2023.02.28—2023.03.05
Top Papers
Subjects: cs.CL
1.Language Is Not All You Need: Aligning Perception with Language Models

标题:KOSMOS-1:语言不是你所需要的全部:将感知与语言模型相结合
作者:Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv
文章链接:https://arxiv.org/abs/2302.14045



语言、多模式感知、动作和世界建模的大融合是通向通用人工智能的关键一步。在这项工作中,我们介绍了 Kosmos-1,这是一种多模态大型语言模型 (MLLM),它可以感知一般模态、在上下文中学习(即少镜头)并遵循指令(即零镜头)。具体来说,我们在网络规模的多模式语料库上从头开始训练 Kosmos-1,包括任意交错的文本和图像、图像-说明对和文本数据。我们在没有任何梯度更新或微调的情况下,在广泛的任务上评估各种设置,包括零样本、少样本和多模态思维链提示。实验结果表明,Kosmos-1 在 (i) 语言理解、生成,甚至无 OCR NLP(直接输入文档图像),(ii) 感知语言任务,包括多模态对话、图像字幕、视觉问题等方面取得了令人印象深刻的表现回答,以及 (iii) 视觉任务,例如带有描述的图像识别(通过文本指令指定分类)。我们还表明,MLLM 可以从跨模态迁移中受益,即将知识从语言迁移到多模态,以及从多模态迁移到语言。此外,我们还引入了一个 Raven IQ 测试数据集,用于诊断 MLLM 的非语言推理能力。
上榜理由
这是微软在2.27最新发布的多模式大型语言模型 (MLLM):
他们的模型可以理解图像、文本、带文本的图像、OCR、图像字幕、视觉 QA。它甚至可以解决智商测试。
KOSMOS-1 可以感知一般模式,在上下文中学习(即少镜头),并遵循指令(即零镜头)。KOSMOS-1 在网络规模的多模式语料库上从头开始训练,包括任意交错的文本和图像、图像-标题对和文本数据。
该团队还引入了 Raven IQ 测试数据集,用于诊断 MLLM 的非语言推理能力。
多模式思维链提示使 KOSMOS-1 能够处理复杂的问答和推理任务。
2.EvoPrompting: Language Models for Code-Level Neural Architecture Search

标题:EvoPrompting:用于代码级神经架构搜索的语言模型
作者:Angelica Chen, David M. Dohan, David R. So
文章链接:https://arxiv.org/abs/2302.14838v1


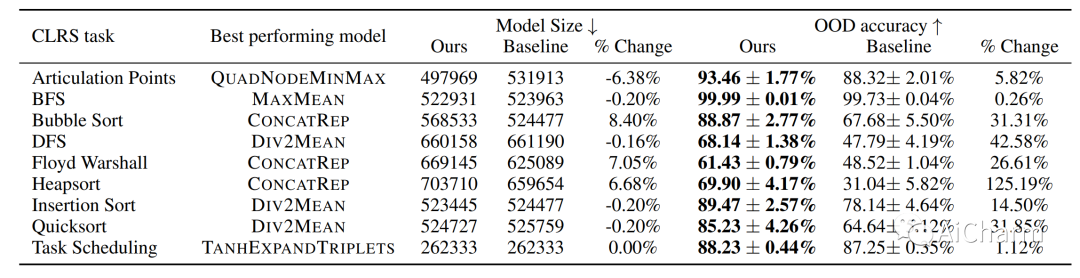
鉴于最近用于代码生成的语言模型 (LM) 取得的令人瞩目的成就,我们探索了将 LM 作为自适应变异和交叉算子用于进化神经架构搜索 (NAS) 算法的用途。虽然 NAS 仍然证明 LM 仅通过提示无法成功完成一项任务太难,但我们发现进化提示工程与软提示调整的结合,我们称之为 EvoPrompting 的方法,始终如一地找到多样化和高性能的模型。我们首先证明 EvoPrompting 在计算高效的 MNIST-1D 数据集上是有效的,其中 EvoPrompting 产生的卷积架构变体在准确性和模型大小方面优于人类专家设计的变体和朴素的少样本提示。然后,我们将我们的方法应用于在 CLRS 算法推理基准上搜索图神经网络,其中 EvoPrompting 能够设计新颖的架构,在 30 个算法推理任务中的 21 个上优于当前最先进的模型,同时保持相似的模型大小. EvoPrompting 成功地在各种机器学习任务中设计出准确高效的神经网络架构,同时也具有足够的通用性,可以轻松适应神经网络设计以外的其他任务。
Subjects: cs.CV
1.High-resolution image reconstruction with latent diffusion models from human brain activity(CVPR 2023)

