【NLP相关】ChatGPT的前世今生:GPT模型的原理、研究进展和案例
自然语言处理(NLP)是人工智能领域中最为热门的研究方向之一,近年来在自然语言生成、文本分类、机器翻译等任务上取得了许多重要进展。而GPT模型(Generative Pre-trained Transformer)作为NLP领域中的新宠,具有许多优势,已经被广泛应用于各种任务中。本文将会介绍GPT模型的原理、优劣势以及其在实际应用中的案例和代码,并延伸介绍GPT类模型的研究进展。
1. GPT模型的原理
GPT模型是一种基于Transformer的语言模型,其基本原理是使用大规模语料库进行预训练,再在特定任务上进行微调,从而得到对该任务的优化模型。
在GPT中,使用了一种叫做自监督学习的技术来预训练模型。自监督学习是指利用无需人工标注的数据,让模型在特定任务上自我学习和调整参数,以提高模型的泛化能力。具体而言,GPT通过预测序列中缺失的某个单词或单词的顺序来进行预训练,这个任务被称为语言模型任务。例如,给定句子中的前几个单词,GPT需要预测下一个单词,这个任务可以在大规模无监督语料库上训练,例如维基百科等。
预训练阶段结束后,GPT可以通过微调来完成下游任务,例如文本分类、语义相似度计算等。在微调阶段,GPT将在有标注数据集上进行有监督学习,通过反向传播算法调整模型参数,以提高模型在特定任务上的性能。
通过以上的无监督和有监督预训练,GPT模型可以学习到文本中的语言规律和上下文信息,从而成为一个具有强大语言生成能力的模型。
2. GPT-1、GPT-2和GPT-3的介绍
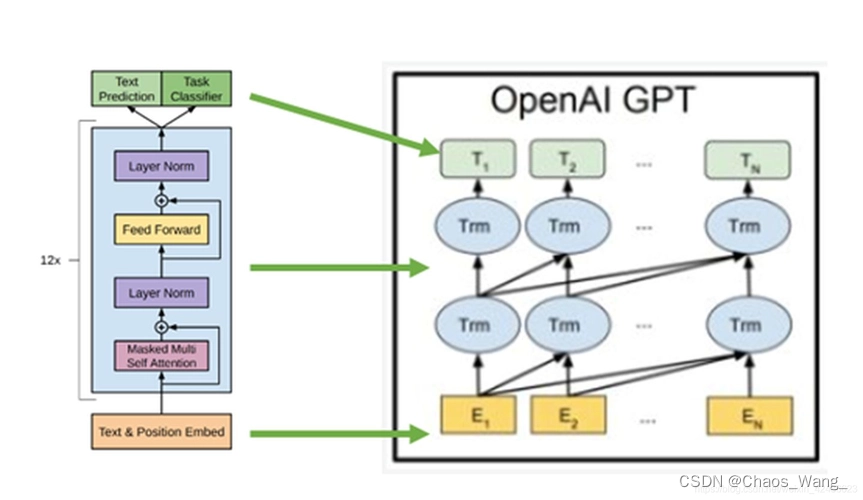
GPT是由OpenAI开发的一系列基于深度学习的自然语言处理模型。GPT的全称是Generative Pre-trained Transformer,其核心是基于Transformer架构的神经网络,主要用于生成自然语言文本。以下是GPT-1、GPT-2和GPT-3的原理、训练过程以及区别和联系的简要介绍。
(1)GPT-1
GPT-1是OpenAI于2018年发布的第一个GPT模型,使用了117M个参数。GPT-1的核心思想是预训练语言模型,即通过在大规模语料库上进行无监督学习,使模型学会理解和生成自然语言文本。GPT-1的预训练过程包括两个阶段:第一个阶段是无标签的预训练,即在语料库上进行自监督学习,学习输入序列与输出序列之间的关系;第二个阶段是有标签的微调,即在特定任务上进行有监督学习,以进一步提高模型的性能。
(2)GPT-2
GPT-2是OpenAI于2019年发布的第二个GPT模型,使用了1.5B个参数。GPT-2相对于GPT-1的改进在于使用了更大的模型和更广泛的训练数据集,并且取消了微调阶段。GPT-2的训练过程包括单一的预训练阶段,通过在大规模语料库上进行无监督学习来训练模型。GPT-2还使用了一种名为“无样本生成”的技术,可以在没有任何文本提示的情况下生成连贯的文本段落。
(3)GPT-3
GPT-3是OpenAI于2020年发布的第三个GPT模型,使用了175B个参数。GPT-3相对于GPT-2的改进在于使用了更大的模型和更广泛的训练数据集,并且引入了一种名为“多任务学习”的训练方式。在多任务学习中,模型被同时训练用于多个不同的任务,从而提高了模型的泛化能力和效果。GPT-3还引入了一种名为“零样本学习”的技术,可以在没有任何训练数据的情况下进行新任务的学习。
(4)区别和联系
GPT-1、GPT-2和GPT-3的核心思想都是预训练语言模型,即通过在大规模语料库上进行无监督学习,使模型学会理解和生成自然语言文本。它们的训练过程都包括预训练阶段和微调阶段(GPT-2除外),而且它们都使用了Transformer架构,Transformer架构是一种自注意力机制,可以处理序列数据并捕捉长期依赖关系。但是,它们之间也有一些区别和联系:
-
参数量:随着模型的升级,GPT-1、GPT-2和GPT-3的参数量不断增加,分别为117M、1.5B和175B。
