内存(Memory)是计算机中最重要的部件之一,计算机运时的程序以及数据都依赖它进行存储。内存主要分为随机存储器(RAM),只读存储器(ROM)以及高速缓存(Cache)。
仅仅雷达的原始回波数据(Radar data cube)就可能达MByte级别的数据体量,这对MCU的内存来说尺寸很大。本篇文章主要介绍了在雷达嵌入式编程中会遇到的MPU(Memory Protect Unit)、Cache以及不同数据格式在内存中的存储格式和雷达基带涉及的加速核与内存区的映射。总而言之,与内存相关的嵌入式编程以及优化方式会在本文中对其进行说明,并从内存优化的角度对可以应用的诸如 同址复用等思路进行说明。 👻
MPU+Cache
Cache一致性问题一般发生在多核处理器上,单核处理器基本不用考虑这个问题。
现在的处理器一般都有两级(L1cache,L2cache)甚至三级缓存,当核0读写外部存储器如DDR内的数据时,会将数据保存在L2cache和L1Dcache中。后续如果该数据一直在cache中,那么对该数据的读写都会直接操作cache内的数据,而不会去修改DDR中的数据。以此提高CPU的读写速度。但是这可能导致其他主机(如其他核)读取DDR的数据与核0中cache中的数据不一致。例如核0已经将位于DDR中的变量num从11修改为56了,但是其他核读取num时,依然有可能读取到的是11。最新的num数据56可能依旧在核0的cache中,没有写回到DDR中。一般来说,多级缓存之间的一致性不需要我们来维护,我们主要维护不同核之间的数据一致。
// ...
// recieve data from DMA or HW peripheral
// addr = cache line aligned buffer address
// size = multiple of cache line aligned size in bytes
// invalidate contents of cache so that a CPU can see the data written by DMA or HW peripheral
CacheP_inv(addr, size, CacheP_TYPE_ALL);上面的代码为将对应地址空间执行了Writeback-Invalidate操作,其的作用是将Cache写回到DDR中,之后Cache中的数据将会无效。这种操作多用于读取核间共享的存储区域之前。除了Writeback-Invalidate操作,还有Invalidate(将CACHE中的数据视为无效数据)以及Writeback(将CACHE中的数据写回存储器中如DDR)等操作。
MPU定义了存储器不同地址空间的属性和存储器的访问权限。MPU不会提升嵌入式应用的性能,而是用于系统中问题的检测(比如试图访问非法或者不允许的存储器位置所导致的应用错误)。如果检测到有错误,则会触发HardFault异常。实际上,许多微控制器用不到MPU,但MPU可以提高嵌入式系统的健壮性,使得系统更加安全。
/** MPU Region Base Address Register Value
*
* \param Region The region to be configured, number 0 to 15.
* \param BaseAddress The base address for the region.
*/
#define ARM_MPU_RBAR(Region, BaseAddress) \
(((BaseAddress) & MPU_RBAR_ADDR_Msk) | \
((Region) & MPU_RBAR_REGION_Msk) | \
(MPU_RBAR_VALID_Msk))
#define ARM_MPU_RASR_EX(DisableExec, AccessPermission, AccessAttributes, SubRegionDisable, Size) \
((((DisableExec) << MPU_RASR_XN_Pos) & MPU_RASR_XN_Msk) | \
(((AccessPermission) << MPU_RASR_AP_Pos) & MPU_RASR_AP_Msk) | \
(((AccessAttributes) & (MPU_RASR_TEX_Msk | MPU_RASR_S_Msk | MPU_RASR_C_Msk | MPU_RASR_B_Msk))) | \
(((SubRegionDisable) << MPU_RASR_SRD_Pos) & MPU_RASR_SRD_Msk) | \
(((Size) << MPU_RASR_SIZE_Pos) & MPU_RASR_SIZE_Msk) | \
(((MPU_RASR_ENABLE_Msk))))
/**
* MPU Region Attribute and Size Register Value
*
* \param DisableExec Instruction access disable bit, 1= disable instruction fetches.
* \param AccessPermission Data access permissions, allows you to configure read/write access for User and Privileged mode.
* \param TypeExtField Type extension field, allows you to configure memory access type, for example strongly ordered, peripheral.
* \param IsShareable Region is shareable between multiple bus masters.
* \param IsCacheable Region is cacheable, i.e. its value may be kept in cache.
* \param IsBufferable Region is bufferable, i.e. using write-back caching. Cacheable but non-bufferable regions use write-through policy.