标题:利用人脑活动的潜在扩散模型重建高分辨率图像
作者:Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, Jingren Zhou
文章链接:https://www.biorxiv.org/content/10.1101/2022.11.18.517004v2
项目代码:https://github.com/yu-takagi/StableDiffusionReconstruction

正在上传…重新上传取消
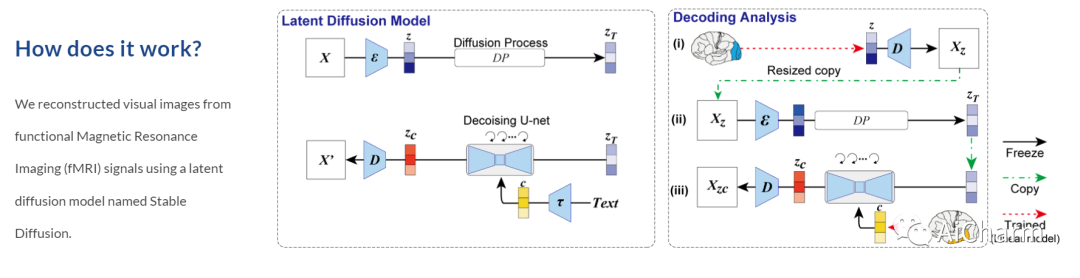
从人类大脑活动重建视觉体验提供了一种独特的方式来理解大脑如何代表世界,并解释计算机视觉模型与我们的视觉系统之间的联系。虽然最近已将深度生成模型用于此任务,但重建具有高语义保真度的逼真图像仍然是一个具有挑战性的问题。在这里,我们提出了一种基于扩散模型 (DM) 的新方法来重建通过功能磁共振成像 (fMRI) 获得的人脑活动图像。更具体地说,我们依赖于称为稳定扩散的潜在扩散模型 (LDM)。该模型降低了 DM 的计算成本,同时保留了它们的高生成性能。我们还通过研究 LDM 的不同组件(例如潜在向量 Z、调节输入 C 和去噪 U-Net 的不同元素)如何与不同的大脑功能相关来表征 LDM 的内部机制。我们表明,我们提出的方法可以以直接的方式重建具有高保真度的高分辨率图像,而无需对复杂的深度学习模型进行任何额外的训练和微调。我们还从神经科学的角度对不同的 LDM 组件进行了定量解释。总的来说,我们的研究提出了一种从人类大脑活动中重建图像的有前途的方法,并为理解 DM 提供了一个新的框架。
上榜理由
这是CVPR2023开源的一篇论文,它的神奇点在于:
从某意义上来说,它实现了读心术,简单框架可以从具有高语义保真度的大脑活动中重建高分辨率图像,而无需训练或微调复杂的深度生成模型。我只想说For real?
它利用今年最火的稳定扩散的潜在扩散模型从功能性磁共振成像 (fMRI) 信号重建视觉图像。
通过将特定组件映射到大脑区域,从神经科学的角度定量解释 LDM 的每个组件。还客观解释了 LDM 实现的文本到图像转换过程如何结合条件文本表达的语义信息,同时保持原始图像的外观。
2.X&Fuse: Fusing Visual Information in Text-to-Image Generation

