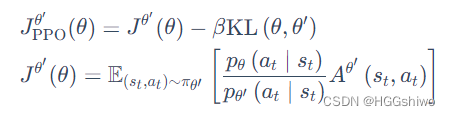文章目录
- 前言
- Motivation
- Contributions
- Method
- Facet-constrained Question Generation
- Multiform Question Prompting and Ranking
- Experiments
- Dataset
- Result
- Auto-metric evaluation
- Human evaluation
- Knowledge
前言
- 最近对一些之前的文章进行了重读,因此整理了之前的笔记
- 理解不当之处,请多多指导
- 概括:本文利用facet word,基于
GPT-2进行了 zero-shot 的限制生成,使生成的问题更容易包含facet word。同时利用了prompt,使用8种模板,对每个模板都生成一个结果,然后使用一些排序算法自动挑选出一个最终结果。 - 更多论文可见:ShiyuNee/Awesome-Conversation-Clarifying-Questions-for-Information-Retrieval: Papers about Conversation and Clarifying Questions (github.com)
Motivation
Generate clarifying questions in a zero-shot setting to overcome the cold start problem and data bias.
cold start problem: 缺少数据导致难应用,难应用导致缺少数据
data bias: 获得包括所有可能topic的监督数据不现实,在这些数据上训练也会有 bias
Contributions
- the first to propose a zero-shot clarifying question generation system, which attempts to address the cold-start challenge of asking clarifying questions in conversational search.
- the first to cast clarifying question generation as a constrained language generation task and show the advantage of this configuration.
- We propose an auxiliary evaluation strategy for clarifying question generations, which removes the information-scarce question templates from both generations and references.
Method
Backbone: a checkpoint of GPT-2
- original inference objective is to predict the next token given all previous texts

Directly append the query q q q and facet f f f as input and let GPT-2 generate cq will cause two challenges:
- it does not necessarily cover facets in the generation.
- the generated sentences are not necessarily in the tone of clarifying questions
We divide our system into two parts:
- facet-constrained question generation(tackle the first challenge)
- multi-form question prompting and ranking(tackle the second challenge, rank different clarifying questions generated by different templates)
Facet-constrained Question Generation
Our model utilizes the facet words not as input but as constraints. We employ an algorithm called Neurologic Decoding. Neurologic Decoding is based on beam search.
-
in t t t step, assuming the already generated candidates in the beam are 𝐶 = { 𝑐 1 : 𝑘 } 𝐶 = \{𝑐_{1:𝑘} \} C={c1:k}, k k k is the beam size, c i = x 1 : ( t − 1 ) i c_i=x^i_{1:(t-1)} ci=x1:(t−1)i is the i i i th candidate, x 1 : ( t − 1 ) i x^i_{1:(t-1)} x1:(t−1)i are tokens generated from decoding step 1 to ( t − 1 ) (t-1) (t−1)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-98Ld4wAG-1678024307327)

- explain about why this method could better constrain the decoder to generate facet-related questions:
- ( 2 ) t o p − β (2)top- \beta (2)top−β is the main reason for promoting facet words in generations. Because of this filtering, Neurologic Decoding tends to discard generations with fewer facet words regardless of their generation probability
-
(
3
)
(3)
(3) the group is the key for Neurologic Decoding to explore as many branches as possible. Because this grouping method keeps the most cases $(2^{| 𝑓 |} ) $of facet word inclusions, allowing the decoder to cover the most possibilities of ordering constraints in generation
- because if we choose top K candidates directly, there may be some candidates containing same facets, this results in less situation containing diverse facets. Towards choosing the best candidate in each group and then choose top K candidates, every candidate will contain different facets.
- explain about why this method could better constrain the decoder to generate facet-related questions:
Multiform Question Prompting and Ranking
Use clarifying question templates as the starting text of the generation and let the decoder generate the rest of question body.
- if the q q q is “I am looking for information about South Africa.” Then we give the decoder “I am looking for information about South Africa. [SEP] would you like to know” as input and let it generate the rest.
- we use multiple prompts(templates) to both cover more ways of clarification and avoid making users bored
For each query, we will append these eight prompts to the query and form eight input and generate eight questions.
- use ranking methods to choose the best one as the returned question
Experiments
Zero-shot clarifying question generation with existing baselines
- Q-GPT-0:
- input: query
- QF-GPT-0:
- input: facet + query
- Prompt-based GPT-0: includes a special instructional prompt as input
- input: q “Ask a question that contains words in the list [f]”
- Template-0: a template-guided approach using GPT-2
- input: add the eight question templates during decoding and generate the rest of the question
Existing facet-driven baselines(finetuned):
- Template-facet: append the facet word right after the question template

- QF-GPT: a GPT-2 finetuning version of QF-GPT-0.
- finetunes on a set of tuples in the form as f [SEP] q [BOS] cq [EOS]
- Prompt-based finetuned GPT: a finetuning version of Prompt-based GPT-0
- finetune GPT-2 with the structure: 𝑞 “Ask a question that contains words in the list [𝑓 ].” 𝑐𝑞
Note: simple facets-input finetuning is highly inefficient in informing the decoder to generate facet-related questions by observing a facet coverage rate of only 20%
Dataset
ClariQ-FKw: has rows of (q,f,cq) tuples.
qis an open-domain search query,fis a search facet,cqis a human-generated clarifying question- The facet in
ClariQis in the form of a faceted search query.ClariQ-FKwextracts the keyword of the faceted query as its facet column and samples a dataset with 1756 training examples and 425 evaluation examples
Our proposed system does not access the training set while the other supervised learning systems can access the training set for finetuning.
Result
Auto-metric evaluation

RQ1: How well can we do in zero-shot clarifying question generation with existing baselines
- all these baselines(the first four rows) struggle to produce any reasonable generations except for Template-0(but it’s question body is not good)
- we find existing zero-shot GPT-2-based approaches cannot solve the clarifying question generation task effectively.
RQ2: the effectiveness of facet information for facet-specific clarifying question generation
- compare our proposed zero-shot facet constrained (ZSFC) methods with a facet-free variation of ZSFC named Subject-constrained which uses subject of the query as constraints.
- our study show that adequate use of facet information can significantly improve clarifying question generation quality
RQ3: whether our proposed zeroshot approach can perform the same or even better than existing facet-driven baselines
- We see that from both tables, our zero-shot facet-driven approaches are always better than the finetuning baselines
Note: Template-facet rewriting is a simple yet strong baseline that both finetuning-based methods are actually worse than it.
Human evaluation
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5eC8PWul-1678024307328)
Knowledge
Approaches to clarifying query ambiguity can be roughly divided into three categories:
- Query Reformulation: iteratively refine the query
- is more efficient in context-rich situations
- Query Suggestion: offer related queries to the user
- is good for leading search topics, discovering user needs
- Asking Clarifying Questions: proactively engages users to provide additional context.
- could be exclusively helpful to clarify ambiguous queries without context.