是因为在调用page cache接口时不会使用该spanlist,这样做的目的是提高并发度,能够让其它线程能在此期间使用该spanlist,尤其是要向spanlist归还数据块的线程。具体调用的page cache函数暂时不需要了解,只用知道返回的是一个span即可。获得span后要将数据块大小记录一下,同时_isUse用于page cache归还资源使用,暂时不用了解。
这也就解释为了什么会在第36行要给spanlist再次加锁:只有在获得span并将数据块切分好后,要把该span入spanlist的时候才会改变spanlist结构。(spanlist本质就是一个临界资源)
//没有非空span,从pageCache中获取
spanlist->_mtx.unlock();
PageCache::getPageCache()->_mtx.lock();
Span* sp = PageCache::getPageCache()->newSpan(sizeClass::getPageIndex(size));
sp->_size = size;//设定size大小,用于释放时确定空间大小
sp->_isUse = true;
PageCache::getPageCache()->_mtx.unlock();第三部分(22-39行)就是切分span并入spanlist的过程。根据我们已知的数据块大小,将span的大块数据块切分成目标大小的数据块们。但是这并不是说page cache所传入的大块数据块就是能正好切分,而是存在剩余一小部分的可能的!那剩下的那一些就会在被分配给线程的时候作为内碎片出现。除此之外需要特别说明的是,因为在page cache中并没有使用span的成员_freelist管理数据块,而是直接管理数据块的起始地址,也就是记录在成员_pageID中,因此page cache所返回的span中_freelist为空,我们需要手动记录起始地址在_freelist中。
同时需要提前了解的是,page cache并没有采用_pageID直接记录地址的方式,而是将地址除8KB的结果记录。因为在本项目中,我们规定一页大小为8KB,_pageID所记录的实际是该数据块起始位置是内存中第几个页。那么获取真实地址的方式就是页号 x 8KB。
//static const size_t PAGE_SHIFT = 13;// 2 ^ 13 == 8KB
char* start = (char*)(sp->_pageID << PAGE_SHIFT);//计算起始地址,等价于sp->_pageID * 2^13(8KB)因为要切分整个数据块,所以还需要获取末尾地址。通过获取整个数据块的大小,起始地址加上整体大小就是末尾地址。由于page cache返回的span中记录了一共有多少个页(成员_n),那么页的个数乘8KB就是整体大小。
