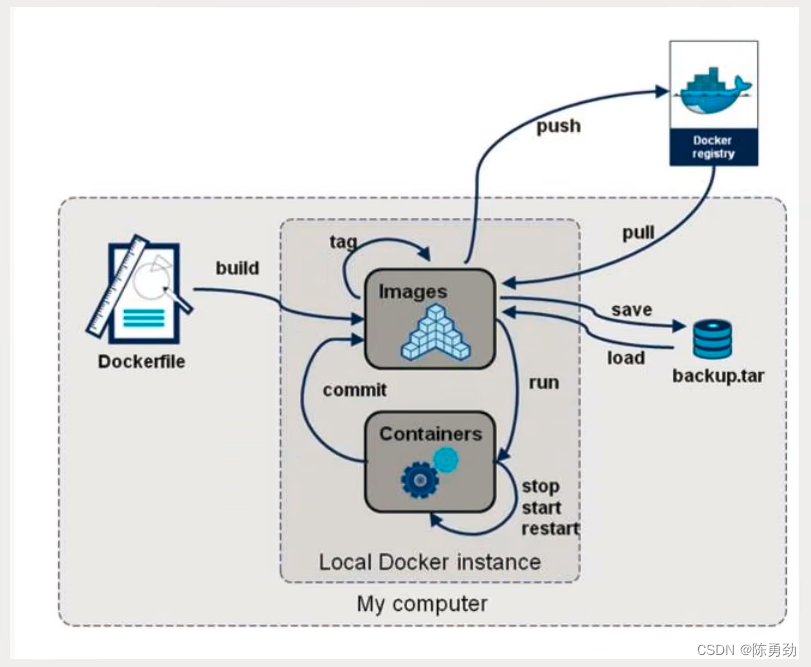
为什么要使用Nosql
现在是大数据时代,过大的数据一般的数据库无法进行分析处理了。
- 单机MySQL的年代

90年代,一个基本的网站访问量一般不会太大,单个数据库完全足够!
那个时候,更多的去使用静态网站,服务器没有太大的压力
这种情况下,整个网站的瓶颈是什么?
- 数据量如果太大,一个机器放不下了
- 数据的索引 (单表超过300万就一定要建索引),一个机器内存也放不下
- 访问量(读写混合),一个服务器承受不了
- Memcached(缓存)+ MySQL + 垂直拆分(读写分离)
网站80%的情况下都是在读,如果每次都是查询数据库则效率太低。所以来使用缓存来保证效率。
发展过程:优化数据结构和索引 => 文件缓存(IO)=> Memcached(当时最热门的技术)
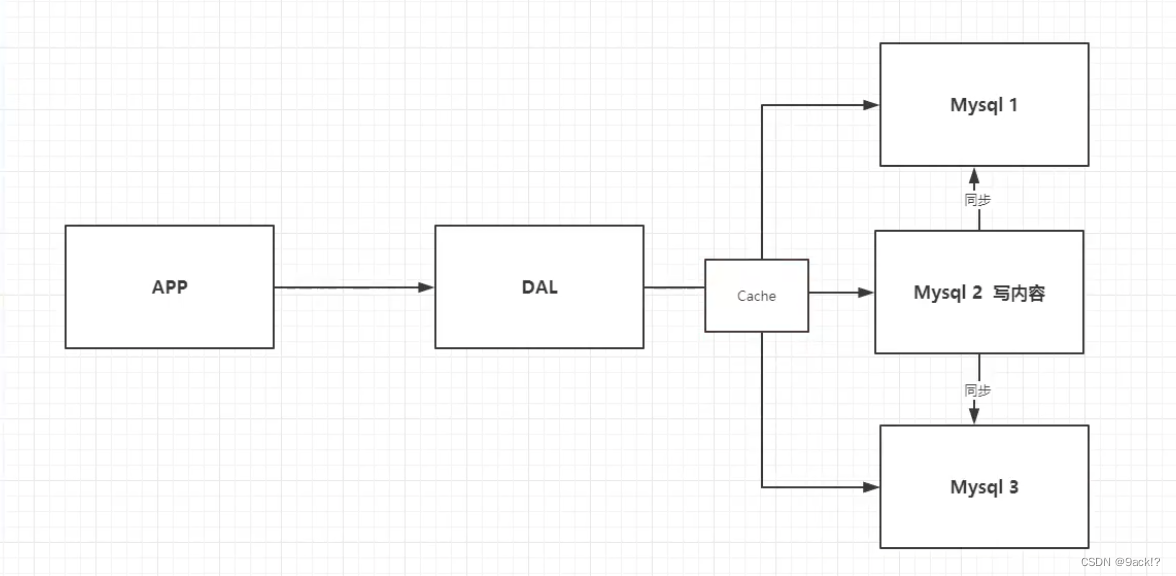
图中只有服务器 Mysql2 用来写,其他服务器都只负责读,其他服务器去同步 Mysql2 中的内容
- 分库分表 + 水平拆分(集群)
慢慢使用分库分表来解决写的压力。
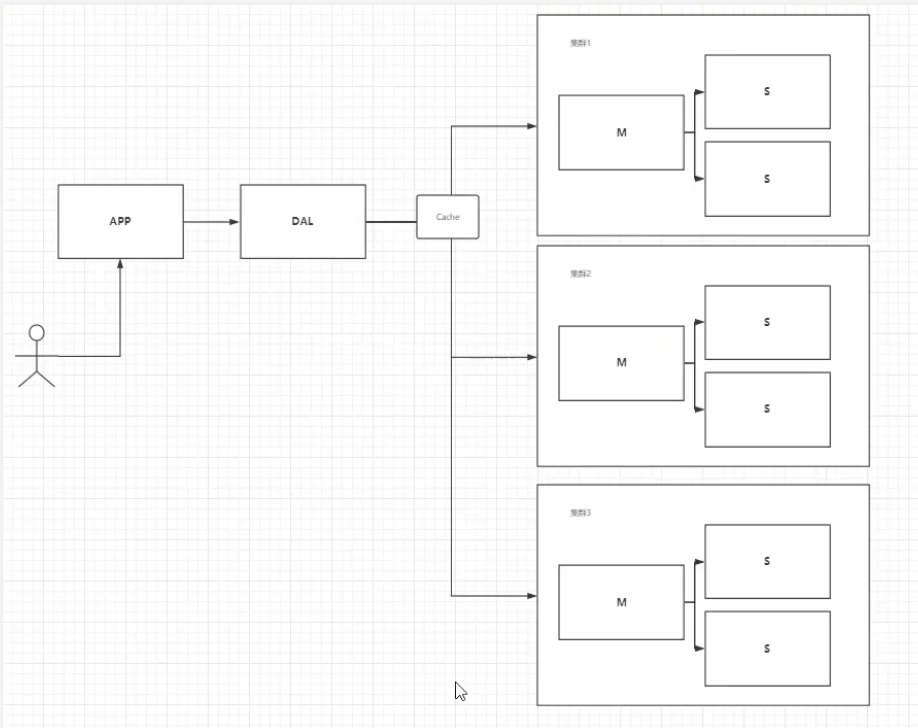
每个集群只存三分之一的用户数据。
- 最近年代
数据量多,变化快。关系型数据库就不够用了。
