1.说说ArrayList
1.基本原理
ArrayList,原理就是底层基于数组来实现。
01.基本原理:
数组的长度是固定的,java里面数组都是定长数组,比如数组大小设置为100,此时你不停的往ArrayList里面塞入这个数据,此时元素数量超过了100以后,此时就会发生一个数组的扩容,就会搞一个更大的数组,把以前的数组拷贝到新的数组里面去。
这个数组扩容+元素拷贝的过程,相对来说会慢一些
02.缺点:
01:不要频繁的往arralist里面去塞数据,导致他频繁的数组扩容,避免扩容的时候较差的性能影响了系统的运行。
02: 数组来实现,数组你要是往数组的中间加一个元素,是不是要把数组中那个新增元素后面的元素全部往后面挪动一位,所以说,如果你是往ArrayList中间插入一个元素,或者随机删除某个元素,性能比较差,会导致他后面的大量的元素挪动一个位置。
03.优点:
基于数组来实现,非常适合随机读,你可以随机的去读数组中的某个元素。
例如:list.get(10),相当于是在获取第11个元素,这个随机读的性能是比较高的,随机读,list.get(2),list.get(20),随机读list里任何一个元素。
因为基于数组来实现,他在随机获取数组里的某个元素的时候,性能很高,他可以基于他底层对数组的实现来快速的随机读取到某个元素,直接可以通过内存地址来定位某个元素。
04.常用场景:
ArrayList,常用,如果你不会频繁的在里面插入一些元素,不会导致频繁的元素的位置移动、数组扩容,就是有一批数据,查询出来,灌入ArrayList中,后面不会频繁插入元素了,主要就是遍历这个集合,或者是通过索引随机读取某个元素。
如果果你涉及到了频繁的插入元素到list中的话,尽量还是不要用ArrayList,数组,定长数组,长度是固定的,元素大量的移动,数组的扩容+元素的拷贝。
05.场景示例:
开发系统的时候,大量的场景,需要一个集合,里面可以按照顺序灌入一些数据,ArrayList的话呢,他的最最主要的功能作用,就是说他里面的元素是有顺序的,我们在系统里的一些数据,都是需要按照我插入的顺序来排列的。
2.源码剖析
01.核心方法的剖析
咱们来启动一个demo工程,在里面写写集合的代码,跟进去看看各种集合的实现原理,直接可以看JDK底层的源码。
(1).示例代码:
public class ArrayListDemo {
public static void main(String[] args) {
ArrayList<String> sayLove =new ArrayList<String>();
sayLove.add("老婆,早上好");
sayLove.add("老婆,下午好");
sayLove.add("老婆,下班啦,我去找你");
sayLove.set(0,"老婆,早上好,我们一起吃早饭吧");
sayLove.add(2,"老婆,注意坐姿,不要久坐哦");
}
}
(2).构造函数分析:
默认的构造函数,直接初始化一个ArrayList实例的话,会将内部的数组做成一个默认的空数组,{},Object[],他有一个默认的初始化的数组的大小的数值,是10,也就是我们可以认为他默认的数组初始化的大小就是只有10个元素。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};//空数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
private static final int DEFAULT_CAPACITY = 10;//初始容量 10
注意点:
ArrayList的话,玩儿好的话,一般来说,你应该都不是使用这个默认的构造函数,你构造一个ArrayList的话,基本上来说就是默认他里面不会有太频繁的插入、移除元素的操作,大体上他里面有多少元素,你应该可以推测一下的。
基本上最好是给ArrayList构造的时候,给一个比较靠谱的初始化的数组的大小,比如说,100个数据,1000,10000,避免数组太小,往里面塞入数据的时候,导致数据不断的扩容,不断的搞新的数组。
ensureCapacityInternal(size + 1); // Increments modCount!!你每次往ArrayList中塞入数据的时候,人家都会判断一下,当前数组的元素是否塞满了,如果塞满的话,此时就会扩容这个数组,然后将老数组中的元素拷贝到新数组中去,确保说数组一定是可以承受足够多的元素的。
(3).add(E)方法
日常多表白,恩爱不懈怠。
分析如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
#2 ensureCapacityInternal(size + 1);:判断一下当前的数组容量是不是满了,如果满了会进行扩容;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
1).第一次进入这个方法时,minCapacity=10,默认值,而此时底层还是个空数组,自然会进行数组的扩容。扩容代码如下:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
通过计算,确认本次数组增加的容量就是默认大小10,然后通过Arrays.copyOf进行数组的数据拷贝和创建新数组。
#3 elementData[size++] = e;,就是将添加数据数据放到index=0的位置上,并且size+1;
2).然后就返回添加成功了。
数组的变化:
size=0,elementData={}变成了size=1,elementData=["老婆,早上好"]
依次执行三次,就完成今天的sayLove日常了。
(4).set(index,E)方法
一起起床是静好,一起吃早饭是喂饱。
sayLove.set(0,"老婆,早上好,我们一起吃早饭吧");
分析如下:
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