size_t length = sp->_n << PAGE_SHIFT;//计算pageCache分配的span的大小,单位:byte
char* end = start + length;//末尾地址
sp->_freeList = start;//起始地址记录在成员_freeList中五.Page Cache设计方法
(一).总体思路
page cache作为最底层的缓存层,作用就是从系统直接获取内存并分配给central cache。因此,对外就两个接口:分配内存给central cache、从central cache回收内存。回收内存函数在释放内存章节讲解。内部存储内存的数据结构依旧是哈希桶,同样也是采用spanlist数组的形式。但具体含义又和central cache不同。同时在page cache内部管理内存是以整个哈希桶为单位,而不是像central cache以自由链表spanlist为单位。因此page cache需要整体加锁,也就是在类内定义互斥锁对象。又因为page cache为所有线程共享,与central cache一样采用单例模式中的饿汉模式,不再赘述。
//<PageCache.h>
class PageCache {
public:
static pageCache* getPageCache();//获取单例对象
span* newSpan(size_t i);//向central cache分配内存(分配一个span)
std::mutex _mtx;//互斥锁
span* MapObjectToSpan(void* start);//用于回收内存,后续讲解
void ReleaseSpanToPageCache(span* sp);//用于回收内存,后续讲解
private:
spanList _spanlists[PAGES];//哈希桶
static pageCache _pc;//单例对象
std::unordered_map<PAGE_TYPE, span*> _idSpanMap;//用于回收内存,后续讲解
private:
pageCache() = default;
pageCache(const pageCache& pc) = delete;
pageCache& operator=(const pageCache& pc) = delete;
};(二).自由链表和哈希桶
