目录
- Join
- Join的分类
- 笛卡尔积
- 笛卡尔积出现的原因
- 为什么不推荐有笛卡尔积出现
- 那应该怎么做多表连接
- Join的使用
- 小表驱动大表
- 小表驱动大表是什么
- 小表驱动大表的好处
- 如何区分哪一个是驱动表和被驱动表
- Join原理及算法
- NLJ算法
- BNLJ算法
- 总结:如何写入高性能的连接查询
- 为什么MySQL不推荐使用Join
- 那有什么可以替代Join的方案
Join
首先我们先抛出一个问题,为什么要使用Join?
Join可以将我们数据库中的两张或者两张以上的表进行连接操作,并且使用Join做关联查询的好处是可以做分页。
Join的分类
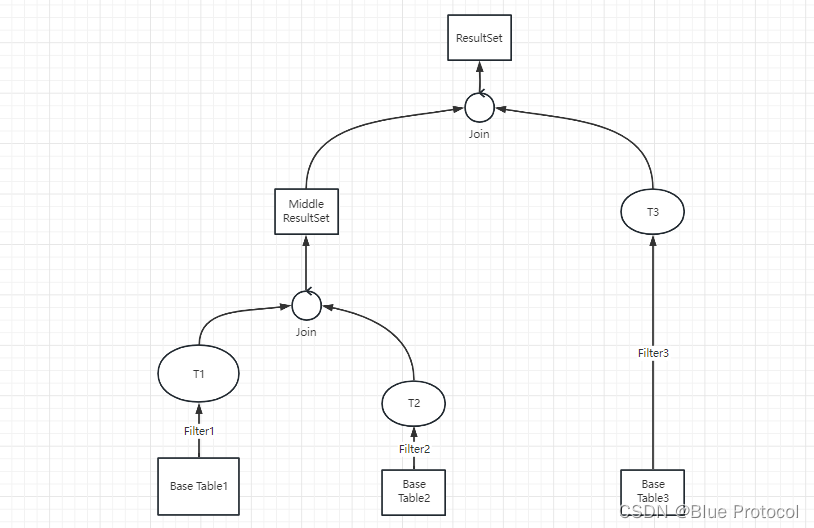
Join的分类我们可以具体看下面这张图片。
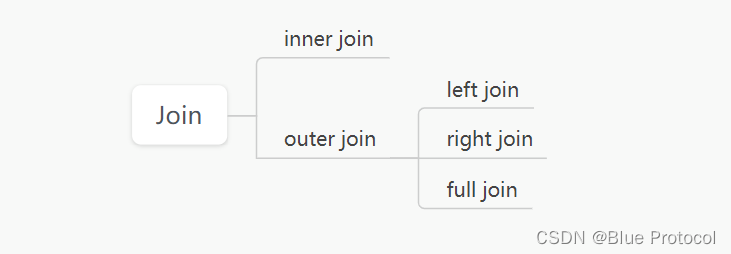
具体分类说明看下文。
笛卡尔积
笛卡尔积是我们多表联合查询的时候会出现的一种现象。我们来举个例子来简单理解笛卡尔积。
假设集合A={a, b}有两个元素,集合B={0, 1, 2}有三个元素,则两个集合的笛卡尔积为
{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)},有2*3为6个元素。
笛卡尔积出现的原因
- 如果数据库表关联查询时,只是纯粹的进行表连接没有使用其他条件,会出现全部的笛卡尔积。
- 数据库表关联查询,如果ON条件是非唯一字段,则会出现局部笛卡尔积。
- 数据库表关联查询,如果ON条件是表的唯一字段,则不会出现笛卡尔积。
为什么不推荐有笛卡尔积出现
- 笛卡尔积没有什么实践意义。在实际应用中,笛卡尔积本身大多没有什么实际用处,只有在两个表连接时加上限制条件,才会有实际意义。
- 多个大数据量的表产生的笛卡尔积表会占用很大的内存空间。
那应该怎么做多表连接
我们在进行表连接查询的时候一般都会使用JOIN xxx ON xxx的语法,ON语句的执行是在JOIN语句之前的,也就是说两张表数据行之间进行匹配的时候,会先判断数据行是否符合ON语句后面的条件,再决定是否JOIN。
(因此,有一个显而易见的SQL优化的方案是,当两张表的数据量比较大,又需要连接查询时,应该使用 FROM table1 JOIN table2 ON xxx的语法,避免使用 FROM table1,table2 WHERE xxx 的语法,因为后者会在内存中先生成一张数据量比较大的笛卡尔积表,增加了内存的开销。)
Join的使用
Join的分类
- 内联接(Inner Join):内连接查询返回满足条件的所有记录,如果没有指定是left还是right 仅仅只有一个join也是inner join。
- 左联接(Left Join):除了匹配2张表中相关联的记录外,还会匹配左表中剩余的记录,右表中未匹配到的字段用NULL表示。
- 右外联接(Right Join):除了匹配2张表中相关联的记录外,还会匹配右表中剩余的记录,左表中未匹配到的字段用NULL表示。
小表驱动大表
说到连接,我们经常会听到的规则是小表驱动大表。
小表驱动大表是什么
小表驱动大表指的是用小数据集的来驱动大数据集。
小表驱动大表的好处
我们可以使用两个循环来理解小表驱动大表,例如:现有两个表A与B ,表A有200条数据,表B有20万条数据
小表驱动大表 : A驱动表,B被驱动表
for(200条){
for(20万条){
...
}
}
大表驱动小表 : B驱动表,A被驱动表
for(20万){
for(200条){
...
}
}
看以上两个for循环,总共循环的次数是一样的。但是对于MySQL数据库而言,并不是这样了,我们尽量选择第1个for循环,也就是小表驱动大表。
数据库连接的建立,第一个建立了200条次链接,第二个建立了20万次链接。假设链接了两次,每次做上百万次的数据集查询,查完就走,这样就只做了两次;相反建立了上百万次链接,申请链接释放反复重复,这样系统就受不了了。
综上,小表驱动大表的好处是
- 通过减少创建连接的次数,来加快查询速度。
- 驱动表索引没有生效,被驱动表索引有效 。检索大表的时候可以使用索引,B+树查找时间复杂度是logn,所以小驱大大概的时间200log2000000,当然比2000000log200快很多
如何区分哪一个是驱动表和被驱动表
1)通过EXPLAIN查看SQL语句的执行计划可以判断在谁是驱动表,EXPLAIN语句分析出来的第一行的表即是驱动表 ;
2)在JOIN查询中经常用到的 inner join、left join、right join
(1)当使用left join时,左表是驱动表,右表是被驱动表 ;
(2)当使用right join时,右表时驱动表,左表是被驱动表 ;
(3)当使用inner join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表 ;
测试环境配置:MYSQL 5.7
数据准备:创建两张测试表 大表 user_big_info ,测试数据400万条, 小表user_small_info ,测试数据200万条 ;
CREATE TABLE `user_small_info` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` varchar(32) NOT NULL COMMENT '用户唯一标识',
`username` varchar(32) NOT NULL DEFAULT '' COMMENT '用户名',
`password` varchar(255) NOT NULL DEFAULT '' COMMENT '密码',
`real_name` varchar(32) NOT NULL DEFAULT '' COMMENT '真实姓名',
`phone` varchar(32) NOT NULL DEFAULT '' COMMENT '手机号码',
`remarks` varchar(255) NOT NULL DEFAULT '' COMMENT '备注',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '状态 1-启用 2-禁用 ',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_user_id` (`user_id`) USING BTREE,
KEY `idx_username` (`username`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3000001 DEFAULT CHARSET=utf8 COMMENT='用户表';
LEFT JOIN 测试:小表驱动大表

