项目要点
- 10-monkey-species,是十个种类的猴子的图像集。
- txt 文件读取: labels = pd.read_csv( './monkey_labels.txt' , header= 0)
- 训练数据 图片数据增强: # 图片数据生成器
# 图片数据生成器
train_datagen = keras.preprocessing.image.ImageDataGenerator(rescale = 1.0/ 255,
rotation_range= 40,
width_shift_range= 0.2,
height_shift_range= 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
vertical_flip= True,
fill_mode= 'nearest')- 训练数据读取 并统一尺寸:
train_generator = train_datagen.flow_from_directory(train_dir,
target_size= (height, width),
batch_size = batch_size,
shuffle= True,
seed = 7,
class_mode = 'categorical')- valid_dategen = keras.preprocessing.image.ImageDataGenerator(rescale = 1. / 255) # 目标数据转换
- 目标数据读取 并转换尺寸:
valid_generator = valid_dategen.flow_from_directory(valid_dir,
target_size= (height, width),
batch_size = batch_size,
shuffle= True,
seed = 7,
class_mode = 'categorical')- 创建模型:
- model = keras.models.Sequential()
- model.add(keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same', activation = 'relu', input_shape = (128, 128, 3))) # 添加输入层
- model.add(keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same', activation = 'relu')) # 添加卷积层
- model.add(keras.layers.MaxPool2D()) # 添加池化层
- 维度转换: model.add(keras.layers.Flatten())
- 添加卷积层: model.add(keras.layers.Dense(32, activation = 'relu'))
- 添加输出层; model.add(keras.layers.Dense(10, activation = 'softmax'))
- 配置模型:
model.compile(loss = 'categorical_crossentropy', # 独热编码, 所以不用sparse
optimizer = 'adam',
metrics = 'accuracy')- 查看模型: model.summary()
- 模型训练:
histroy = model.fit(train_generator,
steps_per_epoch= train_num // batch_size,
epochs = 10,
validation_data = valid_generator,
validation_steps= valid_num // batch_size)一 10-monkey-species
10-monkey-species 数据集是一个10类不同品种猴子的数据集,这个数据集是从 kaggle 平台中下载到本地使用的。
1.1 导包
import tensorflow as tf
from tensorflow import keras
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
cpu=tf.config.list_physical_devices("CPU")
tf.config.set_visible_devices(cpu)
print(tf.config.list_logical_devices())1.2 数据导入
train_dir = './training/training/'
valid_dir = './validation/validation/'
label_file = './monkey_labels.txt'
labels = pd.read_csv(label_file, header= 0)
labels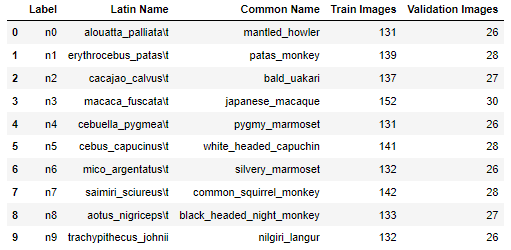
# 图片数据生成器
train_datagen = keras.preprocessing.image.ImageDataGenerator(rescale = 1.0/ 255,
rotation_range= 40,
width_shift_range= 0.2,
height_shift_range= 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
vertical_flip= True,
fill_mode= 'nearest')
height = 128
width = 128
channels = 3
batch_size = 32
num_classes = 10
train_generator = train_datagen.flow_from_directory(train_dir,
target_size= (height, width),
batch_size = batch_size,