因为page cache作为最底层的缓存,存储的内存一定是最多的。因此存储下标含义和central cache、thread cache不同。page cache哈希桶每个下标代表了内部span存储多少个页。举个例子,下标为1的桶代表挂的span内部数据块 是一个页的大小(8KB)。下标为2的桶中数据块大小为2个页。第i个桶就说明内部数据块大小是i个页。page cache共有128个桶,最大的数据块大小为128 * 8KB=1MB。需要特别注意的是,为了存储方便,并没有启用0号下标。并且除了头节点外,所有的span都挂有内存,使用时都是一个span被整体使用。
图示如下:

(三).向central cache提供内存
因为page cache最小的桶都有8KB,我们首先需要确定central cache所需的内存多大的桶能提供。central cache在调用该接口时,传入的参数是对应桶的下标。计算下标采用数据块大小与需求块数的乘积除以8KB,所得就是对应下标。因为规定数据块最大为256KB,除以8KB对应第32号桶,因此远远不会超过page cache最大容量。那可能有人会问,剩下的90多个桶呢不会浪费么?——不会的,因为page cache每次向系统申请的内存就是1MB,也就是第128个桶对应的数据块大小。这么大的容量在切分后同样会剩下一大部分,剩余的极有可能超过第32个桶数据块容量,因此需要32号之后更大的桶来存储。
因此,提供内存的思路就是先看对应桶中是否非空,非空就返回一个span,空的就向下寻找,当下方桶中有非空桶时切分数据块,返回目标大小的span,剩余的部分放入对应桶中。如果整个哈希桶都是空的,那么向系统申请1MB(8 * 128KB)内存,同样切分后返回目标span并将剩余内存入对应桶中。
让我用流程图再解释一遍提供内存的原理:
假设central cache申请的是第4号桶也就是32KB,那么先检测page cache中第4号桶是否有span。
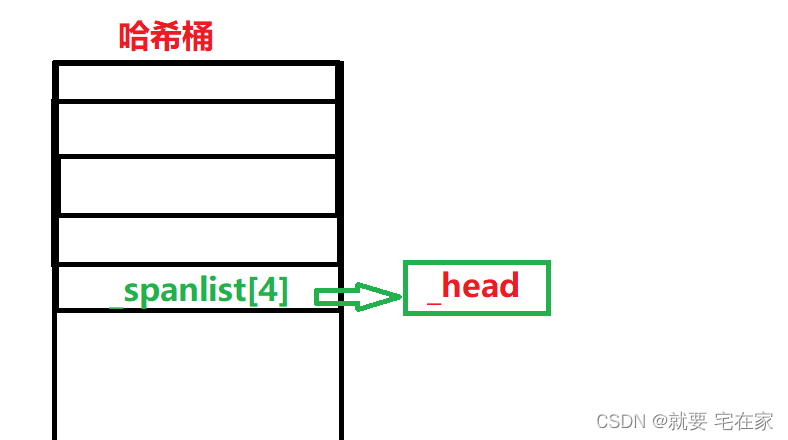
发现只有一个头节点,那么需要向下在更大的桶中寻找。

结果所有的桶中都只有一个头节点,并没有span,此时需要向系统申请1MB内存,放入最后一个桶中
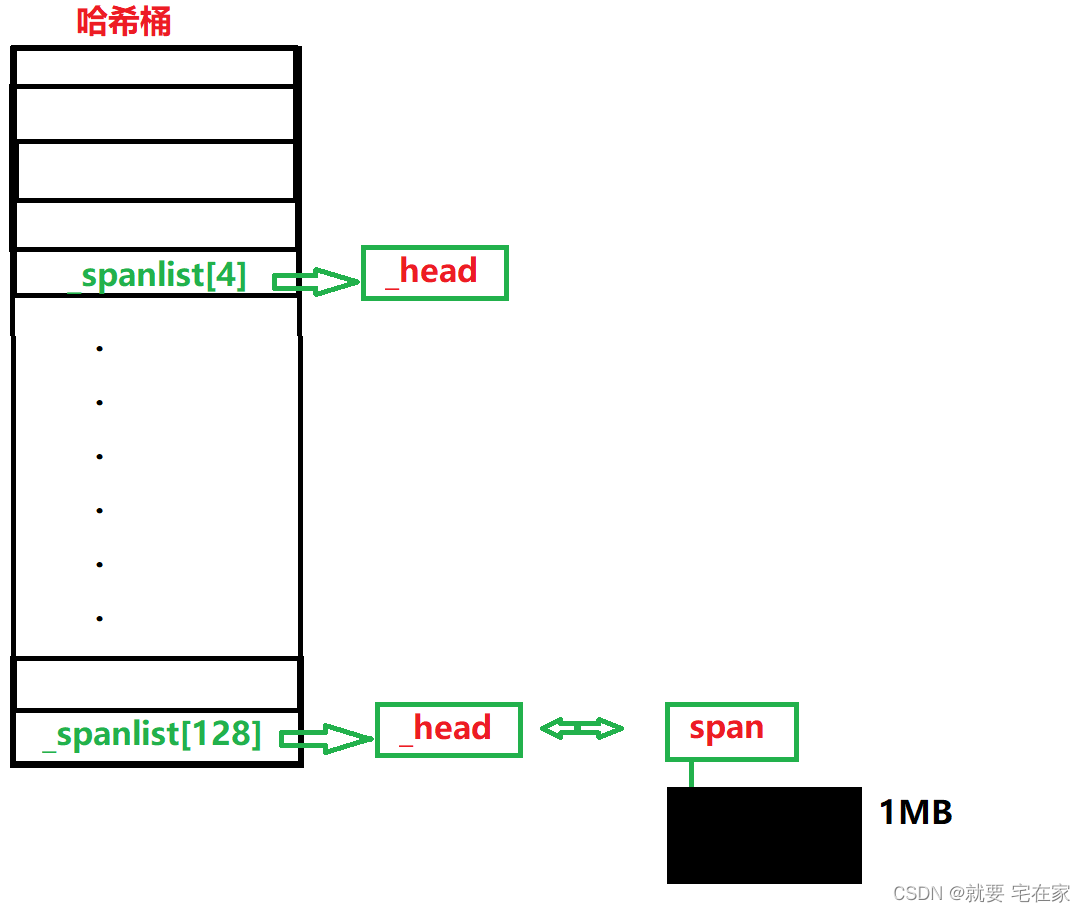
切分这个1MB的span为32KB和992KB的两个span。

将992KB大小的span入哈希桶第124号桶中(992KB/8KB=124),返回给central cache32KB大小的span。
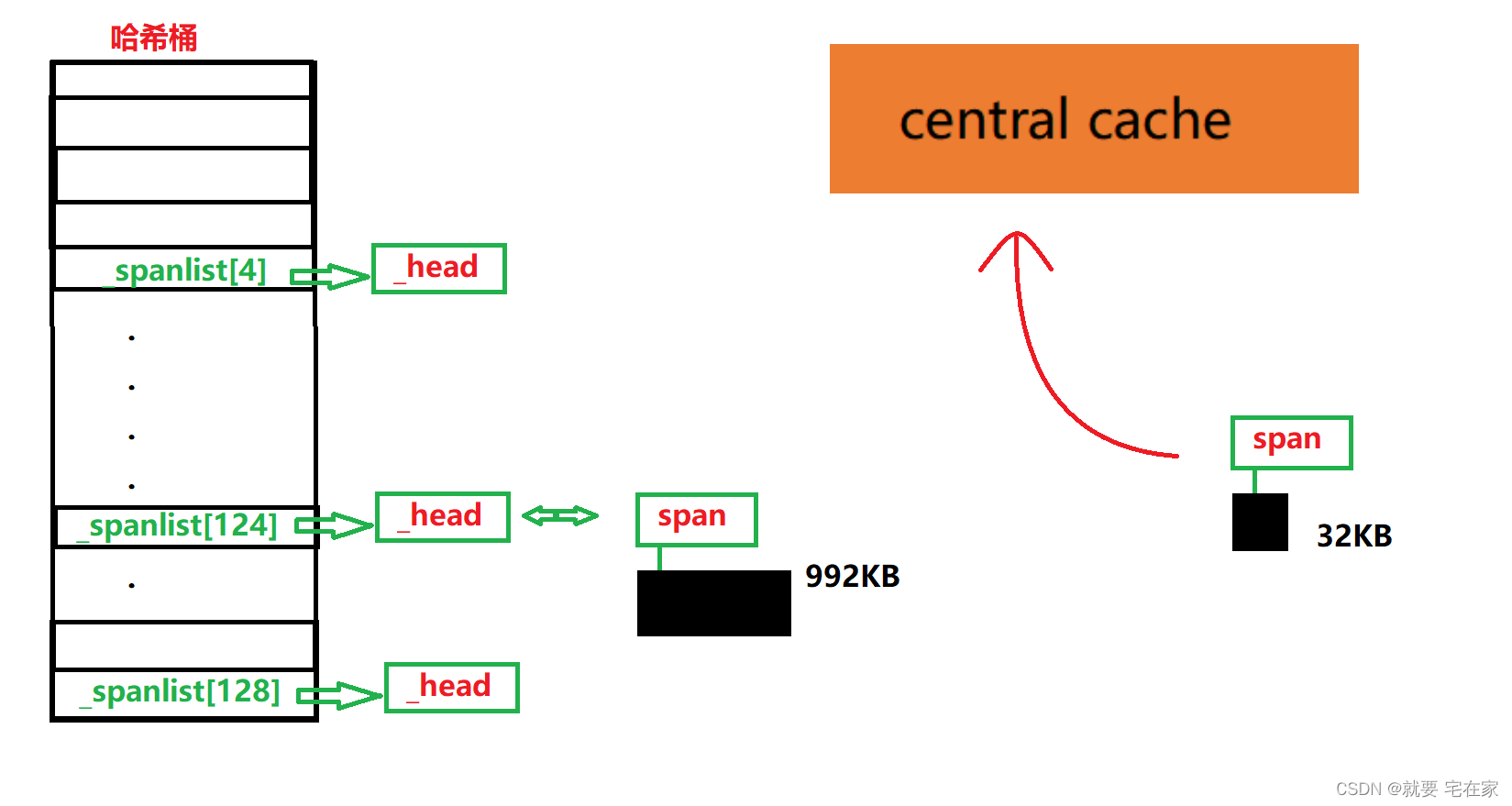
下面我们来实现一下代码:
//<PageCache.cpp>
Span* PageCache::newSpan(size_t i) {//给central cache一个span,参数为pageCache中spanlists下标
assert(i != 0);
if (i >= PAGES) {//如果申请空间大于1MB,后续优化时会说明
...