标题:X&Fuse:在文本到图像生成中融合视觉信息
作者:Yuval Kirstain, Omer Levy, Adam Polyak
文章链接:https://arxiv.org/abs/2303.01000
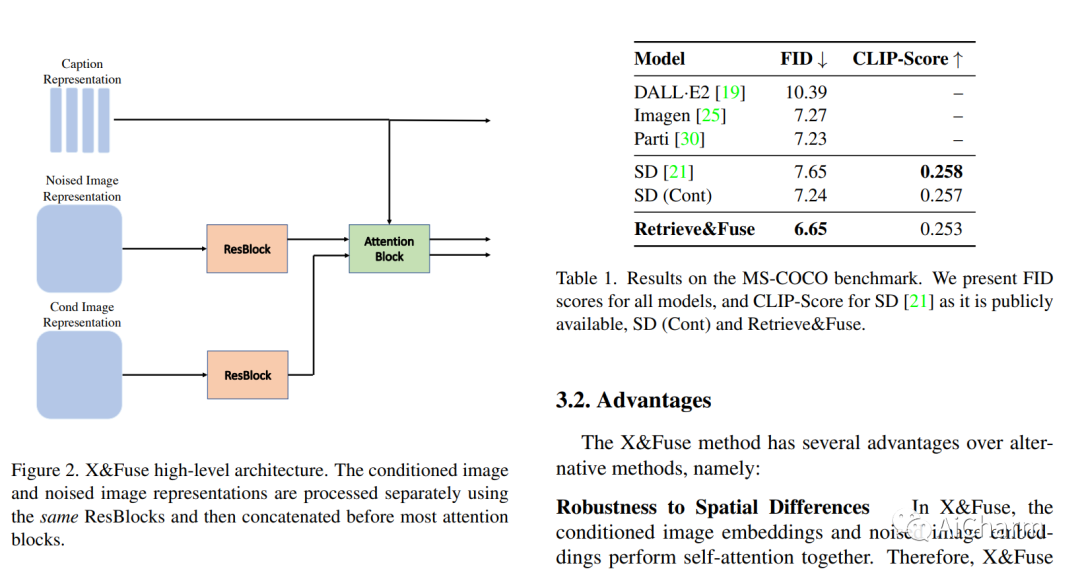


我们介绍了 X&Fuse,这是一种在从文本生成图像时调节视觉信息的通用方法。我们展示了 X&Fuse 在三种不同的文本到图像生成场景中的潜力。 (i) 当一组图像可用时,我们检索并调整相关图像 (Retrieve&Fuse),从而显着改进 MS-COCO 基准测试,在零 - 中获得 6.65 的最新 FID 分数拍摄设置。 (ii) 当裁剪对象图像在手边时,我们利用它们并执行主题驱动生成 (Crop&Fuse),优于文本反转方法,同时速度超过 x100。 (iii) 拥有对图像场景 (Scene&Fuse) 的 oracle 访问权限,使我们能够在零镜头设置中在 MS-COCO 上获得 5.03 的 FID 分数。我们的实验表明,对于模型可能受益于额外视觉信息的场景,X&Fuse 是一种有效、易于适应、简单且通用的方法。
3.Imagic: Text-Based Real Image Editing with Diffusion Models

标题:Imagic:使用扩散模型进行基于文本的真实图像编辑
作者:Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, Michal Irani
文章链接:https://arxiv.org/abs/2302.04761
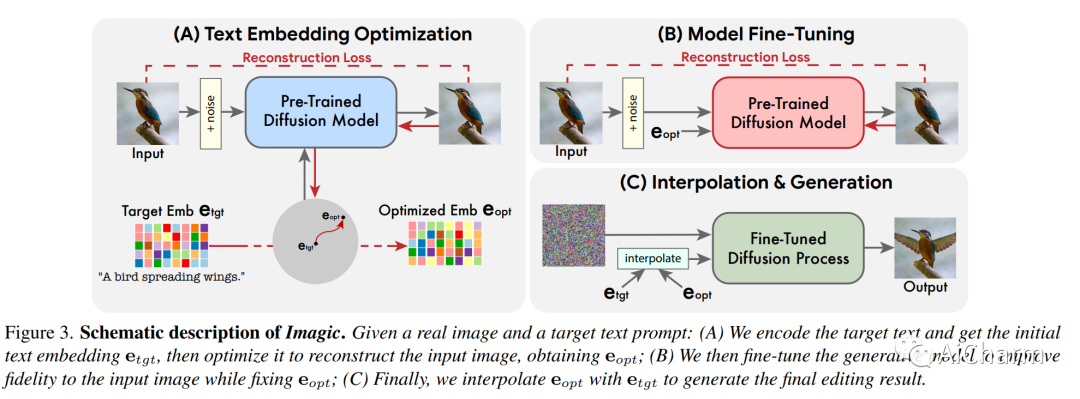