* \param SubRegionDisable Sub-region disable field.
* \param Size Region size of the region to be configured, for example 4K, 8K.
*/
#define ARM_MPU_RASR(DisableExec, AccessPermission, TypeExtField, IsShareable, IsCacheable, IsBufferable, SubRegionDisable, Size) \
ARM_MPU_RASR_EX(DisableExec, AccessPermission, ARM_MPU_ACCESS_(TypeExtField, IsShareable, IsCacheable, IsBufferable), SubRegionDisable, Size)
/* Region 3 setting: Memory with Device type, not shareable, non-cacheable */
MPU->RBAR = ARM_MPU_RBAR(3, 0x31C00000U); //0x30000000U
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 2, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_32MB);
上述代码将0x31C00000为起点的32MB数据区域设置为了non-cacheable(意味着所有observers都可以观察该内存的实际值),not shareable(如果被多个observer使用Non-shareable内存,无序的读写的操作顺序会导致异常)。当然,在设置MPU regions时,建议将cache与MPU失能,配置完成之后再使能。
Data representation
在基带模块中主要涉及的数据类型如下:
定点实数/复数
浮点复数
伪浮点复数
定点实数/复数
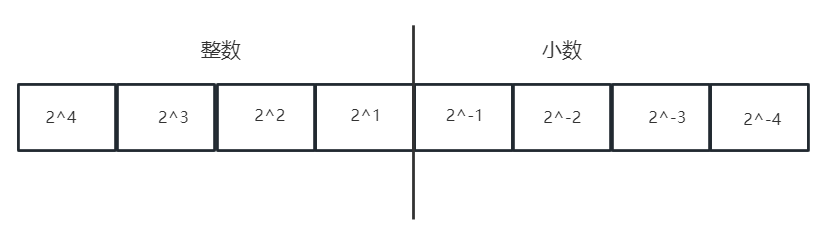
下图是一个8位定点实数的Bit图,高四位是整数,第四位是小数。实数1.5对应表示为00011000。
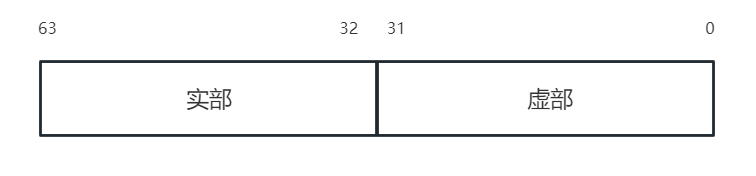
定点的复数如下图为高32位为实部,低32位为虚部。0-12bit位为虚部的小数部分,13-31bit为虚部的整数部分。32-44bit为实部小数部分,45-63bit为实部的整数部分。
浮点复数
如下图所示,浮点复数的实部和虚部是由两个符合IEEE754标准的单精度短浮点数的标准的32位数表示。
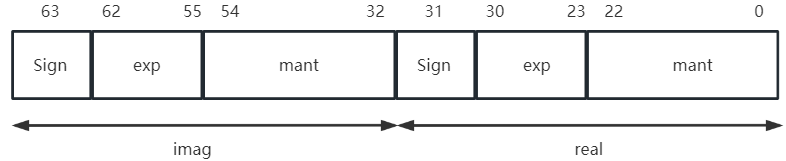
单精度短浮点数的由1位符号位,8位指数位和23位有效数字位构成。实际上有效数字位是24位,因为第一位有效数字总是“1”,不必存储。有效数字位是一个二进制纯小数。8位指数位中第一位是符号位,这符号位和一般的符号位不同,它用“1”代表正,用”0“代表负。整个单精度短浮点数的符号位用“1”代表负,“0”代表正。指数位为正代表有效数字位需要右移指数+1,为负则代表需要左翼左移指数按位取反。距离举个转换的例子:
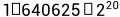 =
=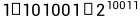 =
=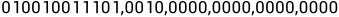
伪浮点复数
伪浮点复数这种数据存储格式能够有效的减少内存压力,它将需要64位存储的浮点复数用32位来存储。结构如下:

实部和虚部都以14位数表示,他们的浮点位置由高4位计算得出。复数的实数部分数值=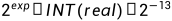 ,复数的虚数部分数值=