}
spanList* splist = &_spanlists[i];//获取特定span链表
//如果目标链表中有span
if (!splist->empty()) {
span* retSpan = splist->pop_front();
retSpan->_n = i;//记录数据块共多少页
...
return retSpan;
}
//没有就向后面更大的桶中找span
size_t n = i + 1;
while (n < PAGES) {
//当前桶中有span
if (!_spanlists[n].empty()) {
span* retSpan = new span;//建立新span,用于返回
span* nSpan = _spanlists[n].pop_front();//摘下桶中第一次span
//记录返回的span信息
retSpan->_pageID = nSpan->_pageID;
retSpan->_n = i;
//记录切分后剩余span的信息并入相应桶中
nSpan->_n -= i;
nSpan->_pageID += i;
_spanlists[nSpan->_n].push_front(nSpan);
...
}
...
return retSpan;
}
//当前桶中没有span,继续向后找
else {
n++;
}
}
//哈希桶中没有,向系统要
span* retSpan = new span;
void* ptr = ...//获取系统内存,不采用malloc或new,方式后续说明
//1MB大小span入哈希桶
retSpan->_n = PAGES - 1;
retSpan->_pageID = (PAGE_TYPE)ptr >> PAGE_SHIFT;
_spanlists[retSpan->_n].push_front(retSpan);
//递归调用,此时因为最大的桶中有span,再次调用函数会遍历到最后一个桶经过切分后返回目标span
return newSpan(i);
}六.释放内存
(一).thread cache释放内存
释放流程很简单,根据获取的内存大小,找到对应的自由链表,将该内存入链即可。我们重点说说什么时候向central cache归还内存。
当数据块入链后检查此时链表长度,如果超过了慢增长大小,也就是成员_gainNum的值,那么将此时链表中_gainNum数量个结点出链交给central cache。换句话说就是当链表长度超过下次向central cache申请数据块数量时,向central cache归还一组数据块。
//<ThreadCache.cpp>
void ThreadCache::Deallocate(void* obj, size_t size) {
size_t i = sizeClass::index(size);//找到对应自由链表
_freelist[i].push(obj);//入链表
//如果链表结点数量过多,向central cache归还一部分
if (_freelist[i].size() >= _freelist[i]._gainNum) {
void* start = nullptr;
void* end = nullptr;
//将_gainNum个的数据块从链表摘下
_freelist[i].popRange(start, end, _freelist[i]._gainNum);
//调用central cache接口,交还数据块
CentralCache::getCentralCache()->ReleaseListToSpans(start, size);
}
}当然,用户的调用接口内部就是直接调用thread cache成员函数:
//<TCMalloc.h>
void tcFree(void* obj, size_t size) {//对外的回收内存接口
if (i > 32) {//大于256KB
...
}
else {
tCache->Deallocate(obj, size);
}
}(二).central cache释放内存
thread cache将链表起始数据块地址和数据块大小作为参数传给函数。因为这些数据块大小相同,因此都在同一个桶(自由链表)中,central cache只需要根据每个数据块的地址,找到对应span然后 把数据块入span下挂的链表即可。但是并没有任何数据记录了span和地址的关系,那我们怎么通过地址找到span呢?
——采用KV模型在span创建的时候就记录地址与span的映射关系。但是这里我们需要注意,就连32位机器都有2^32个地址,逐一记录根本不现实。因此,采用记录页号与span的映射关系。这是因为page cache交给central cache的是以页为单位的连续内存。因此,地址除以8KB就能找到对应的页号进而找到对应内存。
举个例子,比如我们归还的内存块起始地址是0x11223344,因为我们把内存按照8KB一组划分,因此地址除以8KB后,得到该内存块属于页号为35089的页。然后通过kv模型锁定该页属于哪个span,然后把内存交给该span。
因此,当span中所属的内存块被交还后,连接顺序可能是混乱的,并不是按照从page cache来时地址从小到大排好,但是内存依旧是那些内存。这就好比一副全新的扑克,在玩完被放回牌盒后可能顺序是乱的,但牌还是那些牌,并不会出现丢牌或多牌的情况。
此时我们可以采用unordered_map作为kv模型,因为其底层是一个哈希桶检索效率很高。又因为是记录页号与span的关系,因此创建索引的过程应该设在page cache将span交给central cache前,也就是在page cache内部定义一个unordered_map成员用于索引。
//<PageCache.h>
class PageCache {
...
std::unordered_map<PAGE_TYPE, span*> _idSpanMap;
...
};在page cache向central cache提供内存的函数中,找到或切分出目标大小span后,依次记录每一个页与该span的映射关系:
//<PageCache.cpp>
Span* PageCache::newSpan(size_t i) {
if (i >= PAGES) {//如果申请空间大于128 * 8KB
...
}
spanList* splist = &_spanlists[i];//获取特定span链表
//如果目标链表中有span
if (!splist->empty()) {
...
//建立页号与span映射关系
for (size_t i = 0; i < retSpan->_n; i++) {
_idSpanMap[retSpan->_pageID + i] = retSpan;
}
return retSpan;
}
//没有就向后面更大的桶中找span
size_t n = i + 1;
while (n < PAGES) {
//当前桶中有span
if (!_spanlists[n].empty()) {
...