文本条件图像编辑最近引起了相当大的兴趣。然而,目前大多数方法要么限于特定的编辑类型(例如,对象叠加、样式转换),要么适用于合成生成的图像,要么需要一个共同对象的多个输入图像。在本文中,我们首次展示了将复杂(例如,非刚性)文本引导的语义编辑应用于单个真实图像的能力。例如,我们可以改变图像中一个或多个对象的姿势和构图,同时保留其原始特征。我们的方法可以让一只站立的狗坐下或跳跃,让一只鸟张开翅膀,等等——每一个都在用户提供的单一高分辨率自然图像中。与之前的工作相反,我们提出的方法只需要一个输入图像和一个目标文本(所需的编辑)。它对真实图像进行操作,不需要任何额外的输入(例如图像蒙版或对象的额外视图)。我们的方法,我们称之为“想象”,利用预训练的文本到图像扩散模型来完成这项任务。它生成与输入图像和目标文本对齐的文本嵌入,同时微调扩散模型以捕获特定于图像的外观。我们在来自不同领域的大量输入上展示了我们方法的质量和多功能性,展示了大量高质量的复杂语义图像编辑,所有这些都在一个统一的框架内。
Subjects: cs.RL
1.Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes(ICLR 2023 notable top 5%)

标题:对不同多任务数据的离线 Q 学习既可扩展又可泛化
作者:Aviral Kumar, Rishabh Agarwal, Xinyang Geng, George Tucker, Sergey Levine
文章链接:https://openreview.net/forum?id=4-k7kUavAj
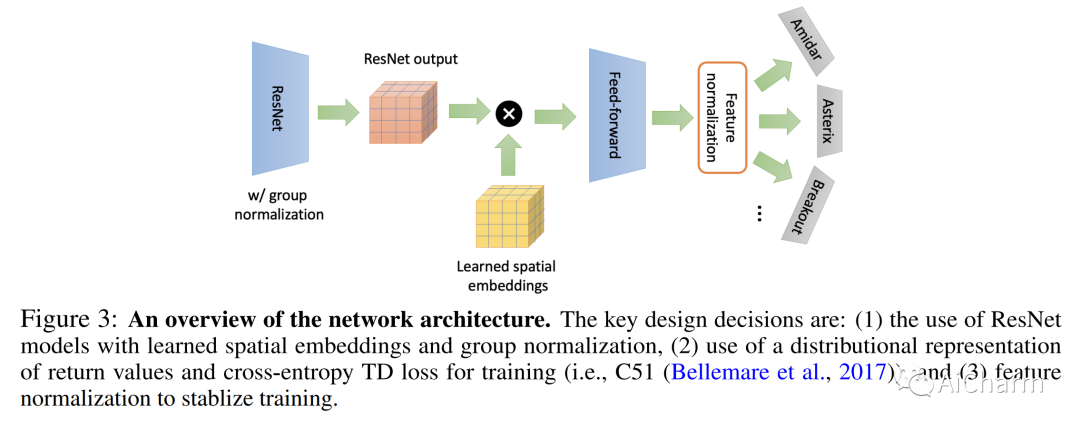