,复数的虚数部分数值=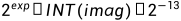 。下面举个例子,复数-7+4i在内存中以伪浮点复数存储为0x34002400。
。下面举个例子,复数-7+4i在内存中以伪浮点复数存储为0x34002400。
Memory Map
雷达的MCU一般都是多核的,成本高一点的会是多个ARM核与DSP核,成本低一点的也会有ARM核与各种加速核。这些核心都有对RAM进行读写的需要。我们针对低成本芯片集成电路蓝本,大约简化以下几个主体。
Bus Master:ARM核,我们编写的代码就是跑在这个核心。
PREP:主要用于原始的AD回波数据的存储组织。
BB_DMA:Direct Memory Access.它可以解放核心,提供内存间拷贝的功能。也可以为诸如FFT这种核心提供内存块数据的逐条/个数据的读取等操作。
P1:提供在距离维之前的数据处理功能,包括幅相等校准与Zeros的工作。
P2:提供在速度维之前的数据处理工作,包括复数的累加求信号均值等操作。
FFT:提供快速傅里叶变化算法实现。
CFAR:提供各种恒虚警算法实现。
我们把RAM分为两部分,BUF1和BUF2,BUF1存储包括FFT的原始与结果数据,BUF2存储一些窗口数据。MCU中的每个核心都对RAM有不同位宽的读写需求,核心直接也有相互写入的需求。我们把数据想象成水流,而各个加速核想象成水处理池,而我们嵌入式工程师就像是水管工,将核心根据需要用RAM中的数据连接起来,来搭建一个信号处理流程。下表是这些核心与RAM不同位宽的读写关系图(纵向表头为请求方,表格中的读写是请求方的读写,横向为响应方)。
P1_ZO | P1_MUL | FFT | P2 | CFAR | BUF1 | BUF2 | |
BUS Master | 32/64读/写 | 32/64读/写 | |||||
BB_DMA | 16写 | 32写 | 32写 | 8/16/32/64读 8/16/32写 | 8/16/32/64读 8/16/32写 | ||
PREP | 64写 | ||||||
P1 | 32写 | 32写 | |||||
FFT | 32写 | 16/32读 32写 | |||||
P2 | 32写 | 32读 32写 | 32读 32写 | ||||
CFAR | 32读 64写 |
BUF1可以根据存储的数据种类进一步划分,比如可以划分为存储AD回波数据的区域,存储距离维FFT结果数据区,速度维FFT结果数据,这么存储可以进行更好的调试信号处理调试以及更灵活的信号处理流程搭建,但是一旦流程固定之后,我们完全可以将一些数据区域复用,比如ADC_SAMPLE_ADDR与FFT1D_CACHE_ADDR可以指向一个地址,这样处理可以大大减少对内存空间的压力。
除了上述的可供ARM核心读写的BUF1+BUF2内存区域(我们称之为原始数据区),具有加速核的雷达SOC还有一些"影子RAM",这么称呼是因为他们仿佛是原始数据区域的影子一样,这些区域ARM核心并不能直接写,但是可以读,每当我们向原始数据区写入的后,不同的影子RAM会自动写入对应原始数据经过一种固定运算或者更改存储格式后的数据.
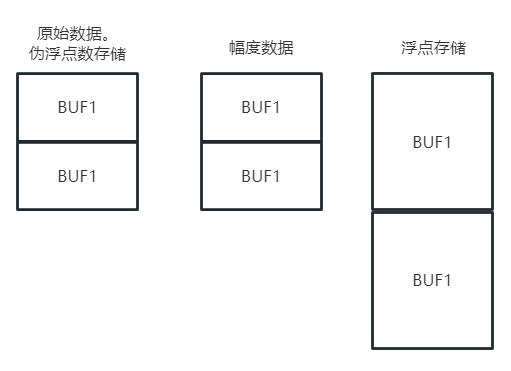
正如上图,第一个影子RAM是对应原始复数数据经过i.e.abs,log2,log运算之后的幅度实数数据,CFAR加速核进行相应算法的原始数据就来自这里。第二个影子RAM是对应以伪浮点数存储的原始数据以符合IEEE754标准的浮点数进行存储,P1/2的涉及的一些复数运算来源于这里。
十六宿舍 原创作品,转载必须标注原文链接。
©2023 Yang Li. All rights reserved.
欢迎关注 『十六宿舍』 ,大家喜欢的话,给个 👍 ,更多关于嵌入式相关技术的内容持续更新中。


![buu [NPUCTF2020]这是什么觅 1](https://img-blog.csdnimg.cn/dfc1504fa71c49ef89878dbd9de4176c.png)