//建立页号与span映射关系
for (size_t i = 0; i < retSpan->_n; i++) {
_idSpanMap[retSpan->_pageID + i] = retSpan;
}
//建立切分后剩余内存的起始页号、末尾页号与span映射关系,用于page cache回收内存
_idSpanMap[nSpan->_pageID] = nSpan;
_idSpanMap[nSpan->_pageID + nSpan->_n - 1] = nSpan;
return retSpan;
}
...
}
//哈希桶中没有,向系统要
...
}通过地址找到对应span后,此时就应该将该数据块放入span。每归还一个数据块,span中记录被取走数据块数量的成员_useCount--,当_useCount减到0时,说明所有的数据块都已经归还,此时就应该向page cache归还整个span了。这便是central cache的释放内存流程。
同时需要注意,因为所有线程共享central cache因此归还数据块的过程应该加锁,根据函数参数知道数据块大小,进而锁定是哪一个桶(spanlist),将对应桶加锁即可。
伪代码如下:
//<CentralCache.cpp>
void CentralCache::ReleaseListToSpans(void* start, size_t size) {//从threadCache获得批量数据块, size即每个块的大小
//加锁保护
size_t index = sizeClass::index(size);
_spanList[index]._mtx.lock();
while (start) {
//先找数据块从哪个span来的