结果:
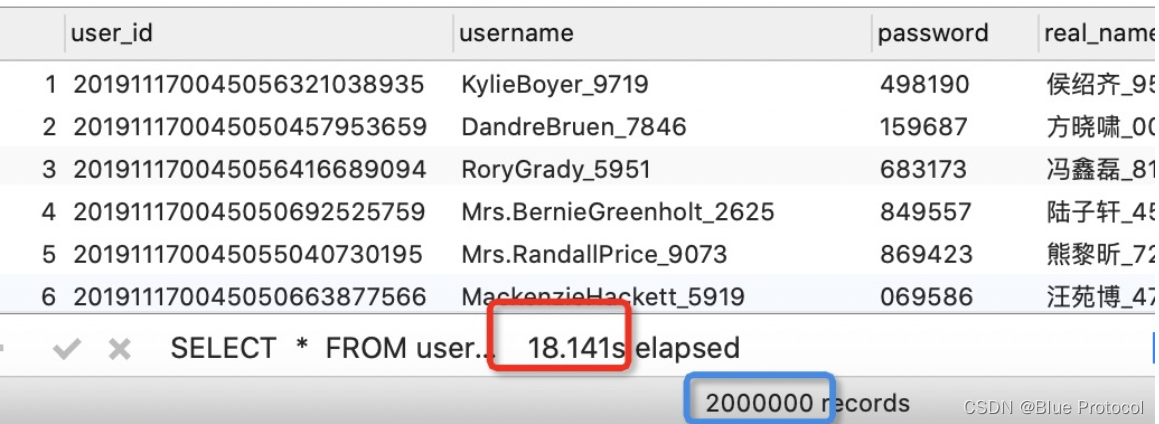
执行时间:18.141s ,由于使用左连接以小表为主表所以,返回行数:200万。
执行计划