#2 rangeCheck(index);:还记得我们那些年学Java的青葱岁月吗?都得喊一嗓子:角标越界,错误就在这里了,熟悉的异常,值得的青葱岁月。
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
#3 E oldValue = elementData(index);:操作很简单,返回原来位置上的值,将新值插入想插入的位置,并返回旧值。
就像老婆说,你去换下饮水机的水,换上新桶,拿下旧桶。
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
(5).add(index,E)方法
牵挂是一根线,每天想的是可以把你栓在身上。
sayLove.add(2,"老婆,注意坐姿,不要久坐哦");
分析如下:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
#2,#4,还是熟悉的检查角标是否越界以及检查容量是否已满。
#5,调用native方法System.arraycopy,进行数组中元素的移位,参数如下所示:
index=2,size=3;
System.arraycopy(elementData, 新增的角标位=2, elementData, 往后移动的起始角标位=3,
要往后移动的个数=1);
elementeData这个数组,从第2位开始(第3个元素),拷贝1个元素,到elementData这个数组(还是原来的这个数组),从第3位开始(第4个元素开始)。
#5,#6,插入新值到指定位置,size+1。
完成指定位置插入数据的操作。
(6).remove(index)方法
程序猿说我下班了,绝对是违背了山盟海誓里说的,“我绝对不会骗你”。
sayLove.remove(2);//加班,所以,不能去找媳妇了。撤回 “老婆,下班啦,我去找你” 这句话。
分析如下:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
#7 int numMoved = size - index - 1;:numoved=4-2-1=1,要移动的个数,当前大于0,调用native方法,进行数组元素移动,System.arraycopy(elementData, 3, elementData, 2,1);,从当前数组的index=3位置,共一个元素,从index=2位置开始拷贝。
把elementData数组中,从index =3开始的元素,一共有1个元素,拷贝到elementData数组中(原来的数组里),从index = 2开始,进行拷贝。
说到底,就是删除位置后的所有元素都往前移位,然后将最后位置上的元素设置为null。so easy。
2.谈谈LinkedList
1.基本原理
底层是基于链表来实现的。
01.基本原理:
LinkedList,链表,一个节点挂着另外一个节点。LinkedList是基于双向链表实现的。
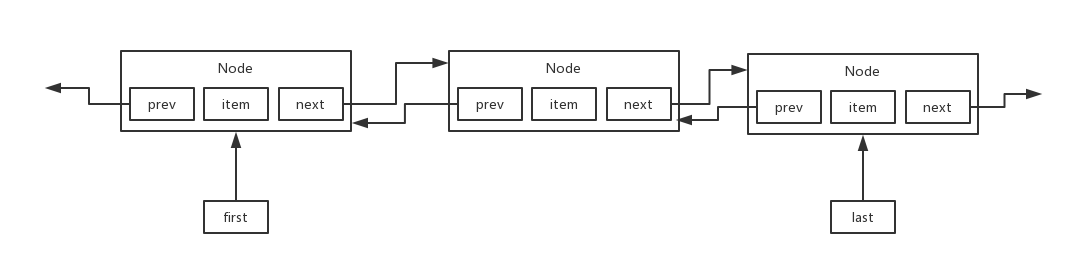
02.优点:
往这个里面中间插入一些元素,或者不停的往list里插入元素,都没关系,因为人家是链表,中间插入元素,不需要跟ArrayList数组那样子,挪动大量的元素的,不需要,人家直接在链表里加一个节点就可以了。
如果你不断的往LinkedList中插入一些元素,大量的插入,就不需要像ArrayList数组那样还要去扩容啊什么的,人家是一个链表,就是不断的把新的节点挂到链表上就可以了。
LinkedList的优点,就是非常适合各种元素频繁的插入里面去。
03.缺点:
不太适合在随机的位置,获取某个随机的位置的元素,比如LinkedList.get(10),这种操作,性能就很低,因为他需要遍历这个链表,从头开始遍历这个链表,直到找到index = 10的这个元素为止。
04.常用场景:
适合,频繁的在list中插入和删除某个元素,然后尤其是LinkedList他其实是可以当做队列来用的,这个东西的话呢,我们后面看源码的时候,可以来看一下,先进先出,在list尾部怼进去一个元素,从头部拿出来一个元素。如果要在内存里实现一个基本的队列的话,可以用LinkedList。
05.场景示例:
系统开发中,凡是用到了内存队列,用LinkedList,他里面基于链表实现,天然就可以做队列的数据结构,先进先出,链表来实现,特别适合频繁的在里面插入元素什么的,也不会导致数组扩容。
2.源码剖析
01.插入元素
在尾部插入元素、在头部插入元素、在中间插入元素
add(),默认就是在队列的尾部插入一个元素,在那个双向链表的尾部插入一个元素
add(index, element),是在队列的中间插入一个元素
addFirst(),在队列的头部插入一个元素
addLast(),跟add()方法是一样的,也是在尾部插入一个元素
(1).示例代码:
public static void main(String[] args) {
LinkedList<String> housework=new LinkedList<String>();
housework.add("洗菜");
housework.add("切肉");
housework.add("炒菜");
housework.add(1,"给老婆倒杯水");
}
(2).add(E)方法
家务活要一件件做,幸福要一天天过。
分析如下:
public boolean add(E e) {
linkLast(e);
return true;
}
#2 linkLast(e);:将元素直接插入到队尾代码如下:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
1). #2~#4: 第一次last肯定是null,创建了一个Node节点,对象结构Node<preNode,元素,next节点>;并且该节点赋值给了last变量。
2). #5~#8: 第一次last节点是null,所以first节点也被赋值成创建的node节点。而如果是第二次进行add操作的话,就是会将新的Node节点挂在到前一个Node节点的next节点上去。
3).size+1,操作成功。
(3).add(index,E)方法