MySQL当存一些比较大的文件,博客,图片的时候,数据库表会很大,效率就低了。如果有一种数据库来专门处理这种数据,MySQL的压力就变小了。大数据的IO压力下,表几乎没法更改。
目前的一个基本的互联网项目
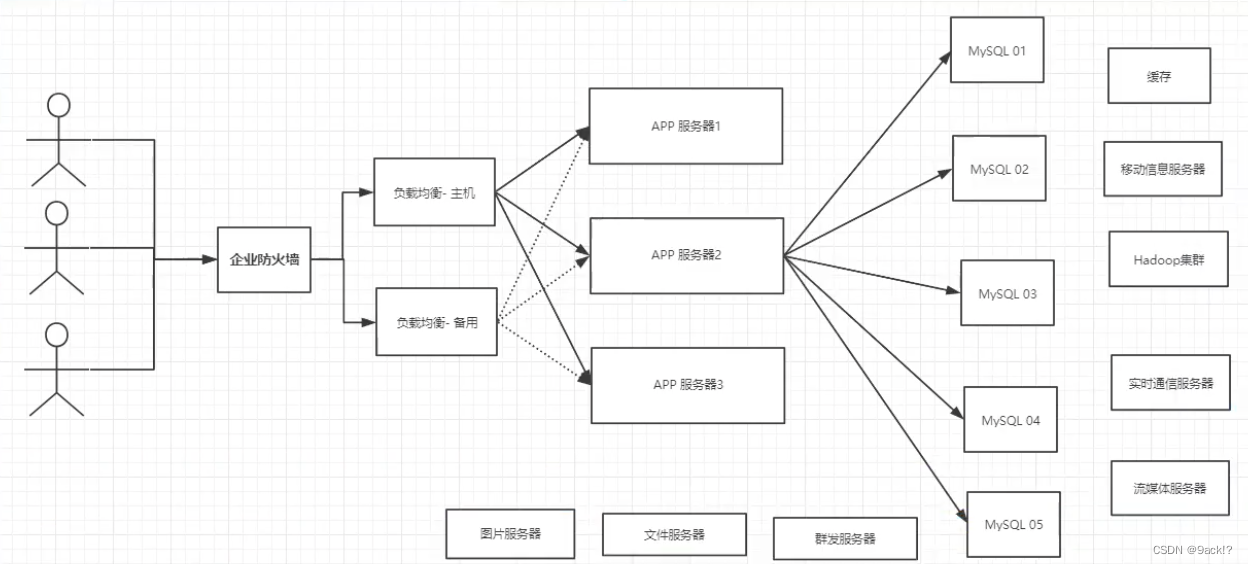
为什么要用NoSQL
用户的个人信息,社交网络,地理位置。用户自己产生的数据,用户的日志等等,爆发式增长。
这个时候我们就需要使用NoSQL数据库了,NoSQL可以很好的处理以上的情况。
什么是NoSQL
NoSQL = Not Only SQL
泛指非关系型数据库,随着web2.0互联网的诞生,传统的关系型数据库很难对付了。尤其是超大规模的高并发社区。NoSQL在当今大数据环境下发展的十分迅速,其中Redis是发展最快的。
用户的个人信息,社交网络,地理位置。这些的数据的存储不需要一个固定的格式,不需要多余的操作就可以横向扩展(集群)。
NoSQL特点
-
方便扩展(数据之间没有关系,很好扩展)
-
大数据量高性能(Redis 一秒可以写8万次,读取11万次,NoSQL的缓存记录级,是一种细粒度的缓存,性能比较高)
-
数据类型是多样性的(不需要实现设计数据库,随取随用)
-
传统的RDBMS和NoSQL
传统的RDBMS
- 结构化组织
- SQL
- 数据和关系都存在单独的表中
- 数据操作,定义语言
- 严格的一致性
- 基础的事务
- …
NoSQL
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性
- CAP定理 和 BASE理论(异地多活)
- 高性能,高可用,高可扩展性
- …
了解: 3V+3高
3V:主要是描述问题的
- 海量 Volume
- 多样 Variety
- 实时 Velocity
3高:主要是对程序的要求
- 高并发
- 高可扩(随时水平拆分,机器不够的时候,随时可以加一台服务器)
- 高性能(保证用户体验和性能)
在公司中一定是:NoSQL + RDBMS 一起使用
NoSQL的四大分类
KV键值对:
- 新浪:Redis
- 美团:Redis + Tair
- 阿里、百度:Redis + memcache
文档型(bson格式):
- MongoDB(一般必须要掌握)
- MongoDB是一个基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档
- MongoDB是一个介于关系型数据库和非关系型数据库的中间的产品。MongoDB是非关系型数据库中功能最丰富,最像关系型数据库的。
- ConthDB
列存储数据库:
- HBase
- 分布式文件系统
图关系数据库
- 存放的是关系,比如社交网络,推荐系统
- Neo4j,InfoGrid
四者之间关系。