LEFT JOIN 测试:大表驱动小表

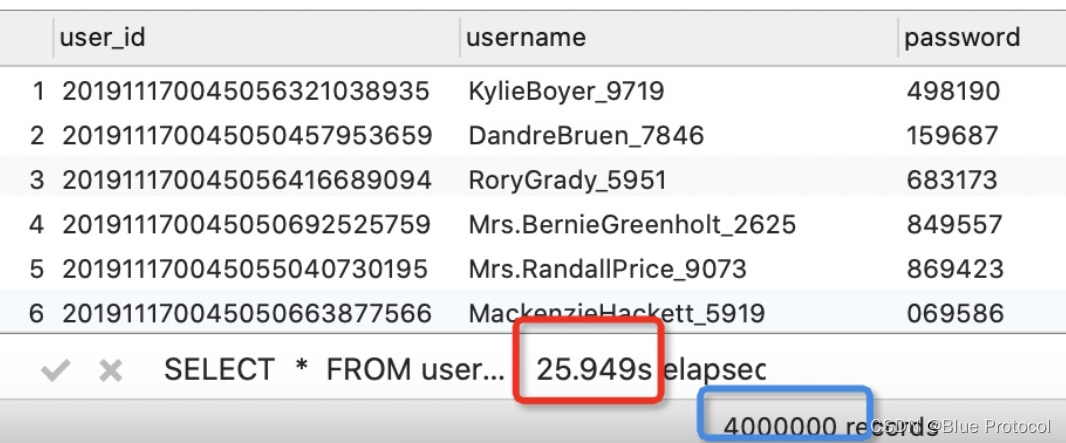
执行时间:25.949s ,由于使用左连接以大表为主表所以,返回行数: 400万
执行计划

Join原理及算法
我们在进行表连接查询的时候一般都会使用JOIN xxx ON xxx的语法,ON语句的执行是在JOIN语句之前的,也就是说两张表数据行之间进行匹配的时候,会先判断数据行是否符合ON语句后面的条件,再决定是否JOIN,对参与 Join 操作的基表或视图进行过滤,之后再对两表进行 Join 操作,输出结果集。
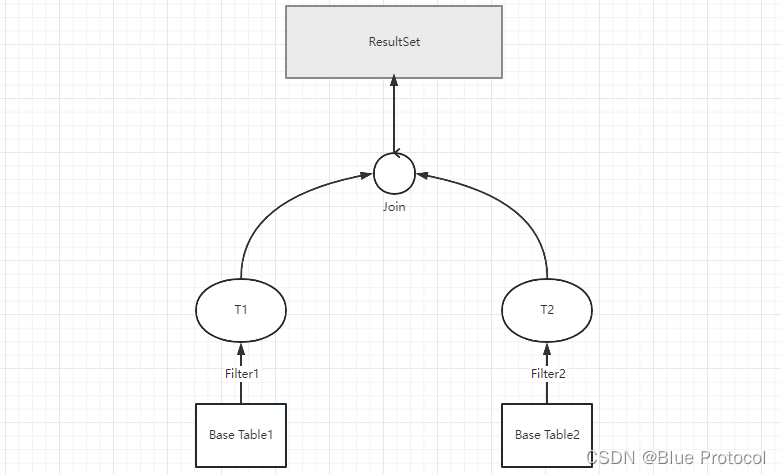
对于三表或多表 Join,则都是可以拆分为两表 Join 的方式进行处理,最先参与 Join 操作的两个表的 Join 的结果集,以表的形式参与后续的 Join 操作。
NLJ算法
NLJ:Nested-Loop Join(嵌套循环算法)
执行过程:一次一行地从驱动表中读取行,在这行数据中取到关联字段,根据关联字段在被驱动表里取出满足条件的行,然后取出两张表的结果合集。
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;