Span* sp = PageCache::getPageCache()->MapObjectToSpan(start);
...//把数据块加入span下挂自由链表,next指针记录下一个数据块地址
sp->_useCount--;//分配给threadcache的数据块-1
//span中所有数据块都回来了,整体还给pageCache
if (sp->_useCount == 0) {
...
}
start = next;
}
_spanList[index]._mtx.unlock();
}(三).page cache释放内存
上文我们知道,central cache释放内存时是将整个span交给page cache。那么page cache内部就是获取一个span,然后找到它的前序和后序span,如果找到就直接整合成一个span,放回哈希桶对应位置;如果没找到就根据大小放到对应哈希桶中。
流程图示如下:
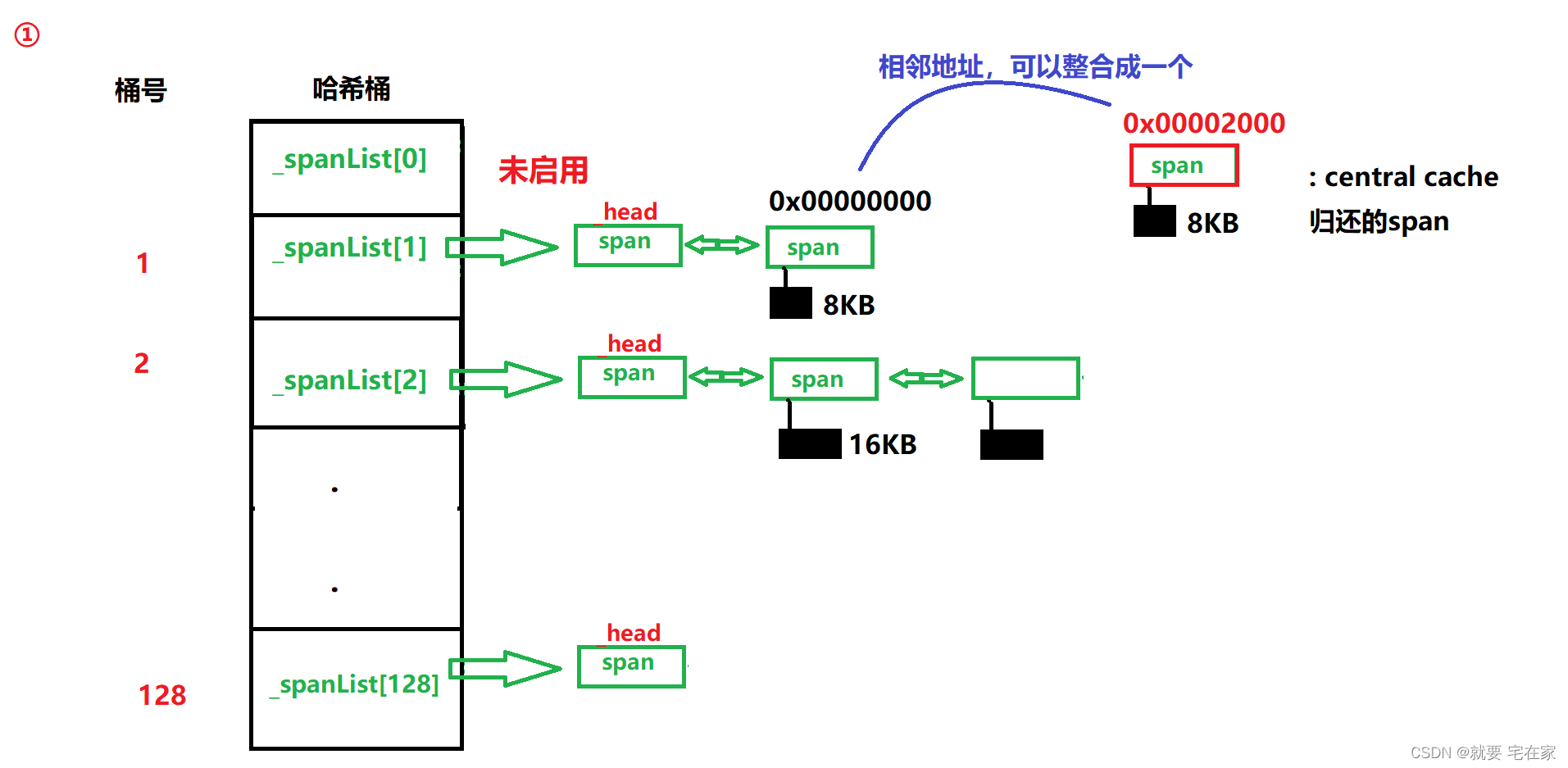
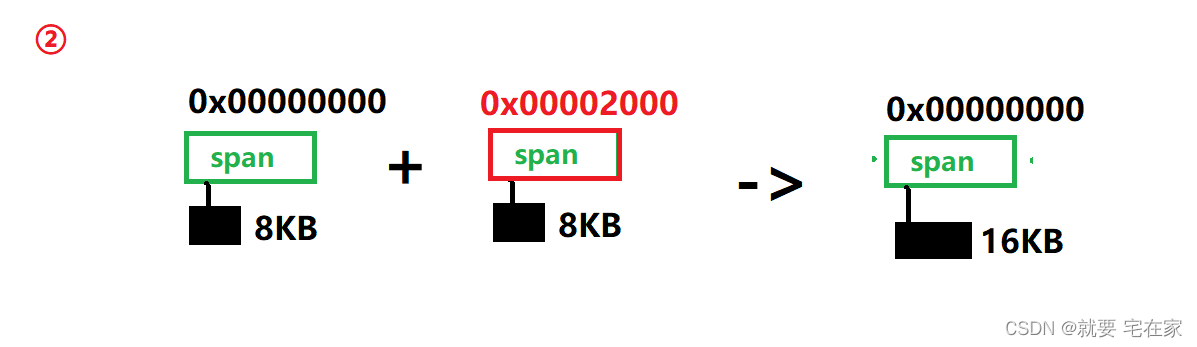
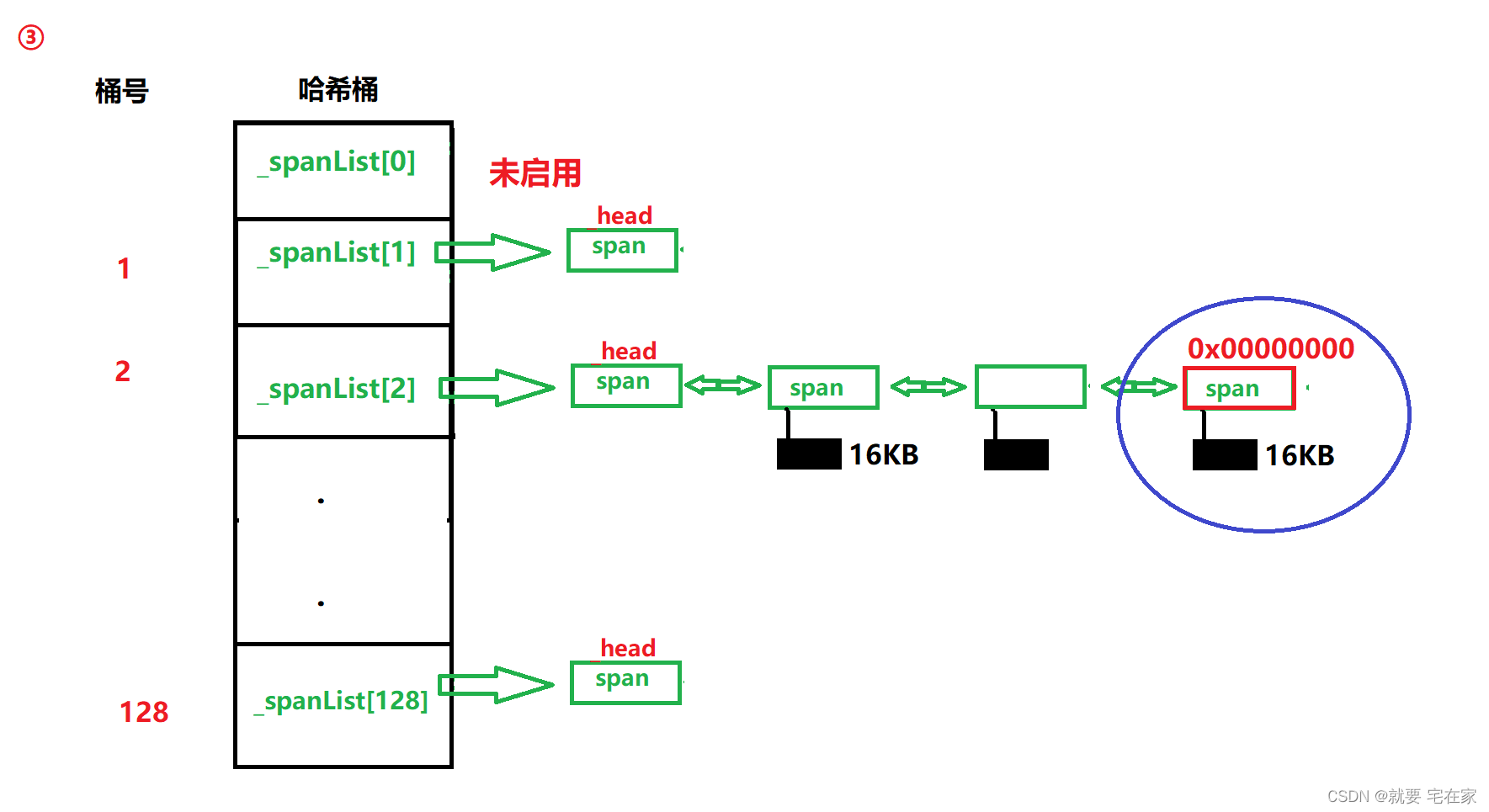
根据span中成员_pageID记录的起始地址,通过地址-1找到上一个span,地址+本span长度找到下一个span,再根据前序和后序span是否存在以及是否正在被使用,判断是否整合。
伪代码思路如下:
void PageCache::ReleaseSpanToPageCache(span* sp) {//将centralCache归还的span整合成更大的span
if (sp->_n >= PAGES) {//如果大于128 * 8KB,直接释放
...