-
训练数据集:GPT-1、GPT-2和GPT-3使用了不同规模和不同领域的训练数据集,其中GPT-3的训练数据集更加广泛和多样化,但具体数据量并没有公开披露。
-
训练方式:GPT-1和GPT-2的训练方式都采用预训练+微调的方式,而GPT-3引入了多任务学习和零样本学习的训练方式,以进一步提高模型的泛化能力和效果。
-
生成能力:随着模型的升级,GPT-1、GPT-2和GPT-3的生成能力都有所提高,尤其是GPT-3的生成能力更为出色,可以生成极其逼真的自然语言文本,有时甚至可以欺骗人类。
3. GPT模型的优势和劣势
3.1 优势
-
(1)高效的语言生成能力
GPT模型能够生成流畅、连贯、自然的文本,可以用于自动文本摘要、机器翻译、对话系统等任务。 -
(2)大规模数据集的预训练
GPT模型使用了大规模的语料库进行预训练,从而可以在各种任务上进行微调,得到更好的性能。 -
(3)可解释性
GPT模型的结构比较简单,而且预训练过程可以提供一些可解释性的信息,例如对于一个生成的句子,可以追溯到哪些词汇和上下文信息对其生成起到了关键作用。 -
(4)可扩展性
GPT模型可以通过不同规模的预训练语料库进行训练,从而可以适应不同大小的任务和数据集。
3.2 劣势
-
(1)需要大量计算资源
GPT模型需要大量的计算资源进行训练和推断,包括GPU和大量的内存。 -
(2)存在生成偏差
由于GPT模型是通过预测下一个词来生成句子的,因此在某些情况下会出现生成偏差的问题,例如生成重复的词汇或者过度使用某些单词。
4. GPT-1、GPT-2、GPT-3对比
| 模型 | 发布时间 | 参数量 | 训练时长 | 训练耗费 | 所用GPU数目 | 训练数据量 |
|---|---|---|---|---|---|---|
| GPT-1 | 2018年11月 | 117M | - | - | - | 约5GB |
| GPT-2 | 2019年2月 | 1.5B | 数周 | - | - | 约40GB |
| GPT-3 | 2020年6月 | 175B | 数月 | 约460万美元 | 1024 张 80GB A100需1一个月 | 约45TB |
5. GPT模型的公式推导
GPT模型使用的是Transformer的结构,其核心思想是自注意力机制(Self-Attention Mechanism),可以用以下公式表示:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
其中, Q , K , V Q,K,V Q,K,V分别表示查询向量、键向量和值向量, d k d_k dk表示向量的维度。这个公式表示的是查询向量与键向量的相似度,然后再根据相似度的权重对值向量进行加权,从而得到输出向量。
GPT模型使用了多头自注意力机制,可以用以下公式表示:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
head
2
,
⋯
,
head
h
)
W
O
MultiHead(Q,K,V)=\text{Concat}(\text{head}_1,\text{head}_2,\cdots,\text{head}_h)W^O
MultiHead(Q,K,V)=Concat(head1,head2,⋯,headh)WO
其中, head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)表示第 i i i个注意力头, h h h表示头的数量, W i Q , W i K , W i V W_i^Q,W_i^K,W_i^V WiQ,WiK,WiV分别表示查询、键、值的投影矩阵, W O W^O WO表示最终输出的投影矩阵。
GPT模型的结构可以用以下公式表示:
GPT ( x ) = TransformerDecoder ( Embedding ( x ) ) \text{GPT}(x)=\text{TransformerDecoder}(\text{Embedding}(x)) GPT(x)=TransformerDecoder(Embedding(x))
其中, x x x表示输入序列, Embedding \text{Embedding} Embedding表示词嵌入层, TransformerDecoder \text{TransformerDecoder} TransformerDecoder表示Transformer的解码器。
6. GPT类模型的研究进展
GPT模型在自然语言处理领域的应用已经非常广泛,除了生成文本和文本分类之外,还可以用于问答系统、机器翻译、对话系统等任务。近年来,GPT类模型的研究进展非常迅速,出现了许多新的模型和算法,例如:
- (1)GPT-3
GPT-3是GPT系列模型的最新版本,拥有1750亿个参数,是迄今为止最大的自然语言处理模型之一。GPT-3的应用范围非常广泛,可以用于生成文本、文本分类、问答系统等任务,甚至可以完成一些常规编程任务。
- (2)T5
T5是一种基于转换器的序列到序列模型,可以用于各种自然语言处理任务。T5不仅可以进行生成式任务,还可以进行分类、标注等任务,甚至可以用于图像生成和语音识别等领域。
- (3)UniLM
UniLM是一种多任务学习模型,可以用于各种自然语言处理任务。UniLM将生成任务和理解任务统一到一个框架中,可以通过联合训练,实现模型参数共享,从而提高模型的效率和泛化能力。
- (4)GShard
GShard是一种分布式训练框架,可以支持训练拥有数百亿个参数的自然语言处理模型。GShard使用数据并行和模型并行相结合的方式,可以在大规模分布式系统上高效地训练模型,从而提高模型的训练速度和精度。
7. GPT模型的案例和代码
7.1 生成文本
下面是使用GPT-2生成文本的Python代码示例:
import torch
import numpy as np
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
input_text = 'The quick brown fox'
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(input_ids, max_length=50, do_sample=True)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
7.2 文本分类
下面是使用GPT-2进行文本分类的Python代码示例:
import torch
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2ForSequenceClassification.from_pretrained('gpt2')
input_text = 'The quick brown fox'
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model(input_ids)
logits = outputs.logits
predicted_label = torch.argmax(logits, dim=1).item()
print(predicted_label)
参考文献
[1] 预训练语言模型之GPT-1,GPT-2和GPT-3 https://zhuanlan.zhihu.com/p/350017443
[2] 从GPT-1到GPT-4看ChatGPT的崛起 https://baijiahao.baidu.com/s?id=1751371730335726395





![[2019红帽杯]childRE](https://img-blog.csdnimg.cn/4c1c595c24e542b6b8c000a8e9c160fd.png)