如果被驱动表中关联字段存在索引,整个过程会读取驱动表中所有的数据(比如100行),然后遍历每行数据中字段a的值,然后在遍历出来的a值索引扫描被驱动表中的对应行,一次找到一个,整个过程扫描了200行。
BNLJ算法
BNLJ:Block Nested-Loop Join(基于块的嵌套循环连接)
执行过程:把驱动表的数据全部读入join_buffer中,然后扫描被驱动表,把被驱动表的每一行取出来和join_buffer中的数据做对比,重复这个步骤。这个过程做了两次全表扫描ALL。
EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;

整个过程对驱动表和被驱动表都做了一次全表扫描(比如t1=10000,t2=100),扫描总行数:10000+100=10100,并且join_buffer里面的数据是无序的,因此对被驱动表的每一行,都需要,100次判断,所以内存中的判断次数是10000*100=100w次。
问题1:join buffer一次性放不下t2表怎么办?
join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。如果放不下表 t2 的所有数据话,策略很简单, 就是分段放。
举栗子:比如 t2 表有1000行记录, join_buffer 一次只能放800行数据,那么执行过程就是先往 join_buffer 里放800行记录,然 后从 t1 表里取数据跟 join_buffer 中数据对比得到部分结果,然后清空 join_buffer ,再放入 t2 表剩余200行记录,再 次从 t1 表里取数据跟 join_buffer 中数据对比。所以就多扫了一次 t1 表。
问题2:被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested-Loop Join 呢?
如果上面第二条sql使用 Nested-Loop Join,那么扫描行数为 100 * 10000 = 100万次,这个是磁盘扫描。 很显然,用BNL磁盘扫描次数少很多,相比于磁盘扫描,BNL的内存计算会快得多。 因此MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法。如果有索引一般选择 NLJ 算法,有 索引的情况下 NLJ 算法比 BNL算法性能更高。
总结:如何写入高性能的连接查询
连表的时候,我们需要去关注磁盘的IO。一般的操作是用小表驱动大表,注意在连接字段上建立索引,特别是被驱动表,这样MySQL内部使用的就是NLJ算法进行连接处理,能有效减少磁盘IO。如果连接条件有索引,MySQL内部会使用NLJ算法。如果没有索引,MySQL内部会使用BNLJ算法来基于内存计算,减少磁盘的IO扫描。
为什么MySQL不推荐使用Join
在阿里巴巴的开发规范中有明确规定超过三个表的情况下禁止使用join,即使是两表join时,也需要注意表的索引,SQL性能。
所以,不推荐使用Join的原因是性能原因。
当表的到达百万级数据量后,Join导致DB性能下降。
分布式的分库分表,不建议使用Join,跨库join表现不良。
当系统比较大时,如果要修改表的字段,单表查询的修改比较容易,Join写的SQL语句也需要修改,单不容易发现。
那有什么可以替代Join的方案
建议分别根据索引进行单表查询,单表查询出来之后,作为条件给下一次的单表查询。这样的结果我们更容易接受。
参考:
由笛卡尔积现象分析数据库表的连接
数据库开发应知应会之笛卡尔积
小表驱动大表
Mysql-表连接join中的NLJ、BNL算法







![[vue] Vite的使用](https://img-blog.csdnimg.cn/27a04531909c4d368b87a6fc1ee5b50e.png)