}
//向前合并
while (1) {
PAGE_TYPE prevId = sp->_pageID - 1;
auto kv = _idSpanMap.find(prevId);
if (kv == _idSpanMap.end()) break;//没找到前序spann
span* prevSp = kv->second;
if (prevSp->_isUse) break;//前序span正被使用
if (prevSp->_n + sp->_n >= PAGES) break;//两个span加起来大于1MB,说明从系统中来时不是同时分配的空间
//合并
sp->_pageID = prevSp->_pageID;//只记录整体的起始地址
sp->_n += prevSp->_n;//记录一共多少个页
_spanlists[prevSp->_n].erase(prevSp);//前序span从对应桶中删除
delete prevSp;
}
//向后合并
while (1) {
...
}
//放入对应桶中
_spanlists[sp->_n].push_front(sp);
sp->_isUse = false;//此时span回到page cache内部,状态设为未使用
_idSpanMap[sp->_pageID] = sp;//记录到索引之中
_idSpanMap[sp->_pageID + sp->_n - 1] = sp;
}七.流程图
(一).申请内存

(二).释放内存

八.优化
(一).直接从系统获取内存
上述代码中,我们采用调用new函数来获取内存,虽然这样没问题,但因为高并发内存池本身就是用来提升malloc/new效率的,因此最好采用直接从系统获取内存的方式。释放内存同理也采用系统接口。
windows下申请内存调用VirtualAlloc函数。第一个参数是内存起始地址;第二个参数是申请大小;第三个参数是相关属性。
我们这里封装了系统调用接口,参数为页数,因此实际申请大小是页数*8KB,也就是kpage << 13。
inline static void* SystemAlloc(size_t kpage)
{
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}Linux下是brk和mmap函数,brk函数是按照堆顺序从低地址向高地址申请内存,mmap可以从堆任意未分配空间的位置申请但一般用于申请超过128KB大小的内存。
除此之外,我们申请自定义类对象空间时也是通过new,比如为span指针申请空间,但此时就不能直接使用系统调用接口。最好是通过自己封装一个简易的定长内存池,内部根据对象大小提前申请一批空间,申请空间时可以直接提供一个对象,当然对象也需要经过初始化,此时采用定位new即可。
(二).大块内存申请
申请大块内存也是一个很重要的场景。因为thread cache最大的桶只能装256KB,因此当申请内存超过256KB时我们就要进行特殊处理。因为申请的大小超过了thread cache和central cache能提供的最大容量,那么只需要使用page cache申请即可。
首先在对外接口上,采用直接调用page cache申请内存的方案。在page cache内部还需要进行判断,如果申请大小小于1MB即小于page cache最大的桶,那么直接通过内部函数申请一个目标大小的span即可,当然申请空间大小是经过内存对齐到页大小整数倍的。但如果申请空间超过1MB,那此时page cache内部就要直接调用系统接口申请内存。
//<TCMalloc.h>
void* tcMalloc(size_t size) {//对外的分配内存接口
if (size > CACHEMAX) {//如果申请大于256KB
size_t realSize = sizeClass::getSize(size);//内存对齐
size_t i = realSize >> PAGE_SHIFT;//根据内存大小判断需要页的数量
pageCache::getPageCache()->_mtx.lock();
span* sp = PageCache::getPageCache()->newSpan(i);
pageCache::getPageCache()->_mtx.unlock();
void* ptr = (void*)(sp->_pageID << PAGE_SHIFT);//根据起始页号找到起始地址
return ptr;
}
else
...