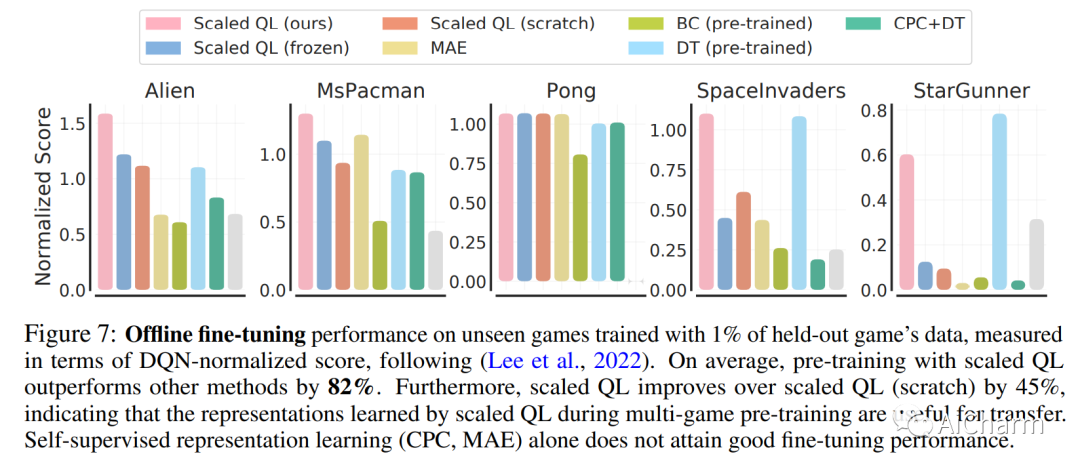
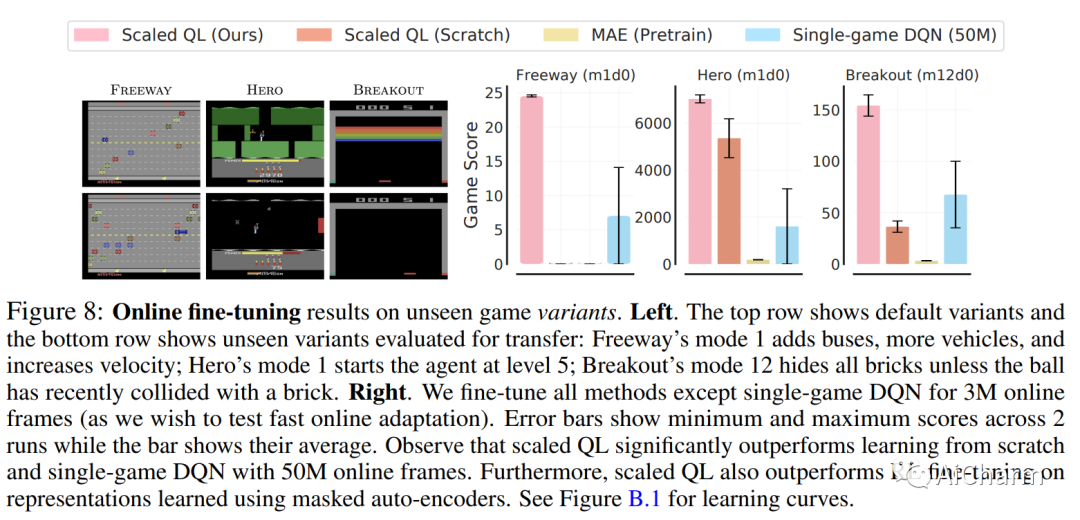
离线强化学习 (RL) 的潜力在于,在大型异构数据集上训练的高容量模型可以产生广泛泛化的代理,类似于视觉和 NLP 中的类似进步。然而,最近的研究表明,离线强化学习方法在扩大模型容量方面遇到了独特的挑战。借鉴这些工作的经验,我们重新审视了以前的设计选择,并发现通过适当的选择:ResNet、基于交叉熵的分布式备份和特征归一化,离线 Q 学习算法表现出随模型容量扩展的强大性能。使用多任务 Atari 作为扩展和泛化的测试平台,我们使用多达 8000 万个参数网络对 40 款具有接近人类性能的游戏训练单一策略,发现模型性能随容量扩展。与之前的工作相比,即使完全在大型(400M 转换)但高度次优的数据集(51% 的人类水平性能)上进行训练,我们也可以推断出超出数据集的性能。与返回条件监督方法相比,离线 Q-learning 与模型容量的比例相似并且具有更好的性能,尤其是当数据集不是最优的时候。最后,我们表明,具有多样化数据集的离线 Q 学习足以学习强大的表示,这些表示有助于快速转移到新游戏和快速在线学习训练游戏的新变体,改进现有的最先进的表示学习方法。
上榜理由
这是ICLR 2023 值得注意的前 5%的论文。
ICLR会议主席:本文旨在通过离线强化学习扩大模型容量并提高泛化性能。特别是,建议的设计选择包括对 ResNet 进行修改、利用基于交叉熵的分布式备份和利用特征归一化。实验结果表明,该方法的有效性能够实现强大的缩放趋势,并且能够显着超越训练轨迹的分数。由于所有审稿人都同意所提出的方法和深入的实验评估背后的新颖性和扎实的直觉,我想选择 Accept with Oral。
审稿人:我认为这篇论文的质量远远超过我目前给出的分数(5 分)。我给这个分数是因为我认为作者(可以访问大量的计算能力和资源)应该解决我提出的一些问题。一个简单的反驳是,“研究不同种类的离线 RL 训练算法超出了本文的范围”——我完全理解这一点,但作者有很好的实验装置和大量数据,我对此表示怀疑许多其他人都可以访问 - 对我的问题进行一些初步调查将使离线 RL 社区受益匪浅。
Notable Papers
1.Colossal-Auto: Unified Automation of Parallelization and Activation Checkpoint for Large-scale Models
标题:Colossal-Auto:大型模型的并行化和激活检查点的统一自动化
文章链接:https://arxiv.org/abs/2302.02599v2
项目代码:https://github.com/hpcaitech/ColossalAI