老婆的事情永远可以插队,优先级No.1
housework.add(1,"给老婆倒杯水");
分析如下:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
#2 checkPositionIndex(index);:对于指定位置的插入数据,我们都是需要进行角标是否越界的检查的;
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
#4-#7:如果正好是最后一个位置,就直接插入到队尾;
如果不是,就要进行指定位置的插入,这里走的是这个分支。
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
1).先根据index获取到之前位置的node;
2).#3~#5: 1. 新创建一个Node,新Node的pre节点设置为原Node节点的pre节点,next节点设置为原node节点。
- 将原来的Node节点的pre节点设置为新Node节点。
2).#6~#9:如果原节点的pre节点是null,就把新Node节点设置为first节点;
否则就是将原Node节点的next节点设置为新创建Node节点。
3).size+1,然后就返回添加成功了。
绕来绕去,其实就像我准备栓老婆的绳子不够长了,我就把绳子剪开,然后呢,拿一节新绳子,接上前半截绳子的头,再接上后半截绳子的,打好俩个结,ok,绳子升级成功。爱情的绳子拉长啦。
02.获取元素
(1).get(index)方法
经常翻看照片,一张张翻过的是,回忆的幸福,二哈的自己和气质的媳妇。
示例代码:
public static void main(String[] args) {
LinkedList<String> loveStory=new LinkedList<String>();
loveStory.add("看电影");
loveStory.add("去野餐");
loveStory.add("摩天轮");
loveStory.add("去海边");
loveStory.get(2);
}
我们来分析这一行代码:
loveStory.get(2);
分析如下:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
#2 checkElementIndex;:角标是否越界的检查。
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
#3 node(index);:这里就极为关键了,LinkedList底层是如何遍历查找指定位置的元素呢?来看如下分析:
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
#4~#6:
1).size/2,取了中间数,然后判断我们要找的位置是在中间数的前部分还是后部分。
如果是前半部分就从first节点开始往后查找,
如果是后半部分,就从last节点开始往前查找,有点二分法查找的感觉。
2).我们这里index=2, 2>2不成立,走else分支,然后,我们可以看到他通过一个for循环进行遍历,从最后一个节点开始,每次都查找Node节点的prev节点,直到index+1的位置时,就跳出循环了,而index+1节点的prev节点不正是我们要获取的index节点么?完美!
03.删除元素
(1).get(index)方法
既然是二哈属性,总有惹媳妇生气的时候,不好的回忆还是适当删除吧!
示例代码:
public static void main(String[] args) {
LinkedList<String> loveStory=new LinkedList<String>();
loveStory.add("看电影");
loveStory.add("去野餐");
loveStory.add("摩天轮");
loveStory.add("惹老婆生气");
loveStory.add("去海边");
loveStory.get(2);
}
我们来分析这一行代码:
loveStory.remove(2);
分析如下:
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
#2 checkElementIndex;:角标是否越界的检查。
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
#3 unlink(node(index));:先遍历找到index对应的Node节点,然后进行删除工作。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
#3~#5:获取index对应的Node节点的prev节点和next节点;
#7~#12:如果prev节点为null,就把Node节点的next节点设置为first节点;
否则就将prev节点的next节点设置为Node节点的next节点。
#14~#19:如果next节点为null,就把Node节点的prev节点设置为last节点;
否则就将next节点的prev节点设置为Node节点的prev节点。
#21~#24:将node节点的值设置为null,size-1,最终返回原来Node的元素值。
还记得前文说的爱情绳子理论吧,这里我们只要是换成缩短绳子,剪开,接上的过程就是删除指定位置Node的过程。
如果生活有烦恼,就把烦恼给删掉,把生活接上去继续幸福。
3).对比总结
(1)ArrayList:一般场景,都是用ArrayList来代表一个集合,不适合频繁的往里面插入和灌入大量的元素遍历,或者随机查,性能都很好。
(2)LinkedList:适合,频繁的在list中插入和删除某个元素,然后尤其是LinkedList他其实是可以当做队列来用的,先进先出,在list尾部怼进去一个元素,从头部拿出来一个元素。在内存里实现一个基本的队列的话,可以用LinkedList。
生活中的美好,从一行代码的运行开始,从朝夕相伴的爱情开始。
最后谢谢大家阅读,有不足之处欢迎指出。