}//<PageCache.cpp>
span* PageCache::newSpan(size_t i) {//给central cache一个span,参数为pageCache中spanlists下标
if (i >= PAGES) {//如果申请空间大于1MB,直接从系统获取
void* ptr = SystemAlloc(i);
Span* sp = spanPool.New();//采用定长内存池获取空间:fixMemoryPool<Span> spanPool;
sp->_pageID = (size_t)ptr >> PAGE_SHIFT;
sp->_n = i;
_idSpanMap[sp->_pageID] = sp;//记录地址与span的索引关系
return sp;
}
...
}(三).解决互斥锁效率问题
因为互斥锁加锁与解锁的过程也需要消耗时间,申请和释放内存的加解锁过程效率还好,但是别忘了根据地址索引span的过程也需要加解锁。这在高并发内存池中是一个频繁的操作,尤其是随着申请释放内存频率的提升,时间消耗会越来越大。我们采用unordered_map实现索引因此必须加锁,那么有没有什么方法能够在不加锁的情况下保证索引安全呢?
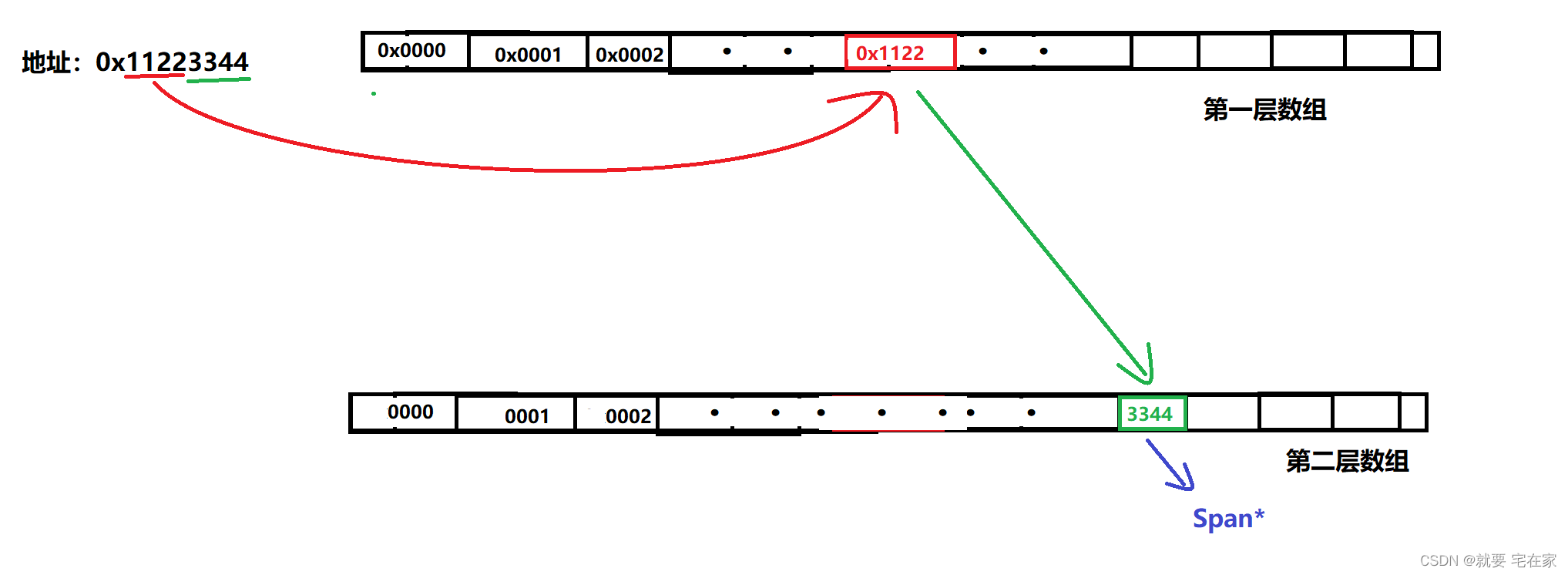
TCMalloc为我们提供了一种解决方案——基数树。首先我们知道因为增或改unordered_map都会改变底层结构(哈希桶),因此unordered_map查找必须加锁。所以需要一个增或改后结构不变的数据结构。最简单的就是直接映射,设置一个一维指针数组,将页号作为下标,每个元素记录对应span。当然也可以采用多层映射(一般是三层)的结构,按照地址的前n位先划出一维数组,根据索引地址的前n位找到对应数组元素,数组元素为数组指针,根据指针找到对应数组。该数组下标代表地址的后m位,再根据索引地址后m位找到对应元素,元素指向对应span。这种多层结构可以节省资源空间,只需要根据地址前n位开辟一个一维数组,只有当索引时再根据后m位创建第二层数组。
图示如下:
九.源码
个人项目源码地址:项目/高并发内存池 · 纽盖特/git all - 码云 - 开源中国 (gitee.com)
如有错误,敬请斧正

![IsADirectoryError: [Errno 21] Is a directory: ‘.‘](https://img-blog.csdnimg.cn/ab6bdc21fab041b8b2c597c3e12e537f.png)