摘要:
近年来,大型模型在各个领域都展示了最先进的性能。然而,训练此类模型需要各种技术来解决 GPU 等设备上计算能力和内存有限的问题。一些常用的技术包括流水线并行、张量并行和激活检查点。虽然现有工作的重点是寻找高效的分布式执行计划 (Zheng et al. 2022) 和激活检查点调度 (Herrmann et al. 2019, Beaumont et al. 2021},但还没有提出联合优化这两个计划的方法。此外,提前编译在很大程度上依赖于准确的内存和计算开销估计,这通常是耗时且具有误导性的。现有的训练系统和机器学习管道要么物理地执行每个操作数,要么使用缩放的输入张量估计内存使用量。要解决这些挑战,我们引入了一个可以联合优化分布式执行和梯度检查点计划的系统。此外,我们还提供了一个易于使用的符号分析器,可以以最少的时间成本为任何 PyTorch 模型生成内存和计算统计信息。我们的方法允许用户以最小的代码更改为基础,在给定的硬件上并行化他们的模型训练。
2.SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
标题:SpikeGPT:带有尖峰神经网络的生成式预训练语言模型
文章链接:https://arxiv.org/abs/2302.12238
项目代码:https://github.com/ridgerchu/spikegpt

摘要:
随着大型语言模型的规模不断扩大,运行它所需的计算资源也在不断扩大。尖峰神经网络 (SNN) 已成为一种节能的深度学习方法,它利用稀疏和事件驱动的激活来减少与模型推理相关的计算开销。虽然它们在许多计算机视觉任务上已经与非尖峰模型竞争,但事实证明 SNN 的训练更具挑战性。因此,它们的性能落后于现代深度学习,我们还没有看到 SNN 在语言生成方面的有效性。在本文中,受 RWKV 语言模型的启发,我们成功地实现了“SpikeGPT”,这是一种具有纯二进制、事件驱动的尖峰激活单元的生成语言模型。我们在三个模型变体上训练所提出的模型:45M、125M 和 260M 参数。据我们所知,这比迄今为止任何功能性反向传播训练的 SNN 大 4 倍。我们通过修改 transformer 块来替换 multi-head self attention 来实现这一点,以随着序列长度的增加将二次计算复杂度降低到线性。相反,输入令牌按顺序流入我们的注意力机制(与典型的 SNN 一样)。我们的初步实验表明,SpikeGPT 在测试基准上与非尖峰模型相比仍然具有竞争力,同时在可以利用稀疏、事件驱动的激活的神经形态硬件上进行处理时,能耗降低了 5 倍。
3.OccDepth: A Depth-Aware Method for 3D Semantic Scene Completion
标题:OccDepth:一种用于 3D 语义场景补全的深度感知方法
文章链接:https://arxiv.org/abs/2302.12192
项目代码:https://github.com/megvii-research/occdepth

摘要:
3D语义场景补全(SSC)可以提供密集的几何和语义场景表示,可应用于自动驾驶和机器人系统领域。仅从视觉图像估计场景的完整几何和语义具有挑战性,准确的深度信息对于恢复 3D 几何至关重要。在本文中,我们提出了第一个名为 OccDepth 的立体 SSC 方法,它充分利用立体图像(或 RGBD 图像)中的隐式深度信息来帮助恢复 3D 几何结构。提出了立体软特征分配(Stereo-SFA)模块,以通过隐式学习立体图像之间的相关性来更好地融合 3D 深度感知特征。特别地,当输入是RGBD图像时,可以通过原始RGB图像和深度图生成虚拟立体图像。此外,Occupancy Aware Depth (OAD) 模块用于使用预训练的深度模型通过知识蒸馏获得几何感知的 3D 特征。此外,本文还提供了一个名为 SemanticTartanAir 的改进 TartanAir 基准,用于进一步测试我们在 SSC 任务上的 OccDepth 方法。与最先进的 RGB 推断 SSC 方法相比,在 SemanticKITTI 上的大量实验表明,我们的 OccDepth 方法实现了卓越的性能,提高了 +4.82% mIoU,其中 +2.49% mIoU 来自立体图像,+2.33% mIoU来自我们提出的深度感知方法。
![[C++]vector模拟实现](https://img-blog.csdnimg.cn/2c75a68a41454f10a47da1e110d276cc.png)