shuffle= True,
seed = 7,
class_mode = 'categorical')
valid_dategen = keras.preprocessing.image.ImageDataGenerator(rescale = 1. / 255)
valid_generator = valid_dategen.flow_from_directory(valid_dir,
target_size= (height, width),
batch_size = batch_size,
shuffle= True,
seed = 7,
class_mode = 'categorical')
print(train_generator.samples) # 1098
print(valid_generator.samples) # 2721.3 创建模型
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters = 32, # 卷积
kernel_size = 3,
padding = 'same',
activation = 'relu',
input_shape = (128, 128, 3))) # 128, 128, 3
model.add(keras.layers.Conv2D(filters = 32,
kernel_size = 3,
padding = 'same',
activation = 'relu'))
model.add(keras.layers.MaxPool2D()) # 池化
model.add(keras.layers.Conv2D(filters = 64, # 卷积
kernel_size = 3,
padding = 'same',
activation = 'relu'))
model.add(keras.layers.Conv2D(filters = 64,
kernel_size = 3,
padding = 'same',
activation = 'relu'))
model.add(keras.layers.MaxPool2D()) # 池化
model.add(keras.layers.Conv2D(filters = 128, # 卷积
kernel_size = 3,
padding = 'same',
activation = 'relu'))
model.add(keras.layers.Conv2D(filters = 128,
kernel_size = 3,
padding = 'same',
activation = 'relu'))
model.add(keras.layers.MaxPool2D()) # 池化
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(32, activation = 'relu'))
model.add(keras.layers.Dense(32, activation = 'relu'))
model.add(keras.layers.Dense(10, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', # 独热编码, 所以不用sparse
optimizer = 'adam',
metrics = 'accuracy')
model.summary()
1.4 模型训练
train_num = train_generator.samples
valid_num = valid_generator.samples
print(train_num, valid_num, batch_size) # 1098, 272, 32histroy = model.fit(train_generator,
steps_per_epoch= train_num // batch_size,
epochs = 10,
validation_data = valid_generator,
validation_steps= valid_num // batch_size)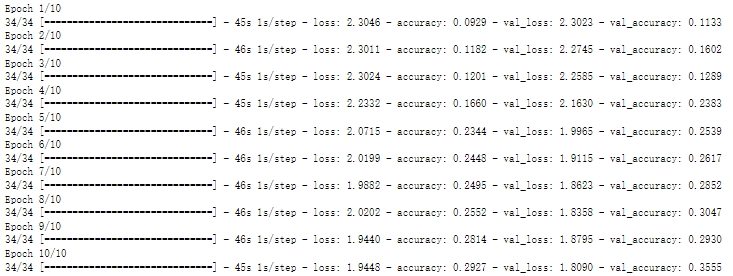
二 VGG 模型分类
# 函数式写法 # M:池化
cfgs = {'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']}def make_feature(cfg):
feature_layers = []
for v in cfg:
if v == 'M':
feature_layers.append(keras.layers.MaxPool2D(pool_size = 2, strides = 2))
else:
feature_layers.append(keras.layers.Conv2D(v, kernel_size = 3,
padding = 'SAME',
activation = 'relu'))
return keras.Sequential(feature_layers, name = 'feature') # 整体当做一层# 定义网络结构
def VGG(feature, im_height = 224, im_width = 224, num_classes = 1000):
input_image = keras.layers.Input(shape = (im_height, im_width, 3), dtype = 'float32')
x = feature(input_image)
x = keras.layers.Flatten()(x) # 将flatten当做一个函数
# dropout, 防止过拟合, 每次放弃部分参数
x = keras.layers.Dropout(rate = 0.5)(x)
# 原论文为4096
x = keras.layers.Dense(512, activation = 'relu')(x)
x = keras.layers.Dropout(rate = 0.5)(x)
x = keras.layers.Dense(512, activation = 'relu')(x)
x = keras.layers.Dense(num_classes)(x)
output = keras.layers.Softmax()(x)
model = keras.models.Model(inputs = input_image, outputs = output)
return model# 定义网络模型
def vgg(model_name = 'vgg16', im_height = 224, im_width = 224, num_classes = 1000):
cfg = cfgs[model_name]
model = VGG(make_feature(cfg), im_height = im_height, im_width= im_width, num_classes= num_classes)
return model
vgg16 = vgg(num_classes = 10)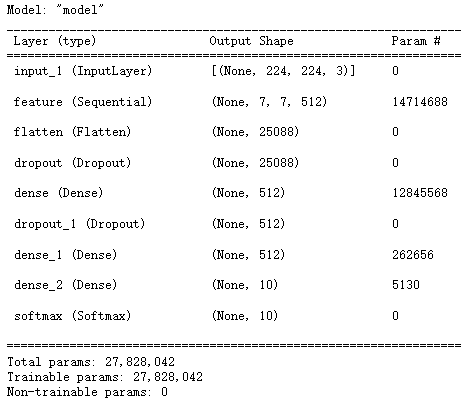
vgg16.compile(optimizer = 'adam', # optimizer 优化器, 防止过拟合
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
histroy = vgg16.fit(train_generator,
steps_per_epoch= train_generator.samples // batch_size,
epochs = 10,
validation_data= valid_generator,
validation_steps= valid_generator.samples // batch_size)
三 Alexnet 模型分类
# 函数式写法
def AlexNet(im_height=224, im_width=224, num_classes=1000):
# 输入层
input_image = keras.layers.Input(shape =(im_height, im_width, 3), dtype = tf.float32)
# 手动实现padding, 周边补零填充
x = keras.layers.ZeroPadding2D(((1, 2), (1, 2)))(input_image)
# 卷积
x = keras.layers.Conv2D(48, kernel_size = 11, strides = 4, activation = 'relu')(x)
# 池化
x = keras.layers.MaxPool2D(pool_size = 3, strides = 2)(x)
# 第二层卷积
x = keras.layers.Conv2D(128, kernel_size = 5, padding = 'same', activation = 'relu')(x)
# 池化
x = keras.layers.MaxPool2D(pool_size = 3, strides = 2)(x)
# 卷积
x = keras.layers.Conv2D(192, kernel_size = 3, padding = 'same', activation = 'relu')(x)
x = keras.layers.Conv2D(192, kernel_size = 3, padding = 'same', activation = 'relu')(x)
x = keras.layers.Conv2D(128, kernel_size = 3, padding = 'same', activation = 'relu')(x)
# 池化 pool_size
x = keras.layers.MaxPool2D(pool_size = 3, strides = 2)(x)
# 传链接
x = keras.layers.Flatten()(x)
# 加dropout
x = keras.layers.Dropout(0.2)(x)
x = keras.layers.Dense(2048, activation = 'relu')(x)
x = keras.layers.Dropout(0.2)(x)
x = keras.layers.Dense(2048, activation = 'relu')(x)
# 输出层
x = keras.layers.Dense(num_classes)(x)
# 预测
predict = keras.layers.Softmax()(x)
model = keras.models.Model(inputs = input_image, outputs = predict)
return model
model = AlexNet(im_height= 224, im_width= 224, num_classes= 10)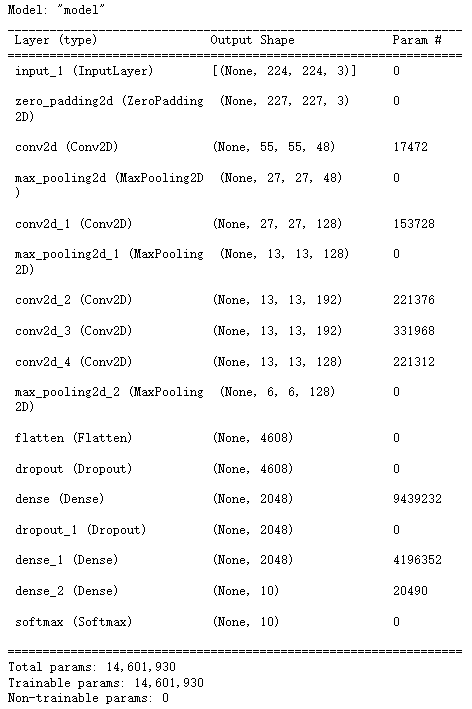
model.compile(optimizer = 'adam', # optimizer 优化器, 防止过拟合
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
histroy = model.fit(train_generator,
steps_per_epoch= train_generator.samples // batch_size,
epochs = 10,
validation_data= valid_generator,
validation_steps= valid_generator.samples // batch_size)
![[Java代码审计]—OFCMS](https://img-blog.csdnimg.cn/c360357cdcd948ec9e1f1c6602b4de19.png#pic_center)